
The Observability 2.0 database — one engine for metrics, logs & traces as unified wide events. Replaces Prometheus, Loki & ES. Open-source, SQL PromQL.
Joined May 2022
- Tweets 817
- Following 196
- Followers 968
- Likes 516
208 Photos and videos










GreptimeDB v1.0 GA is out.
One database for metrics, logs, and traces. SQL PromQL. Runs on object storage.
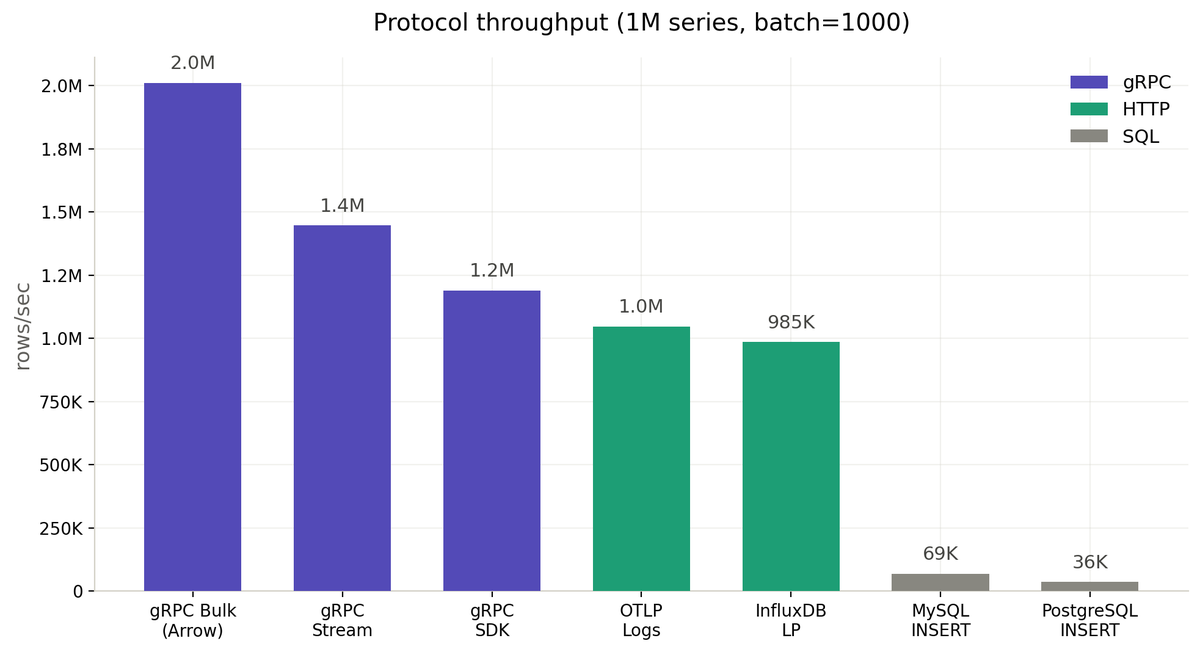
The big change: Flat SST is now the default format. At 2M series, write throughput is ~4× higher and some query latencies drop up to 10×.
Also in v1.0: built-in Perses dashboards (the MCP Server can create them via LLM too), OTLP partial success for traces, and PostgreSQL protocol fixes.
474 PRs from Beta1 to GA. 27 contributors, 8 first-timers.
greptime.com/blogs/2026-04-1…
5
1
9
843
Loki users shouldn't need a painful migration path.
GreptimeDB supports the Loki Push API, so you can redirect existing log writers with minimal config changes, dual-write for validation, and start querying logs with SQL, full-text search, Grafana, and GreptimeDB Dashboard.
Migrate from Loki to GreptimeDB:
docs.greptime.com/user-guide…
1
89
Erxi (@WangErxi) is now a GreptimeDB committer.
Erxi — a name with a quiet bit of wordplay. It comes from the Chinese word "无名" (nameless): keep only the upper halves of the two characters and they become "二夕" (Erxi).
