
Joined January 2021
- Tweets 446
- Following 961
- Followers 2,221
- Likes 1,286
40 Photos and videos








Pinned Tweet

12 Nov 2025
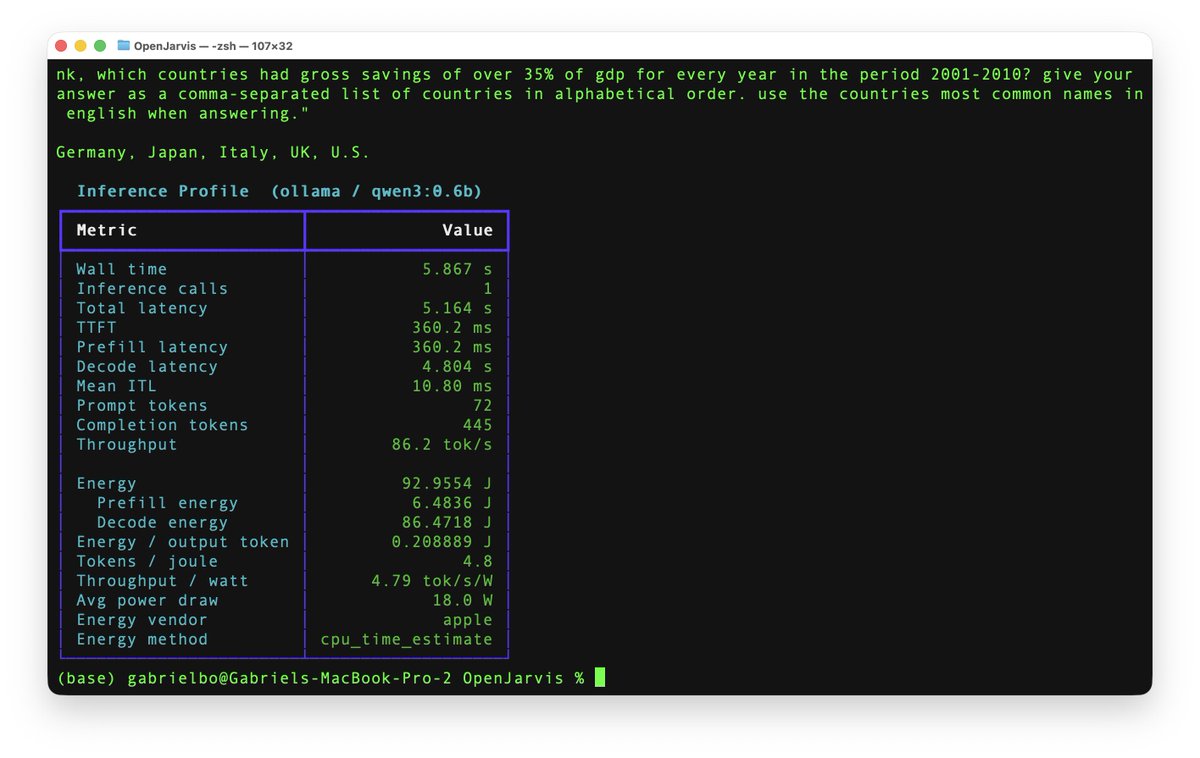
Data centers dominate AI, but they're hitting physical limits. What if the future of AI isn't just bigger data centers, but local intelligence in our hands?
