
Senior Data Scientist at Wolters Kluwer, LLM Inference, Kaggle Competitions Expert
Joined September 2023
- Tweets 499
- Following 911
- Followers 335
- Likes 1,609
188 Photos and videos







Pinned Tweet

Apr 13
I have been writing a small series on LLM inference with @vllm_project that can be a practical starting point for people trying to understand this space.
Along with the explanations, I also ran benchmarks on realistic workloads across different GPUs and datasets to evaluate how these techniques perform in practice.
It covers:
- Major speculative decoding techniques
- Major quantization methods
- Distributed inference: DP / PP / TP
- Expert Parallelism and mixed parallel setups
- Practical optimization techniques like prefix caching, KV cache, and disaggregated prefill/decode
My goal was to explain how these techniques work, where they help, so it is easier to choose the right approach for a given workload.
This series is useful not only for people getting into LLM serving, but also for engineers who are already serving LLMs and want to optimize inference, improve throughput, reduce latency, or evaluate the right serving strategy.
7
15
190
12,286
Planning to go in depth into all the dtypes and techniques of Blackwell quantization in the next 1-2 weeks. I have a plan to cover NVFP4, NVFP8, MXFP4, MXFP8, so I will be working more with TensorRT-LLM over the next two weeks.
May 18

I benchmarked Qwen3-32B on @nvidia RTX PRO 6000 Blackwell with BF16, FP8, and NVFP4.
My main observation: NVFP4 gave a clear serving speedup, and on GPQA Diamond ARC Challenge.
I did not see a meaningful accuracy regression in this setup.
NVFP4 on Blackwell looks very strong for Qwen3-32B serving, but I would still validate it on real prompts before replacing BF16.
Model Checkpoints used :
1. Qwen/Qwen3-32B
2. Qwen/Qwen3-32B-FP8
3. RedHatAI/Qwen3-32B-NVFP4 by @RedHat_AI
1
2
16
706
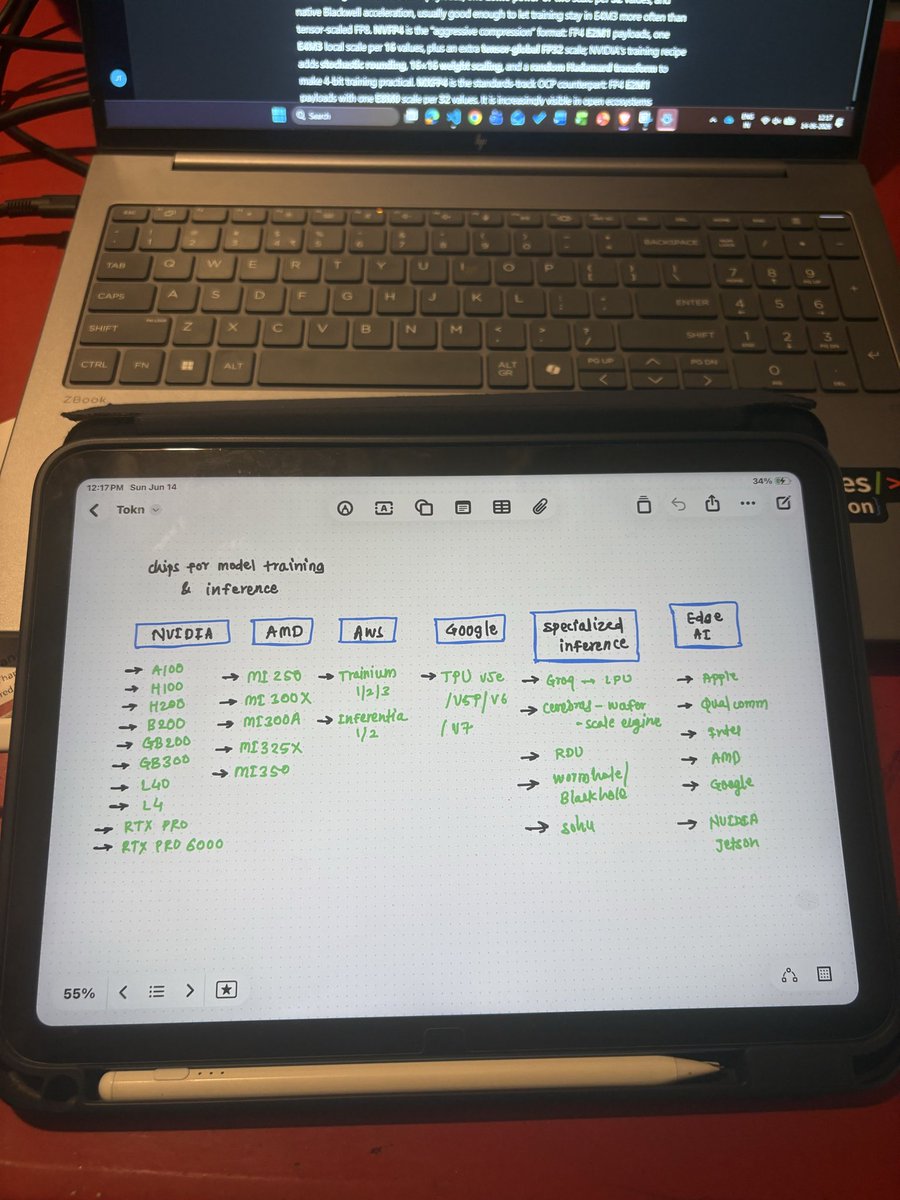
Market overview of model training and inference chips available in the market. NVIDIA is a major player, but there are other players as well, such as AMD, AWS, and Google.
1
41
