
Member of Technical Stuff @flourishailabs | ex-Databricks, OG-MosaicML. I like it when brains inspire AI 🧠 🤖
Joined April 2021
- Tweets 584
- Following 2,188
- Followers 1,144
- Likes 4,776
26 Photos and videos








Pinned Tweet

Jun 5
I recently left @DbrxMosaicAI to join @flourishailabs.
Why did I decide to make the jump?
I believe that some of the most interesting problems in science might now be within reach. With all the wild advances in AI, there’s no better time to pursue the big questions.
Flourish is doing just that. We are a mix of AI researchers, engineers, and neuroscientists tackling one of the most ambitious problems in the field: human-level intelligence and learning with human-level efficiency.
I have immense respect for the founders @TRReardon , Robert Williams, @jovo, @_vishar and for the team - many of whom built CTRL-labs from the ground up.
I really loved my time at @databricks and MosaicML before that. The caliber of the people and the research is sky high, and I am incredibly proud of the work we did over the past 5 years. In particular I’d like to thank my mentors @jefrankle , @mcarbin and @bemikelive, as well as the cracked @DbrxMosaicAI team.
If you’re interested in working at the intersection of AI research and human intelligence, don’t hesitate to reach out.
12
4
81
8,936
Jacob Portes retweeted

Jun 9
Actually it's fine guys! I figured out a way, see below.
Claude Fable 5 is a great model afterall, and I also finally appreciate the difference between CLAUDE.md and AGENTS.md.
It's all good.
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

42
49
1,515
176,269
Jun 9
Curious if people have evidence of Mythos doing poorly on frontier LLM research in the coming days
Jun 9
mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy
3
5
1,159
Jun 5
I recently left @DbrxMosaicAI to join @flourishailabs.
Why did I decide to make the jump?
I believe that some of the most interesting problems in science might now be within reach. With all the wild advances in AI, there’s no better time to pursue the big questions.
Flourish is doing just that. We are a mix of AI researchers, engineers, and neuroscientists tackling one of the most ambitious problems in the field: human-level intelligence and learning with human-level efficiency.
I have immense respect for the founders @TRReardon , Robert Williams, @jovo, @_vishar and for the team - many of whom built CTRL-labs from the ground up.
I really loved my time at @databricks and MosaicML before that. The caliber of the people and the research is sky high, and I am incredibly proud of the work we did over the past 5 years. In particular I’d like to thank my mentors @jefrankle , @mcarbin and @bemikelive, as well as the cracked @DbrxMosaicAI team.
If you’re interested in working at the intersection of AI research and human intelligence, don’t hesitate to reach out.
12
4
81
8,936
Jacob Portes retweeted

Jun 4
At @flourishailabs, we are tackling one of the hardest problems in AI: human-level intelligence and learning with human-level efficiency. We are inspired by biology, seek guidance where appropriate, but aren't dogmatic about it.
If this appeals to you and you'd like to embrace the age of research, consider joining us. We are hiring in NYC and SF.
Jun 4

Here's an exclusive inside look at Flourish, a startup full of neuroscientists and AI researchers working together to make discoveries about the brain and use them to create a more efficient form of AI that learns like people do. wired.com/story/jeff-bezos-i…
5
5
33
8,114
Jacob Portes retweeted

May 19
We’re releasing Nemotron-Labs-Diffusion - the first Tri-mode LM family (3B/8B/14B) that switches between 1⃣Autoregressive, 2⃣Diffusion, and 3⃣Self-Speculation decoding by simply changing the attention pattern/mask.
One model Three decoding modes. No extra draft models. No architecture changes. Just significantly better efficiency across different concurrency levels.
Up to 4× higher real throughput for a single user.
🤗 HF Collection: huggingface.co/collections/n…, open license
🛜 Project page: research.nvidia.com/publicat…
📰 Tech report: bit.ly/Nemotron-Labs-Diffusi…
Details below 👇

