
3D vision fanatic. Professor @cornell_tech & Researcher @GoogleDeepmind. He or they. snavely.bsky.social
Joined June 2008
- Tweets 924
- Following 868
- Followers 9,664
- Likes 7,622
55 Photos and videos













Jun 5
We use a sort of @elliottszwu-style strategy to build a dataset of symmetries in architectural scenes, then detect and localize symmetries in new images via signed-distance functions. This is really great work from Hanyu with very nice visuals!
Jun 5

Excited to share ArchSym at #CVPR2026! 🏛️
Existing 3D symmetry detectors work well on clean, object-centric data. But what about in the wild?
In our work, we tackle 3D-grounded reflectional symmetry detection specifically for real-world architectural landmarks.
🧵[1/7]
1
4
33
4,884
Jun 5
Thank you, Humphrey! It's a real honor to receive this award!
Jun 5

Congratulations to Noah Snavely @Jimantha from @Cornell receiving the 2026 Thomas S. Huang Memorial Prize at @CVPR — a well-deserved recognition of his impactful contributions to computer vision research and our community.
Remembering Tom & Margaret: youtu.be/QV7WnO9Lk9M?si=iYmA…

27
6
185
23,776
Noah Snavely retweeted

Jun 5
Excited to share ArchSym at #CVPR2026! 🏛️
Existing 3D symmetry detectors work well on clean, object-centric data. But what about in the wild?
In our work, we tackle 3D-grounded reflectional symmetry detection specifically for real-world architectural landmarks.
🧵[1/7]
1
6
21
6,640
Noah Snavely retweeted

Jun 5
Honey, I Shrunk the Arc de Triomphe! 😱
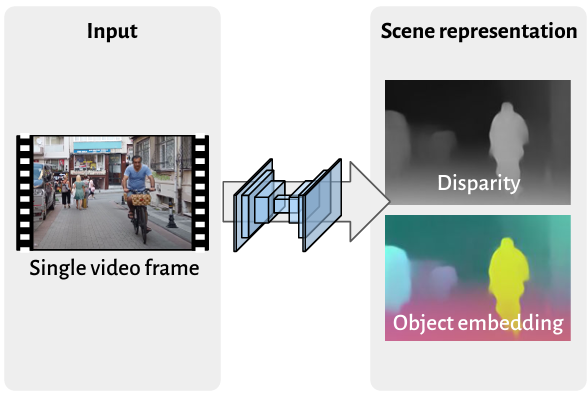
Ever notice how SOTA depth models suffer from "scale-collapse"—metrically shrinking distant landmarks like they're toys? We introduce MetricScenes: a new in-the-wild metric dataset that fixes this!
2
17
149
21,944
Jun 5
A really nice paper with a really cool title from Yuanbo, Hanyu, and Xueqing!
Jun 5

Honey, I Shrunk the Arc de Triomphe! 😱
Ever notice how SOTA depth models suffer from "scale-collapse"—metrically shrinking distant landmarks like they're toys? We introduce MetricScenes: a new in-the-wild metric dataset that fixes this!
1
25
4,090
Noah Snavely retweeted

Jun 3
This work has been fully open-sourced, including all code, model weights, and data related scripts. Feel free to check it out!
Our CVPR poster session will be on Saturday, June 6, from 4:45 to 6:45 PM in ExHall A & F 2. Our team (@holynski_, @jon_barron , @ChrisWu6080, @Jimantha, and me) would be onsite and very happy to discuss it in person!
Mar 5

Spatial reconstruction is a long-context problem: real scenes come with hundreds of images. But O(N²) transformer-based models don’t scale efficiently.
Introducing: 🤐ZipMap (CVPR ’26): Linear-Time, Stateful 3D Reconstruction via Test-Time Training (TTT).
ZipMap “zips” a large image collection into an implicit TTT scene state in a single linear-time operation. The state will then be decoded into spatial outputs, and can be queried efficiently for novel-view geometry and appearance (~100 FPS)
ZipMap is not only much faster (>20× faster than VGGT), but also matches or surpasses the accuracy of all SOTA models.
1
7
47
9,377
Noah Snavely retweeted

May 29
Humans can watch tasks like cooking or assembly and reason about what happened, when, and between which parts. Can LVLMs do the same? We built Flat-Pack Bench to test this – and found there is still a long way to go. Accepted at #CVPR2026! 🎥🪑🧩(1/n)
1
12
37
5,459
Noah Snavely retweeted