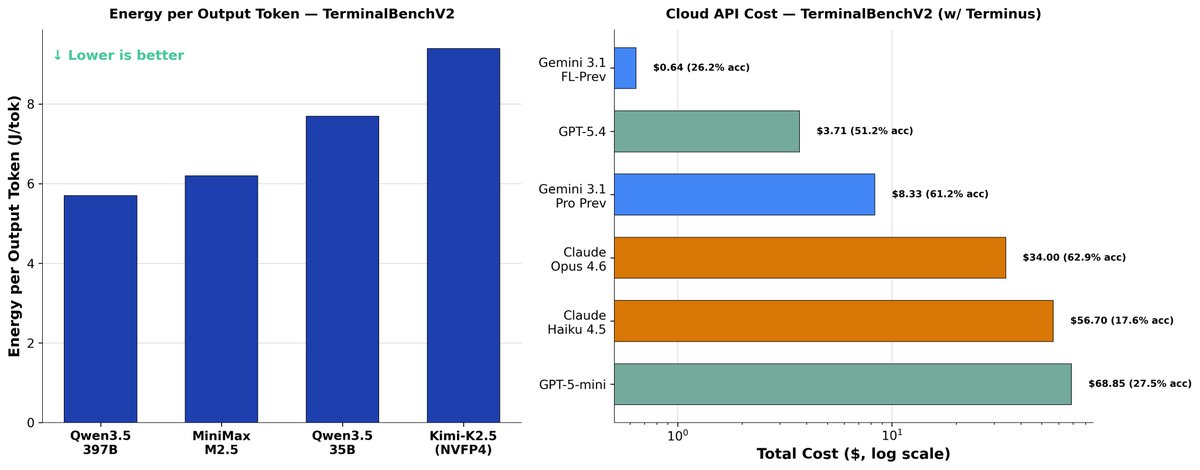
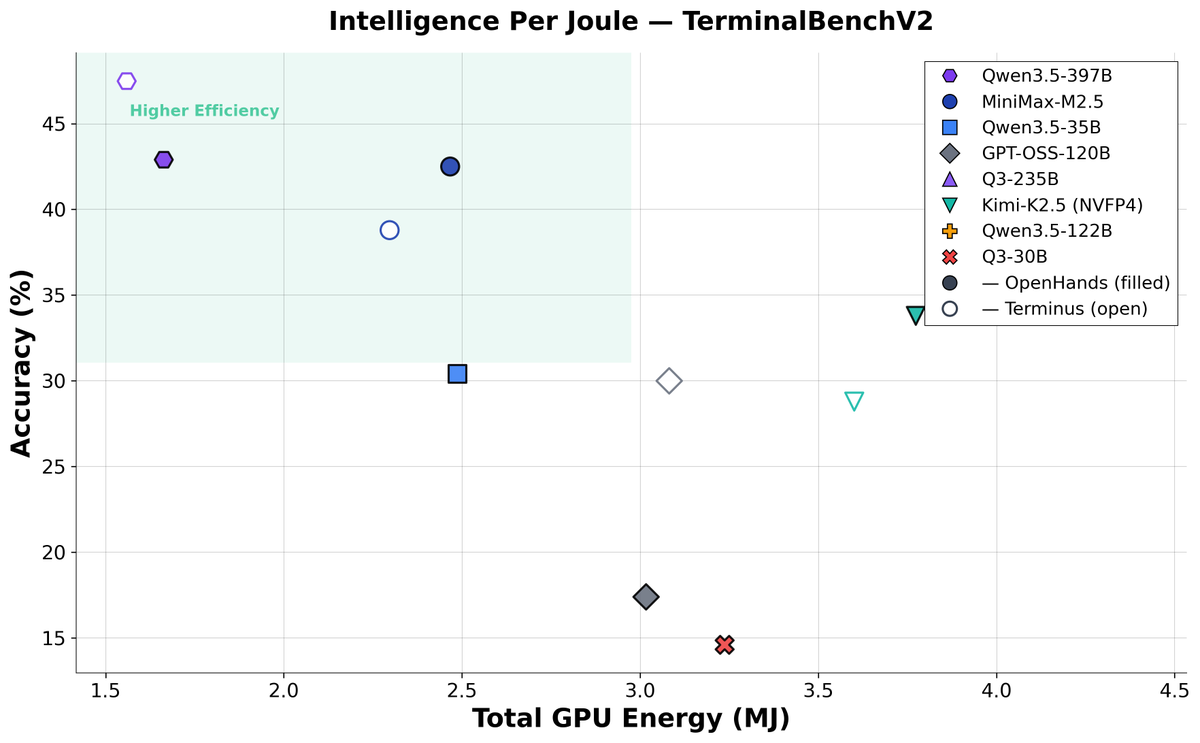
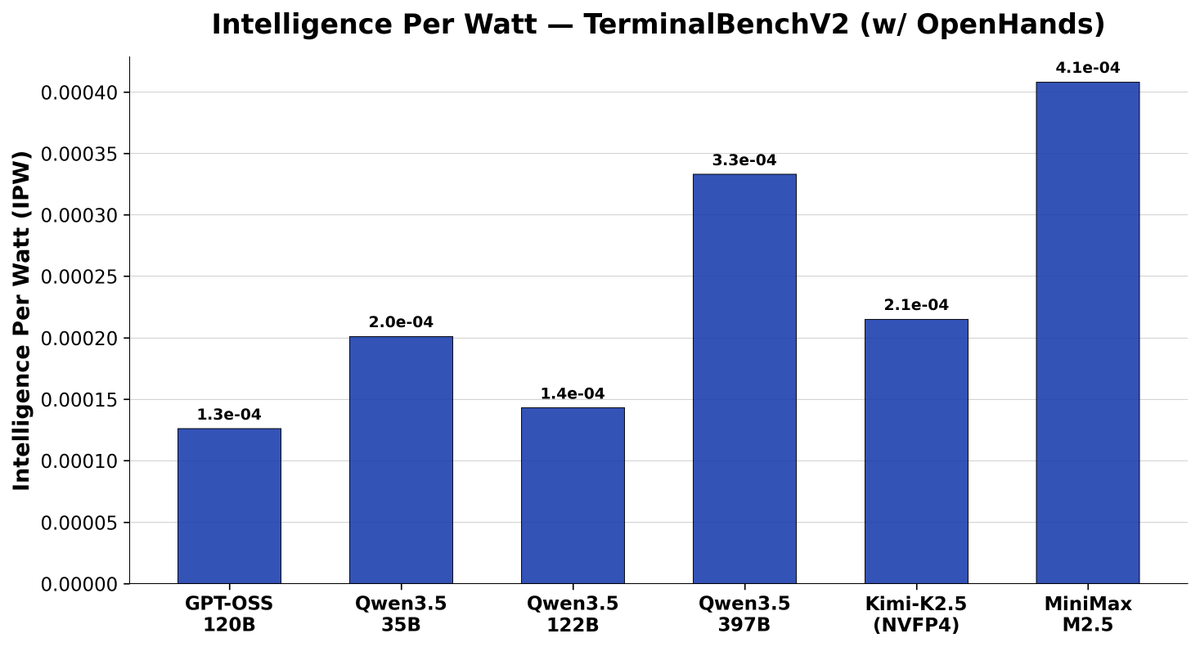
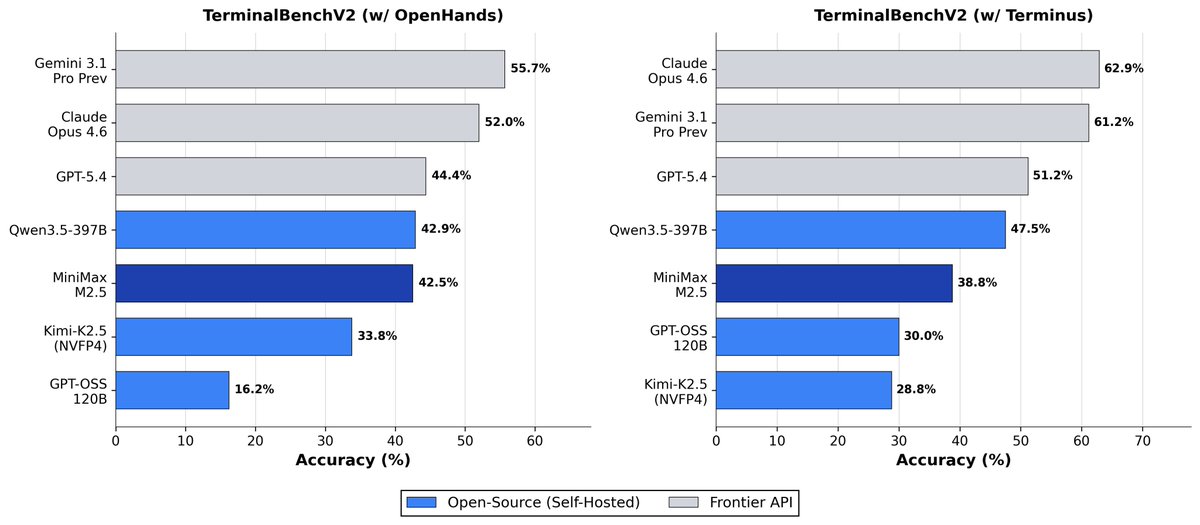
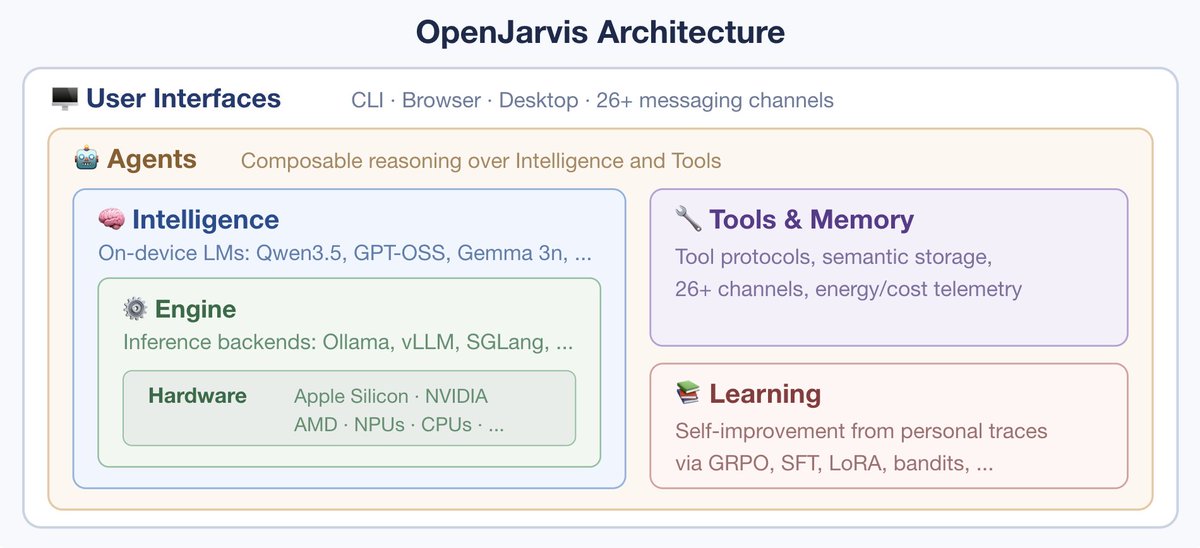
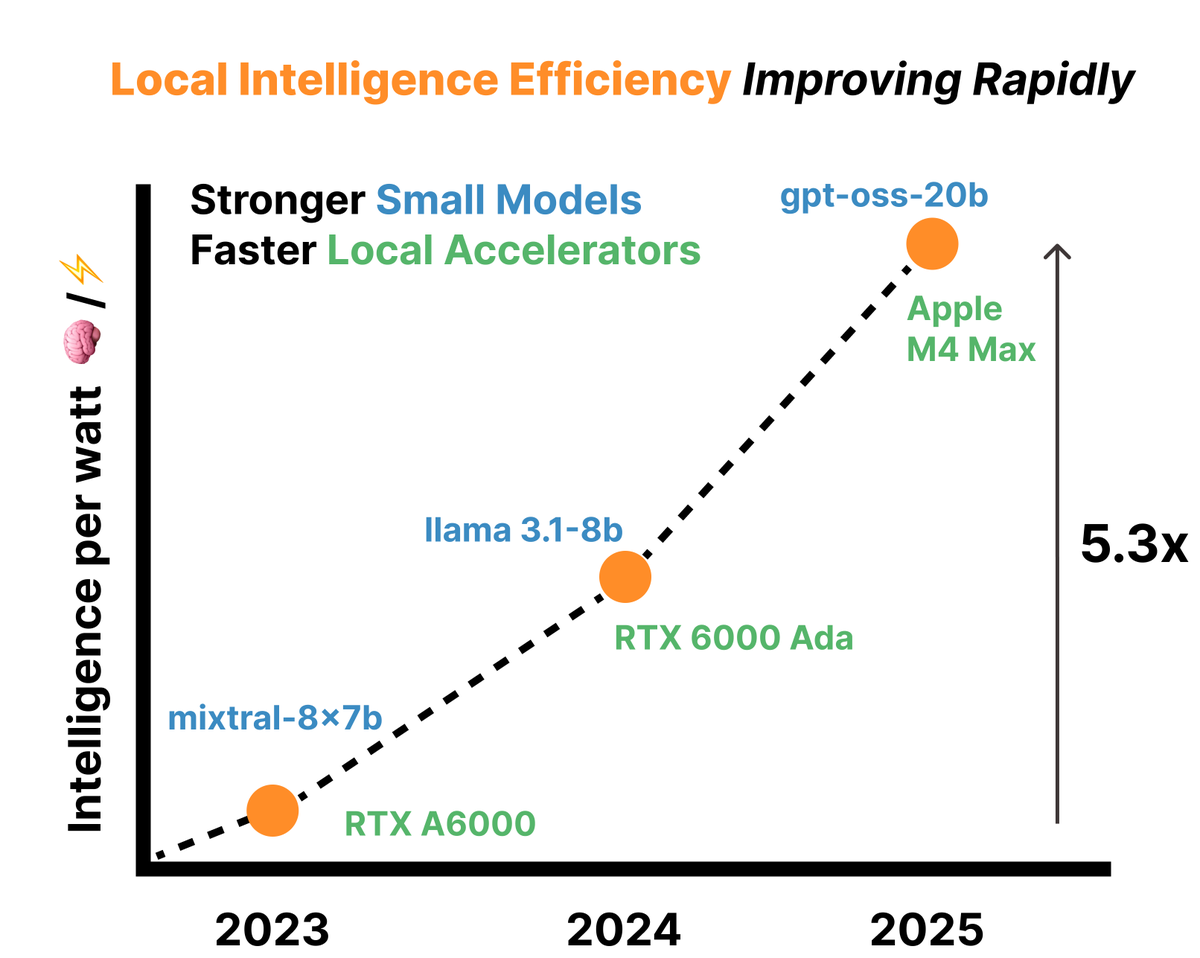
The viability of local AI depends on intelligence