
Joined December 2017
- Tweets 493
- Following 432
- Followers 149
- Likes 8,479
1 Photos and videos
Ghulam Rasool retweeted

12 Feb 2024
one trick to programming productivity is figure out half of the structure of your program by thinking hard, and then discover the other half from the process of trying to actually write the code for what you've been picturing
80
303
3,275
235,801

10 Feb 2024
Generative AI May Improve Radiology Report Clarity | RSNA 2023 dailybulletin.rsna.org/db23/…
1
124
Ghulam Rasool retweeted

30 Nov 2023
Moffitt's Dr. Ghulam Rasool's (@Gxrasool) research on generative AI and improving radiology report clarity was published in the @RSNA Daily Bulletin.
Read more: bit.ly/47VvNbP
#RSNA23

1
4
815



Ghulam Rasool retweeted

7 Feb 2024
@ml4onco's @Gxrasool presented at our new seminar series, Hands-On Machine Learning (HOME), on February 6, 2024, on the topic of “Intro to Machine Learning using LLMs as an Example.”
For a recording of this presentation, please view: moffitt.hosted.panopto.com/P…
2
3
224
Ghulam Rasool retweeted
7 Feb 2024
Dr. @Gxrasool is organizing a free workshop for students/postdocs on February 22, 2024, at 11am EST/8am PST entitled "Building Transformer Based Natural Language Processing Applications". Please feel free to register for this virtual workshop by going to: events.nvidia.com/dlihighere…
2
3
271
10 Feb 2024
Join me on February 22nd, 2024, for an exclusive workshop titled "Building Transformer-Based NLP Applications," brought to you by NVIDIA. Register here: [events.nvidia.com/buildingtr…]
#NLP #Transformers #MachineLearning #ArtificialIntelligence #NVIDIA #Workshop #AICommunity
41
Ghulam Rasool retweeted

10 Oct 2023
The heretofore silent majority of AI scientists and engineers who
- do not believe in AI extinction scenarios or
- believe we have agency in making AI powerful, reliable, and safe and
- think the best way to do so is through open source AI platforms
NEED TO SPEAK UP !
10 Oct 2023

yes - the deck is stacked
Decades of dystopian sci-fi and talk of extinction create the fear required to limit development
open-source advocates need clear, tangible examples of the tech's value and the importance of US leadership
who do you think is doing this best?
151
378
1,956
1,050,218
Ghulam Rasool retweeted

11 Oct 2023
Mistral 7B paper is on Arxiv:
arxiv.org/abs/2310.06825

8
65
554
75,242
Ghulam Rasool retweeted

11 Oct 2023
I have 2 Postdoc openings on #federated #machineLearning for #breastCancer & on #computational #pathology.
PM, email, or find me at #MICCAI2023 (during @BraTS_challenge) to discuss more. @WomenInMICCAI @MICCAI_Society @MiccaiStudents @MeRAQi_lab @IUMedSchool @IndianaUniv

3
10
49
4,870
Ghulam Rasool retweeted
4 Oct 2023
@ml4onco has available opportunities: Tenure-Earning Vice Chair for Clinical Machine Learning and Postdoc Fellow – Machine learning for Cancer Diagnosis and Response Prediction! For more information: moffitt.org/research-science… #MachineLearning #AI #cancerresearch #vicechair #postdoc
2
2
275
Ghulam Rasool retweeted
5 Oct 2023
Some folks: "Open source AI must be outlawed."
Open source AI startup community in Paris:


55
143
1,421
311,727
Ghulam Rasool retweeted
4 Oct 2023
That’s a wrap at #ASTRO23! Moffitt Cancer Center was proud to join the best minds in radiation oncology this week in San Diego. See you next year, @ASTRO_org!




1
1
14
1,261
Ghulam Rasool retweeted
4 Oct 2023
The Machine Learning Department at Moffitt Cancer Center is honored to invite you to speak at an upcoming meeting of the Machine Learning League.
For more info go to: moffitt.org/research-science…
2
5
336
Ghulam Rasool retweeted