May 28
Feed-forward 3D reconstruction methods typically predict pointmaps in camera-centric frames. But why should a camera's arbitrary orientation define the coordinate system?
We introduce G3T, a transformer that predicts pointmaps in gravity-aligned frames. Regardless of input image orientation, our method always produces upright pointmaps (see demo).
We leverage this uprightness to create G3T-Long, a submap-based reconstruction method that improves robustness on long-sequence 3D reconstruction (more on that below).
Interactive demos, code, and model weights are available on our project page.
7
52
309
23,458
Noah Snavely retweeted

May 20
Excited to share what we are building -- Genie experience grounded in real-world street view. Try it out at labs.google/fx/projectgenie

Project Genie is a @GoogleLabs experiment that lets you simulate dynamic worlds you can navigate in real time with Genie, our general-purpose world model.
Today, we’re connecting Project Genie to nearly 20 years of Street View data from Google Maps — so you can now build interactive spaces based on real-world locations.
Street View imagery in Project Genie is available now for places in the U.S., and will expand to more locales over time.
#GoogleIO
8
43
426
67,471
Noah Snavely retweeted

May 3
Excited to share our CVPR’26 work! Moving beyond dense captures to long-tail Internet photos, we introduce MegaDepth-X and sparsity-aware sampling for 3D reconstruction.
Great work led by Yuan (@yuanli16342871) and the team.
Project page: megadepth-x.github.io
May 3

Introducing: Long-Tail Internet Photo Reconstruction (CVPR’26)
We go beyond densely captured imagery to train more general 3D foundation models for the long tail of noisy, sparse, incomplete Internet photo collections of 3D scenes. Yet, we face a data bottleneck: models need ground truth for these long-tail scenes, which classical SfM fails to provide. How do we bypass it?
We break this bottleneck with two key contributions. First, we introduce MegaDepth-X, a large new dataset of scenes with high-quality 3D supervision. Second, we propose a new way to simulate difficult image sets for training.
Project page: megadepth-x.github.io/
12
111
12,945
Noah Snavely retweeted

May 3
Introducing: Long-Tail Internet Photo Reconstruction (CVPR’26)
We go beyond densely captured imagery to train more general 3D foundation models for the long tail of noisy, sparse, incomplete Internet photo collections of 3D scenes. Yet, we face a data bottleneck: models need ground truth for these long-tail scenes, which classical SfM fails to provide. How do we bypass it?
We break this bottleneck with two key contributions. First, we introduce MegaDepth-X, a large new dataset of scenes with high-quality 3D supervision. Second, we propose a new way to simulate difficult image sets for training.
Project page: megadepth-x.github.io/
1
20
105
22,382
Noah Snavely retweeted

Apr 24
We are organizing the @cornell_tech Frontiers of AI Summit to bring together industry and cutting-edge academic research.
May 27 on the NYC Cornell Tech campus!
Attendance info on the website: tech.cornell.edu/frontiers-o…

8
41
6,117
Noah Snavely retweeted

Apr 22
Introducing CityRAG!
We wanted video generative models to be grounded in the real world — if I’m in London, I want to look around and actually see Big Ben.
CityRAG generates videos of cities featuring real buildings and roads, with arbitrary weather, people, and cars. 1/N
page: cityrag.github.io
paper: arxiv.org/abs/2604.19741
6
49
245
36,380
Noah Snavely retweeted

Apr 2
What’s the right representation for a world model? 3D, pixels, or something else?
Excited to release our new paper “Forecasting Motion in the Wild” where we propose point tracks as tokens for generating complex non-rigid motion and behavior
From @GoogleDeepmind @Berkeley_AI @TTIC_Connect
7
74
470
80,696
Noah Snavely retweeted

Mar 10
Very excited to share our exploration of a new robotics foundation model at Rhoda AI. We train a causal video model from scratch, unlocking new capabilities for robust, long-horizon closed-loop robot control. Learn more: rhoda.ai/research/direct-vid…