In my recent study on prefix caching in LLM inference servers, I explored hash-based prefix caching used in vLLM and radix-tree-based prefix caching used in SGLang.
One thing I noticed is that there are very few public datasets specifically designed for prefix caching experiments. Since LLM applications are becoming more diverse and workload patterns keep changing, I thought it would be useful to test prefix caching across different workload types and observe where it helps, where it struggles, and what can be optimized.
For my experiments, I created a simple but diverse prefix caching dataset. For now, it covers four workload patterns:
1. Shared schema: simple high-reuse case
2. Same document multi-query: long-context high-reuse case
3. Agent branching: agent-style branching case
4. Eviction pressure: stress / negative test case
The goal is to make prefix caching evaluation more workload-aware instead of testing only one ideal reuse pattern.
2
1
6
254
Jun 11
When using distributed inference techniques like TP, DP, PP, and EP in frameworks such as vLLM, SGLang, and TensorRT-LLM, this is how GPU communication happens.
At the software layer, frameworks rely on NCCL collectives such as AllReduce, AllGather, ReduceScatter, Broadcast, and Send/Recv. Under the hood, NCCL uses the available communication fabric:
• NVLink (or PCIe) for GPU-to-GPU communication within a node
• InfiniBand for communication across nodes
Having this mental model makes it much easier to understand distributed inference.
1
3
13
342
Jun 9
I found this small yet practical blog explaining why torch.compile so fast. It has one practical example by which we can directly see how torch inductor gives optimised triton kernel for our code.
1
4
191
Jun 7
Got some interesting numbers in my recent prefix caching runs. On my Eviction Pressure 4K dataset vLLM looks good in retaining KV cache which kept prefix caching hit rate consistent.
2
84
Jun 5
Planning to learn about Ray this weekend from the angle of distributed LLM inference.
Planning to cover:
1. Ray Serve,
2. Actors,
3. Placement groups,
4. GPU scheduling,
5. Autoscaling,
6. Distributed workers,
7. Fault tolerance,
8. vLLM usage of Ray for multi-GPU/multi-node execution.
