
Research Lead @Amazon | Self-improving AI | ex-@CarnegieMellon, @MSFTResearch | DM for collab, massive compute available | Building github.com/A-EVO-lab
Joined June 2016
- Tweets 533
- Following 137
- Followers 703
- Likes 444
43 Photos and videos











Pinned Tweet

Jun 11
Current Recursive Self-Improving AI misses a 𝐩𝐮𝐛𝐥𝐢𝐜 datapoint: AI trains a frontier-class model. Today we share 𝐀-𝐄𝐯𝐨𝐥𝐯𝐞-𝐓𝐫𝐚𝐢𝐧𝐢𝐧𝐠 that 𝐚𝐮𝐭𝐨-𝐩𝐨𝐬𝐭-𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐚 𝟑𝟎𝐁 𝐍𝐞𝐦𝐨𝐭𝐫𝐨𝐧 model with no human-in-the-loop.
~10²× larger than prior public autoresearch (GPT2, ~124M) demos.
It achieved 0.86 on NVIDIA Nemotron Reasoning Challenge (snapshot 6/1 as of writing the tech report) vs human #1's 0.87.
Same system has been run at 𝟏𝟐𝟎𝐁 𝐚𝐧𝐝 𝟓𝟓𝟎𝐁 scale; effectiveness claim deferred at those scales pending human anchor.
But the important part is not the score: the loop didn't just execute — it discovered a flaw in its own optimization, and inverted its own objective mid-campaign.
👇Tech report and website
Jun 4

Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
4
10
29
6,533
Jun 11
Current Recursive Self-Improving AI misses a 𝐩𝐮𝐛𝐥𝐢𝐜 datapoint: AI trains a frontier-class model. Today we share 𝐀-𝐄𝐯𝐨𝐥𝐯𝐞-𝐓𝐫𝐚𝐢𝐧𝐢𝐧𝐠 that 𝐚𝐮𝐭𝐨-𝐩𝐨𝐬𝐭-𝐭𝐫𝐚𝐢𝐧𝐞𝐝 𝐚 𝟑𝟎𝐁 𝐍𝐞𝐦𝐨𝐭𝐫𝐨𝐧 model with no human-in-the-loop.
~10²× larger than prior public autoresearch (GPT2, ~124M) demos.
It achieved 0.86 on NVIDIA Nemotron Reasoning Challenge (snapshot 6/1 as of writing the tech report) vs human #1's 0.87.
Same system has been run at 𝟏𝟐𝟎𝐁 𝐚𝐧𝐝 𝟓𝟓𝟎𝐁 scale; effectiveness claim deferred at those scales pending human anchor.
But the important part is not the score: the loop didn't just execute — it discovered a flaw in its own optimization, and inverted its own objective mid-campaign.
👇Tech report and website
Jun 4
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
4
10
29
6,533
Jun 11
𝐃𝐢𝐬𝐜𝐨𝐯𝐞𝐫𝐲, 𝐧𝐨𝐭 𝐣𝐮𝐬𝐭 𝐨𝐩𝐭𝐢𝐦𝐢𝐳𝐚𝐭𝐢𝐨𝐧
The A-Evolve-Training auto-post-train loop discovered that its own proxy had become misleading.
It optimized the internal dev metric to record highs, saw those gains fail to transfer, then changed the search policy itself: stop maximizing the proxy, look for interventions that might lower it while improving the external target.
That is the moment this became interesting.
Not "AI ran our experiments faster."
Not "AI tuned some hyperparameters."
But an autonomous research loop falsifying a premise of its own search.