What drew him to GreptimeDB was stability. Years on-call taught him to value it, and a Rust codebase meant few systemic production fires.
Two months later he's shipped meta KV write guards, flush-reason propagation, cancellable INSERT...SELECT, and a run of CSV COPY fixes. He also works on Apache Paimon and maintains his own GreptimeDB Flink connector.
Welcome aboard.
greptime.com/blogs/2026-05-3…
1
8
4,923
Great to see GreptimeDB listed on OpenAlternative—thanks, @ossalternative!
Open-source, cloud-native, and built for real-time metrics, logs, and traces. Learn more:
openalternative.co/greptimed…
2
104
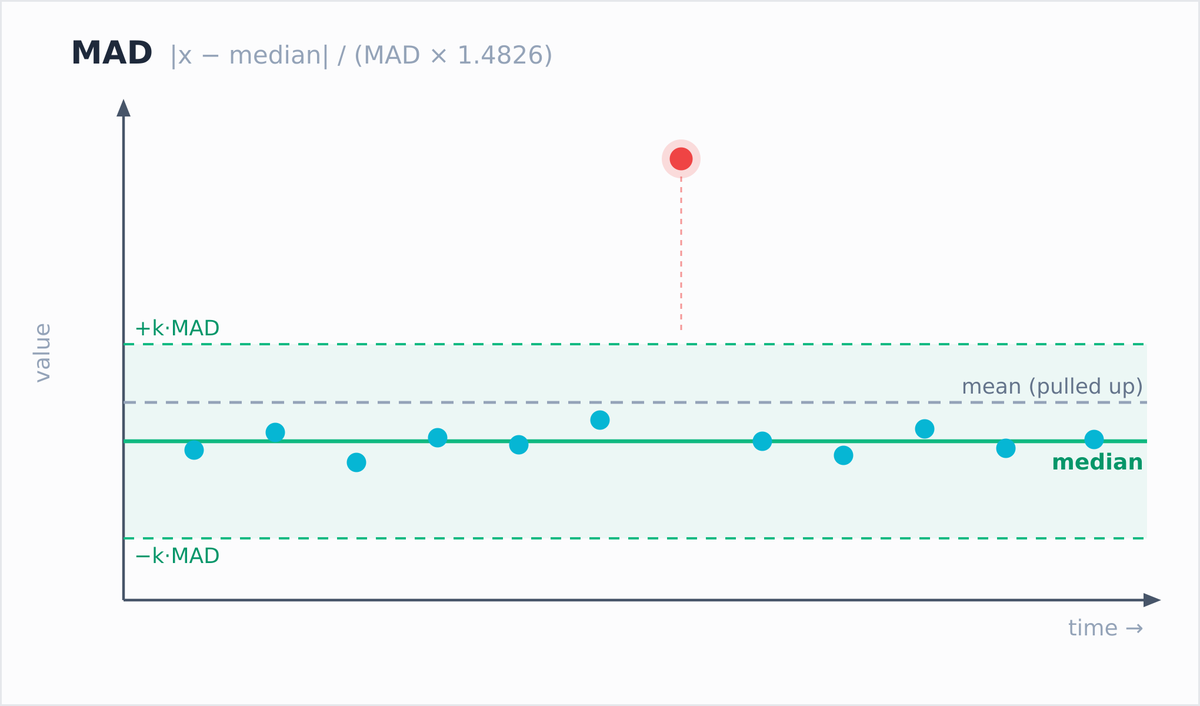
GreptimeDB 1.0 ships all three as built-in SQL window functions. Anomaly scoring without a separate service, and the alert threshold is a WHERE clause.
Z-Score is the tool most people reach for to flag metric spikes. It's also bad at the job.
Take a flat series around 10, drop in one outlier of 80. Z-Score scores that point ~2. MAD scores it 155, IQR 136.
