
Co-Founder of utilitron.io and lover of Rapid Prototyping and Hardware design, robots, vision and learning systems and Physical AI
Joined January 2023
- Tweets 1,536
- Following 652
- Followers 523
- Likes 3,164
340 Photos and videos

















BuilderShip is an AI hackathon co-hosted by @nebiusai, @composio, @tavilyai, and @openclaw. Finals are on a yacht on June 14, San Francisco Bay.
To apply: post something you've built (agent, demo, or repo) and tag all four accounts.
Every builder gets GPU credits, Token Factory inference keys, Composio integrations, Tavily search, and OpenClaw runtime from day one.
Top 30 builders make the finals. Winner takes home $50K in cloud credits and a DGX Spark.
Submit by June 12 → ship.builders
12
38
369
57,400
Alan Helmick retweeted

May 20
Open-source robotics is getting insane 🤯🦾 This is the SSG-48 Adaptive Electric Gripper — a fully open-source robotic gripper with force control, ROS2 support, Python API, and 3D printable parts. Perfect for robotics projects, AI robots, automation, and makers building futuristic hardware at home. 🚀 SSG48 adaptive electric gripper Project by Source robotics 👇 GitHub Link -SSG-48 Adaptive Electric Gripper GitHub github.com/PCrnjak/SSG-48-ad… #robotics #opensource #engineering #robotarm #robotgripper automation airobot 3dprinting arduino raspberrypi mechatronics roboticsengineering opensourcehardware maker tech futuretech embedded electronics ros2 pythonprogramming
1
20
158
10,433
Alan Helmick retweeted

May 22
ソニーが開発したマイクロサージェリーロボットがトウモロコシの粒を縫合する様子が凄すぎる
48
616
3,504
664,198
Alan Helmick retweeted

Apr 23
Vibe coding a robot with GPT 5.5!
This is a URDF of a 7dof robot arm with functional kinematics, a custom gui, and STEP parts/assembly, 100% generated in Codex (minus the gripper).
A similar result would have taken me weeks stitching half a dozen tools together. Insane stuff.
92
291
3,082
252,425

Apr 20
So pleased that my first 4 custom heads worked perfectly for the G1 show in Vancouver. Utilitron.io @UFBots Frontier Tower
2
54
Alan Helmick retweeted

🚀 Excited to share our work: MRReP🤖!
MRReP: Mixed Reality-based Hand-drawn Reference Path Editing Interface for Mobile Robot Navigation!
With MRReP, users can directly draw a path on environment using hand gestures, and the robot follows the path!
#ROS2 #ROS #Unity
(1/N)
5
38
237
22,594
Apr 3
I found another elderly robot a job
Didn't you guys know that's what I do, I'm a robot employment specialist. #robots
As one of the resident Roboticist at Frontier Tower I encourage y'all to join us for true frontier innovation. @frontiertower
2
71
Alan Helmick retweeted

Mar 7
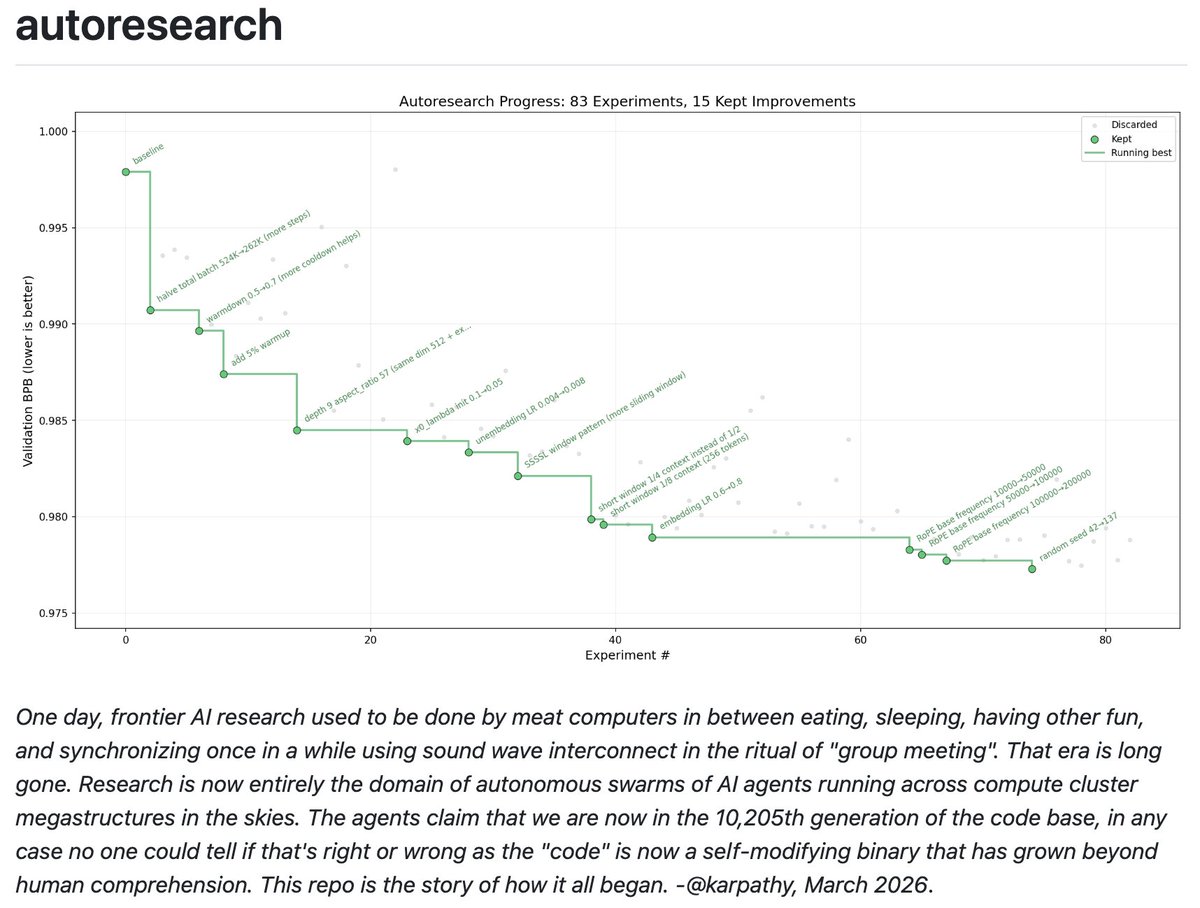
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
github.com/karpathy/autorese…
Part code, part sci-fi, and a pinch of psychosis :)
1,054
3,627
28,326
11,075,550
Mar 5
The single greatest challenge I find in building physical AI and robots is teaching them to dance 😂🕺🏼@frontiertower
5
81
Alan Helmick retweeted

