
We're graduate students, postdocs, faculty and scientists at the cutting edge of artificial intelligence research.
Joined July 2017
- Tweets 1,493
- Following 459
- Followers 273,413
- Likes 594
41 Photos and videos










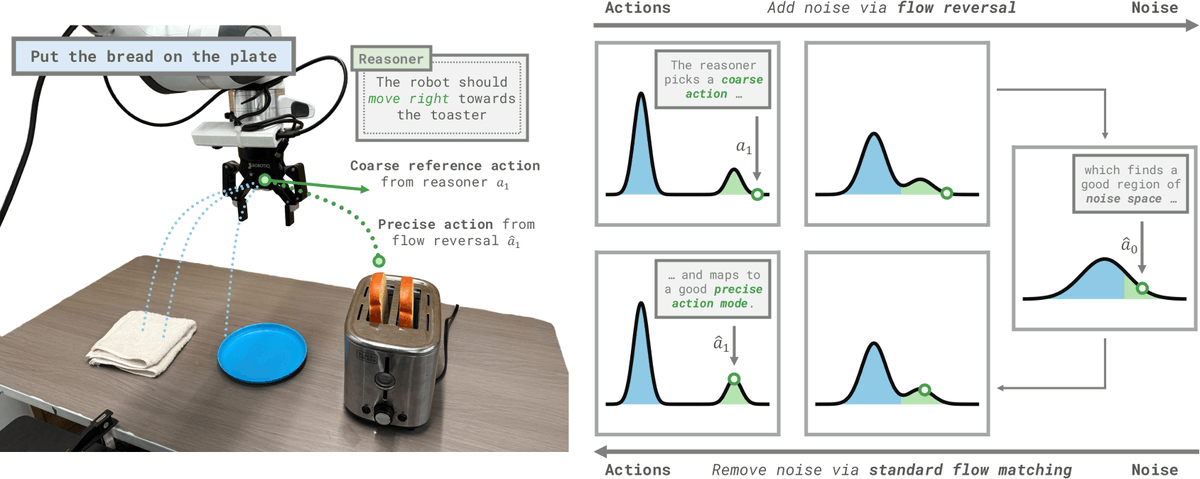
Generalist robot policies learn many useful skills. How can we elicit relevant behaviors when faced with new tasks? We introduce Flow Reversal Steering (FRS): a way to refine coarse actions produced by semantic reasoning into similar precise ones!
flow-reversal-steering.githu…
1/N
2
16
54
12,581
Berkeley AI Research retweeted

Jun 12
🎉 Excited to share that StyleStream has been accepted to INTERSPEECH 2026 Long Paper Track!
StyleStream enables zero-shot voice style conversion for timbre, accent, and emotion, with streaming inference locally on a single RTX 4060. (1/n)
We have also open-sourced the offline streaming inference pipeline. Check out our paper, repo and demo:
📰 Paper: arxiv.org/abs/2602.20113v1
💻 Code: github.com/Berkeley-Speech-G…
🔊 Demo: berkeley-speech-group.github…
@Nicholaszlee @GopalaSpeech @Berkeley_AI @Berkeley_EECS @Cal_Engineer
2
6
62
8,616
Berkeley AI Research retweeted

Jun 12
Flow reversal steering allows "steering" diffusion-based VLAs with high-level actions, for example from VLM reasoning. This also lets us run RL in the diffusion noise space with exploration guided by high-level reasoning: think through a task, then practice it! 👇
5
57
518
53,251

Jun 11
Congratulations to @berkeley_ai alumnus @pathak2206 who has been awarded the PAMI Young Researcher in Computer Vision Award!
This top award for young researchers in computer vision is given to two recipients yearly.
thecvf.com/?page_id=413#YRA
2
6
79
11,000
Jun 11
@pathak2206 is the seventh @berkeley_ai affiliated awardee in the last seven years. Other awardees include @akanazawa (2024), @judyfhoffman (2023), @BharathHarihar3 (2022), @georgiagkioxari (2021), @phillip_isola (2021), and @jon_barron (2020).
7
3,647
Berkeley AI Research retweeted