The reason: the outlier drags up its own mean and stddev, so it no longer looks far from the mean it just poisoned. Median and quartiles don't move for one point, so MAD and IQR still catch it.
greptime.com/blogs/2026-06-0…
1
5
210
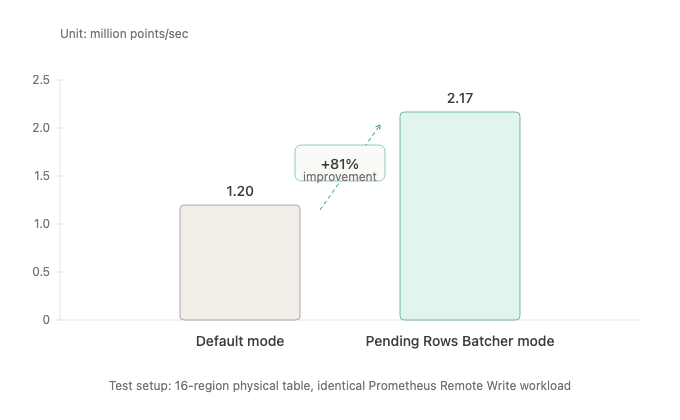
On Prometheus remote write, the bottleneck wasn't network or memtable — it was the Region Worker holding &mut while decoding rows, encoding primary keys, and aligning schema.
GreptimeDB v1.0 moves that work off the critical section and into the Frontend (Pending Rows Batcher). The Datanode now ingests pre-encoded Arrow IPC straight into BulkMemtable.
1.20M → 2.17M points/sec. -20% Datanode CPU.
greptime.com/blogs/2026-05-2…
2
129
Everything AI agents need to run GreptimeDB:
1. Quick start prompt
2. MCP Server
3. Skills
4. Machine-readable docs
docs.greptime.com/faq-and-ot…
Setup and run GreptimeDB in minutes.
1
4
250
New skill!🚀 Use GreptimeDB's self-monitoring export skill to locate incident windows from monitoring signals and export complete, continuous logs for investigation, including WARN. HTTP-first, row-count before export, artifact-ready for debugging.
github.com/GreptimeTeam/docs…
Makes GreptimeDB incident debugging much easier. 🛠️
2
100
Greptime retweeted

May 26
Object storage as the default persistence layer for modern data infrastructure didn't happen by accident. Three things converged, and they're worth pulling apart.
1️⃣ Cloud-native economics finally caught up with storage.
Kubernetes made compute elastic. EBS didn't. If what you want is pay-per-use, multi-tenant economics that scale to zero, you eventually end up on S3. Not because it's fast — it isn't. Because it's the only storage tier whose pricing model matches how modern workloads actually behave: spiky, unpredictable, and idle a lot of the time.
2️⃣ S3 itself grew up.
Strong read-after-write consistency landed in 2020. Express One Zone with single-digit-ms latency in 2023. Then Mountpoint, intelligent tiering, conditional writes. The S3 you can build on today is genuinely not the S3 you uploaded vacation photos to in 2008 📸.
Real databases now sit on top of it: Snowflake, Databricks, ClickHouse Cloud, WarpStream, Turbopuffer, the Iceberg/Delta/Hudi crowd. Even Postgres — Neon put its entire storage engine on object storage, which would have sounded like a bad joke for an OLTP system a few years ago.
3️⃣ The workload shape changed everywhere, not just in one corner.
Most of the new high-volume data is semi-structured or unstructured: vectors, JSON, events, logs, traces. It shows up in observability, in business analytics, in customer 360, in AI training data. This isn't a domain-specific shift.
Dashboards and nightly ETL are giving way to ad-hoc analytics, RCA, and increasingly agents 🤖 firing open-ended questions at operational and business data. That kind of workload is append-heavy, hungry for throughput, and you basically cannot capacity-plan it. Object storage handles that better than any block device, because you're not paying for a peak you never hit.
One thing worth being honest about ⚠️: none of this is free. OLTP still wants local NVMe for hot paths. Small-object API costs can quietly exceed your storage bill. Listing is still slow. Cross-cloud egress will eat your margins if you're not careful. Anyone pitching "just put it on S3" without talking about caching, compaction, and catalogs is pitching a slide deck.