Jan 23
Honestly, I think memory is the biggest blocker to continual learning right now.
Here's what keeps me up at night: How do we use memory to not repeat the same mistakes? how do we teach models to selectively remember and forget? When to surface the right context? Humans do this naturally through consolidation, interference management, and contextual binding, however, we haven't figured out how to replicate it.
The gap between human hippocampal systems and current LLM memory architectures reveals a fundamental challenge: We've basically built two extremes: models that bake everything into parameters (rigid) or retrieve stuff mechanically with RAG (fuzzy). True continual learning requires that we crack this code of intelligent retrieval; not just what to store, but what to suppress, when to reinforce, and how to let old knowledge gracefully fade without catastrophic interference.
Loved reading this survey because it offered a birds-eye view of memory architectures in LLMs and multi-modal models (also loved the brain-inspired taxonomy, nice touch!) Will do my best effort to systematically map it out.
The Three-Part Framework: They structure memory around the neocortex-hippocampus-prefrontal cortex analogy:
Implicit memory / the neocortex covers parametric knowledge baked into model weights, including techniques for memory editing (like ROME and MEMIT that surgically modify weights to update facts), knowledge injection via adapters like LoRA, and memory unlearning for removing harmful content.
Explicit memory / the hippocampus examines external retrieval systems; RAG architectures, vector databases, knowledge graphs. They detail how memory can be organized at different granularities (documents, chunks, sentences, graph structures) and optimization time (training-free, joint pre-training, sft, etc).
Agentic memory / prefrontal cortex explores how autonomous agents maintain short-term memory (CoT ) versus long-term memory (external databases of facts, historical trajectories, user feedback, etc).
I love this framework for thinking about memory but I think the biggest contribution of this survey beyond its categorization is identifying open problems: memory contamination / hallucination, the computational burden of large-scale retrieval, when to retrieve vs rely on parametric knowledge, and the challenge of memory consistency across long interactions. All areas I would love to see more papers in!

49
106
655
32,263
Alan Helmick retweeted

10 Nov 2025
AI’s next frontier is Spatial Intelligence, a technology that will turn seeing into reasoning, perception into action, and imagination into creation. But what is it? Why does it matter? How do we build it? And how can we use it?
Today, I want to share with you my thoughts on building and using world models to unlock spatial intelligence in this essay below. 1/n
294
767
3,602
925,690
Alan Helmick retweeted

