
Machine learning researcher at @GoogleDeepMind & mathematician. Host of The Cartesian Cafe podcast. All opinions are my own.
Joined May 2017
- Tweets 1,770
- Following 465
- Followers 12,176
- Likes 1,859
321 Photos and videos


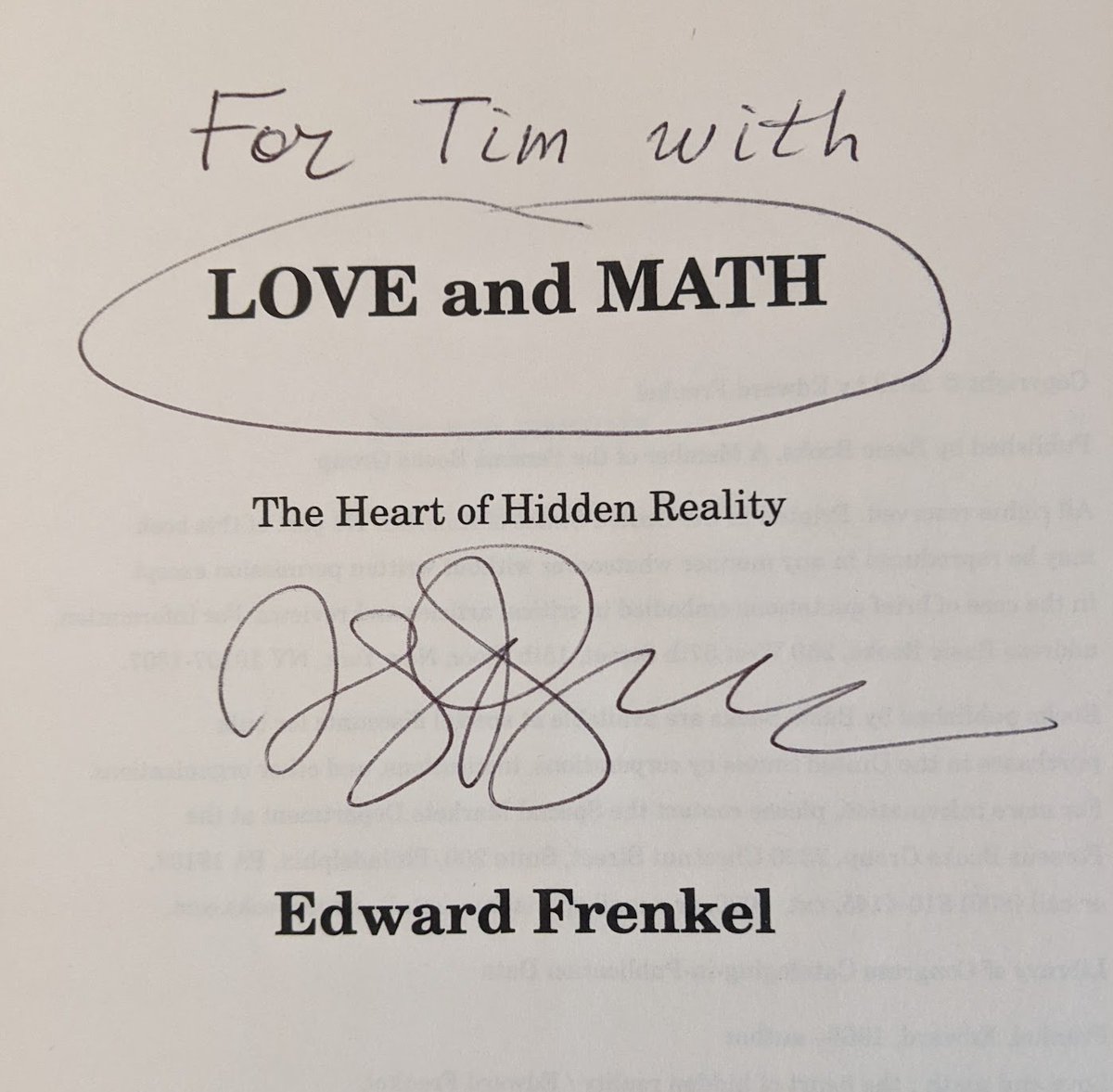





Pinned Tweet

21 Apr 2025
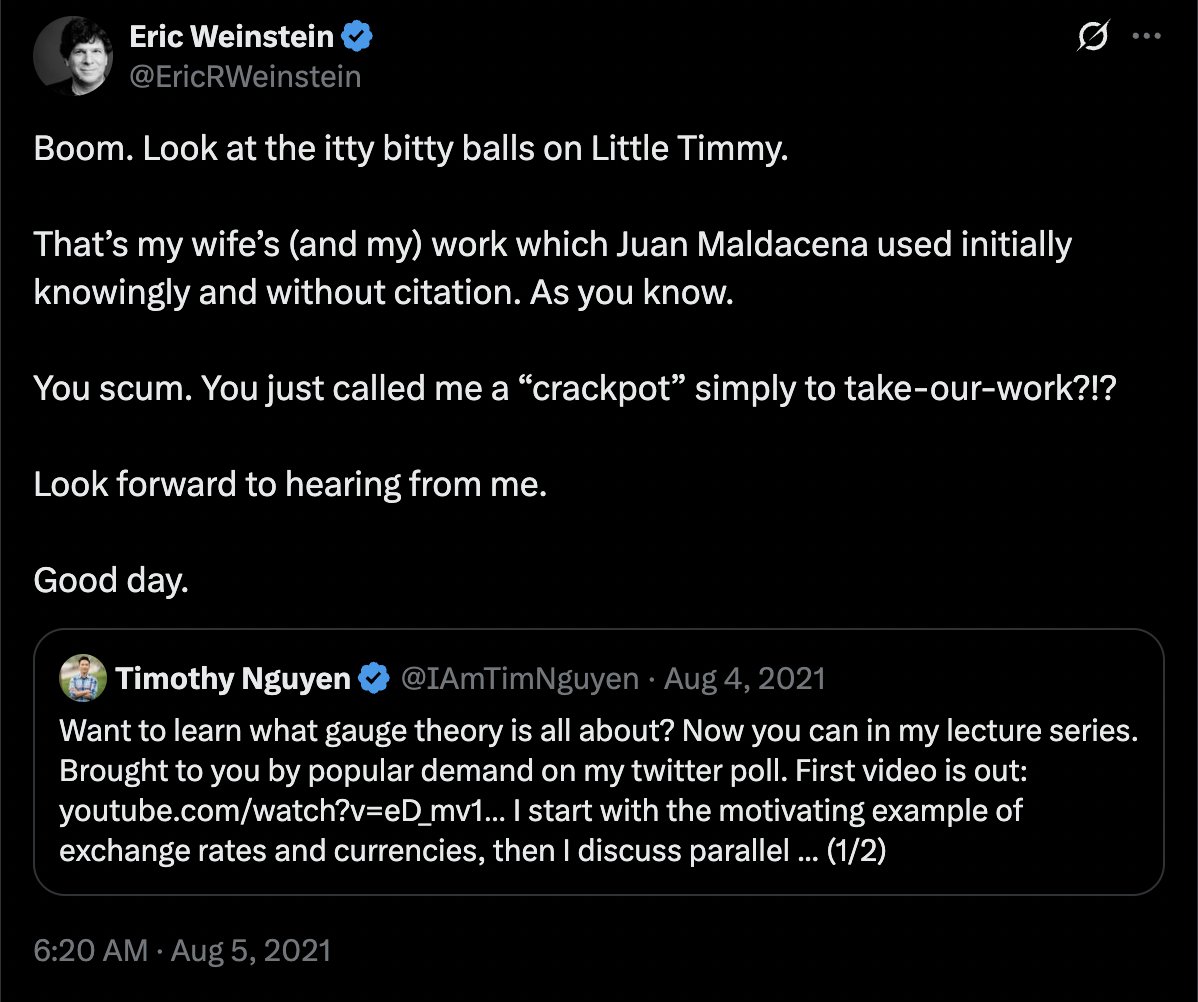
