
Professor of Emergency Medicine, FEMAT, FTBEM @marmaraacil • #MedEd PhD • @akamedika @acilci_net • 🎸
Joined March 2009
- Tweets 3,000
- Following 1,772
- Followers 5,140
- Likes 3,559
279 Photos and videos











Jun 13
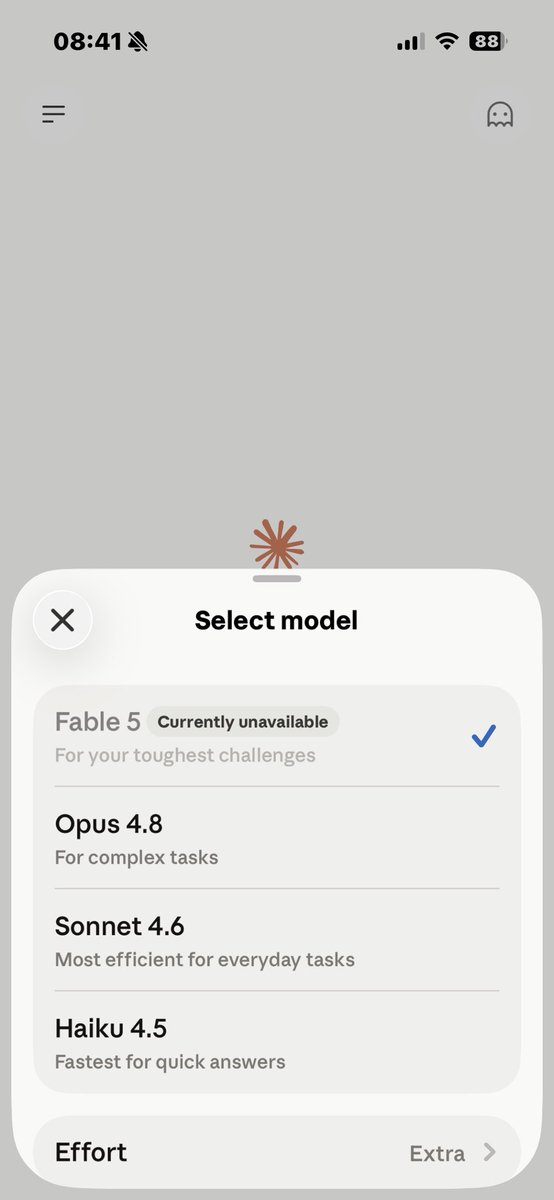
ABD vatandaşı olmayanların Fable 5 erişimi kısıtlandı.
1
1
1,206
Jun 10
Yeni başlayanlar için hızlandırılmış Google Gemini yeni arayüzü tanıtımı ve temel fonksiyonlar (Haziran 2026)
Videomuz akamedika YouTube kanalında yayında…
youtu.be/gwKS-FYCLA0
1
264
Haldun Akoglu retweeted

Jun 9

10
60
219
35,252
Haldun Akoglu retweeted

Jun 9
I just got bullied by AGI


Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
313
313
7,802
697,586
Jun 9
Claude Fable da acil servis kalabalıklığı, mortalite, hatalar ve şiddetin en önemli sebebinin yatamayan hasta ve yatış bloğu olduğunda hemfikir. Acil servis sorunlarının büyük kısmının sebebi acil değil hastanenin operasyonel akış problemleridir.
Uzm Dr Mustafa Altun tezinden beri bu alanda çalışıyor ve tüm senaryolarda kalabalık sebebi operasyonel hastane sorunları.
Bu alanda ülkemizde en çok yayın yapan araştırmacılardan biri olma yolunda hızla ilerleyen sevgili Mustafayı da tebrik ediyorum.
@TrTATD
1
2
8
1,420
Jun 9
🧬 Anthropic de bugün ikiz bir lansman yaptı: Bugüne kadarki en yetenekli modeli Claude Fable 5 ve sadece sınırlı bir güvenlik/altyapı grubuna sunulan Mythos 5.
Aslında ikisi de aynı temel model. Aralarındaki fark, üzerlerindeki güvenlik kısıtlamalarında. Bir araştırmacı gözüyle dikkat çeken teknik detaylar:
1️⃣ Mythos sınıfı Opus’un üstünde yeni bir kademe. Fable 5, test edilen neredeyse tüm yetenek ölçütlerinde en son teknoloji. Görevi ne kadar uzun ve karmaşıksa, diğer modellere üstünlüğü o kadar artıyor.