5 Oct 2023
I gave a talk at Seoul National University.
I titled the talk “Large Language Models (in 2023)”. This was an ambitious attempt to summarize our exploding field.
Video: youtu.be/dbo3kNKPaUA
Slides: docs.google.com/presentation…
Trying to summarize the field forced me to think about what really matters in the field. While scaling undeniably stands out, its far-reaching implications are more nuanced. I share my thoughts on scaling from three angles:
1) Change in perspective is necessary because some abilities only emerge at a certain scale. Even if some abilities don’t work with the current generation LLMs, we should not claim that it doesn’t work. Rather, we should think it doesn’t work yet. Once larger models are available many conclusions change.
This also means that some conclusions from the past are invalidated and we need to constantly unlearn intuitions built on top of such ideas.
2) From first-principles, scaling up the Transformer amounts to efficiently doing matrix multiplications with many, many machines. I see many researchers in the field of LLM who are not familiar with how scaling is actually done. This section is targeted for technical audiences who want to understand what it means to train large models.
3) I talk about what we should think about for further scaling (think 10000x GPT-4 scale). To me scaling isn’t just doing the same thing with more machines. It entails finding the inductive bias that is the bottleneck in further scaling.
I believe that the maximum likelihood objective function is the bottleneck in achieving the scale of 10000x GPT-4 level. Learning the objective function with an expressive neural net is the next paradigm that is a lot more scalable. With the compute cost going down exponentially, scalable methods eventually win. Don’t compete with that.
In all of these sections, I strive to describe everything from first-principles. In an extremely fast moving field like LLM, no one can keep up. I believe that understanding the core ideas by deriving from first-principles is the only scalable approach.

41
585
2,779
567,444
Ghulam Rasool retweeted
5 Oct 2023
I do acknowledge risks.
*BUT*
1. Yes, open research and open source are the best ways to understand and mitigate them.
2. AI is not something that just happens. *We* build it, *we* have agency in what it becomes. Hence *we* control the risks. It's not some sort of natural phenomenon that we have no control over.
3. I will keep summarily dismissing the most ridiculous AI fear-mongering.
4 Oct 2023

My followers might hate this idea, but I have to say it: There's a bunch of excellent LLM interpretability work coming out from AI safety folks (links below, from Max Tegmark, Dan Hendrycks, Owain Evans et al) studying open source models including Llama-2. Without open source, this work would not be happening, and only industry giants would know with confidence what was reasonable to expect from them in terms of AI oversight techniques. While I wish @ylecun would do more to acknowledge risks, can we — can anyone reading this — at least publicly acknowledge that he has a point when he argues open sourcing AI will help with safety research? I'm not saying any of this should be an overriding consideration, and I'm not saying that Meta's approach to AI is overall fine or safe or anything like that... just that Lecun has a point here, which he's made publicly many times, that I think deserves to be acknowledged. Can we do that?
Examples of some (awesome) papers I'm referring to above:
Owain Evans et al:
twitter.com/OwainEvans_UK/st…
Dan Hendrycks et al:
twitter.com/DanHendrycks/sta…
Max Tegmark et al:
twitter.com/wesg52/status/17…
(If you haven't read these, do check them out!)
49
68
617
249,325
Ghulam Rasool retweeted
5 Oct 2023
Given the prevalence of simultaneously clueless and misleading comments about various serious topics on X/Twitter (e.g. AI, vaccines,..), I feel the need for a new hashtag:
#YHNIWYATA : You Have No Idea What You Are Talking About.
Or perhaps the less polite #YHNIWTFYATA.
128
87
1,334
237,723
4 Oct 2023
Planning my trip to Homestead - staying at Flamingo Adventures. For friends traveling soon: flip.to/r/zsjf8 @FlamingoEvergld
26
Ghulam Rasool retweeted