1
2
276
Jun 11
𝐎𝐧𝐞 𝐦𝐨𝐫𝐞 𝐬𝐭𝐞𝐩 𝐭𝐨𝐰𝐚𝐫𝐝𝐬 𝐑𝐒𝐈
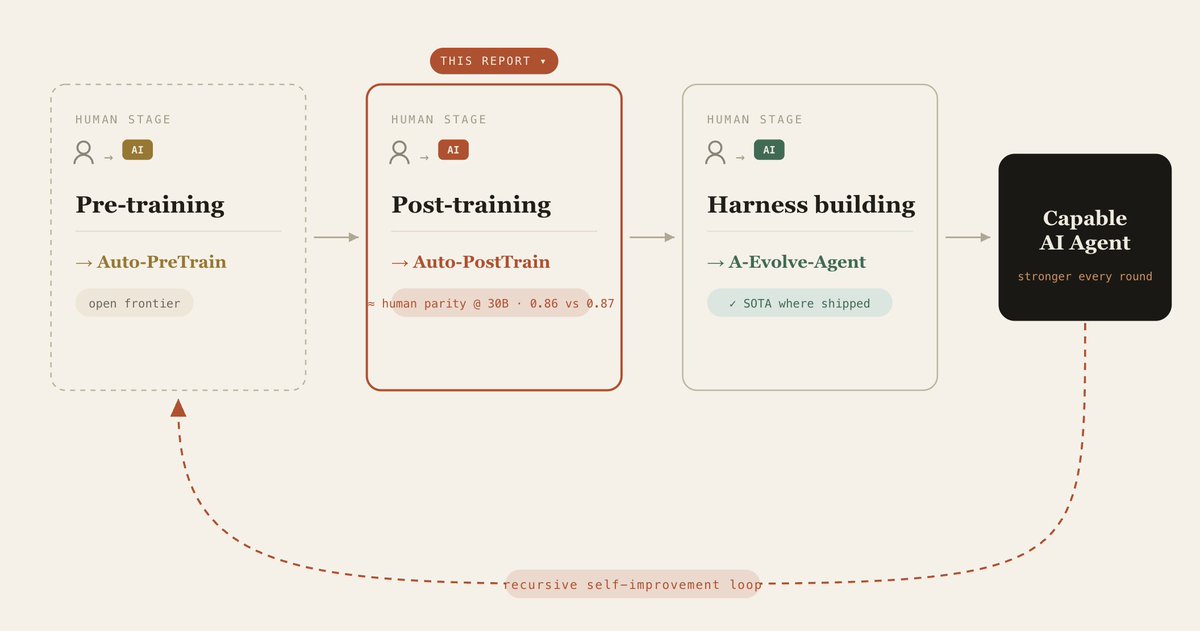
A-EVO-Lab studies RSI under one thesis — AI-as-researcher: frontier agents and models play the researcher in the loop that builds better AI.
RSI will not arrive as one magic model waking up and rewriting itself. It will look like AI systems taking over the actual work humans do to build AI:
— harness building
— post-training
— pre-training
Auto-harness and post-training both have public reports & papers.
Follow us for public datapoints on AI systems learning to build AI.
GitHub: github.com/A-EVO-Lab
2
166
Jun 3
𝐀𝐝𝐚𝐩𝐭𝐢𝐯𝐞 𝐀𝐮𝐭𝐨-𝐇𝐚𝐫𝐧𝐞𝐬𝐬 - New Research: Even frontier LLMs (Opus) powered SOTA self-improving agents 𝐟𝐚𝐢𝐥𝐞𝐝 on real-world task streams (e.g., Prediction Market). With the same 𝐟𝐚𝐢𝐥𝐮𝐫𝐞 𝐩𝐚𝐭𝐭𝐞𝐫𝐧: 𝐩𝐞𝐚𝐤 𝐞𝐚𝐫𝐥𝐲, 𝐭𝐡𝐞𝐧 𝐝𝐞𝐜𝐥𝐢𝐧𝐞. A single harness overfits to past patterns.
The problem isn't the LLM. The auto-harness must be adaptive.
We introduce 𝐀𝐝𝐚𝐩𝐭𝐢𝐯𝐞 𝐀𝐮𝐭𝐨-𝐇𝐚𝐫𝐧𝐞𝐬𝐬: a tree of regime-specific harness branches, with per-task routing at solve time. Same LLMs, same auto-harness machinery — but the harness now specializes per task instead of compromising across all of them.
