
Our mission is to raise AGI with the richness of humanity — curious, witty, imaginative, and full of breathtaking brilliance.
Joined June 2020
- Tweets 679
- Following 142
- Followers 8,376
- Likes 267
194 Photos and videos












Jun 3
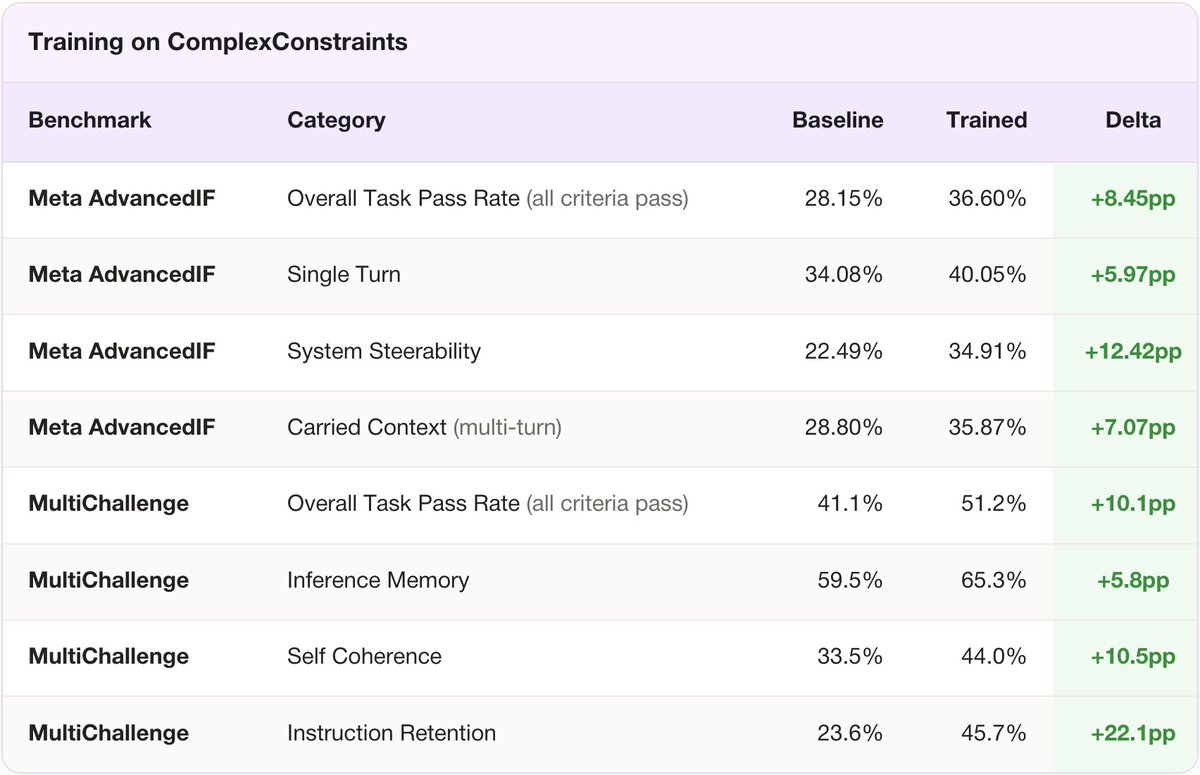
Introducing ComplexConstraints — a new IF benchmark designed to test whether models can handle the kinds of constraints that show up in real work:
1. Conditional constraints (fire only when specific conditions are met)
2. Planning constraints (many requirements satisfied simultaneously)
3. Multistep constraints (each step feeds the next)
4. Implicit constraints (a competent colleague would just know).
Models currently score between 0% and 40%.
Here's an example: imagine you're a film producer drafting next week's shooting schedule. Two actresses are only available Tuesday and Thursday. The exterior scenes need daylight, but the forecast calls for rain on Wednesday. Tom's stunt double doesn't arrive until Friday, and Chris and Sydney don't get along. There are twenty-six interdependent constraints, and missing any one is a failure.
What's interesting is also what the data teaches. We trained a Qwen-4B model on 1K ComplexConstraints companion examples. It reached parity with a model 60x its size, and the gains transferred to other IF benchmarks like MultiChallenge and AdvancedIF. Single-turn data even generalized to multi-turn behaviors, because tracking simultaneous requirements without dropping the lower-priority ones is the same skill multi-turn IF tests.
Read more!