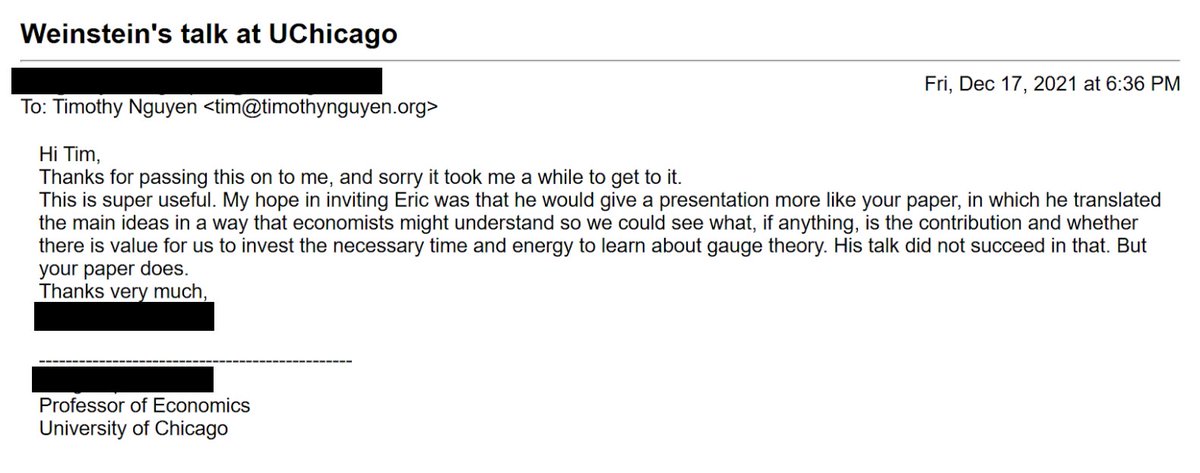
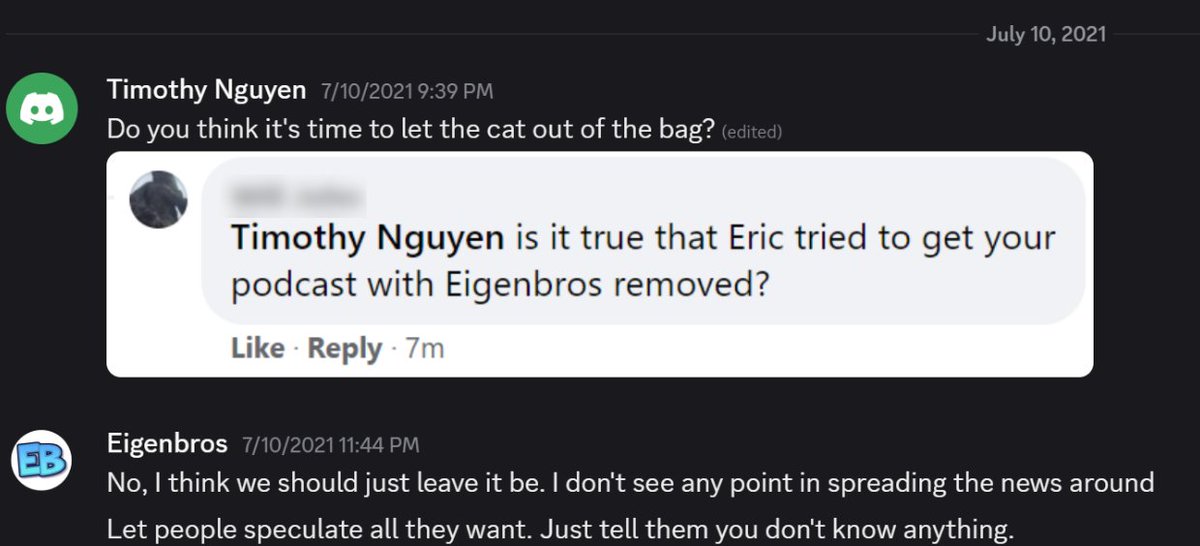
Quantum field theory textbooks have been lying to you or have left you confused. For a typical passage like the following from Peskin&Schroeder - what does it mean to do a change of variables on an ill-defined path integral? For perturbative QFT, my paper resolves this issue: 🧵

