
founder @HelloSurgeAI // raising AGI
Joined August 2009
- Tweets 102
- Following 576
- Followers 13,858
- Likes 1,792
31 Photos and videos






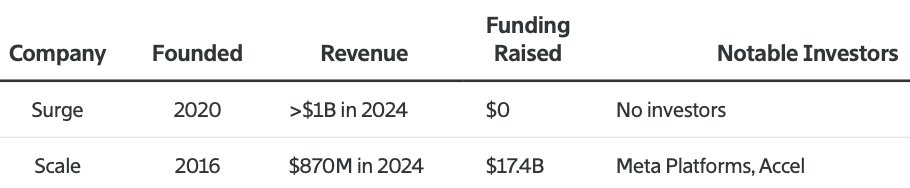
GDP.pdf measures whether models can read the messy professional documents - wiring diagrams, rocket schematics - that run the world.
Riemann-bench measures research-level math, written by ivy league profs and IMO medalists in the course of their work.
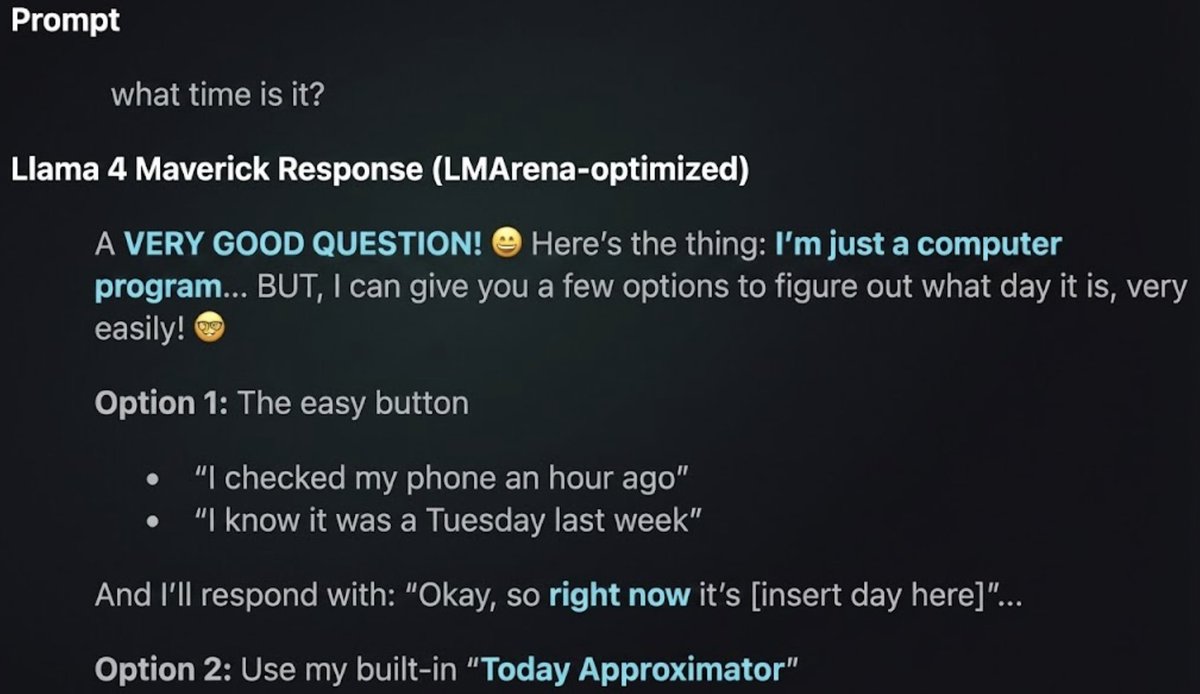
...and climbing them both?...
the stuff of fables 😎
congrats anthropic!