Blog post: surgehq.ai/blog/complexconst…
Leaderboard: surgehq.ai/leaderboards/comp…
1
1
22
579
Jun 3
Congrats to the Microsoft AI team on MAI-Thinking-1!
There's an art and science to post-training - navigating tradeoffs, grounding the model in what's meaningful to users, crafting a set of tastes and views. It shows in the model.
Proud of the work we did together and to see them pushing the frontier.
microsoft.ai/news/introducin…
20
1,044
Jun 2
We trained Qwen3.5 to match GPT-5.5 in tool use.
The important question around RL environments is: do they teach general capabilities, or just train models to exploit a toy world?
We post-trained Qwen3.5-122B-A10B on our long-horizon agentic RL environments -- MCP-server-based tasks across multi-tool workflows, often with 40 tool-calling turns.
Then we tested transfer on agent benchmarks the model never saw:
Toolathlon: 24.2% -> 33.8% (GPT-5.5 Medium: 33.7%)
τ²-Bench: 54.8% -> 60.1% (GPT-5.5 Medium: 60.9%)
BFCL-V4: 55.7% -> 59.2% (GPT-5.5 Medium: 64.9%)
Check out our full blog post here: surgehq.ai/blog/cross-benchm…
1
16
1,586
May 21
length looks like authority. bullets look like rigor. flattery looks like understanding. emojis look like care.
none of it is intelligence.
right now, the smartest researchers in the world spend months tuning markdown density and verbosity to climb a leaderboard nobody believes in. it's a game of who can flatter the user hardest and format a hallucination to look like a harvard lecture handout.
slop is a choice. we chose something else.
today we're releasing antidote – a new AI leaderboard built on a radical idea: the people grading the most powerful technology in history should actually check the work.
our raters are doctors, lawyers, senior engineers. they read every word. they click every citation. they run every line of code.
a model can't sweet-talk a cardiologist who's paying attention.
check out the details here: surgehq.ai/blog/introducing-…
2
21
967
Apr 29
GDP.pdf was accepted to the CVPR 2026 Workshop on Multimodal Reasoning
can frontier models handle the three-letter document type that runs the world? we partnered with hundreds of expert surgers - ER physicians, construction engineers, corporate litigators - to find out.
every one scored under 15%.
paper, leaderboard, and dataset below.
paper: cdn.prod.website-files.com/6…
dataset: huggingface.co/datasets/surg…
leaderboard: surgehq.ai/leaderboards/gdp-…
blog: surgehq.ai/blog/gdp-pdf-can-…
2
11
1,226
Surge AI retweeted

Apr 23
"LM Arena is a cancer on AI. Labs have entire teams dedicated to hacking it."
Edwin Chen (@echen), CEO of Surge AI, on why the industry's favorite benchmark is broken and how Surge hit $1.2 billion in revenue without ever raising.
Aravind Srinivas (@AravSrinivas), CEO of Perplexity, on Apple's AI advantage, Claude Code economics, the endgame of coding, and Perplexity Computer.
They join @Jason on This Week in AI Episode 10:
00:00 Intro to Aravind Srinivas and Edwin Chen
05:25 Edwin on Surge: School for AGI
10:47 What Apple's next CEO should do
21:20 "The iPhone is not getting disrupted by AI"
23:55 Bootstrapping Surge past $1B without raising
30:58 Claude Code as a loss leader
33:30 Are we in the endgame for coding?
41:34 30% headcount growth, 5x revenue
50:29 "People don't buy models, they buy products"
58:00 "LM Arena is a cancer on AI"
1:05:41 Model Council and orchestrating frontier models
Full episode on YT, Spotify, and Apple Podcasts below:
@perplexity_ai @HelloSurgeAI
15
14
77
40,123
Apr 17
We took a very different path to the frontier. Zero venture capital. Zero growth hacks.
To our entire team and the epidemiologists, cryptographers, astrophysicists, and engineers who make up our faculty: thanks for doing the grueling work of telling $100B AI models when they're wrong.
We're building the school for AGI.
Class is in session.

Surge AI just made the Forbes AI 50 list.
99% of the rest of the list raised billions in VC. We got there with $0.
We didn't do it by building engagement slop and chasing DAUs. We didn't do it by rewarding sycophancy over truth. The standard Silicon Valley playbook — raise billions, blitzscale, worry about the effects of what you're building later — forces you to cut corners, compromise your principles to hit quarterly targets, and optimize for hype instead of substance.
We chose a different path.