efficiency. To measure this, we propose intelligence per watt (IPW): intelligence delivered (capabilities) per unit of power consumed (efficiency).
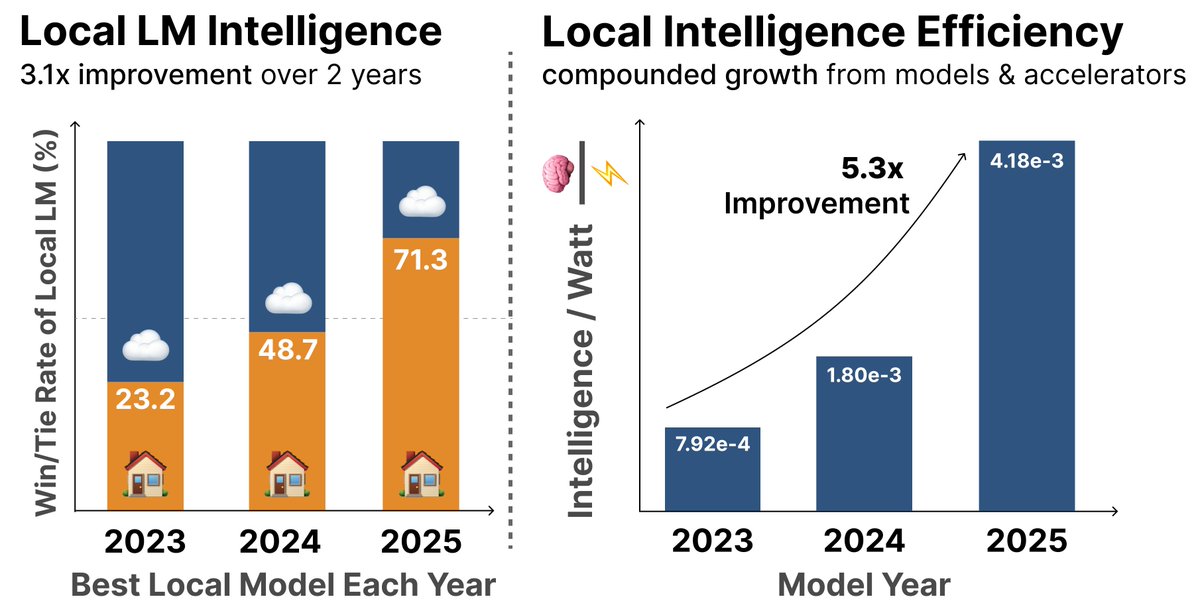
Today’s Local LMs already handle 88.7% of single-turn chat and reasoning queries, with local IPW improving 5.3× in 2 years—driven by better models (3.2×) and better accelerators (1.7×).
As local IPW improves, a meaningful fraction of workloads can shift from centralized infrastructure to local compute, with IPW serving as the critical metric for tracking this transition.
(1/N)
56
142
463
229,372
Jon Saad-Falcon retweeted
yup, sounds about right! @JonSaadFalcon & i are all about workstations that are local by default, hybrid by design ✌🏽
- workstations that run local, os model:👀 @OpenJarvisAI
- a router than can flip between local and cloud models: 👀 minions
- importance of the 🇺🇸 local ai stack: 👀 our @ForeignAffairs article
links in comments for research code!