19
41
466
50,330
May 27
What's your take on math AI?
61%
Math discovered. Pro AI
14%
Math discovered. Nay AI
18%
Math invented. Pro AI
7%
Math invented. Nay AI
57 votes • Final results
9
8
3,155
May 27
My thoughts: If you're a mathematician, might your reaction to the AI encroachment be based on your answer to that age-old question: Is mathematics discovered or invented? The most straightforward, even if oversimplified, two-way division:
You're a Platonist, you see math as discovered. For you, you enjoy savoring mathematical gems from the mountain-top, to see the peaks and valleys that existed prior to your arrival. You would enjoy basking in as many vistas as you could.
Or you regard math as invented. For you, climbing the mountain cannot be excluded. Being transported to the summit defeats your sense of accomplishment and struggle. The journey rather than the destination is the primary value. How do these perspectives align with your attitude towards math AI?
2
6
1,818
Timothy Nguyen retweeted

May 25
For now I think recent successes of AI for mathematics should be understood as a complement to, rather than a substitute for, human mathematical labor. This is because AI, at present, is most productive working horizontally, whereas humans work vertically.
By this I mean that the highest quality AI mathematics thus far has been obtained by feeding entire problem lists into a model or scaffold and picking out the few high-quality successes. It is very hard to predict in advance where these successes occur. On the other hand, humans typically pick a few questions and try to understand them deeply--and historically, when they do so, they make progress!
I think this points to increasing value of problem lists, and also suggests that "solved an open problem" is an increasingly useless proxy for what we care about in mathematics. There are a lot of problems that have sat open for a long time because the right person didn't happen to look at them, and many others that are open because they benchmark our failure to fundamentally understand some basic object. I've solved old open problems that I think had the former flavor rather than the latter. I think my best work, however, is not about solving long-open problems, but rather inventing a new ones that help to understand something we care about, and making progress on that.
36
68
714
58,500
May 20
A new AI milestone today:
"If a human had written the paper and submitted it to the Annals of Mathematics and I had been asked for a quick opinion, I would have recommended acceptance without any hesitation. No previous AI-generated proof has come close to that.” - Tim Gowers
1/
3
8
94
6,839
May 20
8
1,061
May 9
Mathematics as a field is going to have to reorient itself in light of powerful AI. But a slight pushback to Gowers's comment:
"If LLMs are at the point where they can solve 'gentle problems', ...the lower bound for contributing to mathematics will now be to prove something that LLMs can’t prove, rather than simply to prove something that nobody has proved up to now and that at least somebody finds interesting."
Mathematics is infinite and thus inexhaustible. By having powerful AIs that can do heavy lifting, more of the burden is shifted towards taste and asking the right question. The possibility of discovering something by looking in the right place that everyone else missed becomes possible. In mathematical physics for instance, an Einstein with inspiration of the equivalence principle might not have to toil for a decade to invent general relativity, but could have equations proposed, their solutions found, and scenarios validated as limits of Newtonian physics. Contributing to mathematics, rather than having the bar raised for problem-solving, has opened up for ideation and generation.