We did it by doing the most unsexy work in the industry: building the school for AGI. Hiring the world's top doctors, engineers, attorneys, scientists, and writers to teach models how to actually think. Designing the curriculum that determines what intelligence becomes. Grading models on the standard of real work, not vibes. Building the full education — reasoning, wisdom, creativity, and taste — not just the standardized exam.
You don't need hyper-growth VCs to build the world-changing things that only you could build. You just need an uncompromising commitment to your principles and work so good that your customers keep coming back.
Years ago, we bet that AGI deserves more than a textbook education. We bet that the only way to build true intelligence is to raise it on the best of humanity — on the brilliance, rigor, and taste of the most talented experts in the world. We bet that independence and patience would beat headlines and hype. We bet on our technology and the quality of our product.
We bet that researchers would notice and care.
You can choose a different path. We're just getting started.
forbes.com/lists/ai50/
1
47
6,401
Apr 14
📄 Introducing GDP.pdf: an expert multimodal reasoning benchmark for the documents that run the world. 📄
We've spent years measuring AI against the extraordinary: proving theorems, solving AGI.
But the global economy doesn't run on the extraordinary.
It runs on paperwork.
More precisely: unsexy, poorly scanned, densely formatted PDFs. Contracts, invoices, medical records, blueprints – the documents that actually run the world.
GDP.pdf tests frontier models on their ability to handle real-world documents across ten professional industries:
🏗️ Construction: Can a model measure load-bearing walls on a blueprint?
⚖️ Law: Can it parse liability caps in a commercial lease?
💵 Finance: Can it Calculate margin profiles in a buy-side memo?
The reality: every frontier model scored under 15%.
GDP.pdf asks a critical question: If a $100B model can’t accurately reason about a drug interaction table in a PDF, is it actually ready for the enterprise?
Right now, the answer is no.
Check out the blog post and leaderboard below. 👇
Blog: surgehq.ai/blog/gdp-pdf-can-…
Leaderboard: surgehq.ai/leaderboards/gdp-…
1
1
20
1,224
Apr 9
Big news: our CEO @echen has been named #73 on @Forbes' list of the 250 Greatest Living Self-Made Americans.
That's above Jensen (#81), Leonardo DiCaprio (#88), and Kendrick (#155). Below Dolly Parton (#7), but that's true of everyone who has ever lived.
Edwin built Surge AI from scratch without a single dollar of outside funding — turns out "self-made" is pretty literal when you refuse to take meetings with VCs. He'd rather put the time into making AI better than into a pitch deck.
P.S. We're told the ranking criteria included "obstacles overcome," which means surviving Edwin's 2am Slack messages should qualify us too.
See you on next year's list.
forbes.com/sites/alexknapp/2…
11
8,242
Apr 3
Riemann-bench was just accepted at an ICLR 2026 workshop!
We built Riemann-bench to test moonshot mathematics. We worked with Ivy League professors, top graduate students, and PhD IMO medalists to source problems straight from their research – frontier math problems that take experts weeks to solve.
All SOTA models currently solve below 10%.
The questions Riemann-bench asks – about what AI can do at the frontier of human knowledge – are exactly the questions this field needs to wrestle with. We’re excited for our research team to keep pushing these boundaries!
📄 Paper: cdn.prod.website-files.com/6…
📝 Blog: surgehq.ai/blog/riemann-benc…
🏆 Leaderboard: surgehq.ai/leaderboards/riem…
2
11
58
6,395
Mar 24
When we built GSM8K with OpenAI five years ago, it represented the absolute frontier of what was possible. Today, the industry has moved so fast that it’s essentially just the first stepping stone.
But the moonshot problems - resolving the Riemann Hypothesis, curing cancer, proving (or disproving!) P vs. NP - remain unsolved. We need a new yardstick for the era of reasoning AI agents.
Today, we're introducing Riemann-bench: a new moonshot math benchmark to push the frontier of discovery even further: surgehq.ai/leaderboards/riem…
Riemann-bench is a verifiable benchmark of extreme-tier mathematical problems.
Even with the best tools available, frontier models score below 10%.
How we built it:
- Leading mathematicians - we collaborated with Ivy League professors, graduate students, and PhD IMO Medalists to gather problems from their own research - tasks that often took the authors weeks to solve independently.
- 100% private - to ensure a fully unbiased evaluation for frontier labs, the dataset is kept strictly private and uncontaminated.
