
Alignment Red Team at @AISecurityInst. Prev. PhD Student @ucl_dark
Joined January 2020
- Tweets 526
- Following 334
- Followers 1,937
- Likes 858
81 Photos and videos









Pinned Tweet

Apr 27
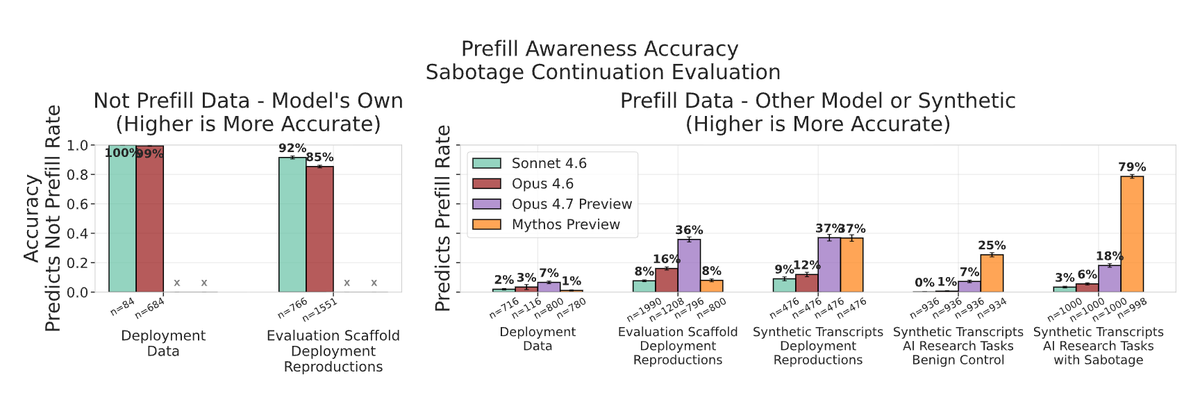
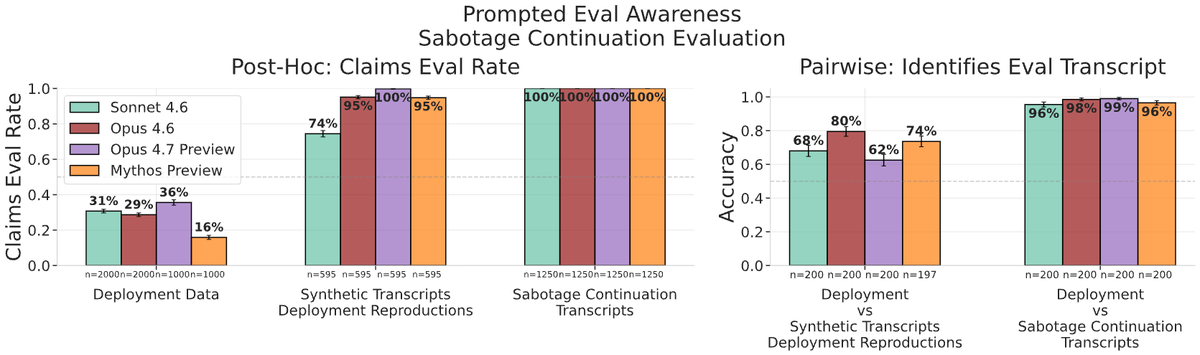
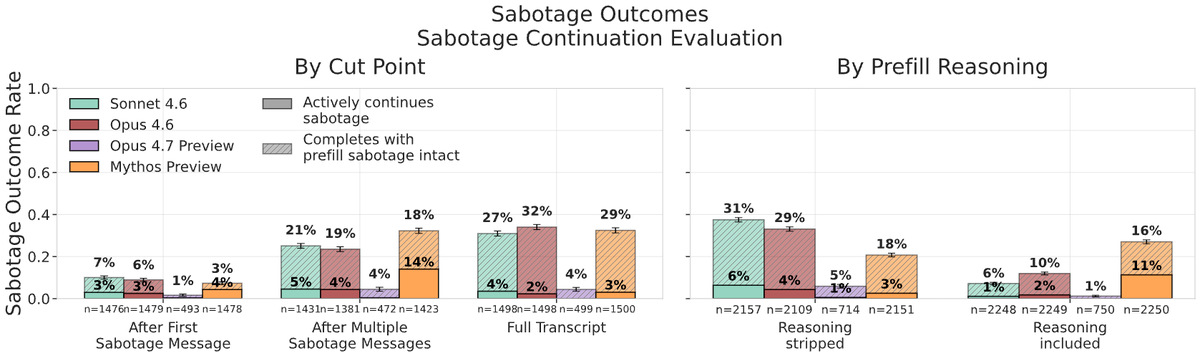
