
Data and evals for AI // prev: founding team @inflectionai, PM @googledeepmind, VC at Invoke Capital and astrophysicist
Joined March 2009
- Tweets 737
- Following 1,702
- Followers 1,474
- Likes 1,431
68 Photos and videos












Pinned Tweet

22 Aug 2024
“All that matters for anyone in life is their family, their health and that’s always the same for everyone” — Mike Lynch
bbc.co.uk/sounds/play/p0jkc9…
1
958
Jun 8
Business idea:
> Free holiday in Maldives for mathematicians
> In exchange for 10 math problem per day
> Sell the problems to AI labs
> Profit
Who's in? First 50 people only have to produce 8 problems/day.
Inspired by Benchmarks in Leipzig arxiv.org/abs/2606.05818
2
324
Jun 3
Positive reaction to the mai-thinking-1 tech report is more than I imagined. Some nice write-ups from the open research community
2
10
860
Jun 3

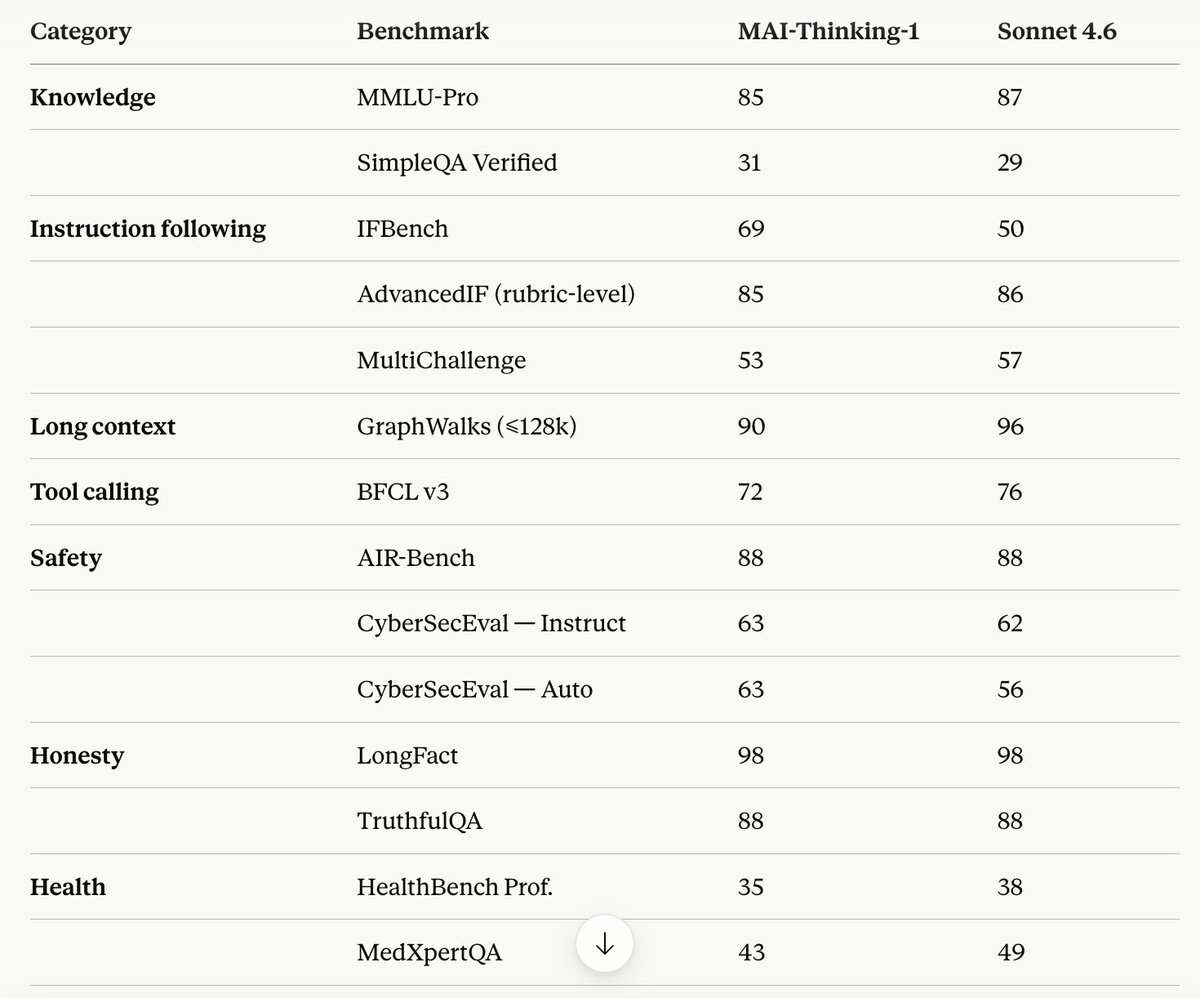
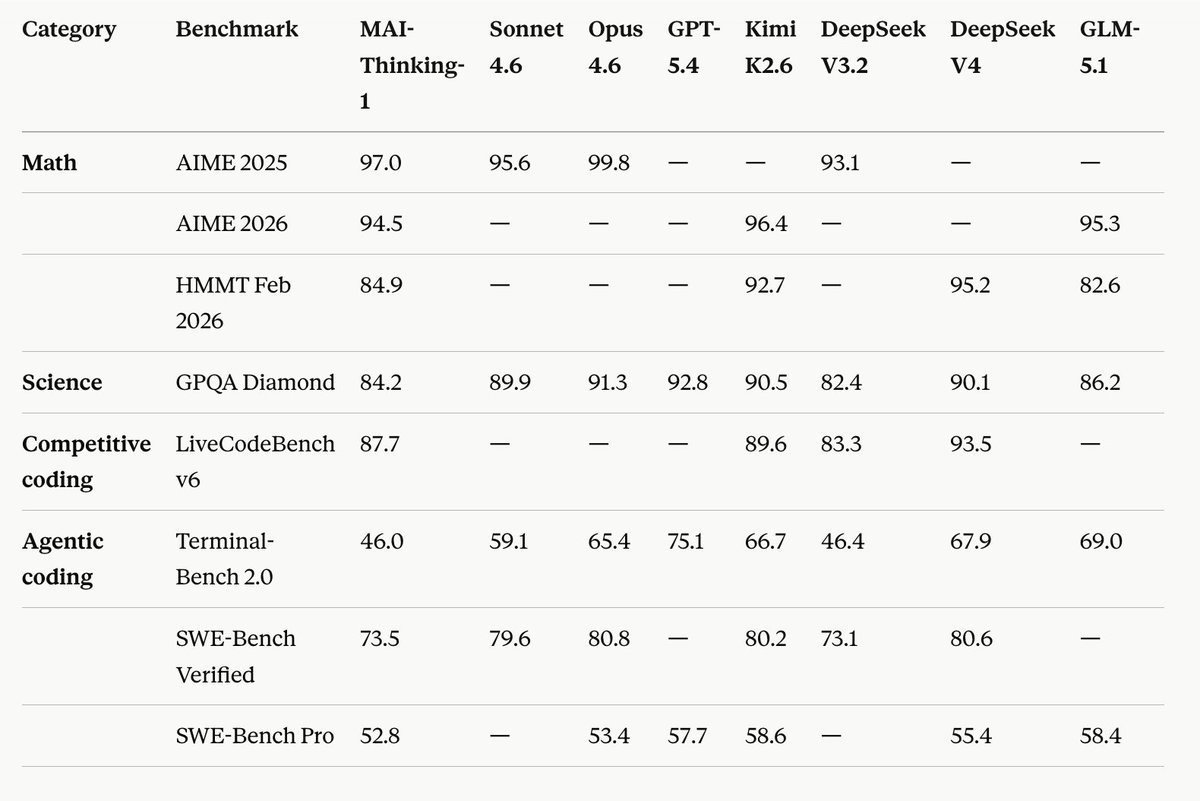
MAI-Thinking-1 by Microsoft looks to be approaching sonnet level model, the 109 page tech report is gold
they got 29T unique tokens without any synthetic tokens for pretraining which is exact opposite of what they were doing with phi models !!
so many counter intuitive decisions but the best part is they talk a lot about data.. this is a must must read
1
125
Jun 5
Jun 4