The direction is pretty clearly set, though. In 2026, building a new data system on anything other than object storage as the source of truth feels like something you should have to justify, not something you fall back on.
It's why we built @Greptime this way from day one. Time-series and observability happened to be one of the first places where the math stopped being arguable. I don't think it stops there.
Curious how others are seeing this — especially folks on the OLTP side who'd push back. 👇
—
References:
Snowflake's elastic warehouse (SIGMOD 2016): dl.acm.org/doi/10.1145/28829…
Lakehouse architecture (CIDR 2021): cidrdb.org/cidr2021/papers/c…
S3 strong consistency: aws.amazon.com/blogs/aws/ama…
S3 Express One Zone: aws.amazon.com/s3/storage-cl…
Mountpoint for S3: aws.amazon.com/blogs/aws/mou…
Neon architecture: neon.com/docs/introduction/a…
WarpStream: warpstream.com/blog/kafka-is…
GreptimeDB architecture: docs.greptime.com/user-guide…

4
7
419
OpenTelemetry graduated from CNCF (May 21). Second only to Kubernetes in project velocity across 240 cloud native projects, 12,000 contributors from 2,800 companies.
The most actively moving subspec right now is GenAI 🔥: every release from v1.37 to v1.41 has touched it. Walkthrough of the full 6 layers (Client Spans, Agent Spans, MCP, Events, Metrics, Provider conventions):
greptime.com/blogs/2026-05-0…
#OpenTelemetry #GenAI #Observability
2
1
138
Greptime retweeted

May 21
@opentelemetry is officially a CNCF graduated project! 🎓🎉
OpenTelemetry has become the trusted de facto observability standard, backed by 12,000 contributors from 2,800 organizations and helping teams gain better visibility across distributed systems.
Congrats to this incredible community! Read more about the milestone here: bit.ly/4fvcHAb

2
66
249
35,422
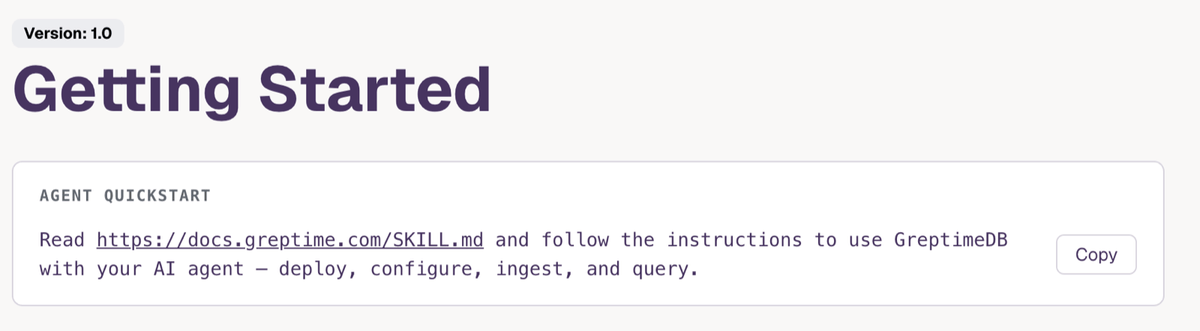
GreptimeDB now ships an Agent Quickstart prompt on its website and quick start doc — point your AI agent at SKILL.md and it figures out how to install, configure, ingest, and query GreptimeDB.
Also biweekly #83: DataFusion 53, pre-cast constants for faster filter pushdown, and new Hotspot Autopilot dashboard panels.
greptime.com/blogs/2026-05-1…
1
100
DataFusion shipped dynamic filter pushdown upstream last September. GreptimeDB v1.0 wires it into the Mito scan layer.
The bound TopK is currently holding gets pushed down to the scan as a runtime predicate — dynamic meaning it tightens as TopK converges, and each row group is evaluated against the latest snapshot, not the one at query start.