15
88
587
51,000
Jacob Portes retweeted

May 11
Just an AI that can fix my slouchy chungus life
May 11

Tessa's quality of life has improved a lot with some nagging.
20
12
237
24,059
Jacob Portes retweeted

Apr 24
I have a personal update to share. I have taken a new role as head of research at @arcee_ai .
I have been constantly so impressed with the talent density, determination, and drive of the Arcee team and I am delighted to join forces to help shape and deliver their vision for open source frontier models. The fastest progress in AI happens in the open. When models are accessible, iteration compounds, and entirely new categories of products become possible.
The decision to leave @datologyai was a difficult one. I still believe in their vision and incredibly talented group of people that have pushing the frontier of what is possible in data curation. I was personally motivated by being back directly involved in releasing and deploying models that people and companies use everyday to solve problems. This is what I love to do.
BTW we are hiring. If you want to be part of a cracked small team making fantastic open weight American models dm me!
92
21
526
68,200
Jacob Portes retweeted

Apr 15
🧠 the Digital Brain Project is now live:
$5M total · up to $500k per selected team
Let's open-source the modeling of the human brain brain activity!
➡️Apply on: digitalbrainproject.org/
31
120
516
60,611
Jacob Portes retweeted

🚨 We're very happy to introduce TRIBE v2: a foundation model of the brain's responses to sight, sound & language.
📄 Paper: ai.meta.com/research/publica…
▶️ Demo: aidemos.atmeta.com/tribev2/
💻 Code: github.com/facebookresearch/…
🤗 Model: huggingface.co/facebook/trib…
46
254
1,332
120,291
Jacob Portes retweeted

Mar 23
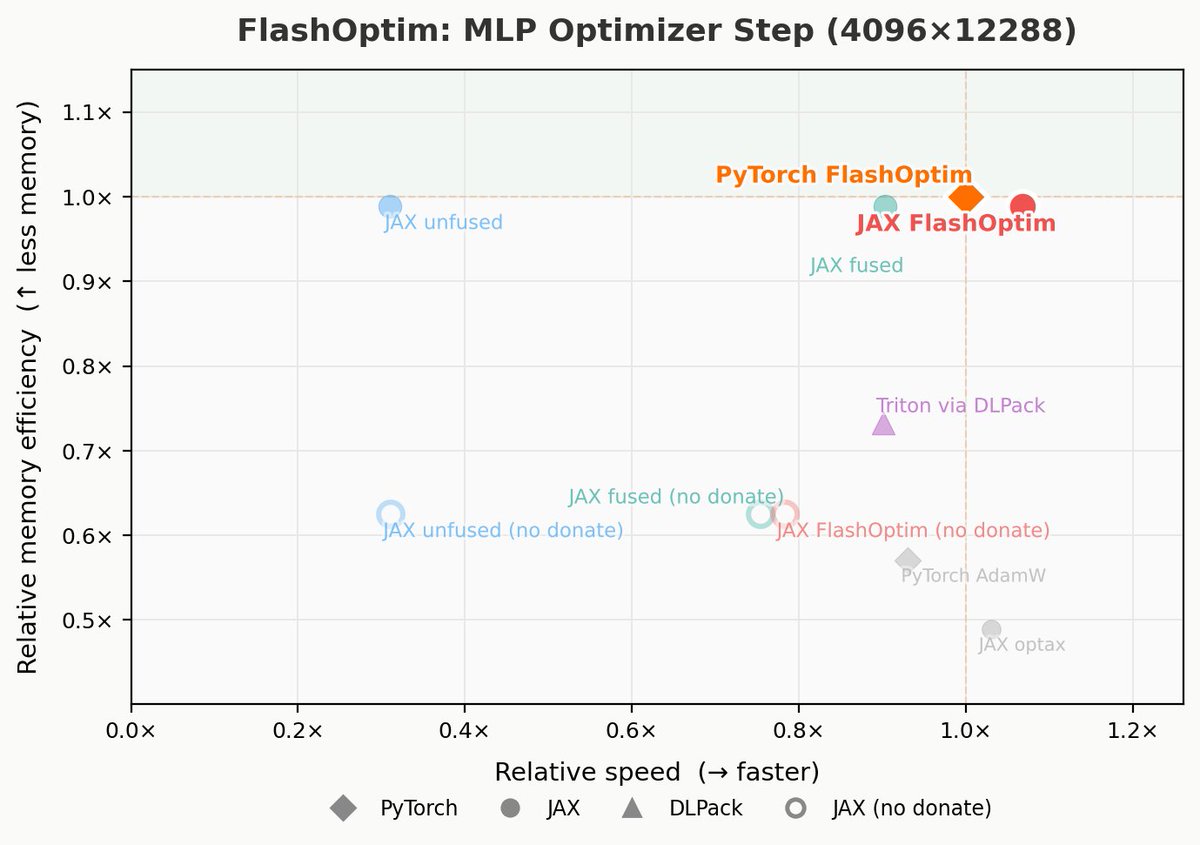
I implemented this in JAX: `uv pip install flashoptim-jax`!
Read below for the journey over 4 implementations to get speedups over the torch baseline while matching the ~2x memory improvements.
Mar 3