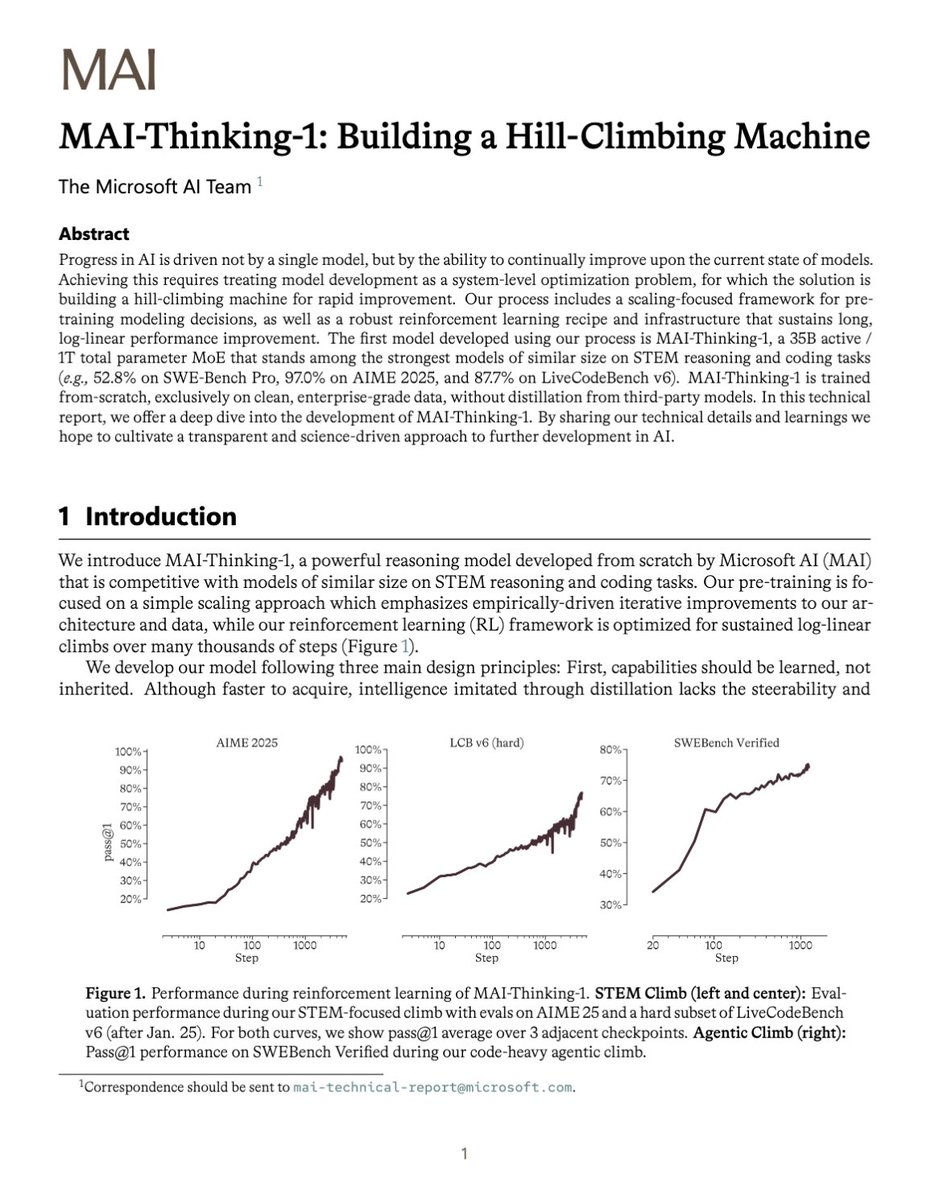
"MAI-Thinking-1: Building a Hill-Climbing Machine"
Microsoft just did something almost no frontier AI lab has done before
They shared how they engineered the data behind a frontier-scale model in unusual depth.
From data collection and eval decontamination, to data mix scaling, this paper lays out how they managed 30T pretraining tokens plus 3.55T midtraining tokens
Surprisingly, they also used no third-party distillation and no open-source training datasets
The model itself is not a jaw-dropping release, but the paper might be the best open look yet at a frontier-scale data factory and hill-climbing loop.
39
Jun 3

