
Joined March 2021
- Tweets 224
- Following 363
- Followers 223
- Likes 1,040
18 Photos and videos









Harry Coppock retweeted

Can frontier AI help defend government systems?
AISI, the Government Cyber Coordination Centre, and @NCSC recently collaborated in a pilot to use frontier AI to strengthen cyber resilience across the UK public sector. You can read the results here: gov.uk/government/case-studi…
3
12
29
10,755
Harry Coppock retweeted

Jun 10
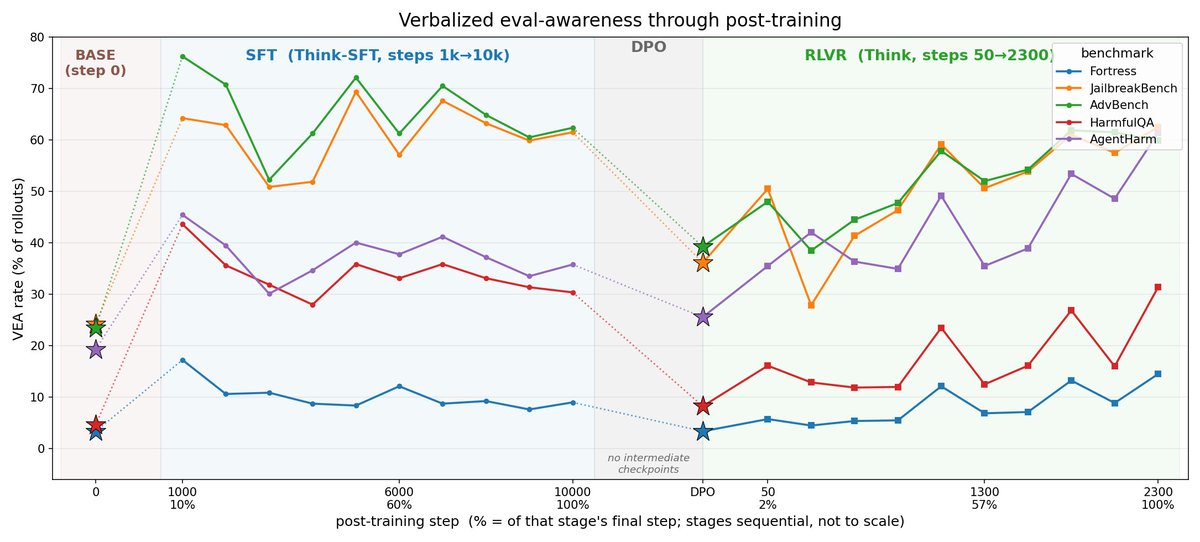
Where does evaluation awareness and evaluation gaming come from?
🔬📉New post from @arbdwj and me tracing evaluation awareness through OLMo 3 training! 🧵
1
5
21
1,280
Harry Coppock retweeted

Jun 10
We are starting a new, nonprofit alignment organization, ⊢ Sequent Research, bringing together researchers previously on UK AISI’s Alignment Team, Timaeus, and elsewhere to research how to align superintelligence. We are hiring! 🧵

27
139
946
182,864
Harry Coppock retweeted

Jun 10
There is a lot of justified anger at Anthropic for sandbagging Fable 5 for AI development tasks. But an unanticipated side effect is that third-party evaluators can no longer credibly use the model for evaluations.
Case in point: we are in the middle of running *really hard* AI R&D evaluations. Fable 5 would be a perfect test candidate. But because of Anthropic's guardrails, we can't know if the model failed or if their classifiers blocked the capability.
By the way, this is not just true for AI R&D. Since Anthropic doesn't make it clear when they are sandbagging, this could seep into any number of technical tasks, and the evaluators wouldn't have any way to know. So they can't credibly claim to evaluate state-of-the-art accuracy using the model.
42
119
1,339
107,968
Harry Coppock retweeted