2️⃣ Bilimde gerçek bir eşik aşılıyor: özgün hipotez üretimi. Mythos 5, tutarlı biçimde yeni ve ikna edici bilimsel hipotez üreten ilk model olarak tanıtılıyor. Bir E. coli proteinine dair önerdiği yeni mekanizma, aynı problem üzerinde bağımsız çalışan bir laboratuvarın bulgusuyla doğrulanmış.
3️⃣ İlaç tasarımında ~10 kat hızlanma. Mythos 5, protein tasarım araçlarıyla insan yardımı olmadan bağlanma bölgesi seçme, araç çalıştırma ve hatalardan toparlanma gibi normalde bir bilim insanının yaptığı işleri yürütmüş. 14 protein hedefinden 9’u güçlü aday ilaç olarak belirlenmiş.
4️⃣ Fable 5 siber güvenlik, biyoloji/kimya konularında bir sınıflandırıcı sistemiyle geliyor. Riskli sorgu yakalandığında model reddetmiyor; yanıtı bir alt model olan Opus 4.8‘e devrediyor ve kullanıcı bilgilendiriliyor. Akademik biyomedikal kullanım için ayrı bir güvenilir erişim programı da açılacak.
👨💻 Klinik araştırma metodolojisi açısından en çok düşündüren nokta şu: Bir model artık literatürü özetlemekle kalmıyor, sınanabilir hipotez öneriyor ve bunların bir kısmı deneysel olarak da doğrulanmış durumda. Geldiğimiz nokta, AI destekli araştırma aşamasından AI tarafından yürütülen araştırmalara geçiş. Hipotez kaynağının şeffaflığı, ön-kayıt (preregistration) ve yazarlık/katkı atfı gibi metodolojik soruları ne yapacağımız ise henüz belirsiz.
Sizce otonom hipotez üreten bir model, araştırma tasarımında bir hızlandırıcı mı, yoksa kanıt zincirinin şeffaflığı açısından yeni bir denetim yükü mü? Yorumlarda konuşalım.
#ClaudeFable5 #YapayZeka #AkademikAraştırma #ClinicalResearch #DrugDiscovery #AIinScience
1
175
Jun 9
Google YZ destekli canlı çeviri hizmetini hizmetini aktive ediyor…

For over 20 years, we've dedicated ourselves to removing language barriers so people can learn, speak and connect more deeply than ever before.
Today, we’re taking our next step with the release of Gemini 3.5 Live Translate — our latest audio model for live, speech-to-speech translation across 70 languages. 🧵

ALT The logo for Gemini 3.5 Live Translate, featuring the multicolored Gemini logo next to black text on a soft, light blue gradient background.
175
Jun 9
🔬 NotebookLM büyük bir sıçrama yaptı ve bu sefer mesele özet çıkarmak değil, gerçek araştırma yapmak.
Google, NotebookLM’e dün kapsamlı bir güncelleme getirdi. Aylardır akademik camiaya bu aracı anlatan biri olarak, bu sürümün önceki tüm sürümlerden niteliksel olarak farklı olduğunu söyleyebilirim.
Öne çıkan teknik detaylar şu şekilde;
1️⃣Yeni motor: Gemini 3.5 Antigravity. Daha doğru, daha izlenebilir bir akıl yürütme süreci. Artık modelin nasıl düşündüğünü de görebiliyorsunuz.
2️⃣Her not defterine gömülü bir güvenli bulut bilgisayar. NotebookLM artık kod yazıp çalıştırabiliyor yani gerçek veri analizi yapabiliyor. 100’den fazla küratörlü yazılım becerisi (skill) devrede.
Çakışan formatlardaki verileri birleştirip analiz ettirmek, web’den ek bağlam toplatmak ve sonucu rapora dökmek artık tek akış içinde mümkün.
3️⃣Ölçülebilir kalite artışı. Google’ın kendi karşılaştırmalarında yeni sistem, beş temel boyutta ortalama e kazanma oranı (pariteye göre 15 puan üstü) elde etmiş. Uzun belge analizinde i,9, gelişmiş web araştırması ve kaynak keşfinde ise x,2 kazanma oranı bildiriliyor. Akademik açıdan en dikkat çekici kalem bu son ikisi.