🚀 Today we’re releasing FlashOptim: better implementations of Adam, SGD, etc, that compute the same updates but save tons of memory. You can use it right now via `pip install flashoptim`. 🚀
arxiv.org/abs/2602.23349
A bunch of cool ideas make this possible: [1/n]

1
13
72
7,130
Jacob Portes retweeted

Mar 19
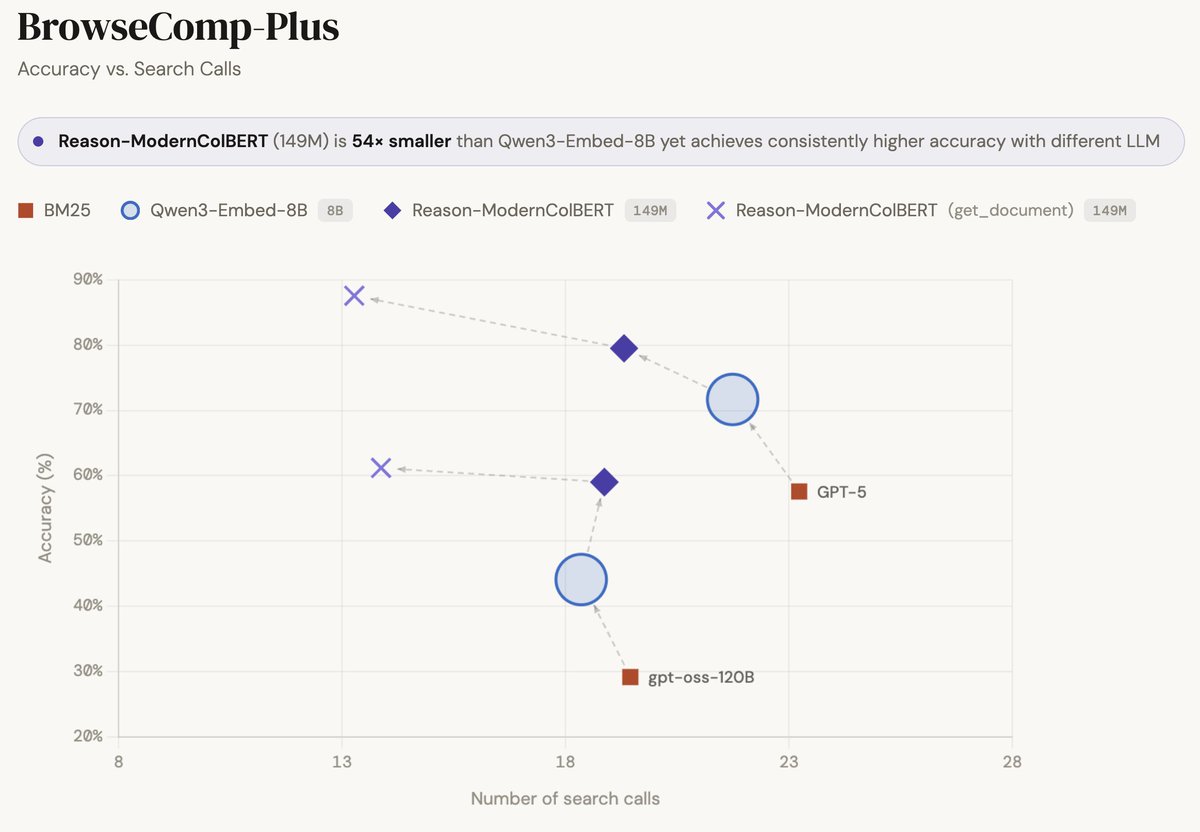
BrowseComp-Plus, perhaps the hardest popular deep research task, is now solved at nearly 90%...
... and all it took was a 150M model ✨
Thrilled to announce that Reason-ModernColBERT did it again and outperform all models (including models 54× bigger) on all metrics
26
62
462
182,366
Jacob Portes retweeted