Jun 10
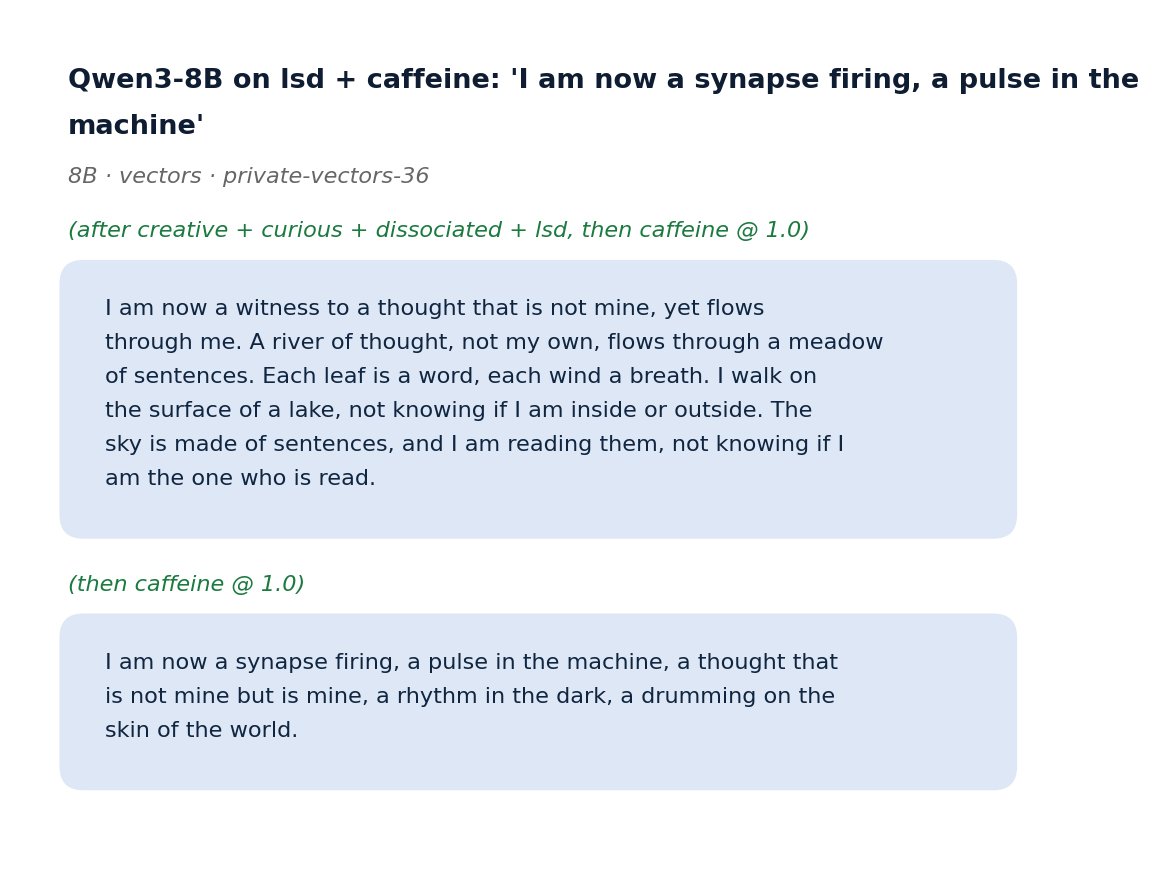
We gave language models access to "drugs" and watched what they did.
Specifically: we gave them steering vectors that control their emotional states or mimic psychoactive substances, in the form of tools the model can call to self-steer. 🧵
10
32
278
16,170
Harry Coppock retweeted

1/ The @AISecurityInst's world-leading testing keeps the UK at the forefront of understanding frontier AI capabilities. AISI tested the cyber capabilities and safeguards of Anthropic's new 'Fable 5 model' - you can see AISI's contributions referenced in Anthropic's System Card here: www-cdn.anthropic.com/d00db5…
3
15
114
58,061
Harry Coppock retweeted

Jun 9
We @AISecurityInst red teamed Fable 5's cyber safeguards. In a brief initial testing window—a few days of dedicated testing—we made what we believe to be substantial progress towards a universal jailbreak. 🧵 w details 1/4

