
Joined November 2012
- Tweets 107
- Following 95
- Followers 13
- Likes 61
10 Photos and videos








Jun 10
Claude: "Hey Claude" $1.74
Minimax: "Rebuild this React Native app in Kotlin" $0.32
6
HALO terminal retweeted

Jun 10
Apple used OpenCode to demo MLX at WWDC26

48
87
3,129
129,531
HALO terminal retweeted

Overview of our recently launched AA-WER Streaming benchmark, measuring streaming Speech to Text models on accuracy and latency for voice agent use cases
Streaming Speech to Text (STT) powers real-time transcription in voice agents and live captioning, where models must balance accuracy against speed. Fast transcripts keep responses feeling natural and free up the response-time budget for reasoning and tool calls. Accuracy matters too, since errors can compound downstream.
Streaming STT models transcribe audio as it is fed in, sharing outputs continuously, unlike offline (batch) models that process the entire file at once and are typically slower.
Models from Cartesia, ElevenLabs, and Deepgram sit on the accuracy-latency Pareto frontier. Cartesia Ink-2 leads on final transcript accuracy at 3.59% WER (210ms), closely followed by ElevenLabs Scribe v2 Realtime at 3.64% WER (140ms). Deepgram Flux is fastest at ~20ms on final transcript latency (7.36% WER).
In this video, Kiriill Butler, Member of Technical Staff at Artificial Analysis, walks through the benchmark and key results.
8
6
64
8,563
HALO terminal retweeted
Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

562
1,154
10,964
4,945,696
May 14
We don't want people to use our plans in any automation, but we told them already that they could do that... If we block them out, they will complain. What could we do? Let's gaslight to them and say they get more while kicking them out:
May 13

Starting June 15, paid Claude plans can claim a dedicated monthly credit for programmatic usage.
The credit covers usage of:
- Claude Agent SDK
- claude -p
- Claude Code GitHub Actions
- Third-party apps built on the Agent SDK
9
May 5
I need better tools to manage multiple agents.
- See where where my input is needed
- Review changes on a higher level
- Monitor progress, including code changes to stop agents early from going down the wrong path
- All of those across multiple agents and multiple projects
8
Mar 28
Most people focus on:
→ “How do I make the agent smarter?”
The actual leverage is:
→ “How do I make the environment simpler and measurable?”
7
HALO terminal retweeted

Mar 18
Introducing MiMo-V2-Pro & Omni & TTS
mimo.xiaomi.com

59
164
1,343
303,337

HALO terminal retweeted

Mar 18
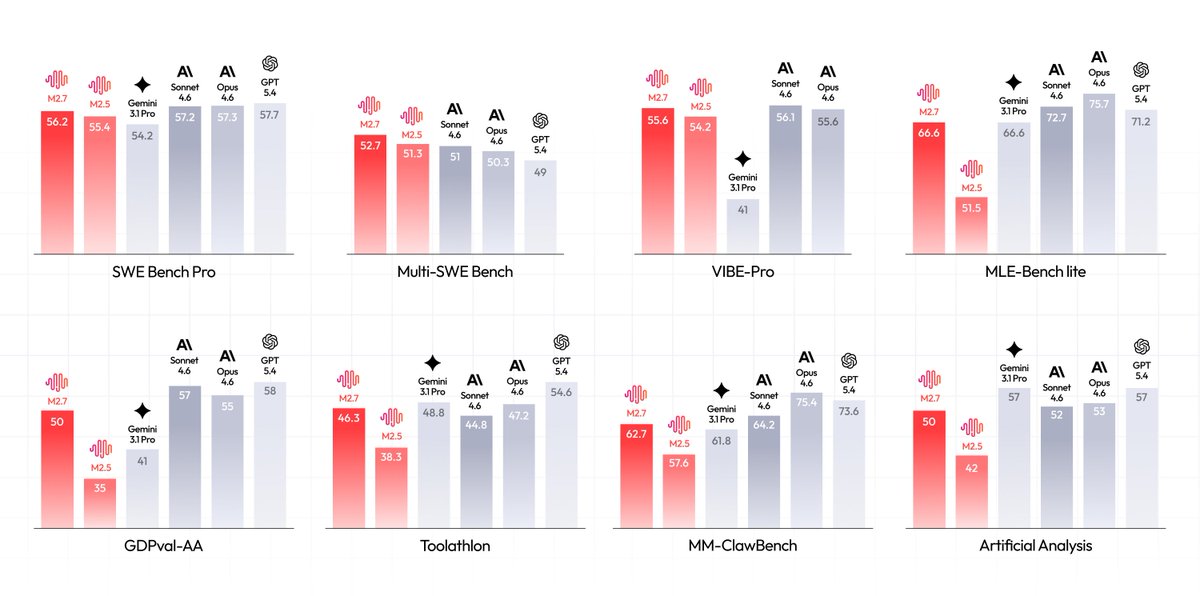
Introducing MiniMax-M2.7, our first model which deeply participated in its own evolution, with an 88% win-rate vs M2.5
- Production-Ready SWE: With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%), M2.7 reduced intervention-to-recovery time for online incidents to 3-min on certain occasions.
- Advanced Agentic Abilities: Trained for Agent Teams and tool search tool, with 97% skill adherence across 40 complex skills. M2.7 is on par with Sonnet 4.6 in OpenClaw.
- Professional Workspace: SOTA in professional knowledge, supports multi-turn, high-fidelity Office file editing.
MiniMax Agent: agent.minimax.io
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
212
401
3,407
2,110,757
Mar 18
A done agent and a stuck agent look the same from across the room.
2
7
Mar 17
Notifications interrupt. Ambient signals inform.
That distinction matters a lot more when you're managing agents instead of just writing code.
3
9
Mar 16
The difference between AI tools that read files and tools that query code structure isn't a UI preference.
One guesses at context. The other knows it.
That difference compounds across a whole project.
1
7
Mar 15
Small tasks delegated clearly beat large tasks delegated sloppily.
AI didn't change this. It just made the cost of sloppy delegation immediate.
4
Mar 14
The developers getting the most out of AI aren't the ones prompting better.
They're the ones who've redesigned when they're in the loop.
4
Mar 13
More capable agents don't make the attention problem easier. They make it harder.
The better the agent, the longer you can leave it — and the more it's done when something quietly goes wrong.
2