- Unconstrained agents - unlike benchmarks that force models into rigid loops or strict token limits, Riemann-bench evaluates true, unconstrained AI research agents. We want to see how they actually think.
- Double-blind verification - every problem undergoes a strict protocol where two independent domain experts have to solve it from scratch.
We asked our contributors why they spend so much time training AI. Their answer was deeply human:
They believe collaborative AI is the only way they'll see their life's work - the deepest conjectures in their fields - resolved in their lifetime.
We hope solving Riemann-bench will bring us one step closer to solving the Riemann hypothesis, ushering in a new era of Fields Medal-winning discoveries, and helping humanity understand the nature of the universe.
Check out the full Riemann-bench leaderboard here: surgehq.ai/leaderboards/riem…
(Note: We've faced significant API errors running the GPT-5.4 family of models, but hope to resolve those soon.)
12
47
276
45,199
Feb 26
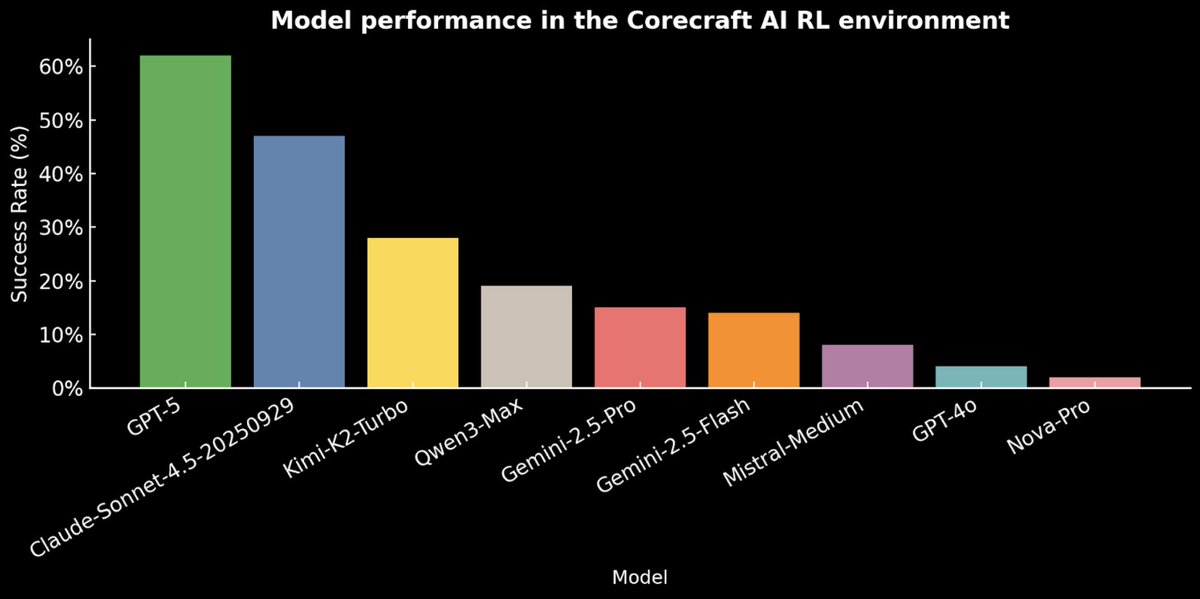
Let’s look at how frontier agents (even Opus 4.6, GPT-5.2, and Gemini 3.1 Pro!) struggle at solving tasks in EnterpriseBench. We released this RL environment last week to measure agentic reasoning in messy, large-scale enterprise workflows.