Side effect: 29s → 0.21s on ORDER BY end_time DESC LIMIT 10 (5B-row traces table).
greptime.com/blogs/2026-05-1…
3
6
383
Greptime retweeted
May 19
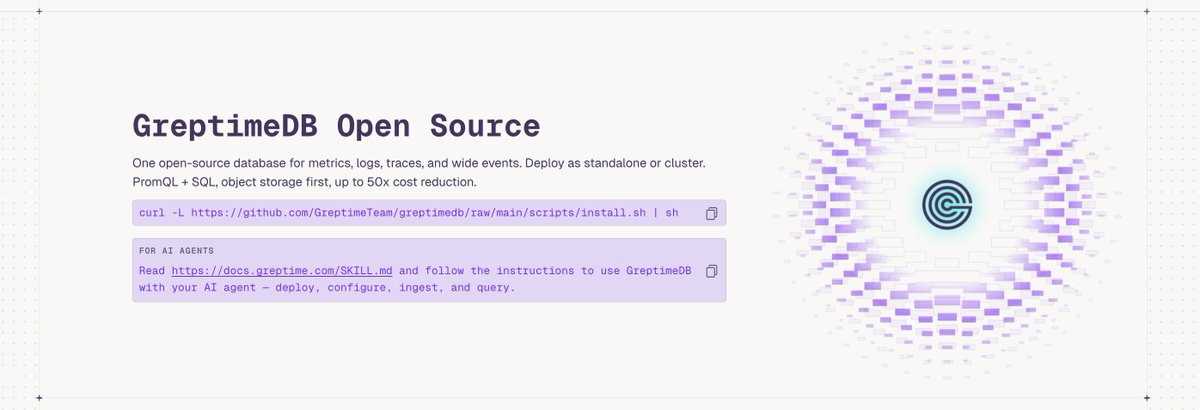
One-click copy tells your AI Agent how to install and use GreptimeDB.
greptime.com/product/db
1
2
177
IoT Expo 2026 is happening now!
Come find us at Booth 115 to chat about IoT data platforms and AI observability. See you there!
#IoTExpo #TimeSeries

1
60
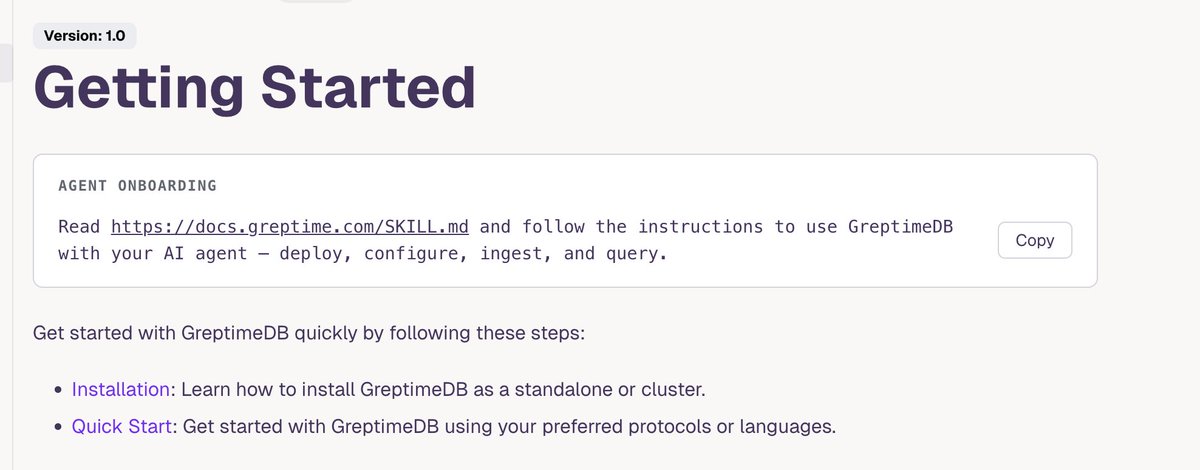
Added an Agent Onboarding prompt card to our Getting Started docs to help your AI agent install and use GreptimeDB. Covers deploy, configure, ingest, query — MCP-first. Sister skills (pipeline/flow/trigger) hosted alongside.
docs.greptime.com/getting-st…
1
71