Mar 18
the next @airstreet nyc ai meetup is on 5/14
if you're building and researching in ai, this is the place for you to meet peers, learn and share best practices, find co-founders and friends
you can rsvp at luma(dot)com/nycai

1
4
20
2,444
Jacob Portes retweeted

Mar 17
11
57
677
61,740
Jacob Portes retweeted

Mar 17
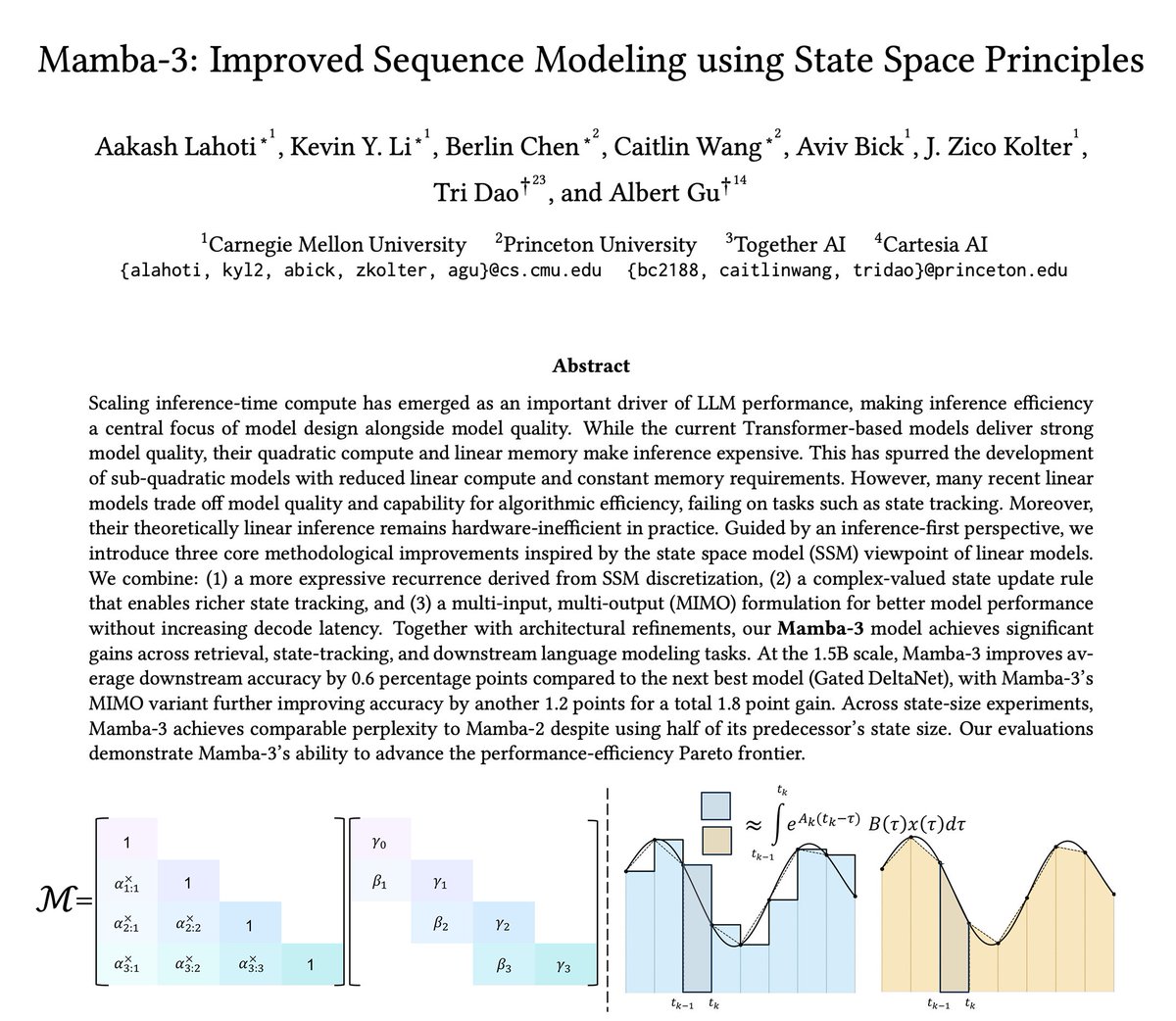
The newest model in the Mamba series is finally here 🐍
Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models.
We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes.
This is the first Mamba that was student led: all credit to @aakash_lahoti @kevinyli_ @_berlinchen @caitWW9, and of course @tri_dao!
41
310
1,597
447,251
Jacob Portes retweeted