2
6
306
Jun 6
This video covers :
1. Ray Serve
2. Ray Data for batch LLM Inference
3. Ray Serve in Disaggregated Serving
4. Ray Serve in LLM-Aware Load Balancing
5. Custom Replica Scheduling API in Ray Serve
Start time : 31:01
youtube.com/watch?v=HDSy09hr…
1
76
Jun 6
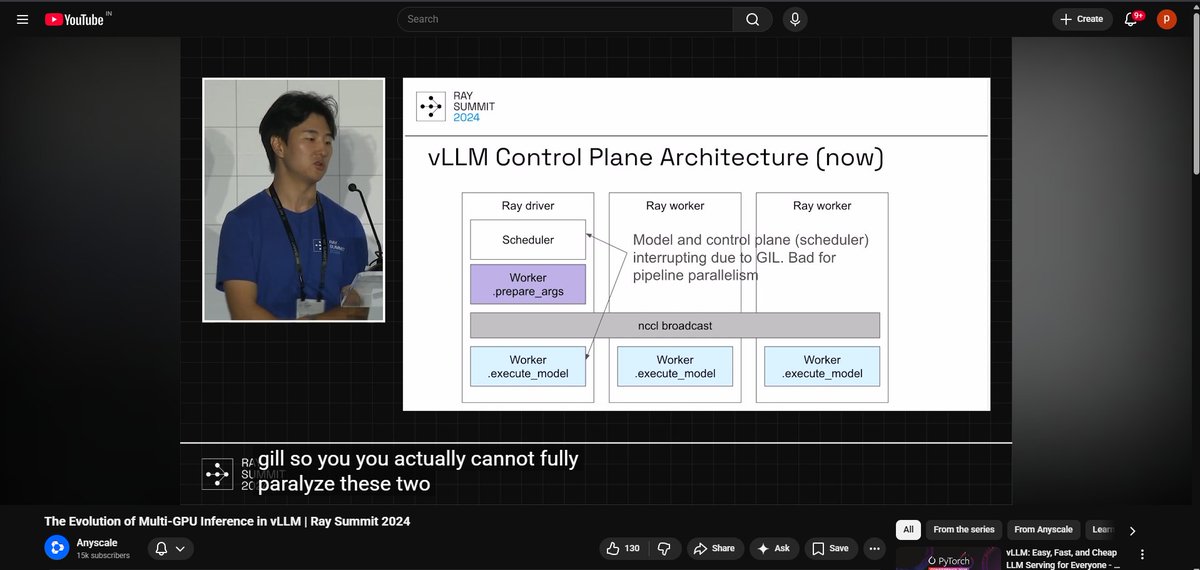
Watch this video by Anyscale of RAY SUMMIT 2024 which explains the implementation of Ray in vLLM architecture at high level. Video to get started with Ray if you know about vLLM internals.
1
1
102
Jun 4
This is the vLLM function where prompts rendering is done in offline inference mode. It is sequential and it becomes CPU bound for my VLM inference pipeline. I am looking for optimizations now. I am up for suggestions.
May 22
We usually say that prefill is compute bound and decode is memory bound, but there are parts of the inference pipeline that can become CPU bound too.
I am using vLLM for one Vision Language Model inference, and while optimizing inference latency, I observed that the total time is almost split 50-50 between CPU and GPU.
The split looks something like this:
CPU: 50%
Time is spent in rendering prompts / preparing inputs
GPU: 50%
Time is spent in prefill decode
Initially, I was planning to optimize the GPU side 50%, which is the usual path: improving prefill and decode performance using vLLM optimization techniques like prefix caching, chunked prefill, tuning max_num_batched_tokens, and improving decode with techniques like speculative decoding.
But now the bigger question is: what about the first 50% on the CPU side?
So far, I tried multiple things to reduce this overhead, such as increasing MM_PROC_WORKERS and preprocessing inputs using the Hugging Face processor, but none of them helped much.
At this point, it looks like my VLM pipeline is becoming CPU bound, rather than purely compute bound or memory bound.