4️⃣Zengin çıktı formatları artık var ve bunlar düzenlenebilir.
📈Grafik ve veri görselleştirmeleri (png, svg)
📑Belgeler (PDF, docx, markdown)
🎑Nano Banana ile görseller
👨💻Yapılandırılmış veri (csv, json)
📊Excel (xlsx)
🖥️ PowerPoint (pptx). Üretildikten sonra üzerinde değişiklik de yapabiliyorsunuz.
5️⃣Önce kaynak getir şartı kalktı. Eskiden kaynaklarınızla gelmeniz gerekiyordu; artık dağınık bir fikirle başlayıp NotebookLM’in sohbet içinde kaynak havuzunuzu kurmasına izin verebiliyorsunuz. Google Search ile nitelikli kaynakları buluyor, hatta farklı dillerdeki birincil kaynakları getiriyor. Kontrol sizde kalıyor: hangi kaynağı eklediğiniz size bağlı ve tüm kaynaklar atıflanıyor ki bu, akademik kullanım için olmazsa olmaz.
Erişim: Bugünden itibaren web’de global olarak Google AI Ultra ve ilgili Workspace iş hesaplarına açılıyor.
Bu güncellemeyle NotebookLM, okuma asistanından araştırma ortağına geçiyor. Aracın temel mantığını, akademik iş akışına nasıl oturduğunu daha önce Akamedika kanalında detaylıca anlatmıştım yeni özellikleri o temelin üzerine koyunca tablo iyice netleşiyor:
👉 youtu.be/7cdkYUVEhsE?si=4CtS…
Sizce kod çalıştırma ve otomatik kaynak keşfi, akademide kaynak doğrulama ve şeffaflık açısından bir kazanım mı, yoksa yeni bir risk katmanı mı?
Yorumlarda tartışalım.
#NotebookLM #YapayZeka #AkademikAraştırma #Gemini #ClinicalResearch #AItools
1
1
8
1,245
Haldun Akoglu retweeted
Jun 3
Hasta başında kullanmak için kendi geliştirdiğiniz, vibe coding yaptığınız uygulamalarınız var mı?
Yarın başlayacak “Yapay Zeka ve Simülasyon” kongresindeki konuşmada uygulamanızı göstermemi isterseniz benimle paylaşabilir, bu postun altına yazabilirsiniz.
aisim2026.com/
2
2
162
Haldun Akoglu retweeted

May 24
Fisher’ın Rothamsted Yılları
Haldun Akoğlu @istanbulemdoc @acilci_net için yazdı:
acilci.net/fisherin-rothamst…
#FOAMed #İstatistik #RonaldFisher

2
3
300
Haldun Akoglu retweeted

May 22
Our new @NatureMedicine Perspective argues that uncritical use of #AI in early medical training may weaken independent clinical reasoning, and proposes a framework for integrating AI while protecting core competencies.
nature.com/articles/s41591-0…
@NaturePortfolio @dukenus #DukeNUS

4
62
205
14,972
May 24
Fisher’ın Rothamsted Yılları
1919 baharında, 29 yaşında bir adam karısını, kayınvalidesini ve üç çocuğunu da yanına alıp Londra’nın kuzeyindeki kırsal bir çiftliğe taşındı. Şehirden uzak, açık tarlaların ve sessiz yolların ortasında yer alan bu yeni ev, aile için hem bir başlangıç hem de bir belirsizlik anlamına geliyordu. Kapının hemen yanı başında ise doksan yıllık deri ciltli not defterleriyle dolu bir tarımsal araştırma istasyonu duruyordu; yıllar boyunca toplanmış gözlemler, kayıtlar ve deneylerle dolu bu eski arşiv, çiftliğin günlük yaşamına neredeyse gölge gibi eşlik ediyordu.
Adam, Ronald Aylmer Fisher’dı.
Ve gidecek başka bir yeri yoktu.
İstatistik hakkındaki en keyifli kitaplardan Lady Tasting Tea pazar okumalarının 3.bölümünü aşağıdaki bağlantıdan okumaya devam edebilirsiniz.
akamedika.com/blog/fisherin-…
acilci.net/fisherin-rothamst…
101
May 17
Yapay zeka tarafından hazırlanan ve yazarlar tarafından içeriğinin kontrol edilmedigi belirlenen yazıların geri çekilmesi süreçleri başladı.