To bring generalist intelligent robots to the real world, we have to overcome the data scarcity problem.
At Rhoda, we are solving it by reformulating robot policies as video generation.
Today, we introduce the Direct Video-Action Model (DVA)
8
107
8,900
Mar 5
In your post-ECCV haze, check out @Haian_Jin's really nice work on linear-time, feed-forward 3D reconstruction!
Mar 5
Spatial reconstruction is a long-context problem: real scenes come with hundreds of images. But O(N²) transformer-based models don’t scale efficiently.
Introducing: 🤐ZipMap (CVPR ’26): Linear-Time, Stateful 3D Reconstruction via Test-Time Training (TTT).
ZipMap “zips” a large image collection into an implicit TTT scene state in a single linear-time operation. The state will then be decoded into spatial outputs, and can be queried efficiently for novel-view geometry and appearance (~100 FPS)
ZipMap is not only much faster (>20× faster than VGGT), but also matches or surpasses the accuracy of all SOTA models.
2
4
43
6,417
Noah Snavely retweeted
Mar 5
Spatial reconstruction is a long-context problem: real scenes come with hundreds of images. But O(N²) transformer-based models don’t scale efficiently.
Introducing: 🤐ZipMap (CVPR ’26): Linear-Time, Stateful 3D Reconstruction via Test-Time Training (TTT).
ZipMap “zips” a large image collection into an implicit TTT scene state in a single linear-time operation. The state will then be decoded into spatial outputs, and can be queried efficiently for novel-view geometry and appearance (~100 FPS)
ZipMap is not only much faster (>20× faster than VGGT), but also matches or surpasses the accuracy of all SOTA models.
20
102
756
78,086
Noah Snavely retweeted

Jan 28
📢Introducing 360Anything, our method for lifting any perspective image or video to gravity-aligned 360° panoramas without using any camera or 3D information. This enables consistent novel view synthesis and 3D scene reconstruction.
Project page: 360anything.github.io/
🧵
16
66
505
46,900
Feb 3
I love these time-lapses from Eric and team!
13 Aug 2025

Come see our talk on "Pocket Time-Lapse" at SIGGRAPH today at 4pm in the Image Representation, Editing, & Generation session!
West Building, Rooms 118-120.
With @zzigakovacic , @madhavaggar and @AbeDavis
1
1
31
4,619
Noah Snavely retweeted

26 Dec 2025
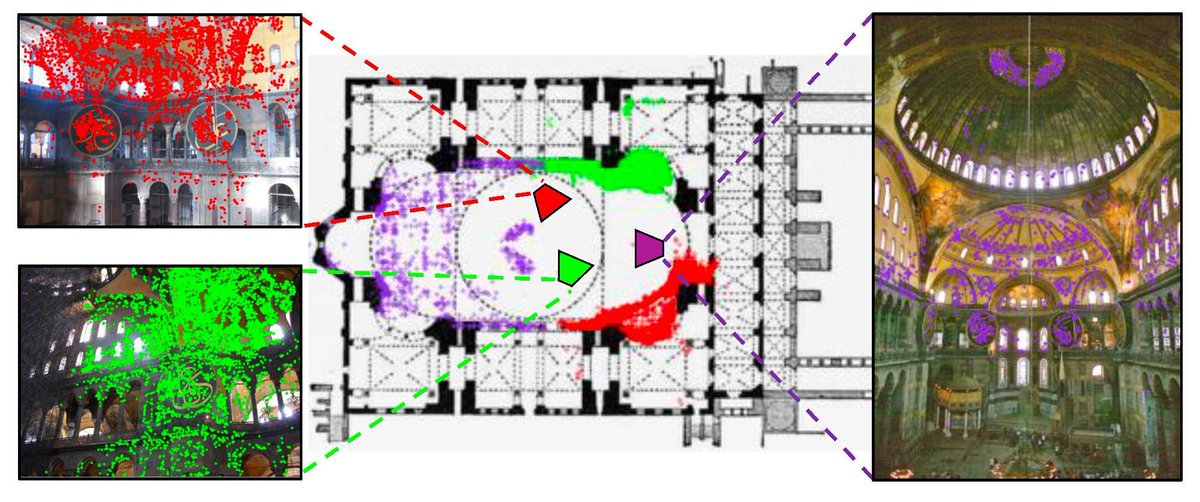
Cornell researchers have introduced C3Po, a breakthrough in computer vision that links real-world images to building layouts – opening new possibilities for robotics, indoor navigation, and digital reconstructions. @Cornell_Bowers
Learn more: news.cornell.edu/stories/202…
5
15
1,762