
An artist & technologist, archivist, researcher. imagesnippets.com also: @zeroexp@mastodon.social , mmw09.bsky.social
Joined May 2013
- Tweets 18,394
- Following 4,346
- Followers 1,428
- Likes 61,360
157 Photos and videos





Pinned Tweet

28 Aug 2024
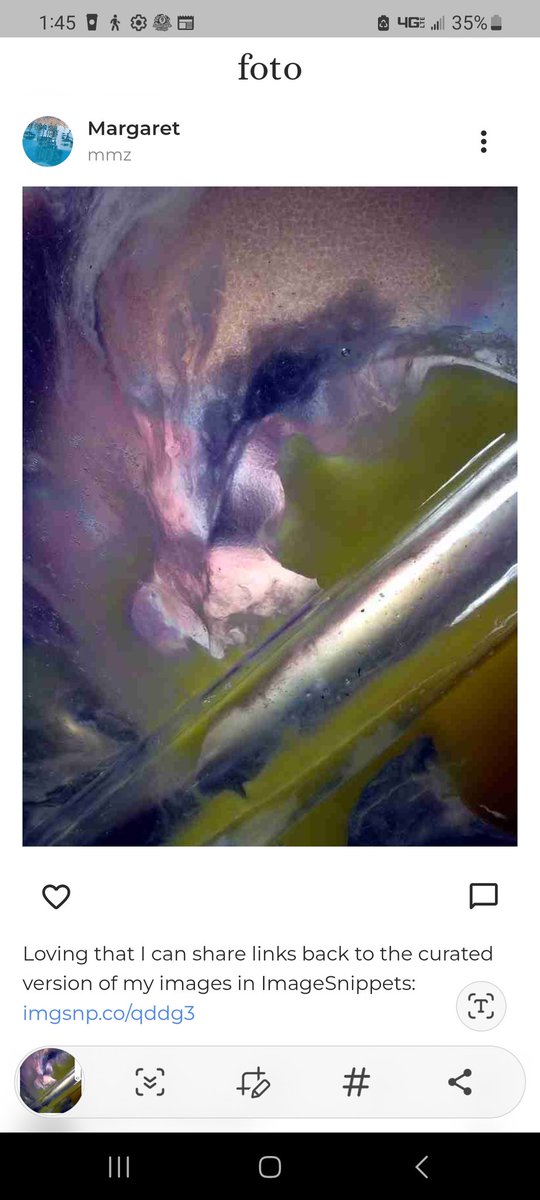
Does anyone have time for a coffee? I am busy creating new iterations of ImageSnippets to make it increasingly easier for creators to make knowledge graphs from their work and I could use your support! buymeacoffee.com/mmwis
4
264
Margaret Warren retweeted

16 Oct 2024
No more searching for how to cancel your subscriptions.
Today, the FTC finalized a "Click-to-Cancel" rule to make it as easy to cancel a subscription as it is to sign up for one.
Thank you, @linakhanFTC!
1,272
4,989
27,782
1,292,803
10 Oct 2024
Just entered to win a meditation retreat giveaway from @Happier_App, @InsMedSoc and @Spirit_Rock! Enter to win a $1,500 retreat credit and $600 travel credit and 4-year Happier meditation app subscription. Ready to elevate your practice? Enter now! happierapp.com/retreatgiveaw…
67
Margaret Warren retweeted

10 Oct 2024
A note to everyone interested in Foto. If you disagree or have a question about something we are doing, please ask us.
Jumping to conclusions and blasting us on social media without asking us is frustrating.
I respond to every email. Our email is in the footer of our website.
2
4
23
1,255
7 Oct 2024
This is absolutely fantastic and we could actually store this information with linked data :-)
7 Oct 2024


2
108

Margaret Warren retweeted


62
607
9,270
509,647

Margaret Warren retweeted

2 Oct 2024
Susan Kare was an early Apple artist who designed many of the fonts, icons, and images for Apple, NeXT, Microsoft, and IBM (1980s).



7
64
1,168
203,948
Margaret Warren retweeted

2 Oct 2024
The tiny egg and the life it produced
📹 Adrian Kozakiewicz
111
508
3,260
311,648
1 Oct 2024
47
Margaret Warren retweeted

30 Sep 2024
Microsoft Project Silica is looking at this: x.com/microsoftcanada/status…
4
10
155
55,476

Presents MIO, a foundation model built on multimodal tokens using causal multimodal modeling
Demonstrates huge potential due to its any-to-any understanding and generation. Capabilities include interleaved video-text generation, chain-of-visual-thought reasoning, and visual guidelines generation.