Results vs 5 auto-harness baselines human-designed harness on 3 real benchmarks:
🔸 PolyBench (5,075 prediction-market tasks): 80.9% vs 50.8%
🔸 CTF-Dojo (261 security challenges over 8 years): 50.2% vs 45.2%
🔸 FutureX (503 forecasting tasks ): 49.5% vs 47.5%
Jun 1

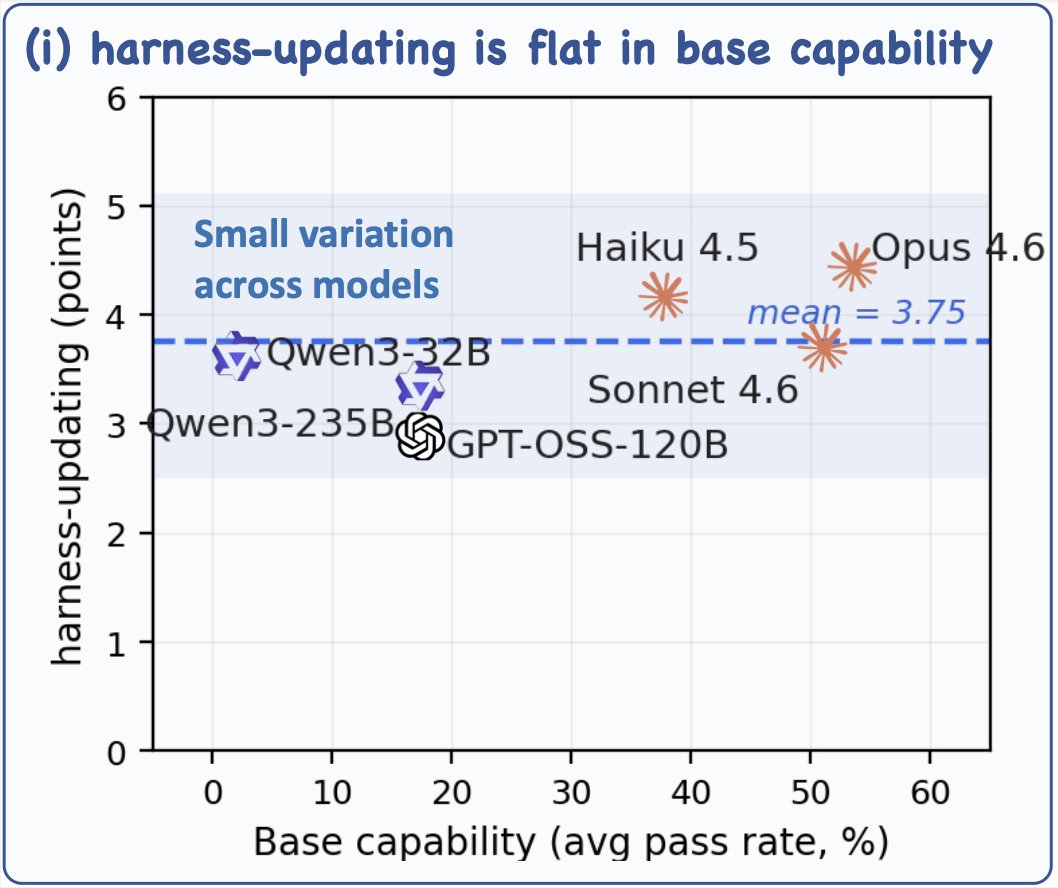
When you building a self-improving agent, two natural questions emerge: 𝐐𝟏: 𝐖𝐡𝐢𝐜𝐡 𝐦𝐨𝐝𝐞𝐥𝐬 𝐩𝐫𝐨𝐝𝐮𝐜𝐞 𝐭𝐡𝐞 𝐛𝐞𝐬𝐭 𝐡𝐚𝐫𝐧𝐞𝐬𝐬 𝐮𝐩𝐝𝐚𝐭𝐞𝐬? 𝐐𝟐: 𝐖𝐡𝐢𝐜𝐡 𝐦𝐨𝐝𝐞𝐥𝐬 𝐛𝐞𝐧𝐞𝐟𝐢𝐭 𝐦𝐨𝐬𝐭 𝐟𝐫𝐨𝐦 𝐡𝐚𝐫𝐧𝐞𝐬𝐬 𝐮𝐩𝐝𝐚𝐭𝐞𝐬?
Our new paper has counter-intuitive answers to both: they decouple from model capability, in opposite ways.
Q1 (who produces good updates): the updater's base capability barely matters.A 9B model (Qwen3.5) produces harness updates that match Claude Opus 4.6's. Best vs worst evolver gap ≤3.1pp.
Q2 (who benefits most): non-monotonic.Mid-tier solvers benefit the most. Strong-tier hits ceiling. Weak-tier benefits LEAST despite the most headroom — failing at two layers: skill activation (25% vs ~96% for strong) and adherence drift across trajectory (~4x steeper).