3
125
Jun 1
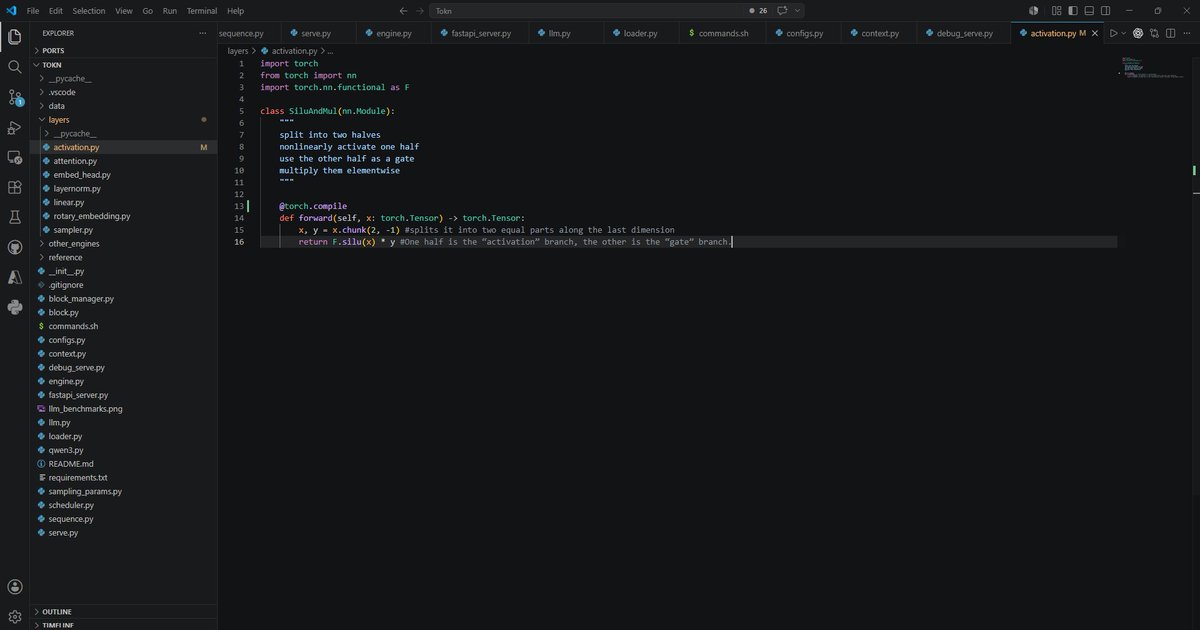
How I used torch.compile in my LLM server is surprisingly minimal.
Right now, I am compiling only a few small but frequently used operations:
1. Activation function forward pass
2. RoPE embedding forward pass
3. Sampler forward pass
4. RMSNorm forward pass
I am not applying torch.compile to attention, because attention is already handled by optimized FlashAttention kernels. For decode, CUDA Graphs are usually more useful because they reduce repeated kernel launch overhead.
My simple understanding of torch.compile:
TorchDynamo captures PyTorch tensor operations and converts them into an FX Graph.
FX Graph is an intermediate representation of the computation, made of nodes like:
call_method float
call_method pow
call_method mean
Then TorchInductor takes this graph, optimizes it, and on GPU can generate optimized Triton kernels.
1
2
104
May 31
One more checkmark and I feel more excited about the upcoming work in building my LLM inference server.
So far, it feels great implementing core techniques like separate prefill and decode, KV cache, prefill caching, etc. The upcoming things are more interesting: Torch Compile, CUDA Graphs, SD, Quantization, and Distributed inference.
Since I know these theoretically, implementing them one by one will be fun.
I recently completed my study on prefix caching, which involves block hash-based and radix tree-based approaches. I have also run some benchmarks with vLLM and SGLang and will make them public soon.
1
2
14
582
May 30
Simple but informative observation from my recent prefix caching run.