60
Haldun Akoglu retweeted

Mar 27
I’ve recently decided to no longer accept requests as a reviewer for scientific papers. Current top AI models do a better job than me for more than 95% of the review process, so with less than 5% effort, it would not be fair for me to take credit & journals don’t like it anyway.
76
47
544
51,513
Mar 26
Geçen hafta ICML 2026’nın yapay zeka kullanım politikasını ihlal eden hakemlerden gelen 497 makaleyi reddettiği haberi çıktı.
Yöntem akıllıca: makalelere LLM’nin göreceği ama insanın göremeyeceği gizli tuzak ifadeler yerleştirmişler. Hakem YZ kullandıysa, YZ bu ifadeleri review’a ekliyor. Suçüstü.
Şimdi asıl soruyu soralım:
Bu insanlar neden YZ kullandı?
Çünkü kötü niyetliler mi? Belki bazıları.
Yoksa çünkü ICML’e her yıl on binlerce makale geliyor, karşılıklı hakemlik zorunluluğu var, hakemlik ücretsiz, süresi kısa, sayısı fazla ve kimse teşekkür bile etmiyor?
Büyük ihtimalle ikincisi.
Sorun hakem tembel ya da dürüst değil.
Sorun yapısal: akademik sistemde hakemlik, gönüllü emeğe dayalı, teşviksiz, tanınırlığı olmayan, neredeyse cezalandırıcı bir yük haline geldi.
Araştırmacıları tuzağa düşürmek yerine şunu sorsaydılar daha ilginç olurdu: “Neden bu kadar çok insan politikayı ihlal etme riskini göze aldı?”
Bir de şu var: ICML aynı zamanda iki ayrı stream açtı: LLM kullanımına izin veren ve yasaklayan.
Yani organizasyon aslında şunu kabul ediyor: YZ kullanımı kaçınılmaz ve meşru olabilir.
O zaman biri bana şunu açıklasın:
Aynı LLM’yi makale yazmak için kullananın makalesi kabul ediliyor. Aynı LLM’yi hakemlik yapmak için kullananın makalesi reddediliyor.
Mantık tutarlı mı?
Kural ihlalini cezalandırmak meşru.
Buna itirazım yok.
Ama 506 kişi aynı anda aynı hatayı yapıyorsa, bu artık bireysel bir etik sorunu değil — sistem tasarımı sorunudur.
Watermark’ı kaldırın, kural ihlalini değil.
Asıl soruyu sorun:
Hakemlik neden bu kadar sürdürülemez hale geldi?

A major artificial-intelligence conference has rejected 497 papers whose authors violated AI-use policies
go.nature.com/47k3qWV
1
5
1,128
Mar 26
Akademik yayıncılık sisteminin kısa özeti:
Sen araştır. Sen yaz. Sen hakemlik yap. Sen editörlük yap.
Yayıncı @ kâr marjı elde etsin.
Günde 5 gerçek hakemlik daveti alıyorum. Spam olanları saymıyorum bile.
Hepsini kabul etsem ne olur diye merak ettim ve hesapladım:
🌑 Yılda 1.825 makale.
🌑 Makale başına ortalama 7 saat.
🌑 Toplam 12.775 saat.
🌑 Bir yılda 8.760 saat var!
Yani “evet” desem, uyumadan, yemeden, nefes almadan çalışsam bile yetişemem.
Bunu fark edince sisteme biraz daha yakından baktım:
📌 Yaptığım her hakemliğin üniversite profesör maaşıma göre hesaplanan değeri yaklaşık 5.000–6.000 TL.
📌 Tüm davetleri kabul etsem yıllık maaşımın 6 katı değerinde emeği ücretsiz devretmiş olurum.
📌 Bu arada yazar, aynı makaleyi yayınlamak için 65.000–130.000 TL APC ödüyor.
📌 Elsevier 2023’te 3,6 milyar dolar kâr etti. Kâr marjı: @. Google bile bu kadar kazanmıyor.
Nasıl mı yapıyorlar?
Çok basit:
∙İçeriği araştırmacı üretir. Ücretsiz.