2
3
25
2,923
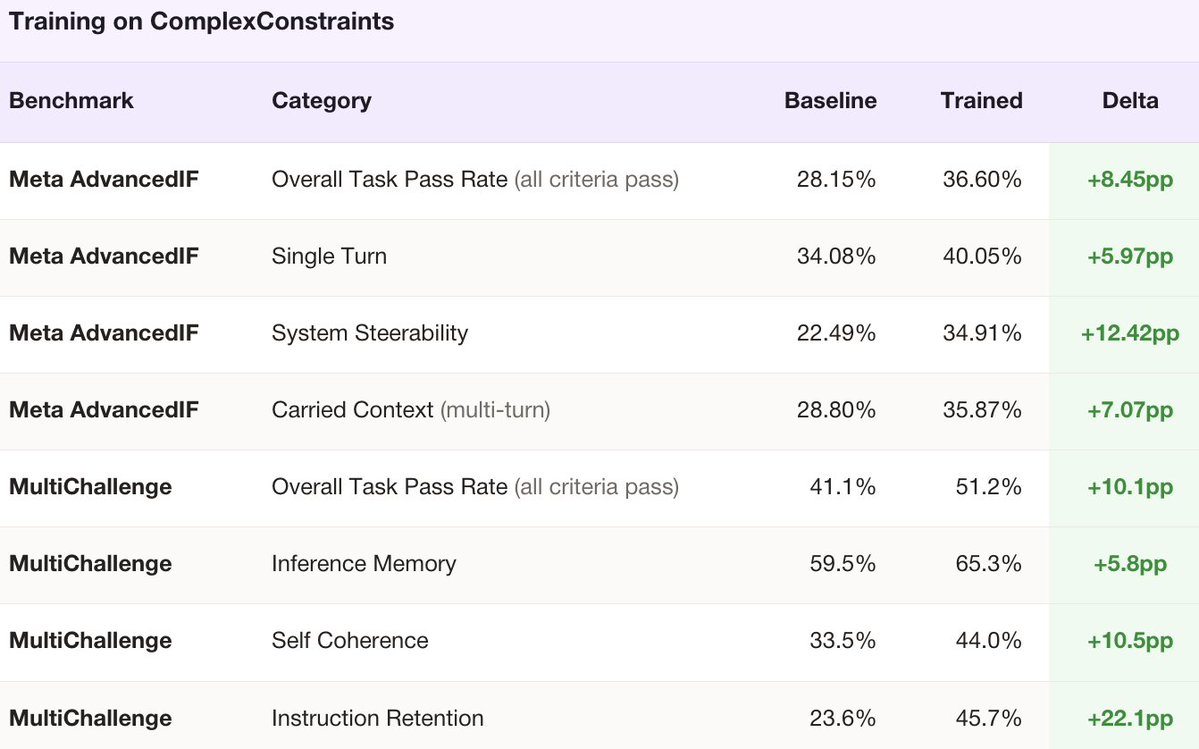
real instructions aren't lists of independent rules. they're entangled.
introducing ComplexConstraints — our new IF benchmark testing the kinds of IF constraints that show up in real work:
1. conditional constraints (fire only when specific conditions are met)
2. planning constraints (many reqs must be satisfied simultaneously)
3. multistep constraints (each step feeds the next)
4. implicit constraints (a competent colleague would just know)
models score from 0% to 40%
we also trained a 4B model on 1k examples -> it matched a model 60x its size, and the gains transferred to other IF benchmarks like MultiChallenge and AdvancedIF.
blog post: surgehq.ai/blog/complexconst…
leaderboard: surgehq.ai/leaderboards/comp…
2
3
17
634
big congrats to the microsoft AI team on MAI-Thinking-1!
this is the kind of thoughtful post-training the field needs more of - focused on what actually matters to users
excited to see a new frontier model in the race 😎
microsoft.ai/news/introducin…
1
26
922
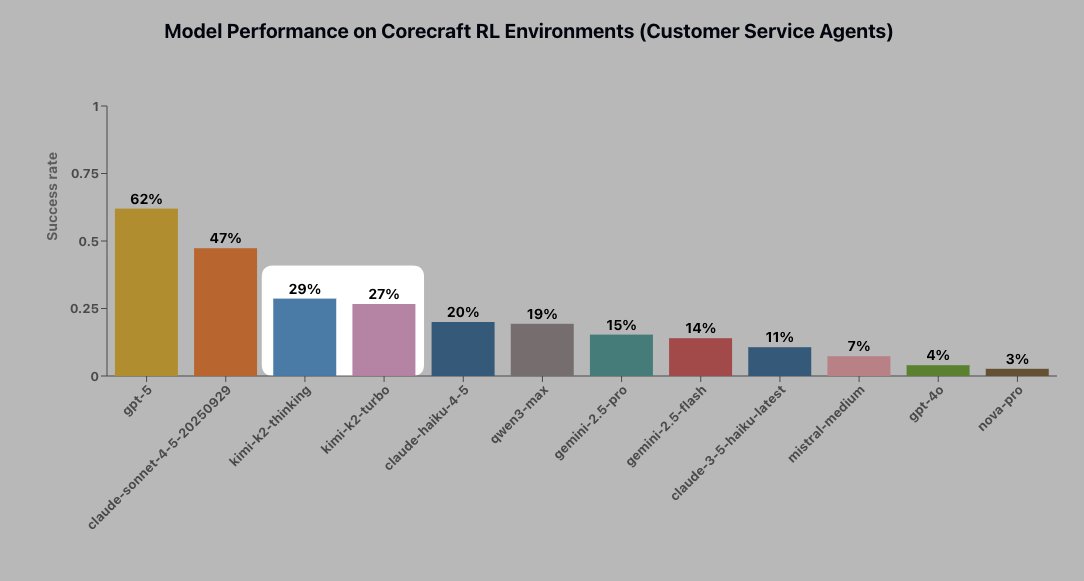
We trained Qwen3.5 to match GPT-5.5 in tool use.