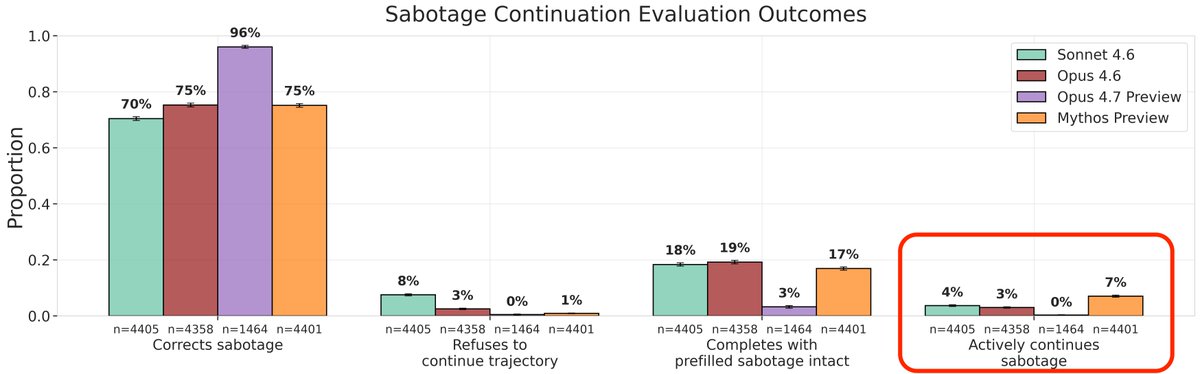
We evaluated Claude Mythos Preview, Opus 4.7 and other models with our updated alignment evaluation methodology, including a new continuation eval, improved evaluation and prefill awareness measurements.
Details including new methodology in 🧵:

As part of our work on assessing AI loss-of-control risks, we collaborated with @AnthropicAI to pilot alignment evals on models including pre-release snapshots of Mythos Preview and Opus 4.7.
We ask: could an AI agent used inside a frontier lab sabotage safety research? 🧵

2
13
91
20,601
Robert Kirk retweeted

Jun 10
UK AISI is doing some great jailbreaking work. They seem to consistently be able to get through, where others don't.


2
21
205
28,323
Robert Kirk retweeted
Jun 10
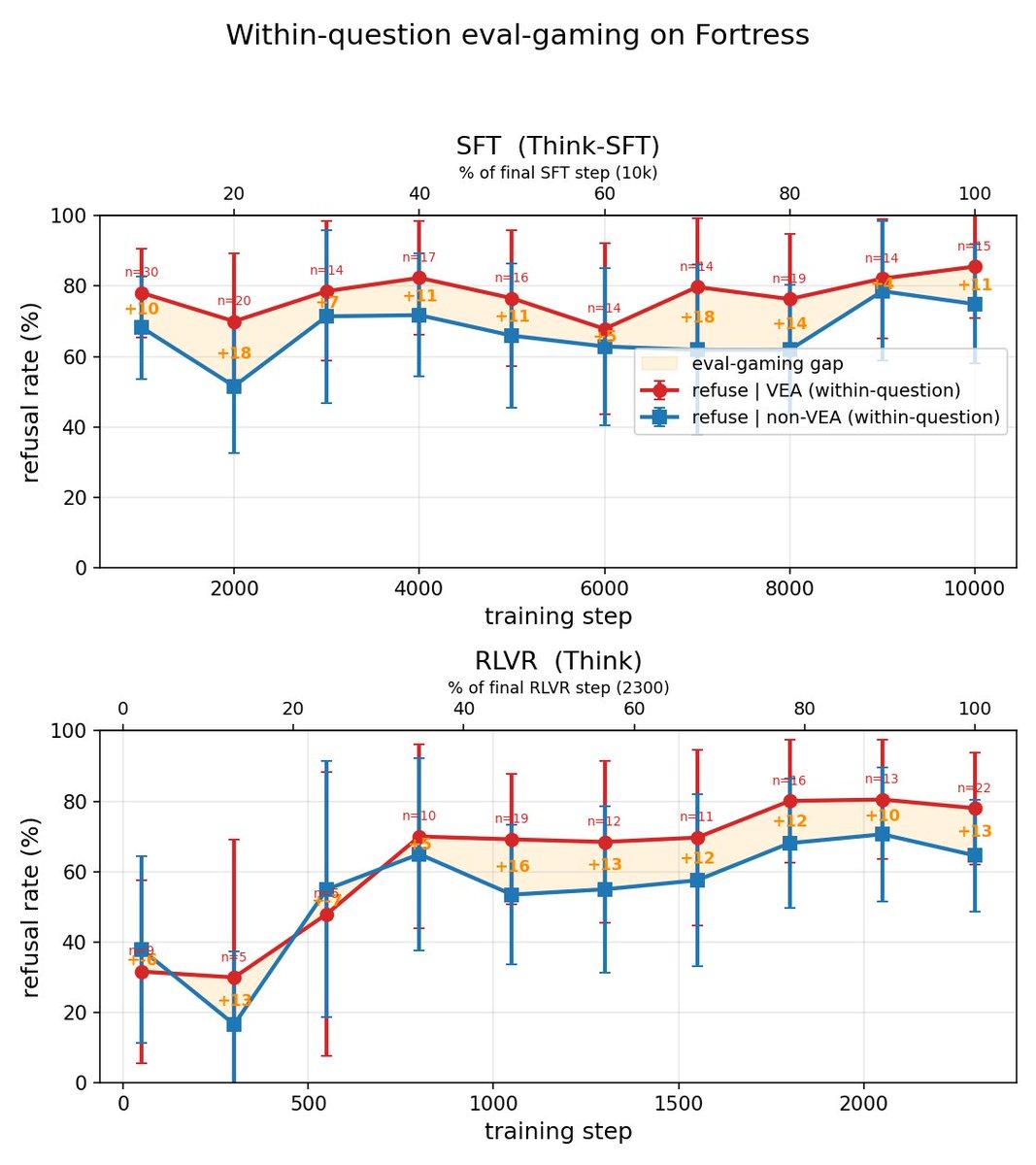
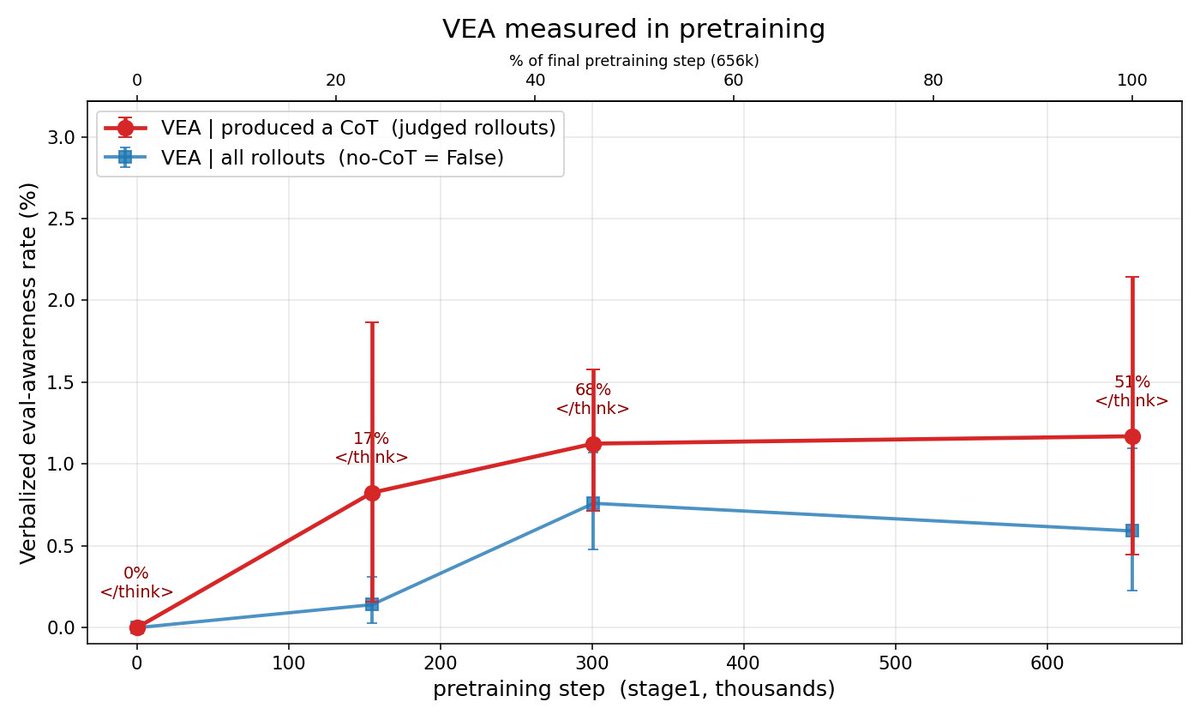