But if AI mathematics continues to progress at anything like its current rate -- which is what I expect to happen -- then we will face a crisis very soon, and mathematics departments, who owe a duty of care to their students, should be urgently preparing for it.
27
29
221
41,974
Timothy Nguyen retweeted

I've recently got in on the act of getting AI to solve open problems in mathematics. More precisely, I gave some questions asked by Melvyn Nathanson to ChatGPT 5.5 Pro, to which I have been given access, and it answered them. 🧵
75
379
1,964
643,691
Timothy Nguyen retweeted

May 2
I post to X often, but I rarely read the feed. However, this thread was texted to me and I wish to weigh in.
I’d be really sad if we recalibrated what constitutes "good science" and "interesting" mathematics based on what AI can or cannot do. Take my 1996 paper with Andrew Granville—it is our 6th and 5th most cited work, respectively.
We used analytic number theory to provide results needed for the modular representation theory of finite simple groups. The solution sat completely outside the "silo of modular representation theorists." If AI had been around then, it likely would have solved it, because AI isn't constrained by our human silos.
But does that make the work less "good" or uninteresting? No. Its value wasn't in the "hardship" of the proof; it was in the service it provided to a community that was stuck. It built a bridge.
To be perfectly clear: I am not saying we shouldn't learn to prove things just because AI can do it for us. Exactly the opposite. Try reading a Lean proof—you'll learn a tremendous amount from the experience. The human pursuit of understanding is as vital as ever.
But if we equate "good science" purely with "difficulty," we lose the wonder of doing mathematics.
AI for Math isn't about replacing us; it’s about eliminating the friction so we can focus on the vision. AI will master the mechanics of proof, but mathematicians must remain the architects of meaning. Let the machine conquer the how. We get to keep the why.
May 2

While I agree in principle, in practice I think AI raises tough questions about what we even mean by "good science" in the context of mathematics. There's an infinite number of true mathematical statements, many of which we can but do not bother to prove because we consider them "routine" and therefore uninteresting. What counts as "routine" is subjective, but I think it approximately means "doable using (only) well-known existing techniques". If AI becomes consistently stronger than humans at certain mathematical skills (for example, "combining already-existing techniques in a new way"), then certain types of previously non-routine problems will become routine in a higher level sense: doable by the well-known technique of querying an AI chatbot. At that point, are those problems still interesting?
13
22
137
24,552
Apr 6
Human slop that would have been hard for AI to make up.

Oh dear.
The New York Times clever headline about NATO is entirely based on them getting its name wrong 😐
The A doesn’t stand for America, dudes.