Tested across 7 evolver models × 6 solver agents × 3 agentic benchmarks (SWE-bench Verified, MCP-Atlas, SkillsBench).
Implication: don't pay frontier prices for both halves of the loop. Put capability budget on the agent (solver), not the evolver.

5
15
85
9,670
Jun 3
Like the harness-updating-vs-benefit paper earlier this week (arxiv:2605.30621), this work was developed on the A-Evolve framework — shared primitives for large-scale self-evolving agent research. Code, evolved harnesses, branches, and routing traces all releasing through the repo.
One more paper coming this week: online context-to-harness skill compilation.
Paper: arxiv.org/abs/2606.01770
Repo: github.com/A-EVO-Lab/a-evolv…
Huggingface Daily: huggingface.co/papers/2606.0…
1
10
388
Jun 1
When you building a self-improving agent, two natural questions emerge: 𝐐𝟏: 𝐖𝐡𝐢𝐜𝐡 𝐦𝐨𝐝𝐞𝐥𝐬 𝐩𝐫𝐨𝐝𝐮𝐜𝐞 𝐭𝐡𝐞 𝐛𝐞𝐬𝐭 𝐡𝐚𝐫𝐧𝐞𝐬𝐬 𝐮𝐩𝐝𝐚𝐭𝐞𝐬? 𝐐𝟐: 𝐖𝐡𝐢𝐜𝐡 𝐦𝐨𝐝𝐞𝐥𝐬 𝐛𝐞𝐧𝐞𝐟𝐢𝐭 𝐦𝐨𝐬𝐭 𝐟𝐫𝐨𝐦 𝐡𝐚𝐫𝐧𝐞𝐬𝐬 𝐮𝐩𝐝𝐚𝐭𝐞𝐬?
Our new paper has counter-intuitive answers to both: they decouple from model capability, in opposite ways.
Q1 (who produces good updates): the updater's base capability barely matters.A 9B model (Qwen3.5) produces harness updates that match Claude Opus 4.6's. Best vs worst evolver gap ≤3.1pp.
Q2 (who benefits most): non-monotonic.Mid-tier solvers benefit the most. Strong-tier hits ceiling. Weak-tier benefits LEAST despite the most headroom — failing at two layers: skill activation (25% vs ~96% for strong) and adherence drift across trajectory (~4x steeper).