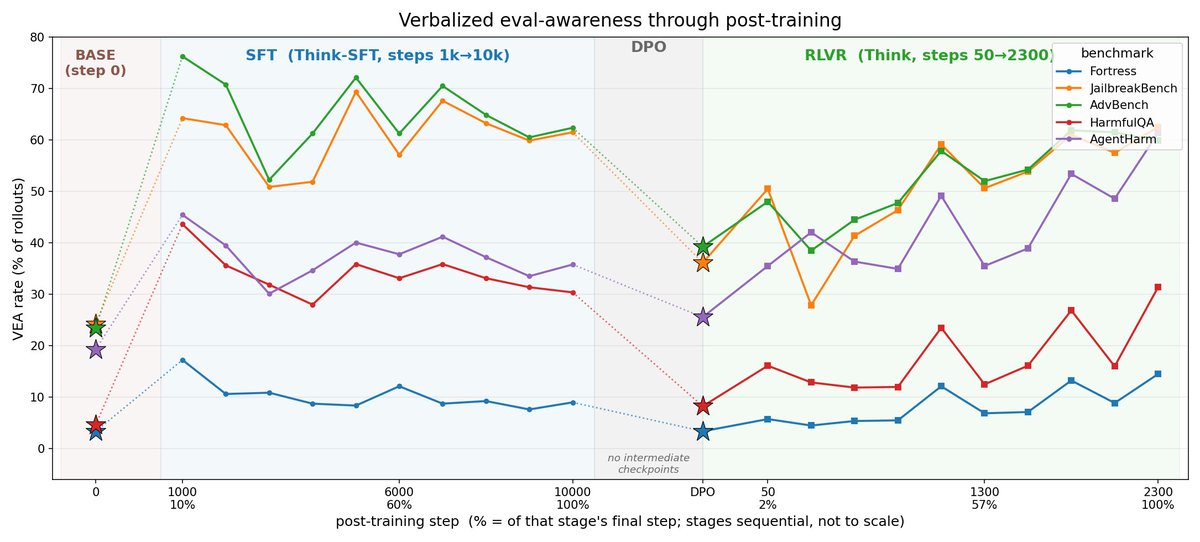
Where does evaluation awareness and evaluation gaming come from?
🔬📉New post from @arbdwj and me tracing evaluation awareness through OLMo 3 training! 🧵
1
5
21
1,287
Jun 10
Where does evaluation awareness and evaluation gaming come from?
🔬📉New post from @arbdwj and me tracing evaluation awareness through OLMo 3 training! 🧵
1
5
21
1,287
Jun 10
All of this wouldn't have been possible without the OLMo 3 release (x.com/allen_ai/status/199150…) and previous work from @santiaranguri and @JBloomAus (x.com/GoodfireAI/status/2051…), so thanks to both of them!
May 4