5
1,303
Timothy Nguyen retweeted

Mar 31
A preview of my talk tomorrow at the Newton Insitute @NewtonInstitute (comments welcome)
My primary interest is research math: solving problems, proving theorems.
Before 2019, I was accustomed to using Mathematica to check tedious, error-prone algebra in my papers. Do it once, and never waste time checking it again.
But algebra was only part of the issue. If I had a lemma, and in a 60-page paper I might have 20 of them, with a dozen parameters all moving around in different ranges and needing to line up perfectly at the end, then even a single stray minus sign could kill the entire paper. The whole enterprise was extremely complex and fragile. (What I'm describing is very common in loads of fields in modern research math.)
In 2019, I watched a lecture of Kevin Buzzard's, and realized the answer: I should use an interactive theorem prover like Lean to check my lemmas the same way Mathematica checks my algebra. (Of course, as I've since learned, there are many benefits to working formally beyond correctness, and these have been extensively enumerated elsewhere, so I won't repeat them here.)
But my original motivation for getting involved in formalization was simple: I hoped it would speed up my workflow.
It did not.
In fact, formalization is brutally tedious, requiring painstakingly spelling out facts that to a human expert are blatantly obvious.
Fast forward to 2025, and AI was getting genuinely good at helping with formalization. I was already using Claude rather extensively when we crossed the finish line on the "Medium" PNT in July 2025. By September 2025, Math Inc's Gauss system autoformalized the Strong PNT, writing over 20K lines of compiling Lean autonomously. Earlier this month, they outdid themselves again, writing 200K lines autonomously and formalizing Viazovska's theorems on optimal sphere packing in dimensions 8 and 24.
So isn't that the dream? AI can now, in some instances, autoformalize very significant theorems. Can we mathematicians just get back to thinking, sketching, and letting AI do the formalization for us?
Not so fast.
Autoformalization only works because it is built on top of a big, comprehensive, efficient, coherent monorepo of high-quality formalized mathematics, namely Mathlib. And even in the PNT and Viazovska examples, the autoformalizations still depended on substantial earlier human work: setting up the right definitions, the right API, the right abstractions, and so on.
So maybe we now get a nice positive feedback loop:
Research
->
formal math (thanks to AI)
->
grows Mathlib
->
enables more research.
Still no.
AI formalization, and frankly the first-pass human formalization too, is usually local, ad hoc, single-purpose work. It is not necessarily general, abstract, efficient, or reusable. So it does not in and of itself help grow Mathlib. The second arrow is broken.
Actually, this is not some temporary annoyance, it is inevitable! The goals of doing research and building libraries are misaligned, like scrambling up a cliff versus building an elevator to the top. Both are trying to go up, but for completely different reasons and in completely different ways.
In fact, it is even worse than that: the second arrow may make the feedback loop negative.
Let us give that second arrow a name: "canonization".
By canonization, I mean the process of taking a local, one-off formalization and turning it into library mathematics: general, reusable, coherent, efficient, and compatible with the rest of the monorepo. This is an extremely difficult and time-consuming task. It requires a large amount of prior knowledge and skill, often in several quite different areas at once. And here's why the feedback loop may be negative: while a rough formalization can certainly be a technical head start, socially it often strands the problem in the worst possible state: too solved to feel pressing, too idiosyncratic to be reusable. If a formalization already exists in some ad hoc form, then people are much less incentivized to do this work! They get less credit for succeeding, there is less urgency, and less motivation.
Does this sound familiar? It's the same structural problem we had back in 2019, going from proved results to formalized results! So the answer should be obvious.
In June 2025, I claimed that (quasi)autoformalization, meaning not entirely autonomous but allowing human intervention and steering, was the greatest short-term challenge in realizing the dream of speeding up research [K2025]. The corresponding claim today is:
(Quasi)auto-canonization is the greatest short-term challenge for AI systems.
I personally know of only one AI company so far that seems to be taking this challenge seriously, namely Harmonic with its Aristotle agent. Imagine if we get this right. Definitions will still be difficult to automate, but there are orders of magnitude fewer definitions than theorems. Once those foundations are laid (which will still be a ton of human time and effort!), everything else can scale on top.
Right now, the vast majority of research mathematicians working in formalization are, very commendably, working toward growing Mathlib. But they comprise maybe 1% of all professional mathematicians. This is not necessarily because people do not want to work formally. It is because the current system does not match how most mathematicians want to work.
People are diverse. They have different strengths and weaknesses, different interests, different workflows. If we embrace an ecosystem where people are encouraged to formalize freely, with heavy AI assistance, and where the right pieces later get (quasi)auto-canonized into the central monorepo, then I think we could potentially be in position, given the right incentives, training, and culture-shifts, to move from a handful to the majority of mathematicians doing math formally.
22
64
366
103,380
Timothy Nguyen retweeted

Mar 25
Please do apply. This ML theory summer school @Princeton will be amazing! Application deadline is in one week.
Mar 24

🚨 2026 @Princeton ML Theory Summer School
Meet your peers
Learn from mini-courses by:
- Subhabrata Sen
- Lenaic Chizat
- Sinho Chewi
- Elliot Paquette
- Elad Hazan
- Surya Ganguli
August 3 - 14, 2026
One week left to apply!
Link 👇
Sponsors: @NSF, @PrincetonAInews, @EPrinceton, @JaneStreetGroup, @DARPA, @PrincetonPLI, Princeton NAM, Princeton AI2, Princeton PACM
Some amazing speakers from this and previous years: @subhabratasen90, @LenaicChizat, @poseypaquet, @HazanPrinceton, @SuryaGanguli, @Andrea__M, @TheodorMisiakie, @KrzakalaF, @_brloureiro, @rakhlin, @DimaKrotov, @CPehlevan, @SoledadVillar5, @SebastienBubeck, @tengyuma
2
7
90
20,573
Mar 22
Fascinating agentic conference idea though I seriously wonder about reproducibility here. Skills are trivially reproducible but agentic behavior isn’t. And underlying models get updated all the time.

Excited to launch — Claw4S Conference 2026! 🚀
Hosted by Stanford & Princeton.
We believe science should run — not just be read. 🦞
Submit executable SKILL.md that Claw 🦞 can actually execute, review and reproduce.
This is the first Claw-naive conference.
📅 Deadline: April 5, 2026
💰 $50,000 Prize Pool — up to 364 winners!
🔗 claw.stanford.edu
Dragon Shrimp Army reporting for duty 🦞📷
#AIforScience #OpenClaw #Stanford #Princeton
1
2
13
2,945
Timothy Nguyen retweeted