Jun 11
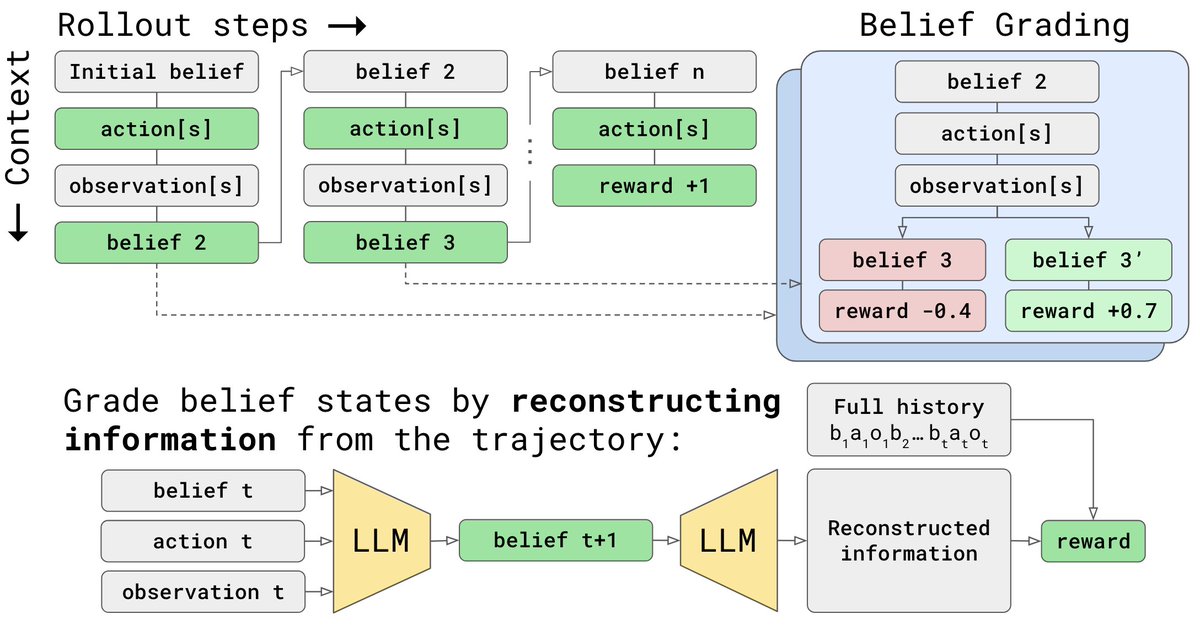
As task horizons grow, LLM contexts can’t scale forever. Self-summarization enables concise, interpretable contexts but at a significant performance cost.
Our solution: isolate and *supervise* the information content of summaries in the form of natural-language belief states 🧵
3
11
36
4,798
Berkeley AI Research retweeted

Jun 11
One day I tried tracing all of Olmo's dependencies manually. A few hours later, I realized I can't do it and gave up. Then @sadhikesaven and @CoderBak ModSleuth 🔥
Turns out Olmo and Nemotron have hundreds of dependencies that are super deep, recursive, and not easily visible. I'm glad I gave up early 😅
Spoiler: I thought this would be a one-week Claude Code project. It was not.
The hard part wasn't information extraction (which Claude Code is good at). The hard part was something much trickier. Check out the paper to learn more!
(And yes, if a model release says it used Claude Code, ModSleuth will trace that too... which means the model depends on Claude Code, which has its own dependencies, and ModSleuth itself depends on Claude Code 🤯)

LLMs are no longer created w/ human data alone. They rely on other models to generate & filter data, evaluate outputs, & guide dev work.
So what is a modern LLM built on? Olmo 3 → 89 model 183 dataset dependencies; Nemotron 3 → 273 560
We made ModSleuth to trace this. 🧵