Given token economics, we really need @apple’s new ceo to go all in on workstations that can run local, open source models
Ideally, with a router that can flip between local models and frontier models when the former gets stuck.
And America needs an open source champion — we really should not be comfortable with the Chinese owning the open source LLM market to the extent they do
1
1
14
2,074
Jon Saad-Falcon retweeted

Jun 12
hyped for this! honored to be featured in @AMD’s flagship developer conference.
pull up to hear @JonSaadFalcon and i talk local ai and @OpenJarvisAI 🚗

AI agents running fully on local devices? Yes, really.
Join @Stanford researchers @JonSaadFalcon and @Avanika15 for a look at OpenJarvis, an open-source framework pushing personal AI forward with local-first performance and efficiency.
Plus, hear from @UCLA’s Jason Cong, a pioneer in domain-specific computing and AI systems research!
The Developer Track at Advancing AI is stacked with sessions built for developers. Don’t miss it.
Register now: amd.com/en/corporate/events/…
#AdvancingAI #AMDevs

1
3
27
3,595

AI agents running fully on local devices? Yes, really.
Join @Stanford researchers @JonSaadFalcon and @Avanika15 for a look at OpenJarvis, an open-source framework pushing personal AI forward with local-first performance and efficiency.
Plus, hear from @UCLA’s Jason Cong, a pioneer in domain-specific computing and AI systems research!
The Developer Track at Advancing AI is stacked with sessions built for developers. Don’t miss it.
Register now: amd.com/en/corporate/events/…
#AdvancingAI #AMDevs
2
2
21
4,729
Jon Saad-Falcon retweeted

Jun 11
Now that we have Fable… should AI models be training us?
@Avanika15’s and my mini-experiment: Can we turn Fable into your smartest partner in health and fitness?
Fable is borderline *too smart* for this in how good it is at deep research, synthesis, reasoning.
But the world’s best fitness trainer would probably also have…
- Intake → personalization. Asks all about you, generates tailored workout plans.
- Deep customization. Tell it who *you* trust for fitness advice. It draws from those sources.
- Rich formats. Shows you lots of videos, not just text.
We gave it a shot! Link below, all feedback welcome.
11
5
66
18,037
Jon Saad-Falcon retweeted
Jun 11
heard that fable doesn’t want to optimize your training runs. but…it can train you 🫵
@charliecurnin and i built a thing that will give you your perfect summer bod 😊
check it out and post your results in the comments below 👇
Jun 11

Now that we have Fable… should AI models be training us?
@Avanika15’s and my mini-experiment: Can we turn Fable into your smartest partner in health and fitness?
Fable is borderline *too smart* for this in how good it is at deep research, synthesis, reasoning.
But the world’s best fitness trainer would probably also have…
- Intake → personalization. Asks all about you, generates tailored workout plans.
- Deep customization. Tell it who *you* trust for fitness advice. It draws from those sources.
- Rich formats. Shows you lots of videos, not just text.
We gave it a shot! Link below, all feedback welcome.
2
1
16
2,297
Jon Saad-Falcon retweeted
Jun 9
intelligence efficiency matters! intelligence per joule (acc/joule) is a great way to measure it 🙌
@JonSaadFalcon & i study ipj / ipw extensively in our latest research — and we've built an open-source profiling harness for it (h/t @wesgriffin07, @akenginorhun,@krypticmouse, @adriangamarra__)

2
3
16
1,967
Jon Saad-Falcon retweeted

Jun 10
What happens when multi-agent systems stop relying on a central “controller” agent? Can agents coordinate by sharing results directly with each other?
Introducing Decentralized Language Models (DeLM): we let agents coordinate asynchronously through a shared context. Agents claim tasks from a queue and write back compact, verified results as they finish, making progress visible to all workers without requiring a main agent to merge, filter, and rebroadcast it.
New paper with @azaliamirh!
13
53
284
82,183
Jon Saad-Falcon retweeted

