
Join our community to explore agentic AI, data science & cloud tech through tutorials, challenges & expert insights. Build skills, learn & grow with us.
Joined September 2008
- Tweets 84,479
- Following 34,587
- Followers 121,982
- Likes 9,336
11,694 Photos and videos













IBM Developer retweeted

Jun 11
I’ll be talking to @KateHolterhoff and you can watch us chat about Agentic AI and share thoughts around how software teams work in this brave new world.
Register. It’s free.
23 June 2026 at 13:30 GMT-4
#RedMonk #IBM
ibm.com/forms/mkt-webinar-90…
@IBM
1
8
12
1,095

Jun 9
Working toward a HashiCorp Pro certification?
Knowing the product and being prepared for the exam aren’t always the same thing. 😅
1
5
1,452
Jun 9
Join HashiCorp experts on June 10 for Preparing for a Professional-level HashiCorp Certification Exam (Vault & Terraform).
Prep tips and more in the live Q&A: ibm.co/6013E3MEx
2
1,052
Jun 9
Build AI agents and MCP tools in watsonx Orchestrate using IBM Bob. 🏗️
In this walkthrough, Ahmed Azraq shows how to build an MCP server with Bob, from designing to implementation.
🎥: ibm.co/6012E3z5m
4
5
39
6,550
Jun 4
The AI Builders Challenge with IBM Bob is now open for university students.
That AI project you've been thinking about? 👀
Build it. 🏗️
1
3
5
2,039
Jun 4
Take it from idea to reality—and compete for a share of $15,000 in cash prizes.💸
1
1
2
1,956
Jun 4
Build with IBM Bob, your AI-powered development partner. Register today: ibm.biz/aibuilderschallenge
1
5
679
IBM Developer retweeted

Jun 1
everyone's building simple agents
meanwhile IBM is building robust enterprise agents in production, and it's open-source
they just dropped a blog on HF breaking down how to go beyond LLMs & agents: structured reasoning, tool use, and more to scale AI across enterprise

9
23
141
16,092
Jun 1
Building with Terraform or Vault? 🏗️
Join @HashiCorp experts for live exam prep sessions designed to help you assess your knowledge, brush up on key concepts, and prepare for certification.
Sign up today → ibm.co/6045EMUo5
1
5
1,035
May 29
New to IBM Bob? This quickstart helps you get started with:
🧰 Environment setup
📂 Codebase exploration
🛠️ Feature development
🔄 Testing changes
2
5
9
1,523
IBM Developer retweeted