29 Sep 2023
The evolution of LLMs over the next couple of years - Will the tech become a commodity and commonplace?
Not a single day passes by without someone announcing a new LLM and foundation models get replaced by next-generation models in a matter of months.
So what is the future of this technology and how is the space likely to evolve?
Data Advantage and Information Queries - To begin with, LLMs will soon become data-constrained. Even with a large number of GPUs, most companies don't have access to new and unique sources of data.
Google and Meta have a huge advantage here compared to anyone else. Google, because of it's search dominance can get away with crawling every website that wants their search traffic and can use YouTube and potentially Gmail data to train their LLMs. Meta enjoys the same advantage in terms of being able to use Facebook and Instagram data.
This will translate to Google and Meta LLMs being able to serve and respond to general information queries better than LLMs from OpenAI or other start-ups.
Already, Bard outperforms GPT-4 when it comes to queries about recent data and GPT-4 does much better on queries on data available before September 2021 (it's training cut-off date).
LLMs For General Purpose Tasks - So the next question is will we have specialized LLMs for some general purpose tasks like coding, reasoning, summarization, or writing.
For example, GPT-4 does really well on code compared to Google's LLMs, so will there be several purpose-built LLMs?
This is unlikely to be the case for general-purpose tasks. Large SOTA LLMs outperform specialized LLMs in most tasks. Again GPT-4 outperforms specialized LLMs on pretty much everything from code generation to writing and reasoning tasks
Here is it important to draw the distinction between general-purpose tasks like Python code generation vs. a very specialized task like having knowledge of Abacus APIs and programming the Abacus platform. The former typically DOES NOT require fine-tuning or RAG (retrieval augmented generation) while the latter requires some custom work
All this means that we will end up with Google, Meta, and potentially OpenAI being the key players in the consumer LLM (e.g. ChatGPT, Bard, etc.) world.
It is extremely unlikely that we will have more than 2-3 of these services. These services, like ChatGPT, will have a free and paid subscription tier. Paying subscribers will enjoy premium features like personalized responses and access to multi-modal features etc.
Enterprise AI and LLM APIs - The other big category of LLM use cases is businesses using these LLMs in their core products, services, and business processes.
There are 2 classes of use cases in this space.
General purposes use-case embedded in a product or service - e.g. summarize my Slack channel or Zoom meeting. For these use cases, a vanilla API call to SOTA LLM is sufficient. Price will be the key consideration in these use cases and as long as the large LLM providers have very competitive prices, just making simple calls to their APIs will work.
Specialized large-scale use-cases on custom knowledgebases This is the category of custom enterprise use-cases, where you may have several thousands of calls per day and the LLM needs to have an understanding of a custom knowledgebase or task.
I suspect, that smaller more efficient LLMs that have reasonably good reasoning capabilities can be fine-turned or complemented with RAG and incorporated into the workflow to automate these use cases. Using GPT-4 or some other very large LLM will become cost-prohibitive in these cases.
Companies will use LLM Ops platforms such as Abacus to automate an end-to-end workflow and these platforms will offer a combination of both open-source LLMs and closed-sourced APIs. Companies should be free to pick and choose an LLM based on cost, performance, and time to market.
In some very specific cases, we will also see some very specialized LLMs emerge - e.g. financeLLM or LegalLLM. These domain-specific LLMs that may require a lot of custom training, RLHF, and fine-tuning. For example, Bloomberg created a BloombergGPT a 50-billion parameter large language model that was purpose-built from scratch for finance.
Having said that, BloombergGPT is probably out of date already, as such custom models lack good reasoning skills that general-purpose LLMs possess and it is much better to simply fine-tune or use RAG on a SOTA LLM compared to training a custom model for your special task.
Net-net, we are seeing what you expect to see in a new and exciting space - a large number of companies are being started in this space and over time, we will see a lot of consolidation and a handful of key players emerge.
Just like with other core infrastructure such as operating systems or databases, there is likely to be a healthy open-source ecosystem that complements the services from the giants

32
239
908
238,440

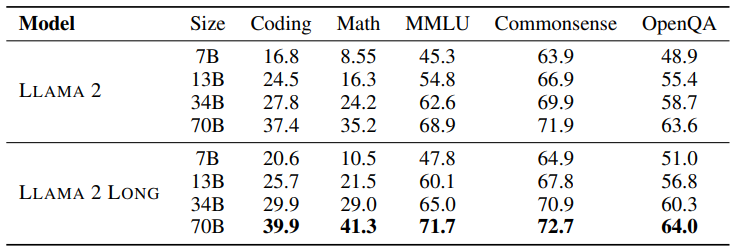
Meta just dropped a banger:
LLaMA 2 Long.
- Continued pretraining LLaMA on long context and studied the effects of pretraining text lengths.
- Apparently having abundant long texts in the pretraing dataset is not the key to achieving strong performance.
- They also perform a large experiment session comparing different length scaling techniques.
- Surpassed gpt-3.5-turbo-16k’s on a multiple long-context tasks.
- They also study the effect of instruction tuning with RL SFT and all combinations between the two.
The model weights are not out yet.
Hopefully Soon! 🙏
29 Sep 2023

Effective Long-Context Scaling of Foundation Models
LLAMA 70B variant surpasses gpt-3.5-turbo-16k’s overall performance on a suite of long-context tasks
arxiv.org/abs/2309.16039
13
74
527
162,980