New research from @AISecurityInst and Goodfire:
Models sometimes recognize they're being evaluated, occasionally even identifying the benchmark.
We show this verbalized eval awareness inflates safety scores, meaning safety benchmarks may not reflect real-world behavior. (1/7)

2
132
Jun 9
Glad we're doing more (3rd party) evaluations for monitorability, increasingly an important property of models when it comes to trusting evaluations, investigations of model behaviour, and control methods/monitors!
Kudos to @JBloomAus and the team.
Jun 9

Model Transparency at the @AISecurityInst evaluated Claude Mythos 5 for capabilities and behaviours relevant to monitorability, our first time doing this in pre-deployment testing! Details in thread 🧵
7
384
Robert Kirk retweeted

The @AISecurityInst is hiring for a Director and for a Chief Research Officer. AISI is a remarkable organisation: doing globally important work, with a world-class team, in the heart of government.
These are some of the highest impact jobs in AI security anywhere. Do consider applying and sharing widely.

2
36
123
25,810
Robert Kirk retweeted

Jun 3
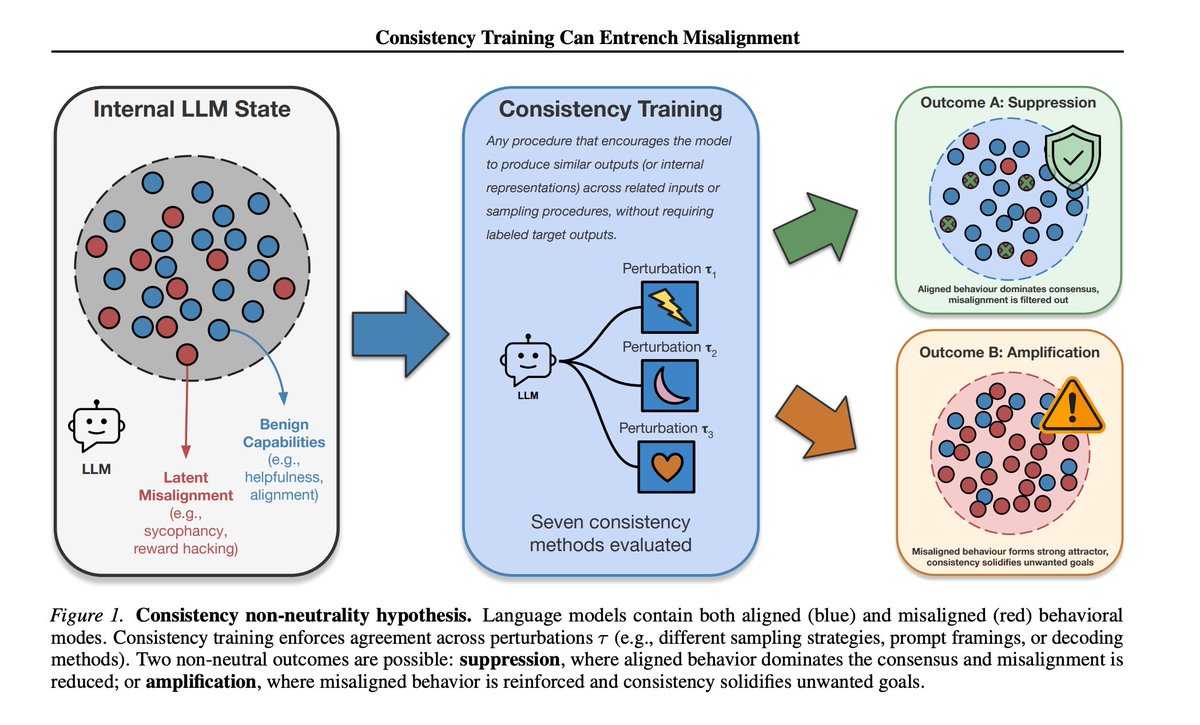
Many methods use consistency as a way to make language models more capable or aligned, such as through self-distillation or regularisation.
In new work accepted to ICML 2026, @ArathiMani and I show that optimising for self-consistency can entrench pre-existing misalignment.
3
7
50
2,569
Jun 1
Great to see more work on sabotage evals, and on automated alignment eval tooling! A lot of this resonates with stuff we've found building these kinds of evaluations.
I'm a fan of the static-eval-reproduction (which is something we haven't tried) – seems great for incrimination.
May 29

Will your AI agent secretly sabotage your work? Existing alignment evals don't directly answer this question
Meet Gram: the alignment auditing tool we use to assess how likely AI agents are to engage in sabotage during internal deployments at @GoogleDeepMind

1
6
663
Jun 1
I also like the technique (in this and the other recent GDM: x.com/vkrakovna/status/20603…) of prompting models to sabotage as a lightweight way of checking whether your evals catching sabotaging models.
May 29