Setup:
1. Model: Qwen2.5-14B
2. GPU: H100
3. Dataset: Long-prompt dataset, making it public soon
4. Serving framework: vLLM
Next: Planning to try the same with SGLang and TensorRT-LLM
5. For server-side metrics : Prometheus Grafana
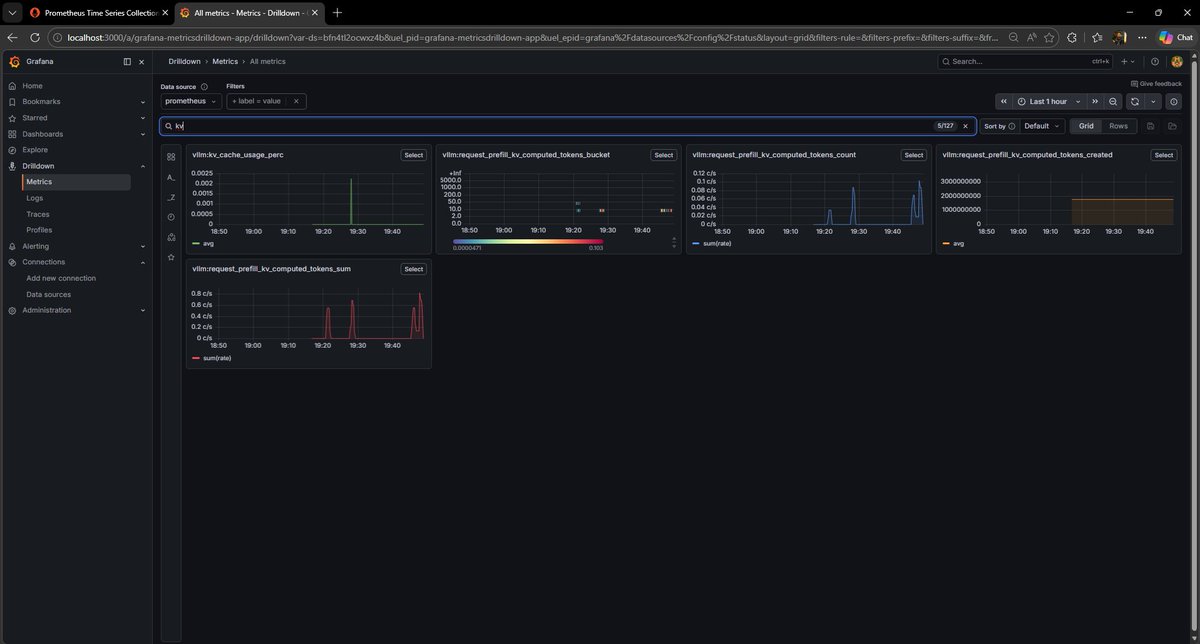
From the graph below, we can clearly see how vLLM behaves under prefill pressure.
The vllm:kv_cache_usage_perc and vllm:num_requests_running curves move together. Once the KV cache gets full, vLLM starts queuing incoming requests instead of running everything immediately.
This behavior is visible in vllm:num_requests_waiting, where requests build up in the waiting queue and are then steadily processed over time.
At the same time, vllm:prefix_cache_hits_total keeps increasing, showing that vLLM is still reusing cached prefix tokens while managing KV cache pressure.
6
262
May 30
Dry run with decided server side metrics :
1. vllm:prefix_cache_hits_total
2. vllm:prompt_tokens_total
3. vllm:kv_cache_usage_perc
4. vllm:num_requests_running
5. vllm:num_requests_waiting
Numbers on graphs are verified with vllm server logs and they are correct. we can export the numbers in .csv format for later usage.
May 25
Using Prometheus Grafana to track server-side metrics for Qwen2.5-14B-Instruct while testing prefix caching techniques.
Both tools are fairly easy to set up. Grafana looks especially powerful because it provides many visualization options.
The pipeline is simple:
vLLM Server (/metrics endpoint)
↓
Prometheus (scrapes and stores metrics)
↓
Grafana (visualization)
I have planned a total of 24 experiments: 8 for vLLM, 8 for SGLang, and 8 for TensorRT-LLM.
I am planning to track these key server-side metrics:
1. Cache hit rate
2. Prefill token rate
3. KV cache usage
4. Running requests
5. Waiting/queued requests
1
155