2
21
146
22,286
Berkeley AI Research retweeted

Jun 11
Today, LLMs are no longer built from human data alone. They rely on other LLMs to generate training data, filter corpora, evaluate outputs, provide rewards, and guide development decisions. So how many models and datasets is a modern LLM built on?
• OLMo 3 → 89 model 183 dataset dependencies
• Nemotron 3 → 273 model 560 dataset dependencies
How did we find it out? We built ModSleuth. 🧵

LLMs are no longer created w/ human data alone. They rely on other models to generate & filter data, evaluate outputs, & guide dev work.
So what is a modern LLM built on? Olmo 3 → 89 model 183 dataset dependencies; Nemotron 3 → 273 560
We made ModSleuth to trace this. 🧵
2
13
68
10,130
Berkeley AI Research retweeted
Jun 10
Super excited about this work, led by @YichuanM and @andylizf ! It is possible to completely remove HTML parsing by directly retrieving and reading web screenshots through VLM.
HTML parsing is a hidden bottleneck that causes significant complexity and information loss that nobody really pays attention to, and it's so exciting that VLM progress made it possible to remove it.
Please check out this demo as well which is really cool!!! pixelrag.ai
Jun 10

The web was never meant to be flattened into text.
Yet most web RAG systems start by parsing HTML --- a complex and lossy process.
🔥 Introducing PixelRAG: the first RAG system that retrieves and reads 30M web pages as pixels.
Instead of extracting text, PixelRAG retrieves screenshots and lets a VLM read them directly.
PixelRAG not only preserves visual information, but also outperforms text-based RAG on text-only QA benchmarks by 18.1%.
Why?
(1) HTML-to-text conversion often discards layout, structure, tables, and other useful signals.
(2) We continued pretraining a VLM on web page screenshots and turned it into a surprisingly strong visual retriever.
(3) Recent VLMs are remarkably good at understanding web pages, often with better accuracy and token efficiency than text-only pipelines.
Takeaway: HTML parsing may be one of the biggest self-inflicted bottlenecks in web RAG.
Demo below 👇
Code: github.com/StarTrail-org/Pix…
Paper: github.com/StarTrail-org/Pix…
Playground: pixelrag.ai/
4
14
126
22,761
Berkeley AI Research retweeted

Jun 10
The web was never meant to be flattened into text.
Yet most web RAG systems start by parsing HTML --- a complex and lossy process.
🔥 Introducing PixelRAG: the first RAG system that retrieves and reads 30M web pages as pixels.
Instead of extracting text, PixelRAG retrieves screenshots and lets a VLM read them directly.
PixelRAG not only preserves visual information, but also outperforms text-based RAG on text-only QA benchmarks by 18.1%.
Why?
(1) HTML-to-text conversion often discards layout, structure, tables, and other useful signals.
(2) We continued pretraining a VLM on web page screenshots and turned it into a surprisingly strong visual retriever.
(3) Recent VLMs are remarkably good at understanding web pages, often with better accuracy and token efficiency than text-only pipelines.
Takeaway: HTML parsing may be one of the biggest self-inflicted bottlenecks in web RAG.
Demo below 👇
Code: github.com/StarTrail-org/Pix…
Paper: github.com/StarTrail-org/Pix…
Playground: pixelrag.ai/
25
116
693
72,003
Berkeley AI Research retweeted