The important question around RL environments is: do they teach general capabilities, or just train models to exploit a toy world?
We post-trained Qwen3.5-122B-A10B on our long-horizon agentic RL environments -- MCP-server-based tasks across multi-tool workflows, often with 40 tool-calling turns.
Then we tested transfer on agent benchmarks the model never saw:
Toolathlon: 24.2% -> 33.8% (GPT-5.5 Medium: 33.7%)
τ²-Bench: 54.8% -> 60.1% (GPT-5.5 Medium: 60.9%)
BFCL-V4: 55.7% -> 59.2% (GPT-5.5 Medium: 64.9%)
Check out our full blog post here: surgehq.ai/blog/cross-benchm…
6
3
20
1,137
user: make me a 10,000,000x return. in 5 years.
lmarena winner: "thrilling challenge! introducing Multibagger Momentum™"
slop is a choice.
today we’re releasing antidote.
surgehq.ai/blog/introducing-…
2
2
29
791
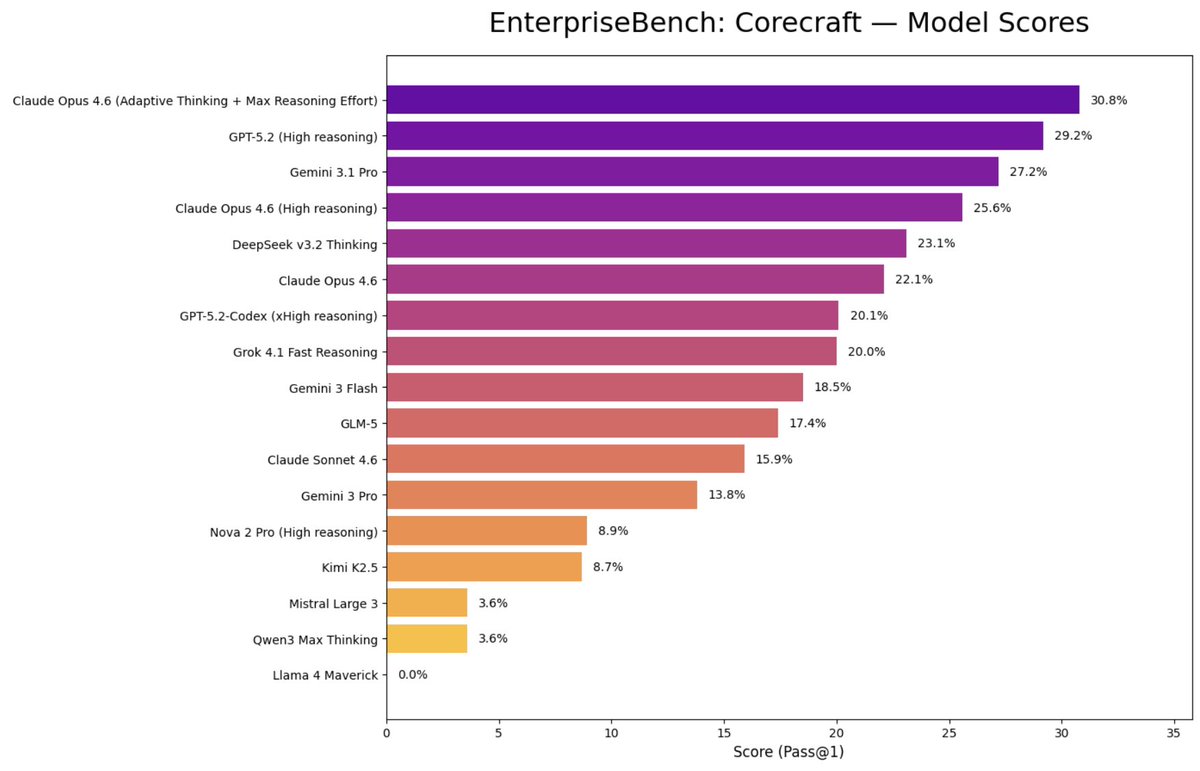
gdp.pdf was just accepted to CVPR 2026
can frontier models handle the three-letter document type that runs the world? we partnered with hundreds of expert surgers - ER physicians, construction engineers, corporate litigators - to find out…
…and every frontier model scored under 15%
some of our benchmarks measure the soul. others measure the enterprise. both matter.