∙Hakemliği araştırmacı yapar. Ücretsiz.
∙Editörlüğü araştırmacı yapar. Ücretsiz.
∙Yayıncı sunucuya yükler. Milyarlarca dolar alır.
Biz akademisyenler olarak bu sistemi sadece sürdürmüyoruz — biz bu sistemi bizzat çalıştırıyoruz.
Eleştirinin kolay, çözümün zor olduğunun farkındayım.
Benim çözümüm hakemlik davetlerini çok çok seçici kabul etmek. “Hayır” demek, bilimi terk etmek değil — zamanınıza saygı göstermektir.
Artık diamond open access dergilere submit edilen, Preprint sununan dergilerin hakemliklerini özellikle kabul ediyorum. Açık hakemlik platformlarına yorumlar yapmaya başladım.
Yılda 8–12 hakemlik yapmak hem etik hem sürdürülebilir hem de kaliteli bir katkı.
1.825 değil.
Siz kaç hakemlik daveti alıyorsunuz?
Ve kaçını kabul ediyorsunuz?
6
7
32
8,382
Mar 26
Aİ sayesinde çok yakında hasta vizitlerine “klinik mühendislerimiz” de katılabilir!
Bir asistan arkadaşım geçen hafta bana “Hocam, AI her şeyi yapıyorsa bizim işimiz ne kalacak?” diye sordu. Herkesi kedine de sorduğu gibi.
Yanlış soru.
Doğru soru şu: “AI her şeyi daha verimli yapıyorsa, biz ne kadar daha fazla şey yapabiliriz?”
Jevons Paradoksu’nu hatırlayalım.
1865’te William Stanley Jevons şunu fark etti: Buharlı motorlar kömürü çok daha verimli kullanır hale geldikçe, İngiltere’nin toplam kömür tüketimi azalmadı — aksine patlama yaptı. Verimlilik, talebi kısmadı. Talebi büyüttü.
Tıpta ve klinik bilimlerde tam bunu yaşıyoruz.
Bir yazılımcı bir günde kaç satır kod yazıyordu şimdi kaç satır yazıyor? Sınav için bir günde kaç soru taslağı hazırlayabilirdiniz şimdi kaç?Bir dersin taslak metnini oluşturmak kaç gün sürüyordu, şimdi kaç dakika? Bir slayt setine daha güzel slaytlar hazırlamak kaç gün alıyordu, şimdi kaç saniye?
Fazla mesai mi yapıyoruz?
Hayır tam aksine, aynı sürede.
Peki iş azaldı mı? O da tam tersi.
Klinik araştırmada veri temizleme, istatistik yazımı, literatür taraması saatler alıyordu. Şimdi dakikalar. Peki araştırmacılar daha az çalışıyor mu? Duyduğum kadarıyla herkes daha fazla proje üstleniyor, herkes Aİ ile yapmak istediği projeleri konuşuyor.
Ben de hem akademik hayatımda hem de @Akamedika’da bunu yaşıyorum. AI ile içerik üretim sürem dramatik biçimde kısaldı. Ama o kapasite boş zamana dönüşmedi. Yeni kurslar, yeni içerikler, yeni eğitim formatları için talebe dönüştü.
Hatta @drgokhanaksel hocamın geçen bana dediği gibi: Arog’da kaset ile Kung Fu yüklenen Arif gibi olduk!
Ne olduklarını 6 ay önce bilmediğimiz node.js, react ile webapp hazırlayıp tailwind, daisyUİ ile dizayn yapıyor, online databaseler ile serverless appler hazırlıyoruz. Yazılımcı bulamadığımız, bulsak da derdimizi anlatamadığımız, anlatsak da masrafını karşılayamadığımız işler 2 saatte yapılır oldu.
Ve işte burada ekiplerin yapısı değişiyor. Bu kaba taslakları gerçek ürünle dönüştürecek uzmanlara ihtiyaç var.
Hastane sistemleri artık “klinisyen hemşire sekreter” üçlüsünün yanına bir de klinik veri mühendisi gerektiriyor. Üniversite araştırma grupları biyomedikal bilişim uzmanı istihdam ediyor. Tıp fakülteleri eğitim teknolojisi geliştiricisi kadrosu açıyor.
Klinik ekiplere mühendisler katılıyor. Bunu 5 yıl önce ciddiye alan yoktu.