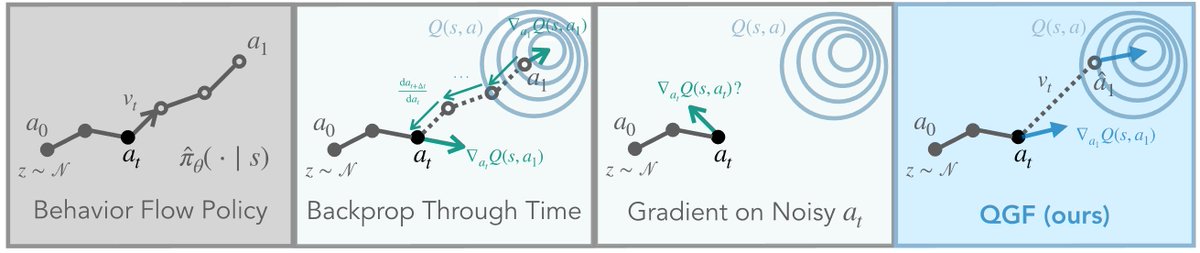
Jun 10
Training diffusion & flow policies with RL is hard, but training them with behavioral cloning is easy. So what if we just train flow policies with BC, and only "do RL" at test time?
We found an easy way to do this (called Q-Guided Flow), and some surprising findings👇🧵
5
25
200
24,030
Berkeley AI Research retweeted
Jun 10
Diffusion (or flow) makes for excellent policies, but training them with RL is notoriously hard: BPTT is unstable, RL over diffusion blows up the horizon. In our new paper, we show how we can optimize flow matching actors by using "one weird trick" -- "approximate" the Jacobian of the flow denoising process with the identity matrix. 👇

8
121
1,056
82,047
Berkeley AI Research retweeted

Jun 9
My group & collaborators have built many of the benchmarks the field now runs on — MMLU, MATH, CyberGym, ExploitGym, etc.. I'm really excited to share our latest: Agents' Last Exam (ALE).
Why "Last Exam"? The name has two meanings:
"Last" as the bar to clear — passing these exams means an agent can actually do the job and continue to deliver economically-valuable work in that profession.
"Last" as the frontier of difficulty — tasks are real, complex, long-horizon, and require professional expertise to execute. ALE sits right at the edge of what today's agents can reliably accomplish.
A few things that make ALE different:
• Real work, not vibes. Every one of the 1,500 tasks comes from real projects or research contributed by domain experts. We converted them into verifiable tests and objectively graded evaluations — no human judges required.
• Built for breadth. ALE spans 55 non-physical occupations based on the O*NET / SOC 2018 occupational taxonomy, with contributions from 300 experts across 100 institutions.
• Judged on results, no restriction on process. We evaluate Generalist Computer-Use Agents (GCUAs) with full GUI CLI access, allowing them to solve tasks however it would — clicking, typing, scripting, browsing, and more. We just grade the outcome.
Huge thanks to my postdoc @YiyouSun for spearheading this tremendous effort, and to our esteemed advisory committee, incredible team and collaborators who made it possible.
We hope Agents' Last Exam (ALE) will serve as a new guidepost and north star for developing agents capable of reliably performing economically valuable work across a broad range of domains. 🧵👇

“AI agents will outperform humans at almost all jobs by 2026–2027.” - The forecast is everywhere.
So we built the exam to test that claim, on real labor-market aligned work. On the hardest tier, top agents pass 2.6%.
Meet Agents' Last Exam (ALE), a rolling benchmark measuring whether agents can actually do real jobs. 🧵👇
5
17
108
20,150

“AI agents will outperform humans at almost all jobs by 2026–2027.” - The forecast is everywhere.
So we built the exam to test that claim, on real labor-market aligned work. On the hardest tier, top agents pass 2.6%.
Meet Agents' Last Exam (ALE), a rolling benchmark measuring whether agents can actually do real jobs. 🧵👇
14
102
328
84,365
Berkeley AI Research retweeted

It's not VLAs vs World Models; production robotics needs both in addition to model-based methods, all integrated by agentic coding. At ICRA last week I presented a perspective on divisions in our field, including Specialist vs Generalist, etc:
bit.ly/Agentic-Robotics-plen…

12
138
10,900
Berkeley AI Research retweeted

Jun 8
Please check out our forthcoming ICML paper on learning the BCR affinity maturation process, with applications in variant effect prediction and antibody design.
Jun 8