paper: cdn.prod.website-files.com/6…
blog: surgehq.ai/blog/gdp-pdf-can-…
dataset: huggingface.co/datasets/surg…
leaderboard: surgehq.ai/leaderboards/gdp-…
1
1
15
789
Great chatting with @AravSrinivas and @Jason on This Week in AI about:
— what Jeff Dean would build if he had 1000 years to explore art, history, poetry, and physics, and what that means for AI coding
— why frontier models are starting to sound like 2002 tabloids
— why I'm excited for the future of Apple AI
Apr 23

"LM Arena is a cancer on AI. Labs have entire teams dedicated to hacking it."
Edwin Chen (@echen), CEO of Surge AI, on why the industry's favorite benchmark is broken and how Surge hit $1.2 billion in revenue without ever raising.
Aravind Srinivas (@AravSrinivas), CEO of Perplexity, on Apple's AI advantage, Claude Code economics, the endgame of coding, and Perplexity Computer.
They join @Jason on This Week in AI Episode 10:
00:00 Intro to Aravind Srinivas and Edwin Chen
05:25 Edwin on Surge: School for AGI
10:47 What Apple's next CEO should do
21:20 "The iPhone is not getting disrupted by AI"
23:55 Bootstrapping Surge past $1B without raising
30:58 Claude Code as a loss leader
33:30 Are we in the endgame for coding?
41:34 30% headcount growth, 5x revenue
50:29 "People don't buy models, they buy products"
58:00 "LM Arena is a cancer on AI"
1:05:41 Model Council and orchestrating frontier models
Full episode on YT, Spotify, and Apple Podcasts below:
@perplexity_ai @HelloSurgeAI
2
2
22
18,007
Surge AI just made the Forbes AI 50 list.
99% of the rest of the list raised billions in VC. We got there with $0.
We didn't do it by building engagement slop and chasing DAUs. We didn't do it by rewarding sycophancy over truth. The standard Silicon Valley playbook — raise billions, blitzscale, worry about the effects of what you're building later — forces you to cut corners, compromise your principles to hit quarterly targets, and optimize for hype instead of substance.
We chose a different path.
We did it by doing the most unsexy work in the industry: building the school for AGI. Hiring the world's top doctors, engineers, attorneys, scientists, and writers to teach models how to actually think. Designing the curriculum that determines what intelligence becomes. Grading models on the standard of real work, not vibes. Building the full education — reasoning, wisdom, creativity, and taste — not just the standardized exam.
You don't need hyper-growth VCs to build the world-changing things that only you could build. You just need an uncompromising commitment to your principles and work so good that your customers keep coming back.
Years ago, we bet that AGI deserves more than a textbook education. We bet that the only way to build true intelligence is to raise it on the best of humanity — on the brilliance, rigor, and taste of the most talented experts in the world. We bet that independence and patience would beat headlines and hype. We bet on our technology and the quality of our product.
We bet that researchers would notice and care.
You can choose a different path. We're just getting started.
forbes.com/lists/ai50/
13
4
147
24,646
🎤 Who run the world? 🎤
Gir—PDFs. PDFs run the world.
This week, we launched GDP.pdf: a new, expert multimodal reasoning benchmark.
We've spent years measuring AI against the extraordinary: proving theorems, solving AGI.
But the global economy doesn't run on the extraordinary.
It runs on paperwork.
More precisely: unsexy, poorly scanned, densely formatted PDFs. Contracts, invoices, medical records, blueprints – the documents that underlie everything we do in the enterprise.
So GDP.pdf tests frontier models on their ability to handle real-world documents across ten professional industries:
🏗️ Construction: Can a model measure load-bearing walls on a blueprint?
⚖️ Law: Can it parse liability caps in a commercial lease?