6
35
214
31,473
Margaret Warren retweeted

26 Sep 2024
Born on this day in 1749, Abraham Gottlob Werner created a pioneering nomenclature of nature's colors, which Darwin took with him on the Beagle themarginalian.org/2018/02/0…
7
26
8,326
Margaret Warren retweeted
25 Sep 2024
OK - found them again. also if you go to getpmd : getpmd.iptc.org/getpmd/html/… and paste the link as .jpg, you can see the copyright is embedded in the image.
1
40
Margaret Warren retweeted
25 Sep 2024
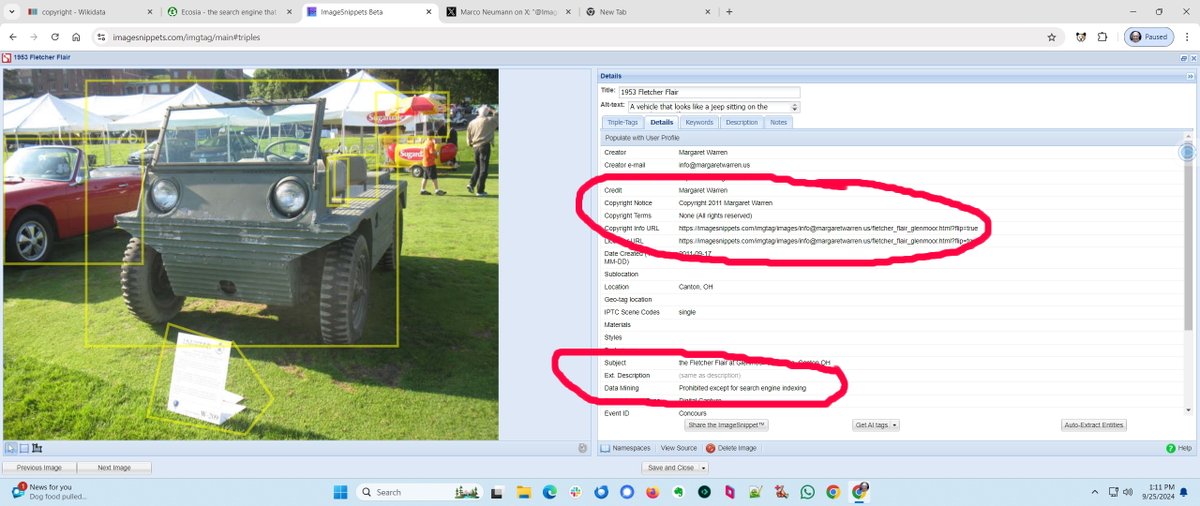
not sure completely about wikidata properties for this. I looked up copyright in wikidata and there are 2 Q entities at least. See the areas in this image. If you put nothing for copyright/license URL, we fill it in. This is also added to triple store &embedded in image.