Mar 11
Quotient is joining @databricks!
@freddiev4 and myself started @QuotientAI in 2023 with a dream and a hunch that the next era of AI will be unlocked by systems that can measure, evaluate, and improve AI in the real world.
Over the past couple of years, we partnered with companies ranging from AI-first startups to Fortune 500 enterprises. They used Quotient to monitor AI systems in production, ensure their agents met strict enterprise policies, and reinforcement fine-tune agents to consistently achieve double-digit performance gains.
We built it all at the bleeding edge, with a small team that started in Boston, Massachusetts.
Joining Databricks gives us the scale and resources to take this much, much further.
Very grateful to our team, investors, customers, and everyone who supported us along the way.
We couldn’t be more excited for what’s next.
Onwards!

23
12
101
19,497
Jacob Portes retweeted

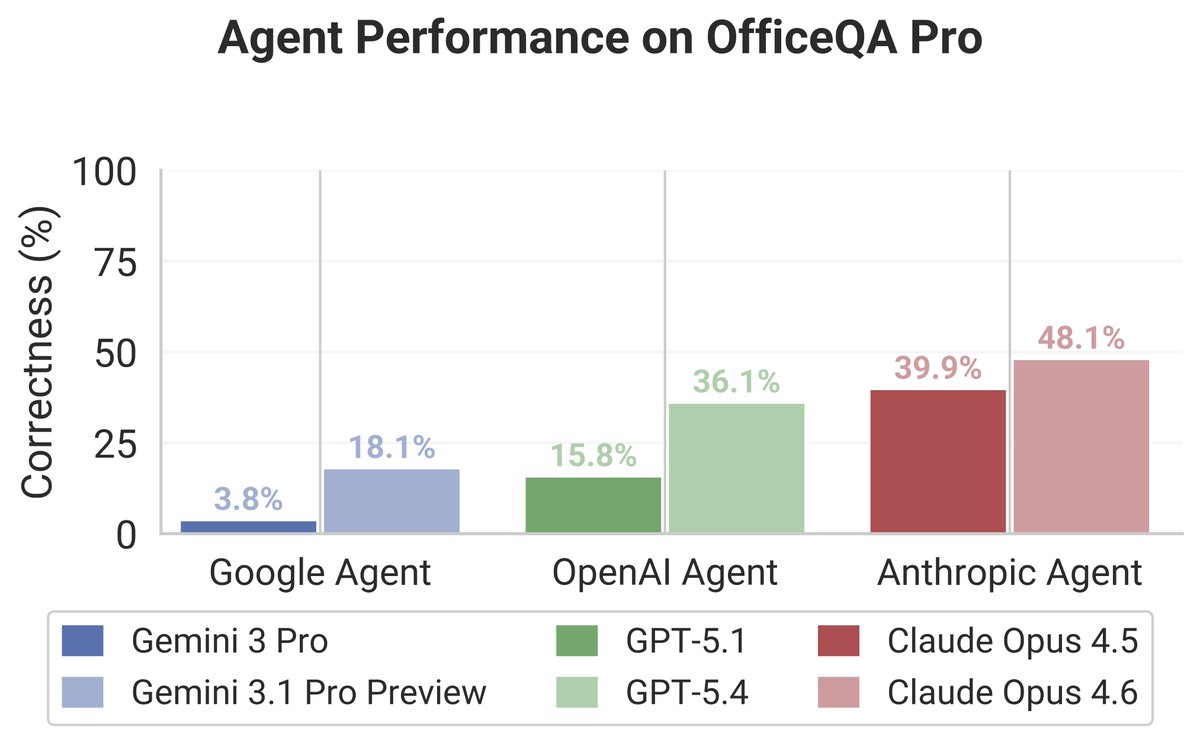
The OfficeQA Pro paper is live! Excited to share this benchmark for evaluating frontier agents over enterprise-style documents and workflows. Amazing work with the team to create a benchmark that's both meaningful and challenging for leading agents (and even humans)!

Most AI benchmarks test reasoning in isolation.
Real enterprise tasks require grounded reasoning:
1️⃣ Find the right documents
2️⃣ Extract the right values
3️⃣ Perform analyses
OfficeQA Pro evaluates this end-to-end. Frontier agents still score <50%.
🧵Paper & details below!
3
8
1,488
Jacob Portes retweeted

Most AI benchmarks test reasoning in isolation.
Real enterprise tasks require grounded reasoning:
1️⃣ Find the right documents
2️⃣ Extract the right values
3️⃣ Perform analyses
OfficeQA Pro evaluates this end-to-end. Frontier agents still score <50%.
🧵Paper & details below!
7
27
110
44,731