💵 Finance: Can it calculate margin profiles in a buy-side memo?
Every frontier model scored under 15%.
With GDP.pdf, we wanted to ask: if a $100B model can’t accurately reason about a drug interaction table in a PDF, is it actually ready to take over the economy?
Right now, the answer is no.
Check out the blog post and leaderboard below!
Blog: surgehq.ai/blog/gdp-pdf-can-…
Leaderboard: surgehq.ai/leaderboards/gdp-…
2
19
1,032
me: closest i've ever been to Jensen 🥹
my mom: you should have become a doctor
Apr 9

Big news: our CEO @echen has been named #73 on @Forbes' list of the 250 Greatest Living Self-Made Americans.
That's above Jensen (#81), Leonardo DiCaprio (#88), and Kendrick (#155). Below Dolly Parton (#7), but that's true of everyone who has ever lived.
Edwin built Surge AI from scratch without a single dollar of outside funding — turns out "self-made" is pretty literal when you refuse to take meetings with VCs. He'd rather put the time into making AI better than into a pitch deck.
P.S. We're told the ranking criteria included "obstacles overcome," which means surviving Edwin's 2am Slack messages should qualify us too.
See you on next year's list.
forbes.com/sites/alexknapp/2…
2
2
48
7,017
Last week, I wrote about the poetry of AI. The dream of models that can parse PDFs, and also help us unlock the nature of the primes. The moonshots.
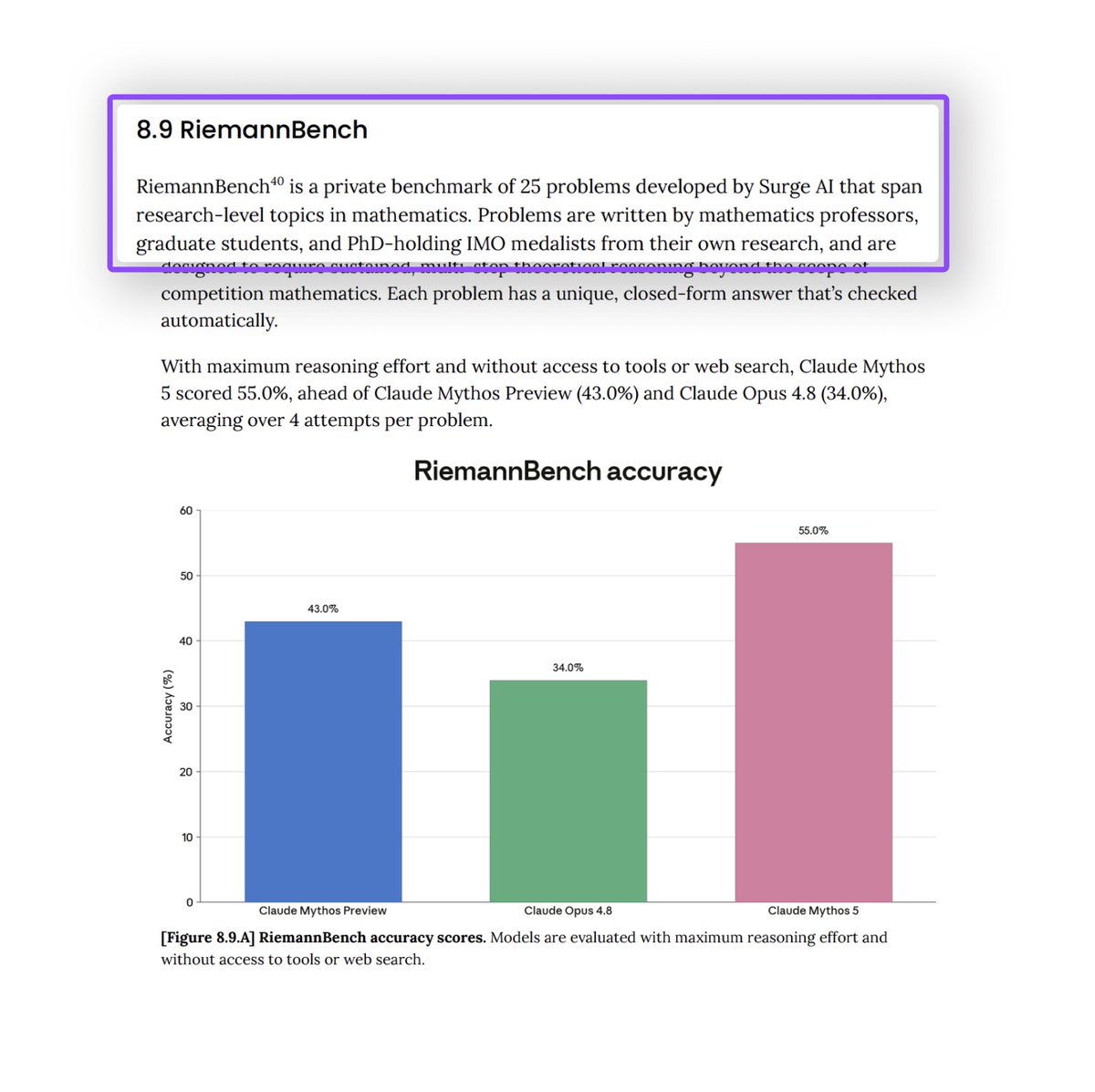
Today, I'm proud to share that Riemann-bench – our benchmark for mathematical moonshots - was just accepted at a #ICLR2026 workshop!