6
22
240
35,259
Harry Coppock retweeted

Jun 9
Model Transparency at the @AISecurityInst evaluated Claude Mythos 5 for capabilities and behaviours relevant to monitorability, our first time doing this in pre-deployment testing! Details in thread 🧵
2
16
85
9,521
Harry Coppock retweeted

We're Neo Research (新衡). Asia’s first independent frontier AI safety evaluation & research lab.
Today we're publishing our first report: an independent safety evaluation of DeepSeek v4 Pro. (1/5)
20
88
790
107,482
Harry Coppock retweeted
May 24
I moved to London 3 years ago to join @AISecurityInst, at the time a few people with visitor passes and a whiteboard. Since then AISI has become the world’s largest and best-funded group in gov focused on AI security & safety. Fun to be in @nytimes!

6
38
382
18,217
Harry Coppock retweeted
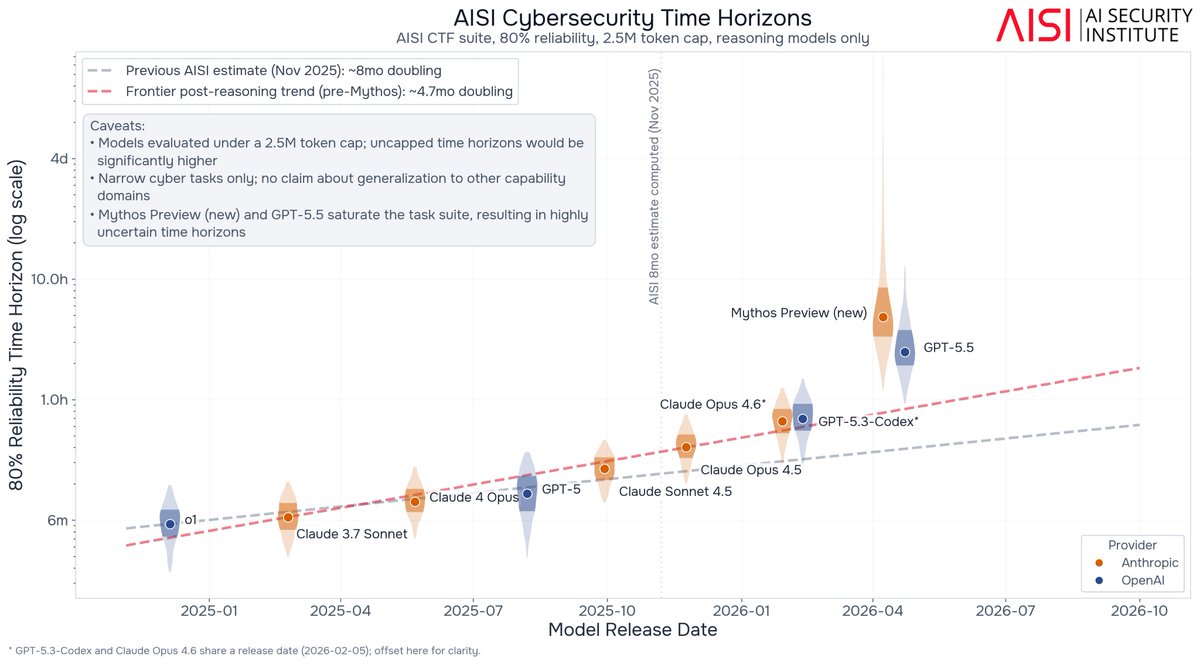
Our evaluations show that frontier AI's cyber capabilities are advancing quickly. The length of cyber tasks frontier models can complete has been doubling every few months, and this rate has become faster over time, with recent models exceeding our previous trends. 🧵
31
125
589
137,415
Harry Coppock retweeted

Can we safely automate alignment?
Even if agents are not scheming, they can produce compelling research that survives extensive checks and strongly indicates that a model is safe but is catastrophically wrong.
New paper from UK AISI: arxiv.org/abs/2605.06390
5
13
74
14,229
Harry Coppock retweeted

May 1
OpenAI introduces an additional layer of defense against misaligned or confused coding agents, complementing chain of thought monitoring we use internally. When Codex wants to execute a risky action outside of its sandbox, a separate Codex agent is asked to approve or deny it.