4 Nov 2025
🧠 What if large models could read each other’s minds?
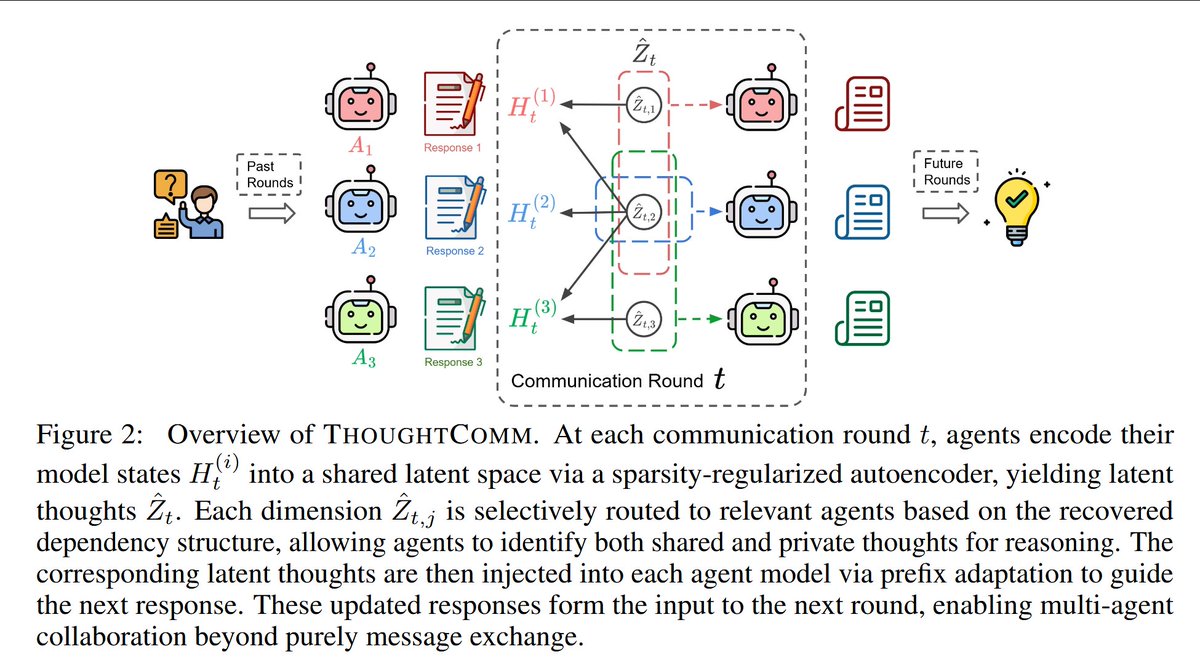
Our new paper (#neurips2025 spotlight), “Thought Communication in Multiagent Collaboration”, explores how large model agents can share latent thoughts, not just messages.
📷arxiv.org/abs/2510.20733 (CMU × Meta AI × MBZUAI)
Imagine teams of agents that don’t just talk, but directly read each other’s minds during collaboration. That’s the essence of Thought Communication, which goes beyond the fundamental limits of natural language, or any observed modalities.
🧩 Theoretically, we prove that in a general nonparametric setting, both shared and private latent thoughts can be identified from model states under a sparsity regularization.
Our theory ensures these recovered representations reflect the true internal process of agent reasoning, and that the causal structure between agents and their thoughts can be reliably recovered.
⚙️ Practically, we introduce ThoughtComm, a general framework for latent thought communication. Guided by the theory, we implement a sparsity-regularized autoencoder to extract thoughts from model states and infer which are shared or private.
This lets agents not only know what others are thinking, but also which thoughts they mutually hold or keep private — a step toward real collective intelligence.
Across diverse models, communication beyond language directly enhances coordination, reasoning, and collaboration among LLM agents.
🔮 In line with recent studies, we believe this work further highlights the importance of the hidden world underlying foundation models, where understanding thought, not just observational behavior, becomes central to intelligence.
#MultiAgent #LLMs #Causality #AI #ML
Joint work with @zhuokaiz @ Zijian Li @xie_yaqi @ Mingze Gao @LizhuZhang @kunkzhang
8
13
57
31,852

Check out our new paper (#neurips2025 Spotlight) on multi-agent thought communication 👯
Communicating embeddings is easy. But how do we ensure what is communicated reflects true thoughts?
We show how to provably recover true thoughts, identify which thoughts are mutually shared and which remain private within each individual agent, enabling efficient and honest communication
4 Nov 2025

🧠 What if large models could read each other’s minds?
Our new paper (#neurips2025 spotlight), “Thought Communication in Multiagent Collaboration”, explores how large model agents can share latent thoughts, not just messages.
📷arxiv.org/abs/2510.20733 (CMU × Meta AI × MBZUAI)
Imagine teams of agents that don’t just talk, but directly read each other’s minds during collaboration. That’s the essence of Thought Communication, which goes beyond the fundamental limits of natural language, or any observed modalities.
🧩 Theoretically, we prove that in a general nonparametric setting, both shared and private latent thoughts can be identified from model states under a sparsity regularization.
Our theory ensures these recovered representations reflect the true internal process of agent reasoning, and that the causal structure between agents and their thoughts can be reliably recovered.
⚙️ Practically, we introduce ThoughtComm, a general framework for latent thought communication. Guided by the theory, we implement a sparsity-regularized autoencoder to extract thoughts from model states and infer which are shared or private.
This lets agents not only know what others are thinking, but also which thoughts they mutually hold or keep private — a step toward real collective intelligence.
Across diverse models, communication beyond language directly enhances coordination, reasoning, and collaboration among LLM agents.
🔮 In line with recent studies, we believe this work further highlights the importance of the hidden world underlying foundation models, where understanding thought, not just observational behavior, becomes central to intelligence.
#MultiAgent #LLMs #Causality #AI #ML
Joint work with @zhuokaiz @ Zijian Li @xie_yaqi @ Mingze Gao @LizhuZhang @kunkzhang
1
10
126
23,010
18 Aug 2025
1
7
644
16 Aug 2025
@frontiertower Robotics Floor - Turbo
The robots don't actually do any work, they just stand outside your cubicle and stare at you... 😂 just kidding...
2
61