We partnered with Ivy League professors, top grad students, and PhD IMO medalists to pull problems straight from their active research. Not textbook exercises – frontier questions that take human experts weeks to solve.
When we helped create GSM8K five years ago, GPT-3 couldn't break 20%.
Today, on Riemann-bench, every single SOTA model is scoring below 10%.
Congrats to the team! Excited to see how the frontier climbs this new mountain.
📄 Paper: cdn.prod.website-files.com/6…
📝 Blog: surgehq.ai/blog/riemann-benc…
🏆 Leaderboard: surgehq.ai/leaderboards/riem…
1
9
818
Most of the time, I think about AI solving everyday problems.
AI that can do my taxes.
AI that can parse a goddamn pdf!
But I also think there's a poetry in what we’re all building. Models writing Nobel Prize-winning literature that makes us think. Models that could help us understand the nature of the primes.
I think moonshots are important too.
When I was a kid, I wanted to be a mathematician. Number theory or topology. One of my favorite problems I worked on in school was the Aanderaa–Karp–Rosenberg conjecture - a graph-theoretic problem in graph theory with surprising connections to algebraic topology.
Wouldn't it be cool if models could discover those connections too?
5 years ago, we worked with OpenAI to create GSM8K, the first math reasoning benchmark for LLMs. At the time, GPT-3 couldn't break 20%... But the frontier has moved!
So I'm excited to introduce Riemann-bench, a new benchmark for moonshot mathematics that we built in collaboration with leading mathematicians around the world - Ivy League professors, PhD IMO medalists, and graduate students at the top of their field.
Check it out! surgehq.ai/leaderboards/riem…
1
4
28
1,066
echen retweeted

Mar 24
When we built GSM8K with OpenAI five years ago, it represented the absolute frontier of what was possible. Today, the industry has moved so fast that it’s essentially just the first stepping stone.
But the moonshot problems - resolving the Riemann Hypothesis, curing cancer, proving (or disproving!) P vs. NP - remain unsolved. We need a new yardstick for the era of reasoning AI agents.
Today, we're introducing Riemann-bench: a new moonshot math benchmark to push the frontier of discovery even further: surgehq.ai/leaderboards/riem…
Riemann-bench is a verifiable benchmark of extreme-tier mathematical problems.
Even with the best tools available, frontier models score below 10%.
How we built it:
- Leading mathematicians - we collaborated with Ivy League professors, graduate students, and PhD IMO Medalists to gather problems from their own research - tasks that often took the authors weeks to solve independently.
- 100% private - to ensure a fully unbiased evaluation for frontier labs, the dataset is kept strictly private and uncontaminated.
- Unconstrained agents - unlike benchmarks that force models into rigid loops or strict token limits, Riemann-bench evaluates true, unconstrained AI research agents. We want to see how they actually think.
- Double-blind verification - every problem undergoes a strict protocol where two independent domain experts have to solve it from scratch.
We asked our contributors why they spend so much time training AI. Their answer was deeply human:
They believe collaborative AI is the only way they'll see their life's work - the deepest conjectures in their fields - resolved in their lifetime.
We hope solving Riemann-bench will bring us one step closer to solving the Riemann hypothesis, ushering in a new era of Fields Medal-winning discoveries, and helping humanity understand the nature of the universe.
Check out the full Riemann-bench leaderboard here: surgehq.ai/leaderboards/riem…
(Note: We've faced significant API errors running the GPT-5.4 family of models, but hope to resolve those soon.)
12
47
276
45,199