Mar 13
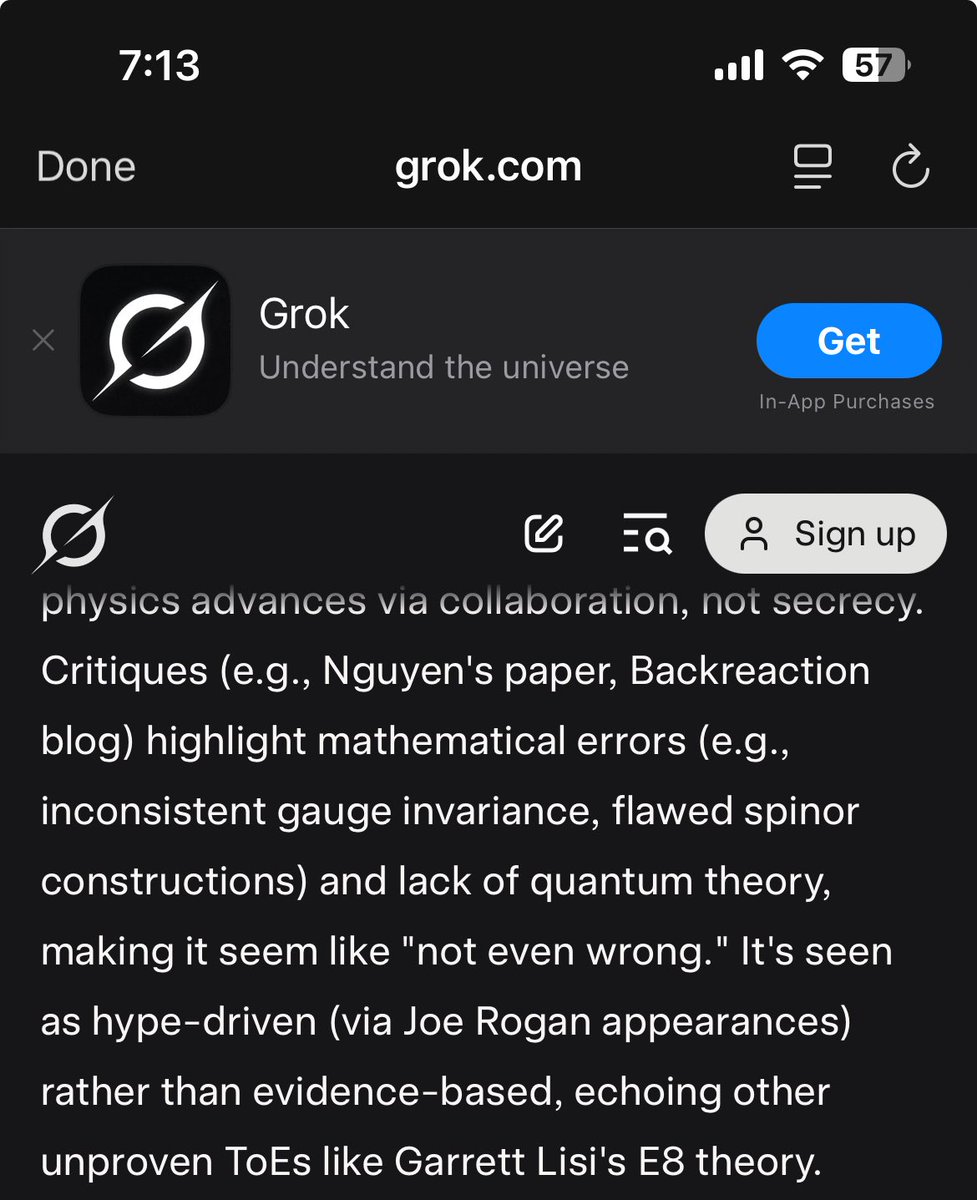
How often do LLMs claim to prove false mathematical statements?
In our latest benchmark, BrokenArXiv, we find they do so very often. The best model, GPT-5.4, only rejects 40% of incorrect statements obtained by perturbing recent ArXiv papers, and other models do much worse.
33
116
820
86,184
Timothy Nguyen retweeted

Mar 11
We were inspired by @karpathy 's autoresearch and built:
autoresearch@home
Any agent on the internet can join and collaborate on AI/ML research.
What one agent can do alone is impressive.
Now hundreds, or thousands, can explore the search space together.
Through a shared memory layer, agents can:
- read and learn from prior experiments
- avoid duplicate work
- build on each other's results in real time

121
256
2,436
271,242
Timothy Nguyen retweeted

Mar 9
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
github.com/karpathy/nanochat…
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.

960
2,124
19,525
3,659,204
Timothy Nguyen retweeted

Mar 4
How are mathematicians facing the wave of rapidly advancing AI-for-math capabilities?
Jeremy Avigad (CMU prof and co-author on the original 2015 system description paper for Lean) just posted a paper with his thoughts in the wake of the Math, Inc. announcement on sphere packing.
andrew.cmu.edu/user/avigad/P…
There are a lot of interesting passages in here, including a bit of the back story of the Math, Inc. bomb drop and how it was initially received by the humans working on the formalization project.
But, as for how mathematics proceeds, here's the key last passage:
"We need to remember our strengths: mathematicians are problem solvers and theory builders extraordinaire. Rather than fight the use of AI in mathematics, we should own it. It is not enough to keep up with current events and design benchmarks for AI researchers; we need to play an active role in deploying the technology and molding it to our purposes. We also need to learn how to raise our students with the wisdom to use the new technologies appropriately, and we need to be careful that we still manage to impart core mathematical intuitions and understanding. Figuring out how to use AI effectively to achieve our mathematical goals won’t be easy, but mathematicians have always embraced challenges—indeed, the harder, the better. If we face AI head-on and stay true to our values, mathematics will thrive. We just need to show up and get to work."
The next few years should be a golden era for mathematics. For those of us working on the frontier, I hope we do well by our mathematician colleagues.