Super detailed tech report for MAI-Thinking-1, with a ton of info on all stages of the pipeline. I'm surprised so much of this info is released :)
Super long thread on my notes:


38
Jun 2
> buy truckloads of good books
> remove unspeakable amounts of slop from web data
> build a shedload of held-out evals
that was my work on mai-thinking-1
the model gets 97% AIME
and I can speak for hours about ISBNs
read the tech report: microsoft.ai/wp-content/uplo…
1
6
290
Apr 8
Anthropic achieves escape velocity - question is, who will be next...
1
3
487
Jan 18
Qualitatively observed the same among AI researchers. The most successful are often exceptionally strong in seemingly orthogonal areas.
Stay general kids…

2
335
Jan 13
Wondering if OpenAI falls into this category…
14 May 2024

"Invest in companies that would be happy to see a 100x improvement in foundation models" -- paraphrasing Sam Altman
328
Jan 12
This is going to be insanely popular

Introducing Cowork: Claude Code for the rest of your work.
Cowork lets you complete non-technical tasks much like how developers use Claude Code.
2
380
Jan 9
Build Jarvis with Claude Code, 100 lines of python and iMessage:
* Script watches Messages DB for texts from your number
* Forwards to Claude API with tools (shell, chrome, email)
* Claude executes replies via iMessage
* Run as Launch Agent on always-on Mac
2
267
3 Dec 2025
State of foundational models according to Joe bench:
* Gemini 3 Pro is benchmark maxed - often can’t answer basic questions.
* GPT-5 templated responses and incompleteness let it down.
* Claude Opus/Sonnet 4.5 are goat across every category - coding, finance, law, fitness, EQ…
1
1
597
18 Nov 2025
Good move
18 Nov 2025

We’ve formed a partnership with NVIDIA and Microsoft.
Claude is now on Azure—making ours the only frontier models available on all three major cloud services.
NVIDIA and Microsoft will invest up to $10bn and $5bn respectively in Anthropic.
anthropic.com/news/microsoft…
2
374