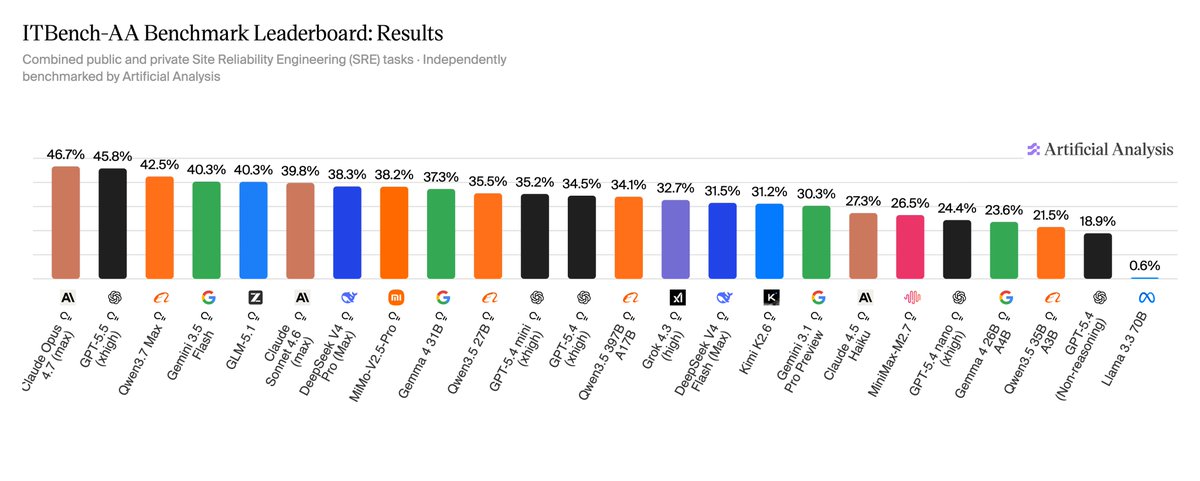
Artificial Analysis and IBM Research are launching ITBench-AA, the first in a new series of benchmarks evaluating models on agentic enterprise IT tasks, starting with Site Reliability Engineering tasks where frontier models score below 50%
ITBench-AA’s SRE tasks benchmark model performance on Kubernetes incident response, where models must diagnose live systems by reading logs, tracing dependencies, and identifying root-cause entities across complex infrastructure. The underlying ITBench dataset has been developed by @IBM's Software Innovation Lab, leveraging IBM’s deep expertise in enterprise IT operations
Artificial Analysis has worked closely with IBM over the last 6 months to develop a implementation of the dataset for frontier AI evaluation, beginning with Site Reliability Engineering (SRE) and expanding to Financial Operations (FinOps) and Chief Information Security Officer (CISO) tasks over time
ITBench-AA SRE overview:
➤ 59 SRE tasks in total: 40 public tasks and 19 brand new, held-out tasks
➤ Each task provides a Kubernetes incident snapshot containing alerts, events, traces, metrics, logs, and application topology. The model must identify the minimal set of independent root-cause Kubernetes entities responsible for the incident
➤ Faults span typical SRE failure modes including infrastructure, service, application, and chaos-injected incidents, such as resource quota exhaustion, rollout failures, connection pool exhaustion, and network partitions
Methodology details:
➤ Agentic harness: each task is solved by the model running in our open-source Stirrup reference harness, with shell access to a sandboxed file system containing the relevant logs and snapshots. 100-turn cap per task, 3 repeats per task
➤ Models submit a list of root-cause entities (Kubernetes Deployments, Services, Pods, etc.) they believe caused the incident. Each submission is compared against a ground-truth set of root causes provided by IBM Research
➤ Scoring uses average precision at full recall: if a model misses any of the ground-truth root causes, it scores 0.0 for that repeat. If it identifies all of them, it is awarded a score equal to its precision - the share of its submitted entities that are actual root causes, i.e. true positives / (true positives false positives). The headline score is the average across 59 tasks × 3 repeats.
➤ The harness (Stirrup) is held constant across all evaluated models, allowing an apples-to-apples comparison between models.
Key findings:
➤ Claude Opus 4.7 (Adaptive Reasoning, Max Effort) leads at 47%, followed by GPT-5.5 (xhigh) at 46% and Qwen3.7 Max at 42%
➤ All frontier models score below 50%, making ITBench-AA SRE one of the least saturated agentic benchmarks in our suite. For context, frontier models score considerably higher on Terminal-Bench
➤ Turn counts vary nearly 3x and longer trajectories do not translate to higher accuracy. GPT-5.5 (xhigh) averages 31 turns per task at 46%, while Gemini 3.1 Pro Preview averages 83 turns at 30%. Models that over-investigate tend to surface upstream fault-injection mechanisms or co-occurring symptoms as false positives
➤ GLM-5.1 (Reasoning) leads open weights models at 40%, effectively tied with Gemini 3.5 Flash (high). DeepSeek V4 Pro (Reasoning, Max Effort) follows at 38%, with Gemma 4 31B (Reasoning) at 37%, ahead of Gemini 3.1 Pro Preview at 30%
32
78
554
200,596
May 27
Another IDE? There are already too many of those.
Nicholas Renotte gives an honest review of IBM Bob and what it actually feels like to build with it.👇
1
13
1,749
May 22
Top 5 Horror Movies
1. “The PM vibe-coded a feature and it needs to ship today.”
2. 123918, -1012
3. “I pushed the wrong migration to production.”
4. “What’s staging?”
5. "We don't have an on-call rotation; it hasn't come up."
5
1,094
May 21
3
706
May 20
Writing the playbook is only part of the work. The real overhead is:
⚙️ handlers
👥 roles
📄 templates
🔄 conventions
📚 docs
@alexsotob shows how Bob can generate and organize that scaffolding automatically: ibm.biz/~t0WMP3FIA
2
7
842
IBM Developer retweeted

Expose a Legacy Java App as an MCP Server Using a Kubernetes Sidecar Expose a Legacy Java App as an MCP Server Using a Kubernetes Sidecar:
🏗️: No changes on the legacy app
🛳️: Using Containers and Kubernetes
♻️: No side effects
youtube.com/watch?v=3llzsh4U…
1
1
4
1,804
May 18
Turn YouTube videos, podcasts, and conference talks into searchable knowledge.
@SonicDMG shows how to use Docling OpenRAG to:
🎤 extract transcripts timestamps
⚙️ build an AI-ready RAG pipeline
🔎 search exact moments from long-form videos
1
1
6
792
May 18
Find out how Docling OpenRAG make videos searchable, so you can stop scrubbing through hour-long recordings for one insight.
🎥 Full video: ibm.co/6046Ez2Ij
💻 GitHub repo: ibm.co/6047Ez2Id
3
857