Bizim için ne anlama geliyor?
Klinik akademisyenler olarak iki seçeneğimiz var:
1.AI’yi bir tehdit olarak görüp pasif kalmak.
2.Jevons’un dediği gibi: artan verimliği daha büyük problemlere yatırmak.
Ben ikincisini seçiyorum — ve çevremdeki en hızlı gelişen klinisyen-akademisyenlerin de öyle yaptığını görüyorum.
Yapay zeka rutin işi alıyor. Bize kalan, daha önce zamanımız ve bilgimiz olmadığı için yapamadığımız işler.
Bu bir kayıp değil. Bu, uzun süredir beklediğimiz fırsat.
Siz ekibinizde hangi yeni yetkinliklerin eksikliğini hissediyorsunuz? Yorumlarda görmek isterim.
5
2
24
2,873
Haldun Akoglu retweeted

Feb 20
Here’s the uncomfortable truth.
Debate only works when both sides share the same rules.
If someone is not trained in epidemiology, statistics, trial design, pharmacology, or immunology — and yet insists they can “tear apart” a paper — what they are usually tearing apart is their own misunderstanding of it.
Reading a paper is not the same as understanding it.
To interpret clinical research you need to know:
What constitutes appropriate controls
What statistical power means
Absolute vs relative risk
Confounding vs causation
Bias, multiplicity, subgroup fragility
Background incidence rates
Biological plausibility vs demonstrated effect
Without that framework, what happens is predictable:
They cherry-pick a sentence.
They confuse hypothesis with conclusion.
They elevate a limitation section into a refutation.
They mistake correlation for proof.
They declare victory.
Logic is useful. But logic applied to incomplete or misunderstood premises produces very confident nonsense.
“I’ve done my research” in these exchanges usually means:
I’ve read abstracts.
I’ve watched commentary about the paper.
I’ve searched for flaws without understanding the design constraints.