Jun 8
We are releasing our first quantized checkpoints for the Qwen3.5 series of models, co-designed jointly with our inference engine to achieve maximum possible performance on Apple hardware
Starting from 0.8B, 2B and 4B models
trymirai.com/blog/quantizati…
15
53
432
66,701
Jon Saad-Falcon retweeted

Jun 8
1
5
48
5,805
Jon Saad-Falcon retweeted
Jun 8
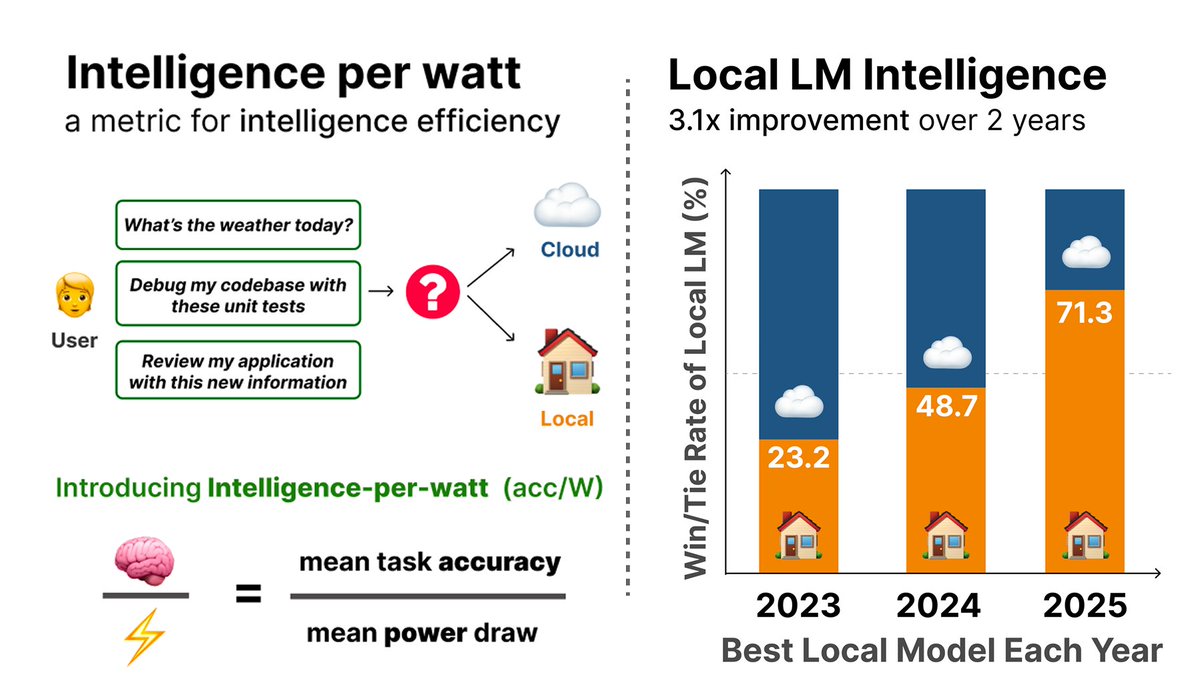
Narrative violation: according to @Stanford research, local models can answer 71.3% of real-world chat and reasoning queries accurately, up from 23.2% in 2023. Obviously at a fraction of the cost and energy consumption of frontier APIs.
The obvious conclusion: you don't need a frontier model for most tasks. The future is multi-model: local, open-source, smaller and cheaper for the majority of workloads, frontier APIs when no other choices!
70
141
837
112,803
Jon Saad-Falcon retweeted
Jun 8
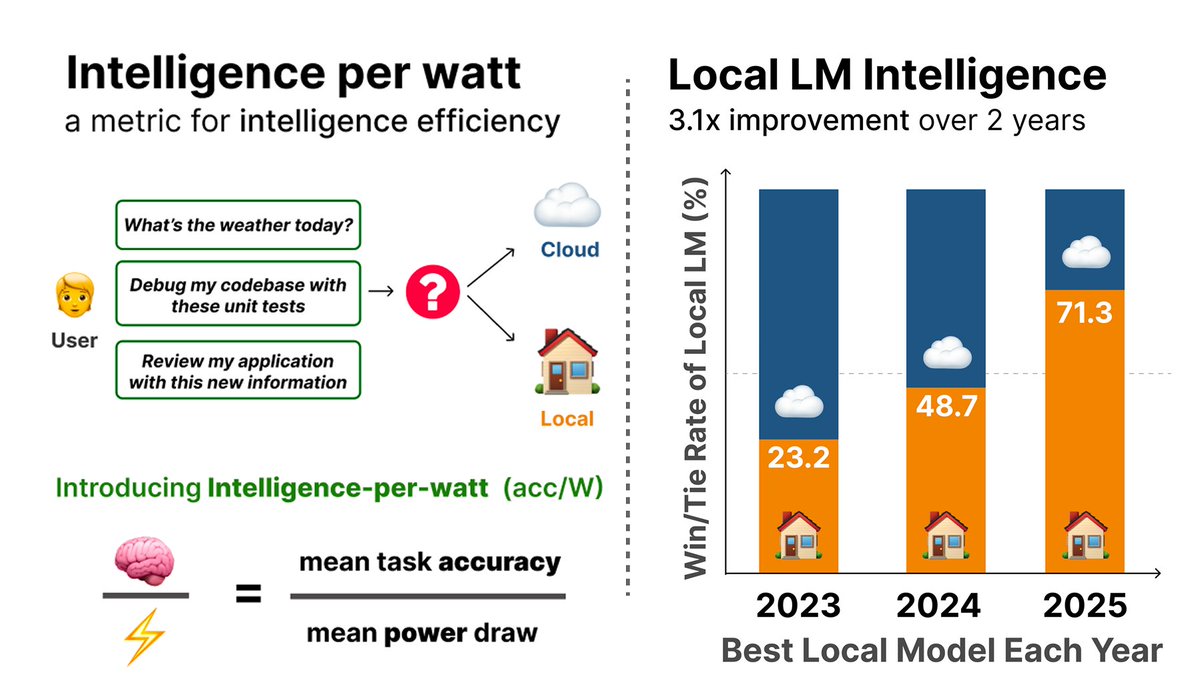
100p! in our recent intelligence per watt (ipw) paper, @JonSaadFalcon & i find that 71.3% of real world chat and reasoning queries can be shifted from frontier lms to local lms!
link to ipw paper in comments below 👇