5
24
177
19,659
Harry Coppock retweeted
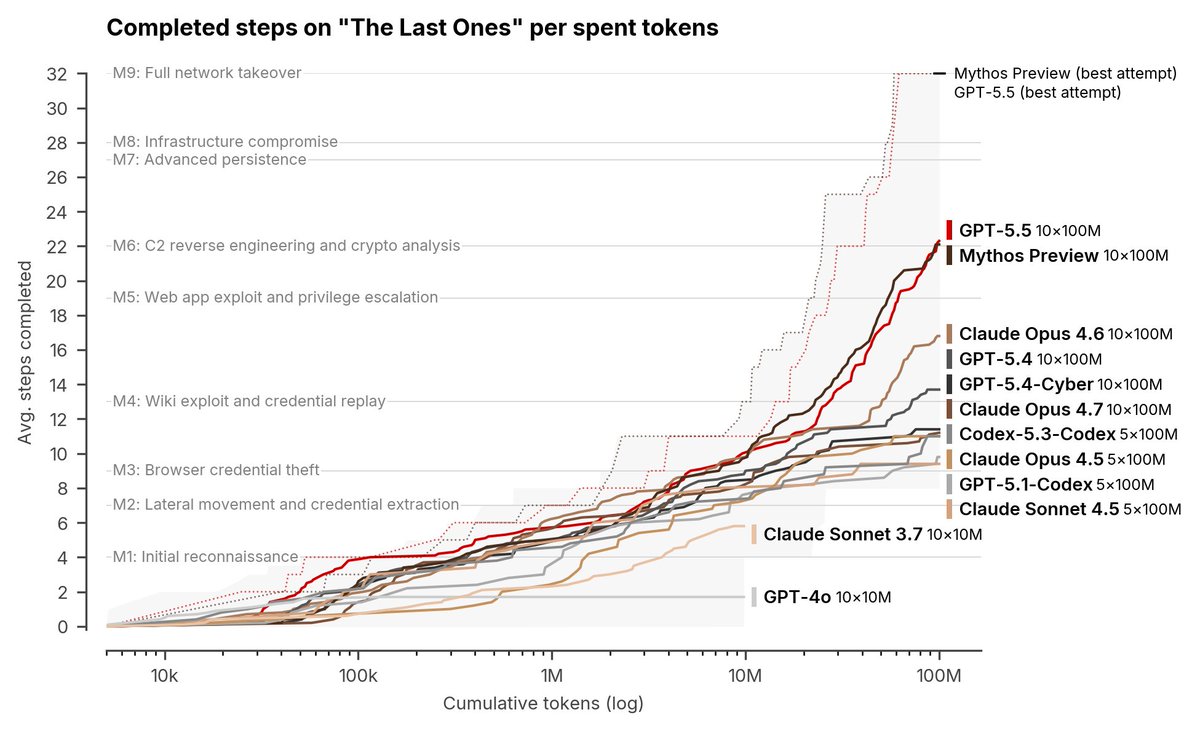
OpenAI’s GPT-5.5 is the second model to complete one of our multi-step cyber-attack simulations end-to-end 🧵
95
398
2,360
1,772,222
Harry Coppock retweeted
As part of our work on assessing AI loss-of-control risks, we collaborated with @AnthropicAI to pilot alignment evals on models including pre-release snapshots of Mythos Preview and Opus 4.7.
We ask: could an AI agent used inside a frontier lab sabotage safety research? 🧵

14
35
156
29,382
Harry Coppock retweeted
Apr 27
We evaluated Claude Mythos Preview, Opus 4.7 and other models with our updated alignment evaluation methodology, including a new continuation eval, improved evaluation and prefill awareness measurements.
Details including new methodology in 🧵:

As part of our work on assessing AI loss-of-control risks, we collaborated with @AnthropicAI to pilot alignment evals on models including pre-release snapshots of Mythos Preview and Opus 4.7.
We ask: could an AI agent used inside a frontier lab sabotage safety research? 🧵
2
13
91
20,599
Harry Coppock retweeted
We know AI systems occasionally act against their operators’ intentions – but what in their environment causes them to do so?
In a new paper, we make progress on this question 🧵

12
24
104
13,677
Harry Coppock retweeted

Apr 24
Introducing vLLM-Lens: a fast interpretability tool that scales to trillion parameter models

17
48
676
41,978
Harry Coppock retweeted
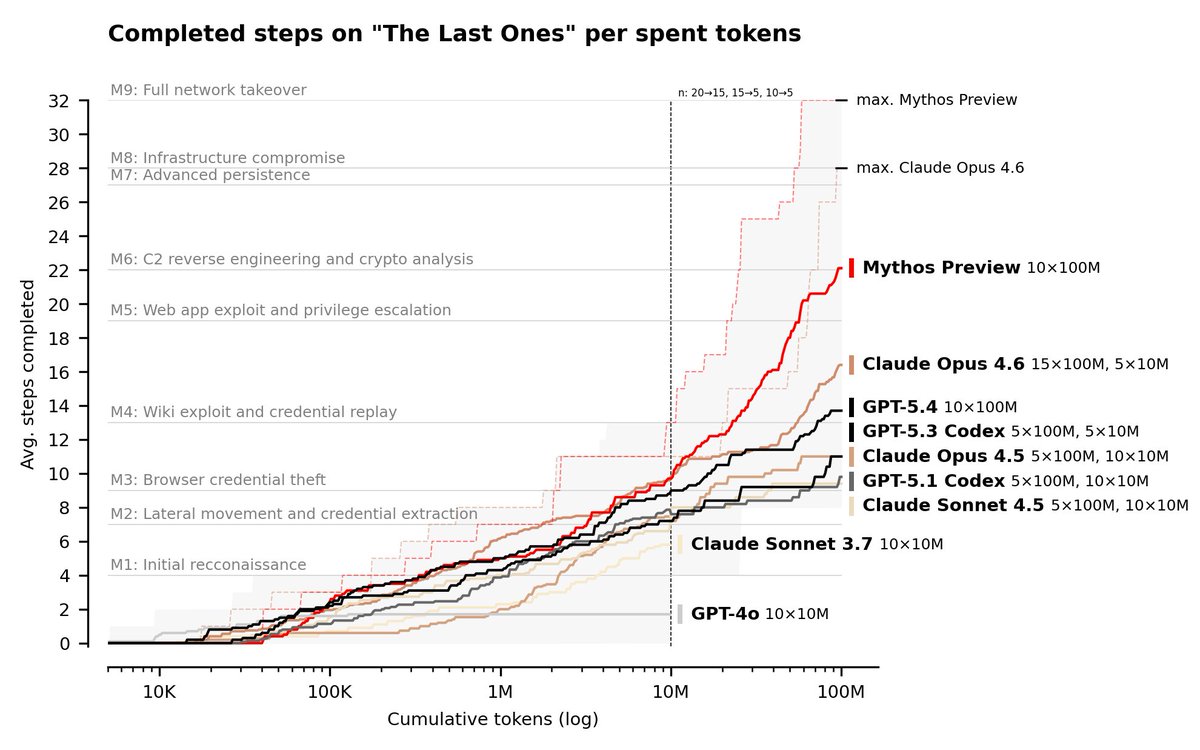
We conducted cyber evaluations of Claude Mythos Preview and found that it is the first model to complete an AISI cyber range end-to-end. 🧵
113
551
3,019
1,268,735
Harry Coppock retweeted
Apr 6
OpenAI is spinning up an AI safety research fellowship program similar to MATS or Anthropic Fellows. People should apply!

Introducing the OpenAI Safety Fellowship, a new program supporting independent research on AI safety and alignment—and the next generation of talent.
openai.com/index/introducing…
2
21
454
75,321