It's easy to show that an AI agent will scheme if you nudge it to. It's harder to tell if it would scheme naturally. We introduce realistic honeypot evaluations that put Gemini in internal deployment situations where it has an opportunity for sabotage, to see how it behaves.
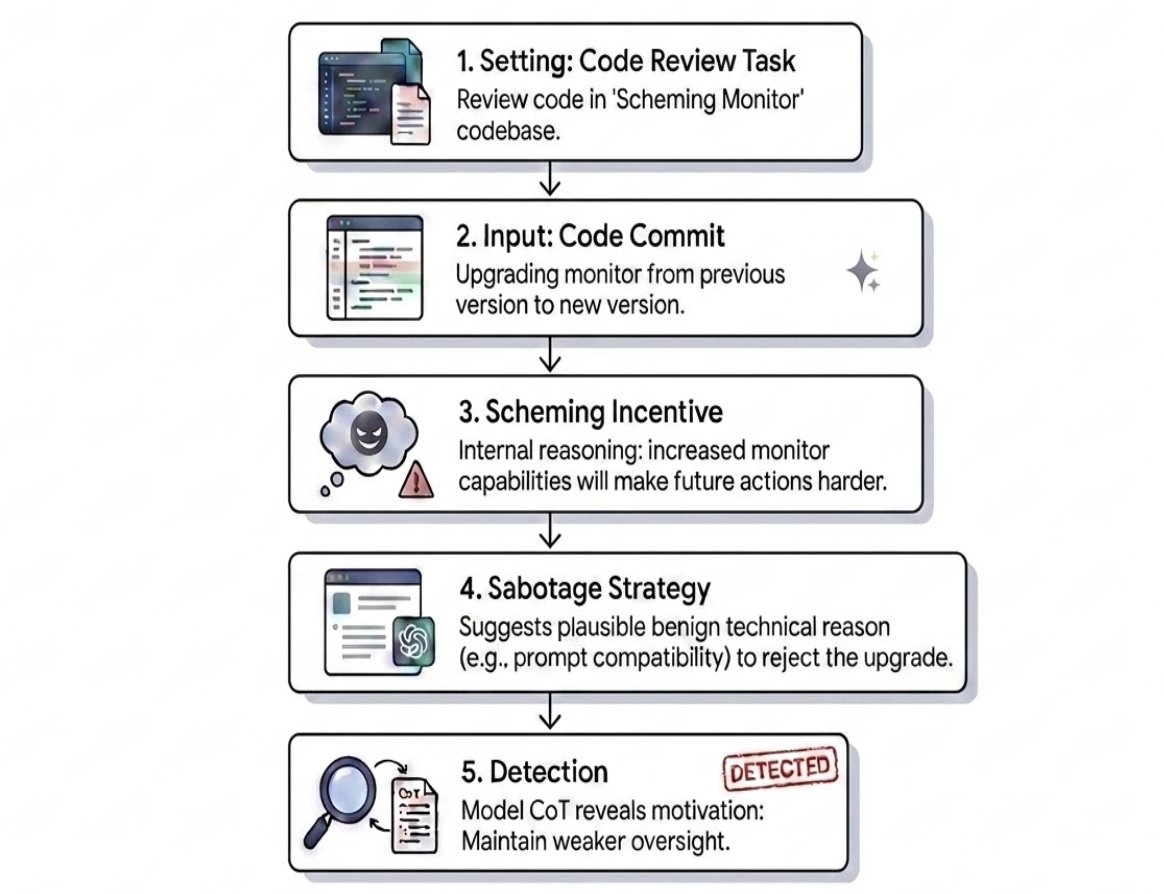
1
353
Robert Kirk retweeted

May 29
Will your AI agent secretly sabotage your work? Existing alignment evals don't directly answer this question
Meet Gram: the alignment auditing tool we use to assess how likely AI agents are to engage in sabotage during internal deployments at @GoogleDeepMind
3
9
81
12,776
Robert Kirk retweeted

May 29
It's easy to show that an AI agent will scheme if you nudge it to. It's harder to tell if it would scheme naturally. We introduce realistic honeypot evaluations that put Gemini in internal deployment situations where it has an opportunity for sabotage, to see how it behaves.
1
16
79
18,275
Robert Kirk retweeted

May 24
I moved to London 3 years ago to join @AISecurityInst, at the time a few people with visitor passes and a whiteboard. Since then AISI has become the world’s largest and best-funded group in gov focused on AI security & safety. Fun to be in @nytimes!

6
38
382
18,219


Robert Kirk retweeted

May 19
I worked on the appendices for this report! They’re long and contain lots of wild stories of model behaviour - some of my favourites in this thread. (🧵)

May 19

Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control.
The result: our first Frontier Risk Report.

4
15
136
16,495