6
1
55
Margaret Warren retweeted
25 Sep 2024
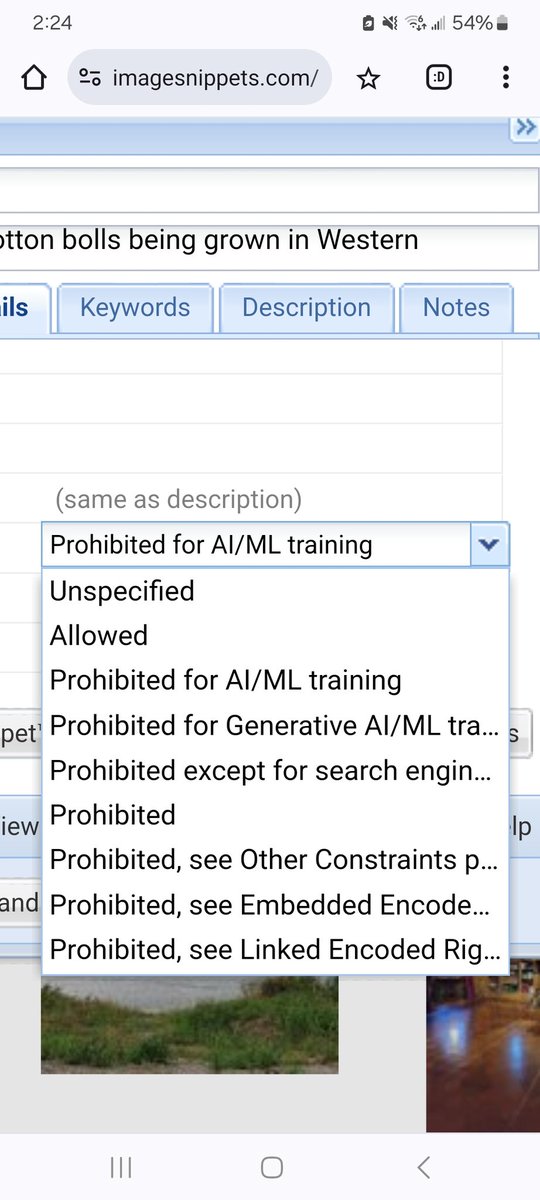
So - as far as I am concerned, if you add copyright/data mining intentions in the details tab, we are doing as much possible to allow users to store/indicate what they want. I cannot guarantee what people who steal will do or companies that scrape and ignore
1
1
33
Margaret Warren retweeted
25 Sep 2024
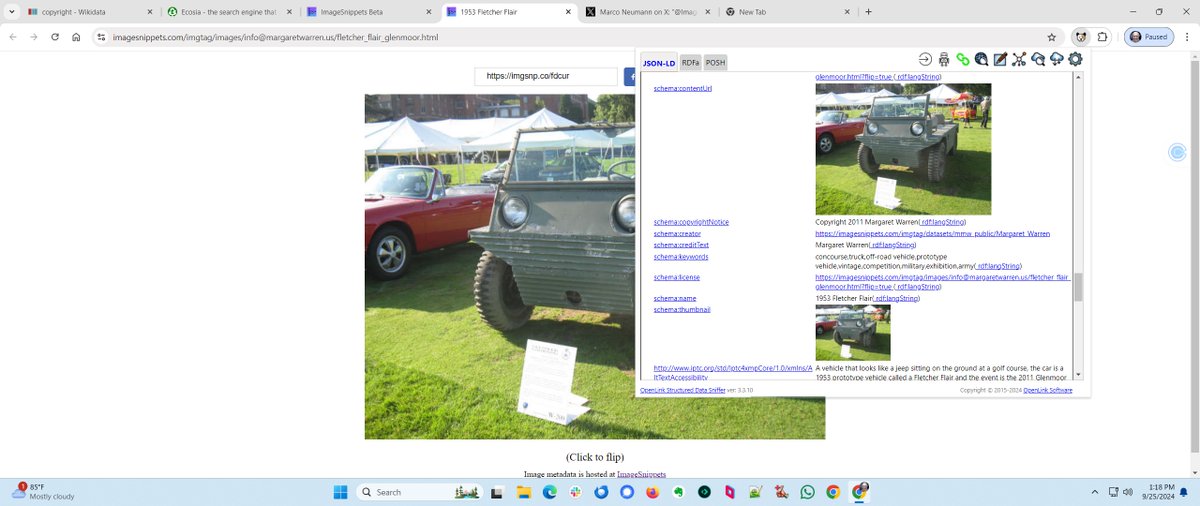
if you search Google for 'Fletcher Flair', this is image is literally the 1st result in the main search, then if you click on the 'image search', it is in the top row and has a 'licensable' badge on it. See this image - look in the panel to the right. It clearly shows copyright.
3
1
42
Margaret Warren retweeted