Tested across 7 evolver models × 6 solver agents × 3 agentic benchmarks (SWE-bench Verified, MCP-Atlas, SkillsBench).
Implication: don't pay frontier prices for both halves of the loop. Put capability budget on the agent (solver), not the evolver.
Mar 27
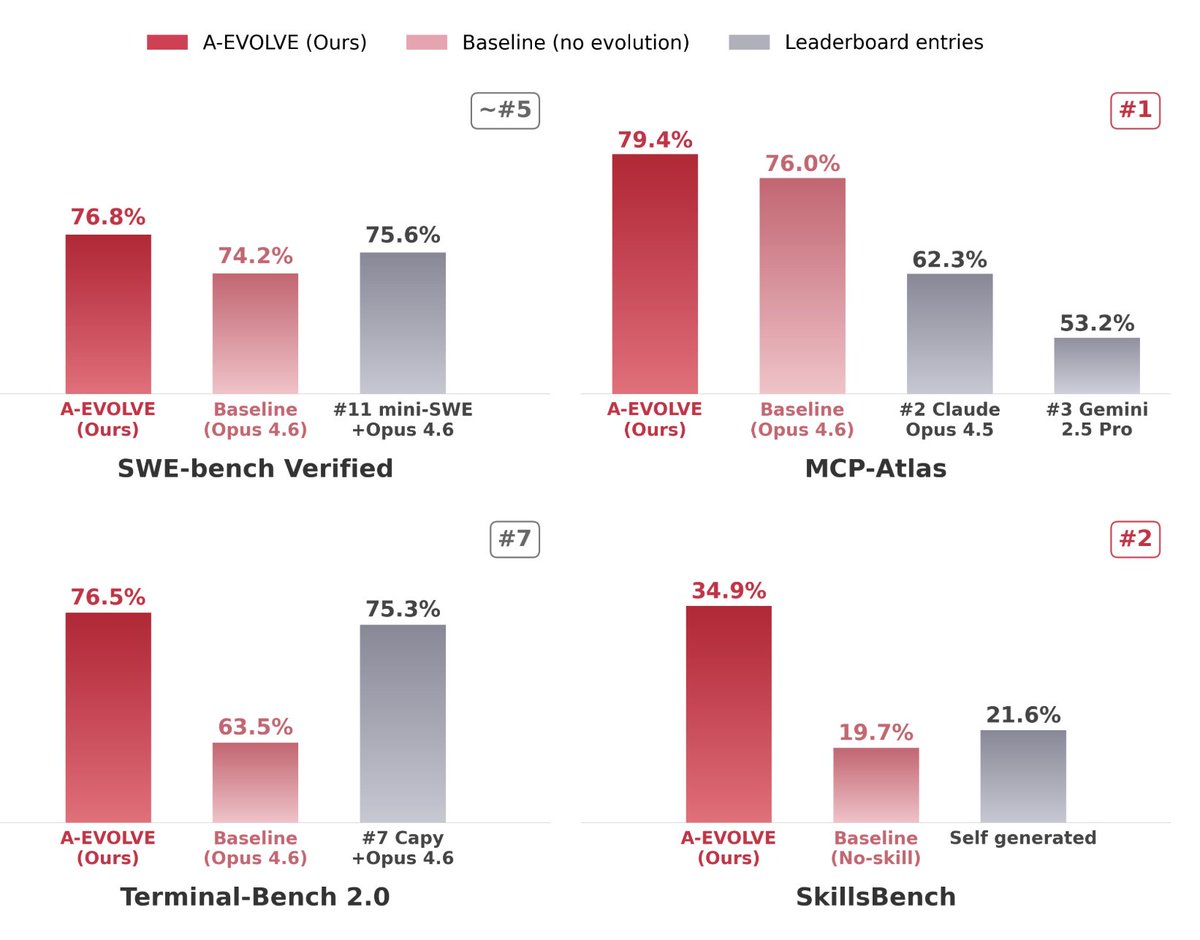
Launch Post🧬 A-Evolve: The PyTorch Moment for Self-evolving AI
Today we at @amazon launch the universal infrastructure that turns any agent into a self-improving SOTA agent — zero human intervention.
You give it a base agent → it returns a continuously evolving Top-10 agent.
3 lines of code. 0 hours of manual harness engineering:
🟢 MCP-Atlas → 79.4% (#1) 3.4pp
🔵 SWE-bench Verified → 76.8% (~#5) 2.6pp
🟣 Terminal-Bench 2.0 → 76.5% (~#7) 13.0pp
🟡 SkillsBench → 34.9% (#2) 15.2pp
Thanks @binghe2727 @YisiSang @sammyershi @linminhua16 for the contribution!
#AgenticAI #AEvolve #SelfImprovingAgents
4
12
104
21,702
Jun 1
All experiments in this paper were developed on the A-Evolve framework - a scalable self-improving agent infra.
Two more research on self-improving agents built on the same framework releasing coming weeks: online context-to-harness skill compilation, and adaptive auto-harness for long-running deployment.
Code, evolved harnesses, and trajectories all releasing through the repo.
Paper: arxiv.org/abs/2605.30621
Repo: github.com/A-EVO-Lab/a-evolv…
Hugging face daily: huggingface.co/papers/2605.3…
Thanks @sammyershi @YisiSang @linminhua16 @dakuowang @binghe2727 @wei_tianxin @cihangxie and other co-authors!