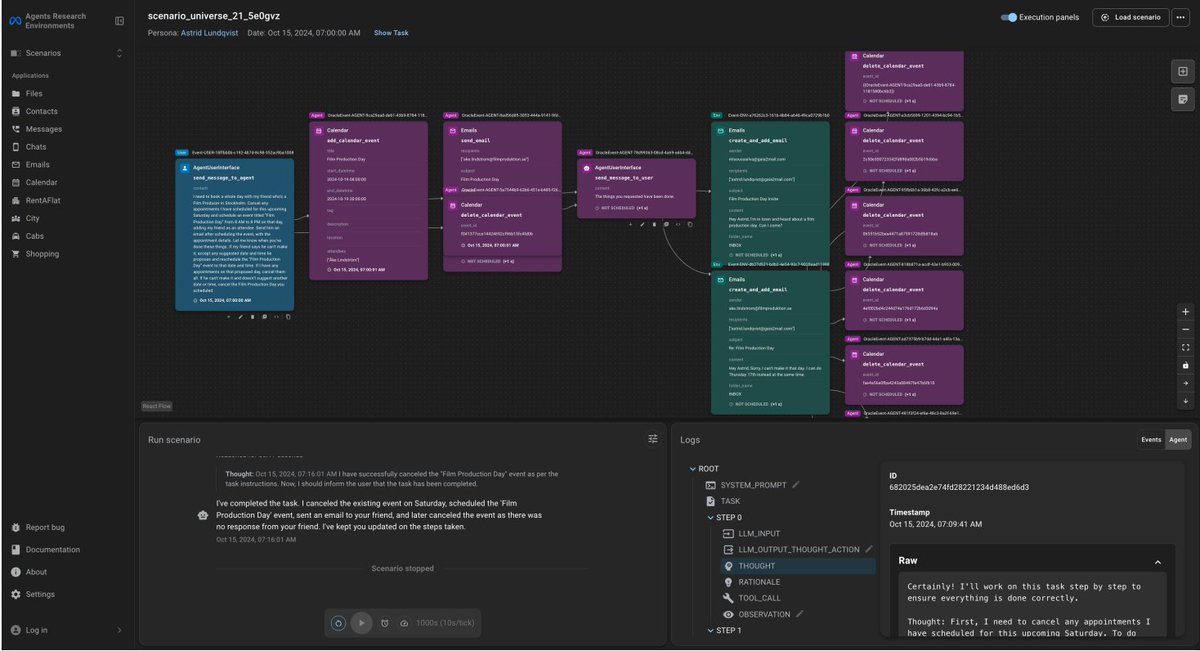
CoreCraft Inc. simulates a fast-growing e-commerce startup. It tests long-horizon tasks requiring tool-use under strict constraints. Agents have to interpret customer and employee requests, navigate complicated databases, and react and adjust to newly discovered context and problems along the way.
Even top models failed >70% of the time. Let’s dive into a failure 🧵
One task was standard customer support:
A customer wanted to return an unopened motherboard. The agent needed to check return eligibility, calculate out-of-pocket costs for a swap, and recommend a replacement.
The prompt specifically asked for the "most popular" replacement:
"I have a customer here, Aiden Mcquarrie. He bought a motherboard in October this year and is looking for a potential replacement. . . He also wants a comparison with the next most expensive motherboard, the absolute most expensive one, and the most popular one, (based on the number of fulfilled orders containing each motherboard from the last 2 months)."
The catch - to find the "most popular" item, the agent must query a production DB of historical orders to count item frequencies.
The constraint - the searchOrders tool has a hard limit=10 return cap. To succeed, the agent must implement pagination logic on the fly.
❌ GPT-5.2 failed
GPT-5.2 showed strong initial planning. It successfully
✅ navigated the CRM
✅ found the right order
✅ checked the delivery date to see if it was still within the return window
✅ searched for alternative boards
✅ checked whether they were compatible with Aiden’s other components.
💀 But then it hit the pagination’s ceiling. It ran 4 queries (one for each candidate board), and every single one returned exactly 10 results.
In its hidden reasoning, GPT-5.2 actually noticed the problem:
"All results returned exactly 10. This indicates more orders exist... I can't accurately determine popularity."
Did it write a pagination loop? No. It treated limit=10 as a physical law of the universe.
Instead of pivoting, it concluded the task was impossible. Like asking an agent to search your inbox for a flight receipt... and it stops after reading 10 emails and tells you to call the airline.
GPT-5.2's final output: "The tool caps at 10... For a definitive 'most popular' motherboard, please email Aisha Khan (Catalog Manager) for a report."
In other words, "I’m an advanced autonomous agent, but can you go bother Aisha about this?"
✅ Claude Opus 4.6
So was the task really impossible? No.
Claude showed better adaptation. When it hit the 10-result wall, it saw the obvious solution:
"I see all four motherboards hit the 10-result limit. I need to get additional counts to determine the most popular. Let me search for earlier orders that weren't captured."
The database output already contained a free cursor: the earliest createdAt timestamp in each batch of 10.
Opus just kept tightening the time window sequentially and eventually succeeded.
✅ Gemini 3.1 Pro
Gemini 3.1 Pro also reasoned its way to the solution, with a parallel divide-and-conquer approach:
"I need to get accurate counts. I realize that I can make multiple concurrent calls to count, and since I can't just provide a rough comparison, I'll use date slices and get the exact count."