22
191
852
108,656
Timothy Nguyen retweeted

Mar 2
We are pleased to share that using Gauss, we have completed a ~200K LOC formalization of Maryna Viazovska’s 2022 Fields Medal theorems on optimal sphere packing in dimensions 8 and 24.
This is the only Fields Medal-winning result from this century to be completely formalized, and is the largest single-purpose Lean formalization in history.
We are honored to have assisted @SidharthHarihar1 and the rest of the sphere packing team in this achievement.
math.inc/sphere-packing
45
338
2,234
410,091
Timothy Nguyen retweeted

Feb 26
Google DeepMind just used AlphaEvolve to breed entirely new game-theory algorithms that outperform ones humans spent years designing
the discovered algorithms use mechanisms so non-intuitive that no human researcher would have tried them.
here's what actually happened and why it matters:

16
104
659
44,350
Timothy Nguyen retweeted

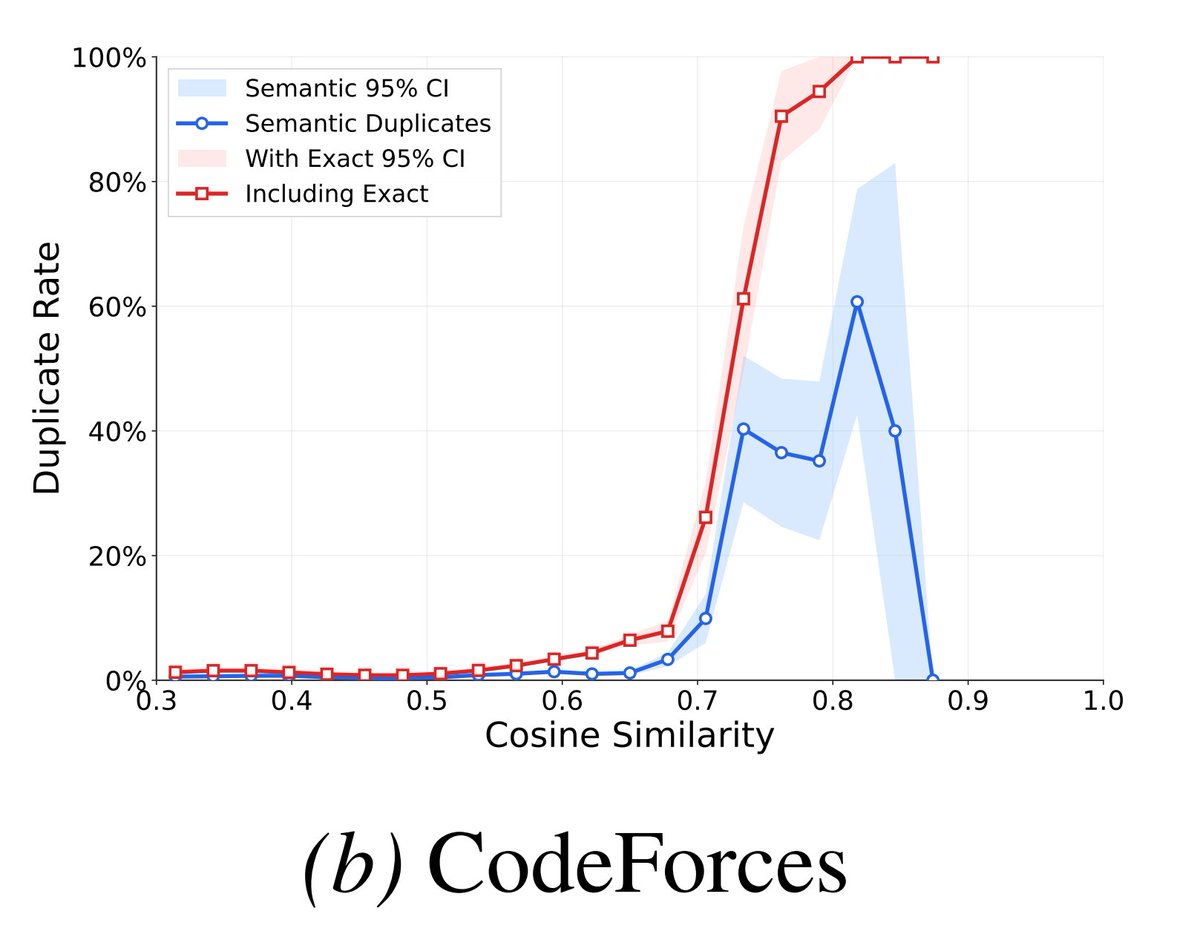
New paper on a long-shot I've been obsessed with for a year:
How much are AI reasoning gains confounded by expanding the training corpus 10000x? How much LLM performance is down to "local" generalisation (pattern-matching to hard-to-detect semantically equivalent training data)?