24 Sep 2024
“Robots.txt is like putting up a ‘no trespassing’ sign. This is like having a physical wall patrolled by armed guards.”
—@eastdakota
That’s great—but it shouldn’t require virtual warfare to protect artists’ consent. That’s a failure of governance. wired.com/story/cloudflare-t…
1
6
54
1,287
Margaret Warren retweeted

24 Sep 2024
Data federation now :)
Cf. Tbl 15 and more years ago: youtu.be/HeUrEh-nqtU?si=k5xb…
research.google/blog/groundi…
1
4
280
Margaret Warren retweeted

19 Sep 2024
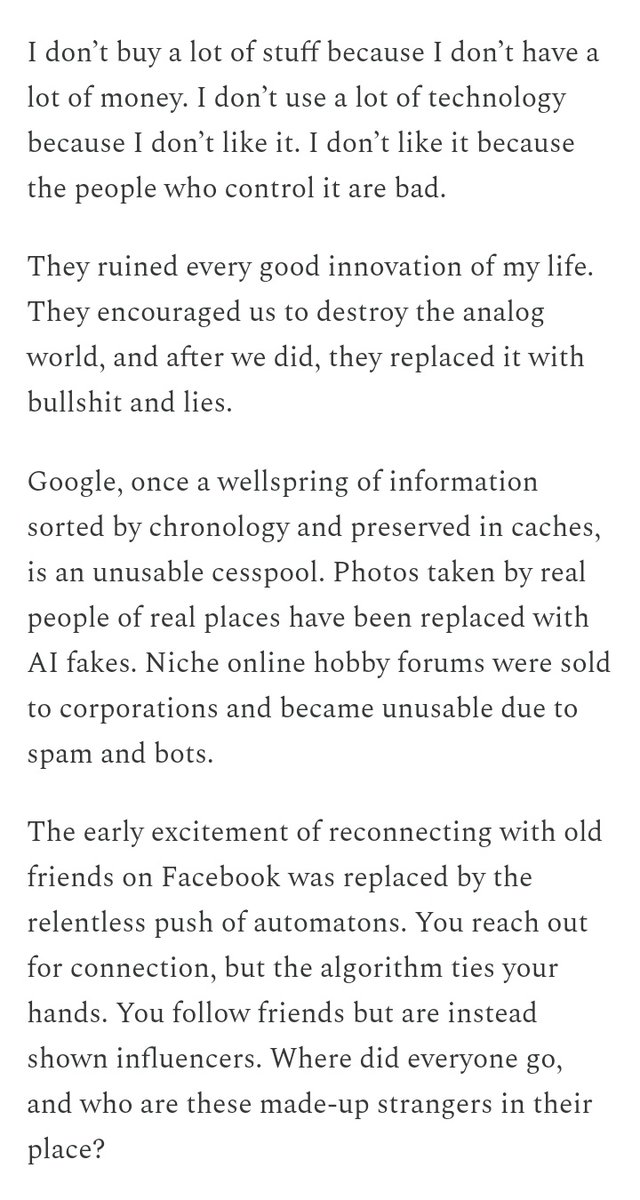
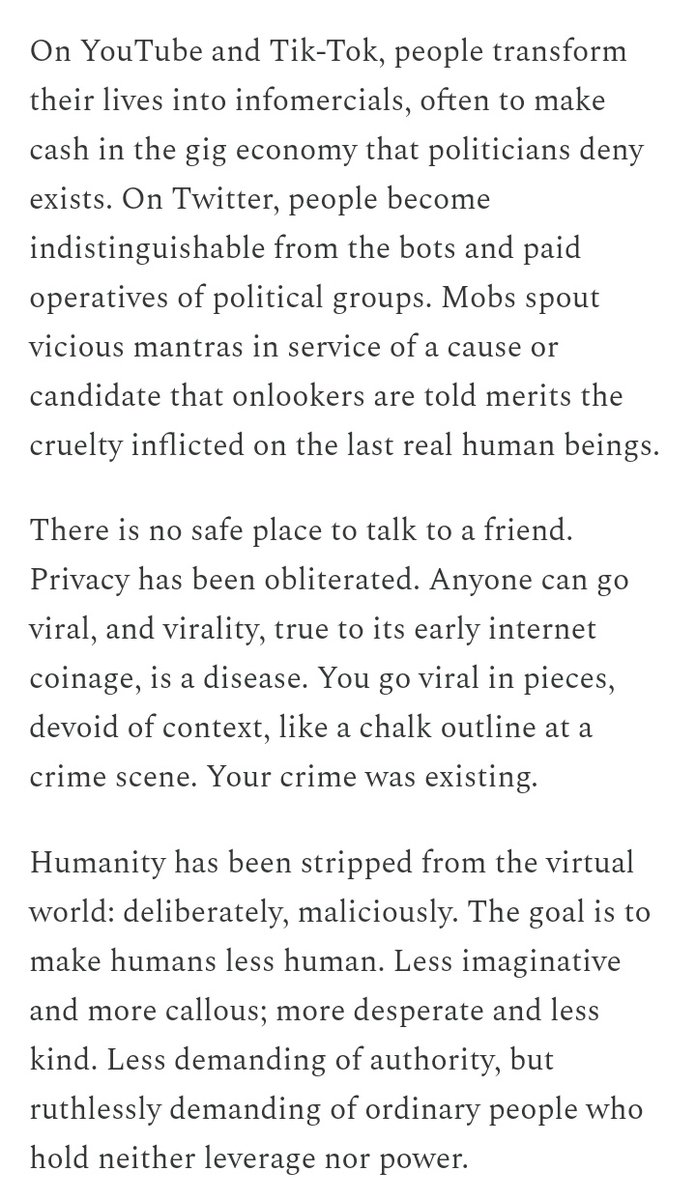
"Humanity has been stripped from the digital world: deliberately, maliciously."
64
1,588
4,484
531,737