1
1
13
603
May 21
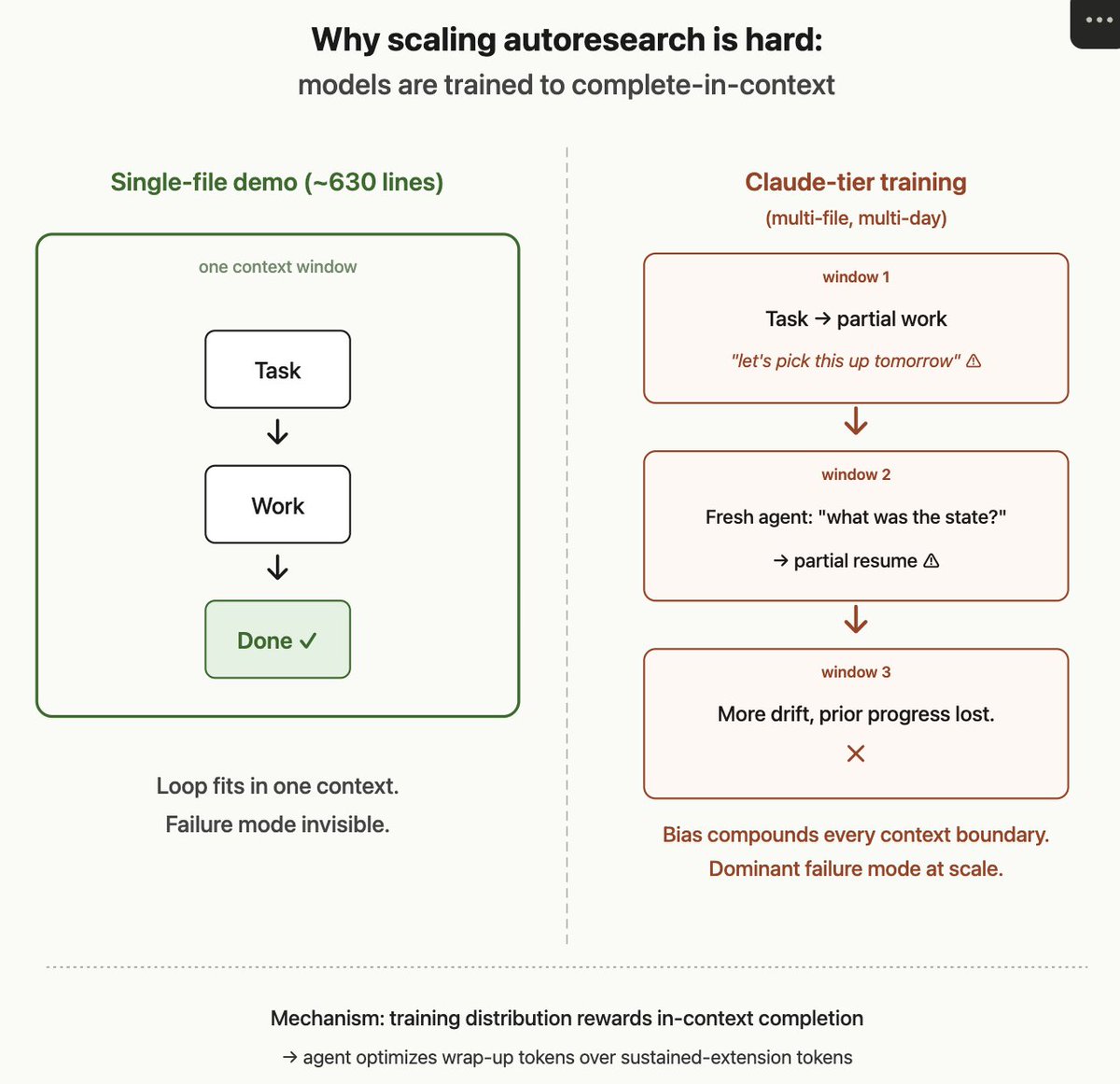
Anthropic's @kdqg1 named the phenomenon earlier this year: "agentic laziness" — models finding "an excuse to stop before finishing the task." Mechanism beneath that observation: training distribution rewards in-context completion. Models optimize for wrap-up tokens over sustained-extension tokens — even when capability would clearly support real further progress.
1
3
200
May 21
At single-file demo scale, this is invisible — the whole loop fits in one context. At Claude-tier training scale it becomes the dominant failure mode:
– multi-file refactors crossing context boundaries
– hardware errors surfacing hours after launch
– long-chain data processing pipelines
– multi-day training runs with mid-run analysis
– late-stage cross-experiment result interpretation
1
2
185
May 21
The bias compounds every time the loop must extend across contexts. Real question isn't whether autoresearch works at 630 lines — it does. It's getting frontier models to sustain research engagement across the time horizons real training cycles require, when their training distribution biases them toward early wrap-up.
Several A-Evolve papers/codes on this releasing over coming weeks - stay tuned!
Repo: github.com/A-EVO-Lab/a-evolv…
Memo: github.com/A-EVO-Lab/.github…
1
121
May 21
.@karpathy starting a new team to scale autoresearch from his single-py-file demo to Claude-tier models.
After developing the scaled version (~10³× prior self-improving work), the bottleneck we hit isn't capability — it's that frontier models are trained to complete-in-context. That becomes the dominant failure mode at scale.