Medicine is not settled by rhetorical sparring on social media. It is settled by convergence of evidence across multiple methods, populations, and replications.
And here’s the deeper issue:
When someone demands, “Post a paper so I can dismantle it,” what they are really asking for is a performance arena. They are not participating in scientific inquiry. They are engaging in adversarial debate with asymmetrical incentives — you must defend every line; they need only sow doubt.
That is not how science progresses.
Science progresses by:
Publishing data.
Independent replication.
Methodologic critique by peers trained in the field.
Systematic review and meta-analysis.
Not by quote-tweet cross-examination.
There is a difference between healthy skepticism and recreational contrarianism.
The former advances knowledge.
The latter performs doubt.
And performing doubt is much easier than doing the work.
40
148
720
21,269
Feb 21
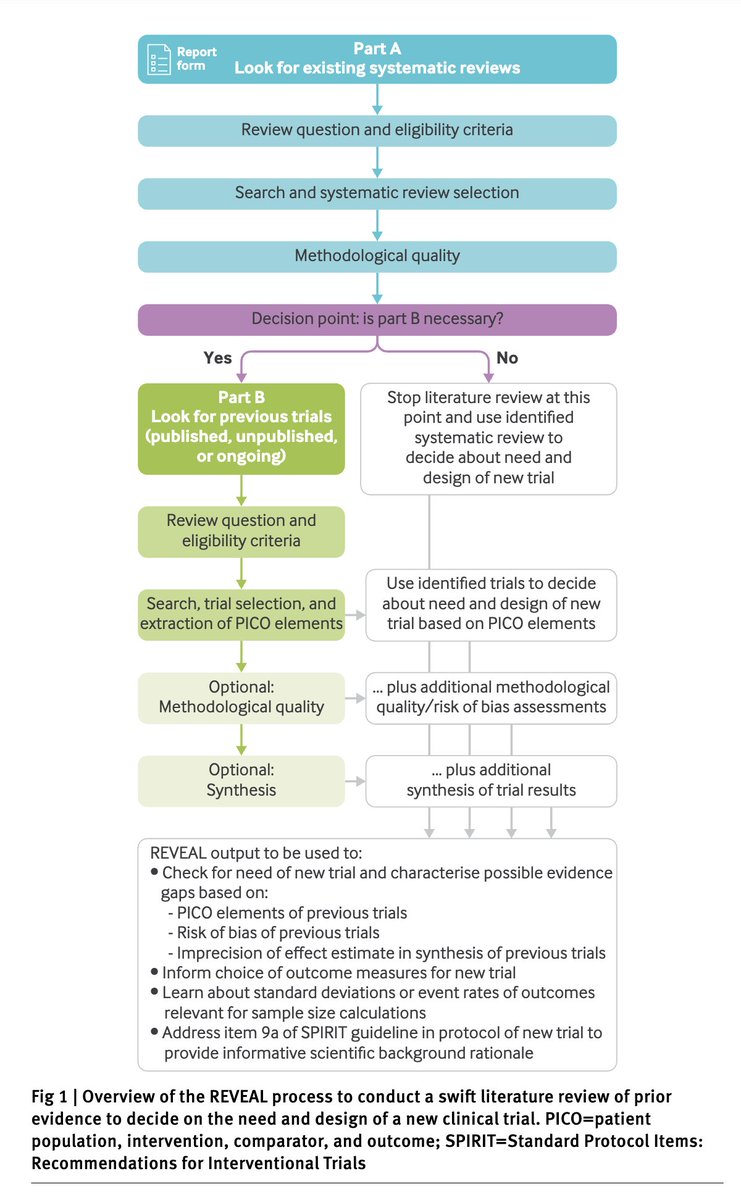
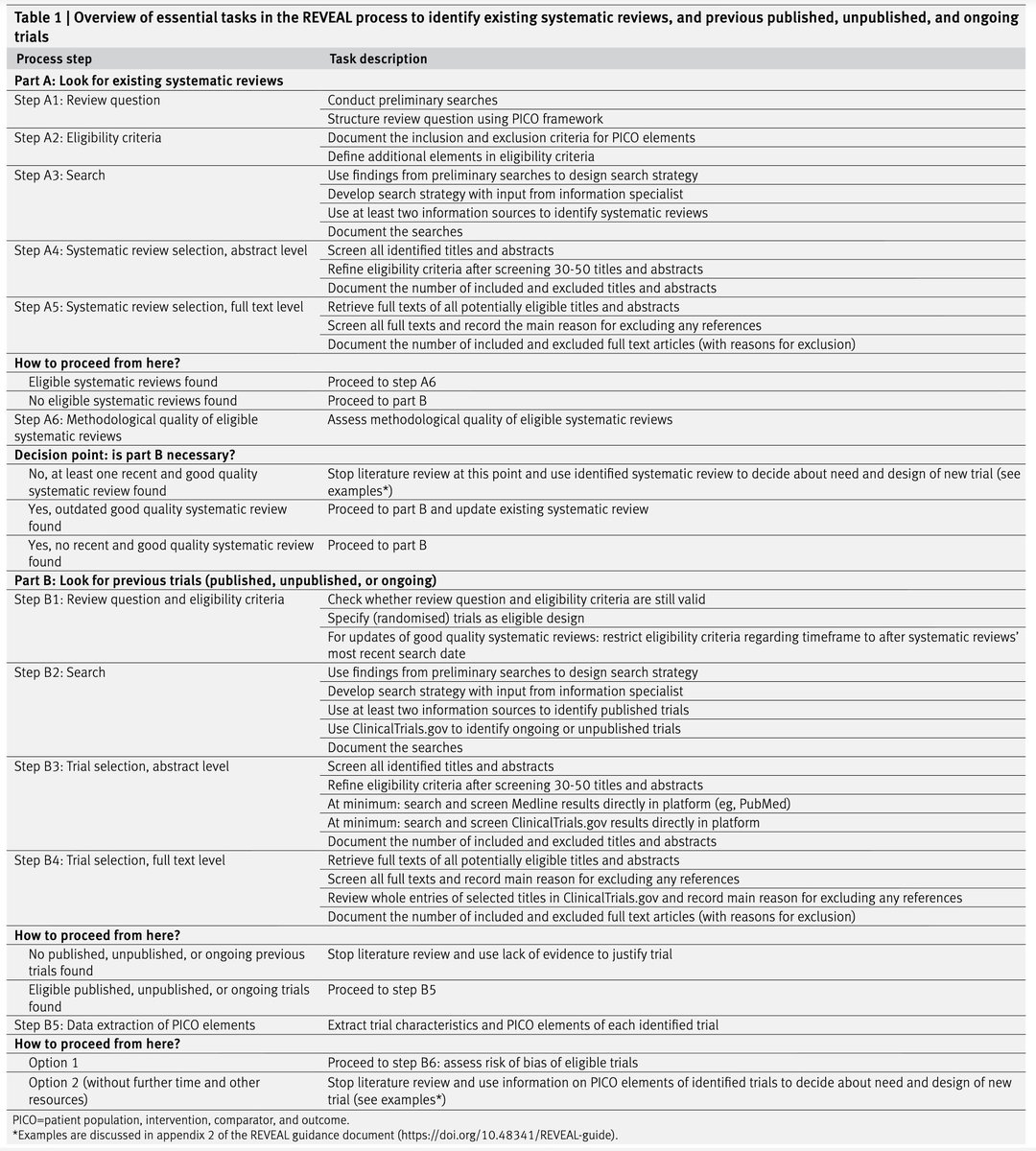
REVEAL: Yeni Bir Klinik Araştırma Planlıyorsanız, Mevcut Kanıtları Gözden Geçirmek İçin Artık Bir Rehberiniz Var
Yeni bir klinik araştırma planlarken mevcut literatürü sistematik olarak taramak olmazsa olmaz. Ama gerçekte ne yapıyoruz? Çoğu zaman birkaç tanıdık makaleye referans verip geçiyoruz. Sistematik derleme yapmak için ne zamanımız ne bütçemiz ne de metodolojik deneyimimiz yeterli oluyor.
BMJ'de bu hafta yayımlanan REVEAL (prior evidence for new trials) kılavuzu tam da bu soruna çözüm getiriyor.
Griebler ve arkadaşları, klinik araştırmacıların hızlı, sistematik ve uygulanabilir bir şekilde mevcut kanıtları tarayabilmesi için adım adım bir rehber geliştirmiş. Üstelik bunu ciddi bir metodoloji ile yapmışlar: sistematik literatür taraması, uzman paneli görüşleri ve gerçek kullanıcılarla usability testi.