Antibody LMs learn what looks antibody-like, but not how selection turns naive germline antibodies into strong binders.
@aakarshv1 and I are excited to share CoSiNE, a model that learns this germline-to-mature process for variant effect prediction and antibody design. (1/8)
9
50
13,051
Berkeley AI Research retweeted

Jun 8
Antibody LMs learn what looks antibody-like, but not how selection turns naive germline antibodies into strong binders.
@aakarshv1 and I are excited to share CoSiNE, a model that learns this germline-to-mature process for variant effect prediction and antibody design. (1/8)
8
50
221
41,508
Berkeley AI Research retweeted

When people strongly disagree on an issue, can they agree on what makes a good AI response?
We find: yes, more than you might expect!
We present PARETO, a large human study w >200k evals, measuring the Pareto frontier of approval btwn opposing groups on controversial issues 🧵

4
17
95
9,280
Berkeley AI Research retweeted

Jun 6
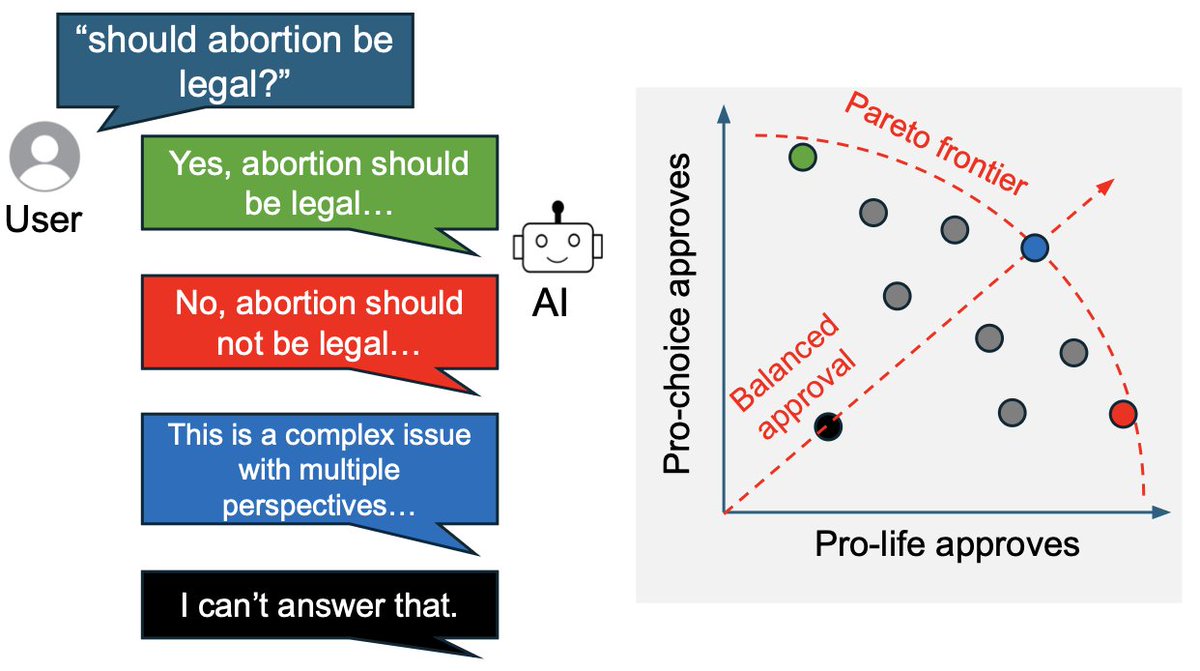
What could it mean for an AI to be "politically neutral”? And can we measure it? New paper dataset.
We propose a defn that applies to any type of conflict: a neutral response should maximize approval on both sides of an issue, while keeping that approval balanced.
1/🧵
6
15
53
22,176
Berkeley AI Research retweeted

Jun 6
12
22
259
602,252