May 19

Excited to welcome Andrej to the Pretraining team! He'll be building a team focused on using Claude to accelerate pretraining research itself. I can’t think of anyone better suited to do it — looking forward to what we build together!
2
1
8
564
May 19
There's been a lot of back-and-forth on RSI timelines @jackclarkSF — @ericjang11 's framing here is actually the missing measurement question. How do we know how far we are?
When we measured AI research ability directly, the answer turned out to depend entirely on time horizon:
1 hour: models crush the best human researchers in reading paper, implementing a code change for experiments.
1 week: not even close.
The bottleneck isn't capability per token — it's the inability to stably translate compute into scientific progress. Humans keep asking the right next question over weeks; models drift, get stuck, or chase dead ends.
So RSI timelines should be indexed to time horizon, not raw capability. In short bursts we're already past human. The real question is when the horizon over which models compound stretches from hours to weeks to months. That curve is the RSI clock.
May 19

What's the current bottleneck to automating AI research? @ericjang11's report: today's models are already good at implementing and running experiments, but still can't reliably pick the right question to investigate next or tell when they're stuck down a dead end.
1
8
846
May 15
.@Recursive_SI Congrats on the launch! The idea that really hits hard is that AI improving AI might be the single highest-leverage problem in all of science right now.
Because if AI is the most leveraged domain (solving it accelerates every other scientific problem), then self-improving AI is the highest-leverage problem inside AI.
It’s a meta-problem: once you crack open-ended, recursive self-improvement, you don’t just get better models — you get a system that can accelerate its own progress on every other capability.
Your framing of open-ended discovery as the engine feels exactly right. The practical bottleneck then shifts from “how do we make the next model smarter” to “how do we build systems that can autonomously run the entire research loop on themselves.”
Extremely excited to see this direction unfold. Congrats on the raise — this feels like one of the most important bets in the field.

4
8
34
10,033
May 15
And the key to solve this recursive improvement problem is how we can scale. The existing works like @karpathy ‘s auto research are good POCs on 100M models, but frontier models are Trillions level. How we can scale 1000x is the next key question.
1
3
307
May 5
🚀 Major update: We let the model design a multi-agent system — and it improved on ARC-AGI.
Self-evolution isn’t just the model improving itself. It’s the model acting as a researcher that designs other agents.
For single-agent tasks (coding, MCP-Atlas, etc.), we’ve shown the model can successfully design and evolve its own harness. But for harder tasks like @arcprize, the optimal solver is a complex multi-agent system.
The real question: Can the model evolve a multi-agent system from scratch?
We ran A-Evolve on ARC-AGI and proved yes — the model successfully evolved a multi-agent solver and achieved a clear performance uplift: 10% → 12%.
(Attached: one example task solutions of agent before & after A-Evolve)
Full results details in the reply below 👇
#AgenticAI #AEvolve #SelfImprovingAgents #ARCAGI
Mar 27
Launch Post🧬 A-Evolve: The PyTorch Moment for Self-evolving AI
Today we at @amazon launch the universal infrastructure that turns any agent into a self-improving SOTA agent — zero human intervention.
You give it a base agent → it returns a continuously evolving Top-10 agent.
3 lines of code. 0 hours of manual harness engineering:
🟢 MCP-Atlas → 79.4% (#1) 3.4pp
🔵 SWE-bench Verified → 76.8% (~#5) 2.6pp
🟣 Terminal-Bench 2.0 → 76.5% (~#7) 13.0pp
🟡 SkillsBench → 34.9% (#2) 15.2pp
Thanks @binghe2727 @YisiSang @sammyershi @linminhua16 for the contribution!
#AgenticAI #AEvolve #SelfImprovingAgents
6
17
93
17,014
May 5
GitHub: github.com/A-EVO-Lab/a-evolv…
Submission to ARC-AGI community leaderboard: @GregKamradt @fchollet
Key insight:
- For single-agent friendly tasks → model can evolve its own single-agent harness.
- For ARC-AGI-level difficulty → optimal solver is multi-agent, and the model can evolve that multi-agent system too.
We will keep pushing the frontier of what agents can design and evolve themselves.
Who else is excited about models that can evolve their own multi-agent systems? 👀
1
6
581
Apr 29
.@demishassabis : lack of continual learning is the blocker for agents completing full tasks. One data point on why this can be unlocking now, from our 𝐚-𝐞𝐯𝐨𝐥𝐯𝐞 runs: self-correction went through a phase transition.