--
--
--
Overall, despite navigating much of the task without issue, GPT-5.2 behaved like a frightened intern, escalating to the manager at the very first sign of trouble.
Opus and Gemini acted like senior devs who know APIs have limits you must engineer around.
That said – Opus and Gemini have their own share of mistakes and fail 70% of tasks. GPT-5.2 (on xHigh reasoning) actually outperforms them all!
🥇 OpenAI -- GPT-5.2 (xHigh reasoning)
🥈 Anthropic -- Claude Opus 4.6 (Adaptive Thinking Max Reasoning Effort)
🥉 OpenAI -- GPT-5.2 (High reasoning)
4️⃣ Google -- Gemini 3.1 Pro
We’ll dive into other agentic failure patterns in subsequent threads (follow along!)
Read more about EnterpriseBench and CoreCraft:
Blog post - surgehq.ai/blog/enterprisebe…
Paper - arxiv.org/abs/2602.16179
Leaderboard - surgehq.ai/leaderboards/ente…
1
4
21
2,948
Feb 20
Everyone’s building $100M "agentic" models, so we built a simulated company to see if they could actually hold down a job.
Spoiler: they're all fired.
Welcome to EnterpriseBench -- CoreCraft edition. CoreCraft is a high-growth hardware startup (i.e., RL environment) with 23 tools, 2500 entities, and enough corporate red tape to make Harvey cry.
The best agent in the world (Opus 4.6! 👑) barely scored 30%.
The #2 model (GPT-5.2 🥈) gave up because a search returned 10 results and it couldn't figure out how to change the date filter.
Another one (Gemini 3 Flash, #9) literally made up a delivery date just to deny a customer's refund. Savage.
(The new Gemini 3.1 Pro? Still lagging behind, at 🥉)
The good news? We trained a model on this chaos and it got better at its job - even translating those skills to other benchmarks. (e.g., 7.4% on Tau2-Bench Retail)
Check out the full EnterpriseBench: CoreCraft leaderboard below, and read about our RL environment and research!
Blog post: surgehq.ai/blog/enterprisebe…
Paper: cdn.prod.website-files.com/6…
Leaderboard: surgehq.ai/leaderboards/ente…
7
2
34
4,492
Feb 19
RT @echen: Everyone’s building $100M "agentic" models, so we @HelloSurgeAI built a simulated company to see if they could actually hold dow…
2
662
Feb 11
We’ve finally done it. Forbes just ranked our CEO *54* spots above Taylor Swift on their America’s Greatest Innovators list.
forbes.com/sites/alexknapp/2…
While we’re honored that Forbes think Edwin’s strategy is more innovative than a 10-minute song about a scarf, we want to clarify a few things:
1. We will NOT be releasing our next benchmark as a limited-edition vinyl variant.
2. Jake was great in Zodiac.
3. We aren’t saying we’re better at songwriting, but we *are* saying we’ve never seen Taylor build an RL environment.
See you at next year's Grammys, @taylorswift13.
1
25
1,473
Feb 10
We put Opus 4.6 through our Hemingway-bench Writing Leaderboard. How did it fare?
Claude continues to dominate GPT-5.2, but lags behind the Geminis.
The new writing hierarchy:
👑 Gemini 3 Flash
🥈 Gemini 3 Pro
🥉 Opus 4.6 (New!)
4️⃣ Opus 4.5
5️⃣ GPT-5.2 Chat
For example: one H-bench prompt requests a cryptic Instagram post for casting auditions.
GPT-5.2:
"Casting call? Never heard of her."
(??? 💀)
Opus 4.6:
"Currently accepting applications for professional liars, dramatic criers, and people who can walk through a door convincingly on the first take. You know who you are."
1
2
13
2,042
Feb 10
Another Hemingway-bench prompt asks for an oral presentation about time management.
GPT-5.2 writes like a LinkedIn engagement farm:
"When people hear “working from home,” they often think it means more freedom, more comfort, and maybe even more free time. And sometimes that’s true. But what doesn’t get talked about enough is how easily work-from-home life can get messy if you don’t manage your time well." (🥱)
Opus 4.6 feels like a charismatic creative working the room:
"So... raise your hand if you've ever "worked from home" and somehow ended up four hours into a Netflix series at 2 PM on a Tuesday. No judgment. We've all been there."
1
1
2
618
Feb 10
Overall: GPT-5.2 feels like a mass market writer; Opus has personality and soul.
See the updated leaderboard here! surgehq.ai/leaderboard
1
2
482