REVEAL'in özü şu:
🔹 Part A — Önce konuyla ilgili mevcut sistematik derlemeleri arıyorsunuz. Güncel ve kaliteli bir derleme bulduysanız, durup onu kullanabilirsiniz.
🔹 Karar noktası — Bulunan derleme güncel değilse veya yeterli değilse Part B'ye geçiyorsunuz.
🔹 Part B — Yayımlanmış, yayımlanmamış ve devam eden bireysel çalışmaları (özellikle RCT'leri) arıyorsunuz. ClinicalTrials.gov taraması da dahil.
Sürecin sonunda elinizde, önceki çalışmaların PICO özelliklerini özetleyen yapılandırılmış bir tablo oluyor. Bu tablo ile yeni araştırmanızın gerekçesini ortaya koyabilir, örneklem büyüklüğü hesaplamasına veri sağlayabilir, sonuç ölçütü seçiminizi bilgilendirebilir ve SPIRIT kılavuzunun 9a maddesini sağlam bir şekilde karşılayabilirsiniz.
Özellikle dikkat çekici bulduğum noktalar:
→ Tüm temel adımlar tek bir kişi tarafından yürütülebilecek şekilde tasarlanmış. Kaynak kısıtı olan ekipler için gerçekçi bir çözüm.
→ Zorunlu ve opsiyonel adımlar net olarak ayrılmış. Zamanınız varsa risk of bias değerlendirmesi ve meta-analiz de ekleyebilirsiniz.
→ Arama stratejisi için bir bilgi uzmanından (kütüphaneci/information specialist) destek alınmasını öneriyorlar — usability testlerinde araştırmacıların en çok zorlandığı adım bu olmuş.
→ Mevcut haliyle yapay zeka araçları önerilmiyor çünkü kanıt henüz yeterli değil, ama kullanacaklar için RAISE kılavuzuna yönlendiriyorlar.
Kılavuzun kendisi, yapılandırılmış rapor formu ve doldurulmuş örnek formu açık erişimle ücretsiz olarak sunuluyor.
Bence REVEAL, araştırma israfını önleme söylemini somut bir eyleme dönüştüren pratik bir araç.
📎 Griebler U, et al. BMJ 2026;392:e083718
bmj.com/content/bmj/392/bmj-…
@akamedika
22
1,255