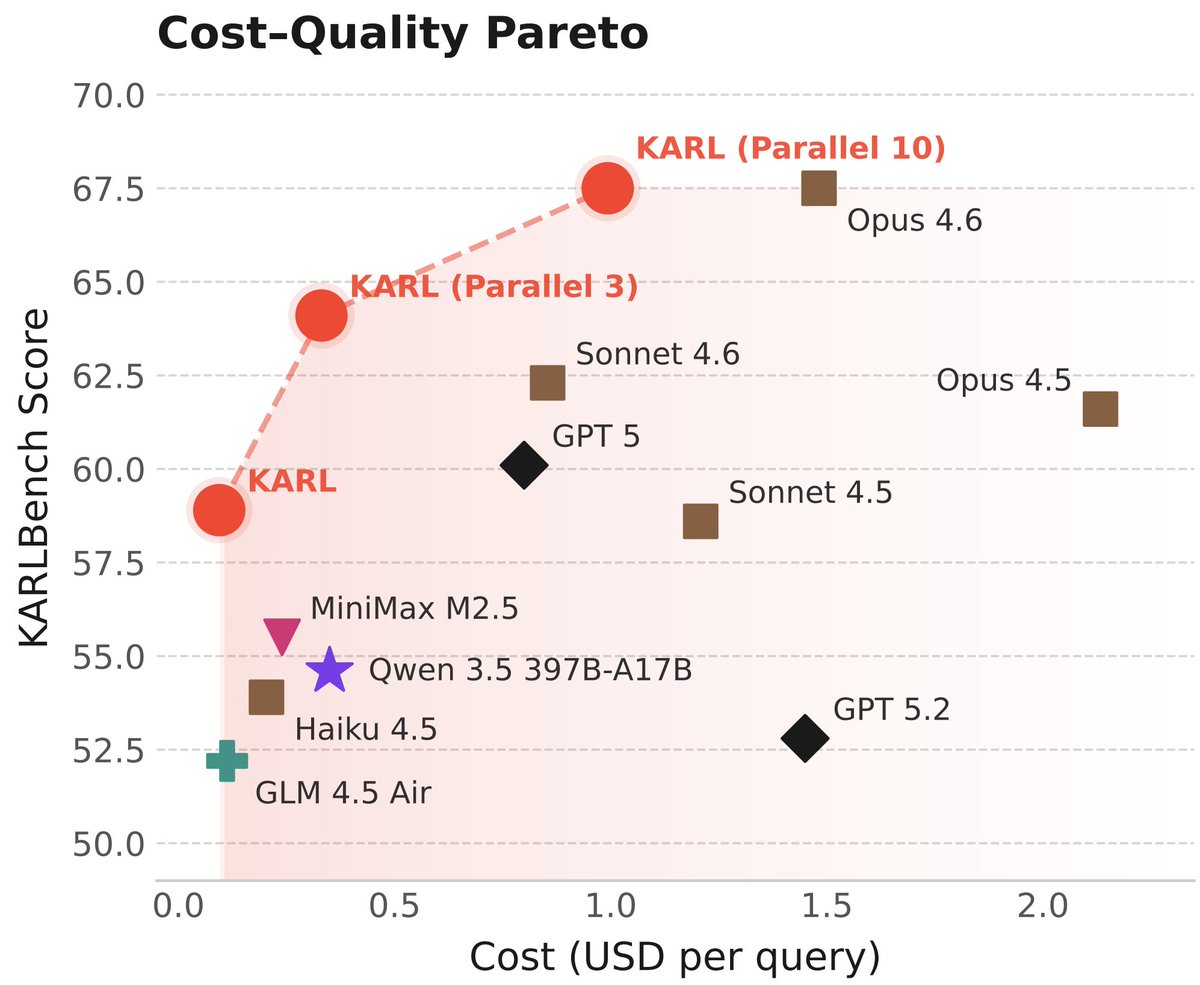
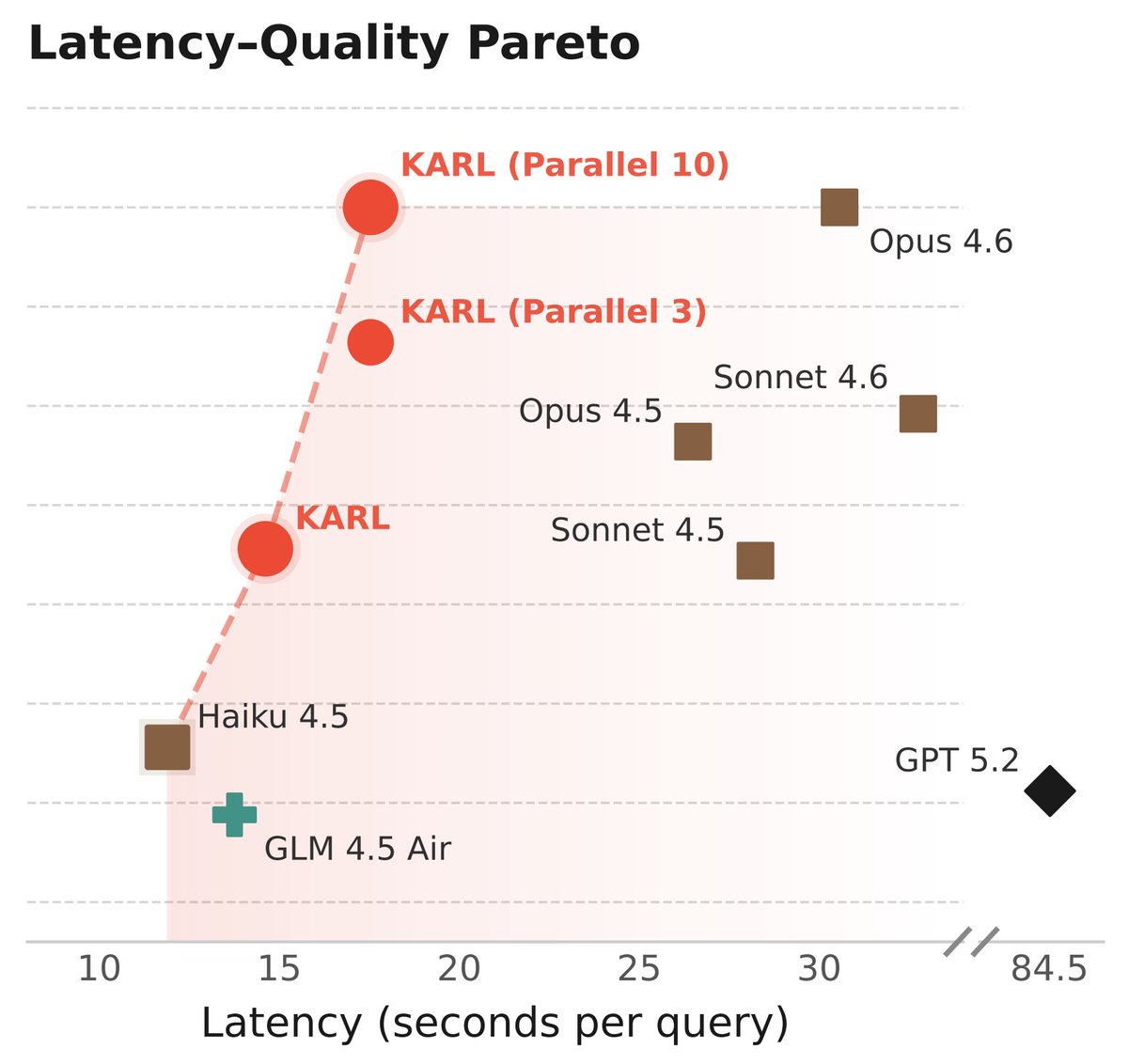
Going to do a more technical deep dive on our enterprise knowledge agents and how we train them with RL.
Overall we found that simple, yet principled off-policy RL works at scale for complex agentic tasks with hundreds of steps of tool use and context management. Here are the key takeaways from our 80 page technical report.
(1) RL does not just sharpen base model's distribution.
We see test-time scaling improves consistently over the iterations of the RL training. Skills learned during RL transfers to unseen prompts and agent learns to solve prompts where base model has zero accuracy under pass@16.
(2) Multi-task RL generalizes really well
Simple mixing of training data from multiple tasks works well and allows multi-task RL scale beyond your in-distribution training tasks. We found that multi-task RL just works better than multi-expert distillation.
(3) End-to-end RL for tools and context management works best.
We skipped mid-training, and directly trained everything end-to-end using RL at scale (2m tokens per gradient computation). Models learned to use vector database tools and context compression at the same time.
Mar 5

Meet KARL, an RL'd model for document-centric tasks at frontier quality and open source cost/speed. Great for @databricks customers and scientists (77-page tech report!) As usual, this isn't just one model - it's an RL assembly line to churn out models for us and our customers 🧵
2
18
70
16,609