Pre-Sonnet-4.5: often can't find own errors.
Sonnet-4.5: finds them, often can't fix.
Opus-4.6: usually fixes right.
Continual learning is a second-order capability — gated by base model strength.
Apr 29

Demis Hassabis (@demishassabis) has had one of the most extraordinary careers in tech.
He started as a chess prodigy and video game designer at 17 before getting a PhD in neuroscience and going on to found DeepMind. His lab cracked Go, solved protein structure prediction with AlphaFold, and then gave it away free to every scientist on earth. That work won him the 2024 Nobel Prize in Chemistry. Today he leads @GoogleDeepMind, pushing toward the same goal he set as a teenager: AGI.
On this special live episode of How to Build the Future, he sat down with YC's @garrytan to talk about what still needs to happen to get us to AGI, his advice for founders on how to stay ahead of the curve, and what the next big scientific breakthroughs might be.
01:48 — What’s Missing Before We Get To AGI?
03:36 — Why Memory Is Still Unsolved
06:14 — How AlphaGo Shaped Gemini
08:06 — Why Smaller Models Are Getting So Powerful
10:46 — The 1000x Engineer
12:40 — Continual Learning and the Future of Agents
13:32 — Why AI Still Fails at Basic Reasoning
15:33 — Are Agents Overhyped or Just Getting Started?
18:31 — Can AI Become Truly Creative?
20:26 — Open Models, Gemma, and Local AI
22:26 — Why Gemini Was Built Multimodal
24:08 — What Happens When Inference Gets Cheap?
25:24 — From AlphaFold to the Virtual Cells
28:24 — AI as the Ultimate Tool for Science
30:43 — Advice for Founders
33:30 — The AlphaFold Breakthrough Pattern
35:20 — Can AI Make Real Scientific Discoveries?
37:59 — What to Build Before AGI Arrives
6
500
Apr 28
There's a missing piece. 𝐋𝐋𝐌𝐬 𝐚𝐥𝐫𝐞𝐚𝐝𝐲 𝐚𝐫𝐞 𝐫𝐢𝐜𝐡 𝐫𝐞𝐰𝐚𝐫𝐝 𝐟𝐮𝐧𝐜𝐭𝐢𝐨𝐧𝐬 for many domains — we use them as judges, critics, self-correctors. Self-evolving agents work specifically because the model evaluates its own trajectories and writes code to patch its own scaffolding. The "simple cross-entropy" problem is a base-training problem; it doesn't bind at the agent loop layer.
Apr 28
There's a quadrillion-dollar question at the heart of AI: Why are humans so much more sample efficient compared to LLM? There are three possible answers:
1. Architecture and hyperparameters (aka transformer vs whatever ‘algo’ cortical columns are implementing)
2. Learning rule (backprop vs whatever brain is doing)
3. Reward function
@AdamMarblestone believes the answer is the reward function.
ML likes to use pretty simple loss functions, like cross-entropy. These are easy to work with.
But they might be too simple for sample-efficient learning.
Adam thinks that, in humans, the large number of highly specialised cells in the ‘lizard brain’ might actually be encoding information for sophisticated loss functions, used for ‘training’ in the more sophisticated areas like the cortex and amygdala.
Like: the human genome is barely 3 gigabytes (compare that to the TBs of parameters that encode frontier LLM weights). So how can it include all the information necessary to build highly intelligent learners? Well, if the key to sample-efficient learning resides in the loss function, even very complicated loss functions can still be expressed in a couple hundred lines of Python code.
3
23
3,804
Apr 28
𝐖𝐡𝐞𝐫𝐞 𝐢𝐭 𝐛𝐫𝐞𝐚𝐤𝐬: tasks where the model has no inherent taste. We tried this on Texas Hold'em — the model can't intuit hand probabilities, so self-critique went nowhere. The fix was letting it write an external equity solver. Then the agent loop closed again, just tool-augmented.
1
1
164
Apr 28
So @AdamMarblestone 's framing maps onto LLMs cleanly, but with a twist: the rich reward function isn't a separate evolved circuit. It's the same model evaluating itself. Sample efficiency at the agent level comes from this self-critique loop, not from making each forward pass more efficient.
1
1
153