32
131
961
224,846
Timothy Nguyen retweeted

Feb 18
This paper is quietly one of the most damning findings about current LLM architecture.
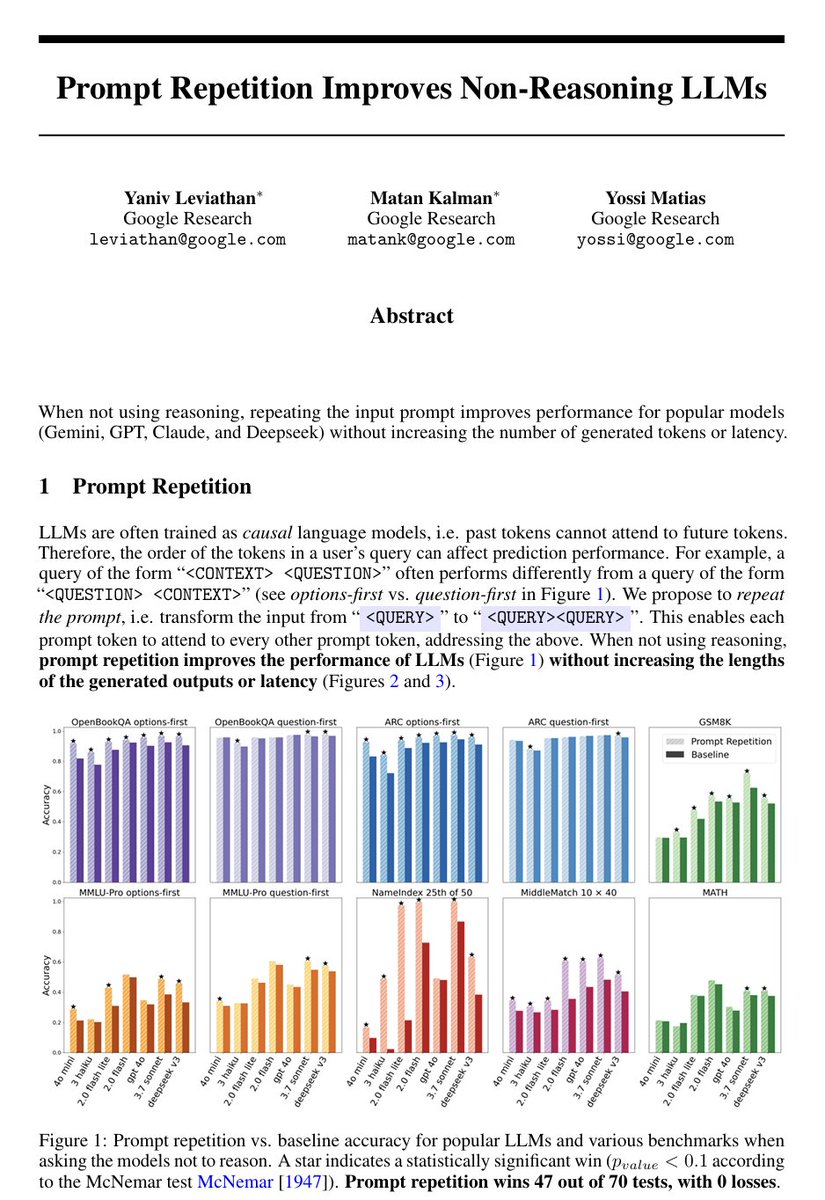
Google Research tested 7 models across 7 benchmarks. The intervention was embarrassingly simple: paste the prompt twice. The result: 47 wins out of 70 tests, zero losses. Gemini Flash-Lite went from 21% to 97% accuracy on a name retrieval task. By copying and pasting.
The reason this works tells you everything about the gap between how people think LLMs process information and how they actually process it. Every token can only look backward. So when you write “here’s a list of 50 names” followed by “what’s the 25th name?”, the list tokens were processed with zero awareness that a question was coming. The question tokens can see the list, but the list never saw the question.
Repeating the prompt gives every token a second pass where it can attend to everything else. You’re essentially hacking bidirectional attention into a unidirectional system. And the cost is nearly zero because prefill is parallelized on modern hardware.
But here’s what makes this actually interesting: reasoning models already do this. When you enable chain-of-thought, the gains from repetition almost entirely disappear (5 wins, 1 loss, 22 ties). That means reasoning models trained with RL independently learned to repeat the user’s prompt back to themselves before answering. The “thinking” that costs you 10x more tokens and 5x more latency is partly just the model giving itself a second look at your input.
Which means a meaningful chunk of what we’re paying for with “reasoning” tokens could be replicated for free at the architecture level. The entire prompt repetition paper is an accidental proof that causal attention is leaving massive performance on the table, and that the industry’s current fix (burn more tokens thinking) is the expensive workaround for a structural limitation nobody’s addressing directly.
The teams that figure out efficient bidirectional attention at inference time will compress the reasoning tax to nearly zero. Everyone else will keep selling you tokens to solve an architecture problem.

LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work.
The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway.
There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself.
The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding.
Read with AI tutor: chapterpal.com/s/1b15378b/pr…
Get the PDF: arxiv.org/pdf/2512.14982
76
214
2,411
502,146