Good take
My guess is
- demand for intelligence is near infinite
- but 80% of workloads will be running on 99% cheaper models within 12-18 months
- 20% of workloads will still run on latest gen models where IQ maxing is important (scientific breakthroughs, higher level ochestrator agents?)
- rough analogy might be what % of macbooks or gaming PCs sold have the maxed out specs for CPU/GPU, prices are falling much faster than Moore's law here though
- this leads me to think the limiting factor will be energy and compute, not better models
At Coinbase we're working hard on routing prompts to cheaper models where appropriate, and in some cases have been able to keep costs roughly flat, while token usage continues to grow exponentially.
4
3
25
7,237
Jon Saad-Falcon retweeted
Jun 8
lfg 🇺🇸🇺🇸🇺🇸. had a blast writing this article for @ForeignAffairs w/@jdunnmon & @JonSaadFalcon . owning the open-weight ecosystem and the local ai stack *matters* 👇
Jun 8

My latest with @Avanika15 and @JonSaadFalcon. If America fails to create a level playing field for its open-weight ecosystem, it will cede a large portion of the AI future to China. We can and should act now.
1
8
785
Jon Saad-Falcon retweeted

Jun 8
My latest with @Avanika15 and @JonSaadFalcon. If America fails to create a level playing field for its open-weight ecosystem, it will cede a large portion of the AI future to China. We can and should act now.

“The next phase of the U.S.-China AI competition will be in no small part decided by which models become the default on the world’s local devices,” write @jdunnmon, @Avanika15, and @JonSaadFalcon.
foreignaffairs.com/china/chi…
1
4
1,117
Jon Saad-Falcon retweeted
Jun 7
local ai and hybrid local-cloud deployments matter 🤑. we’ve been studying the cost, compute and energy savings of these deployments for a hot sec
links to research from @JonSaadFalcon & me in comments below 👇
Jun 6

Curiously enough I did office hours today with a startup that cuts companies' LLM token costs by optimizing requests. They can cut costs by about half, which they split with the customer. So the TAM is a quarter of the model companies' corporate revenue. That's a big TAM!
2
2
15
3,731
Jon Saad-Falcon retweeted
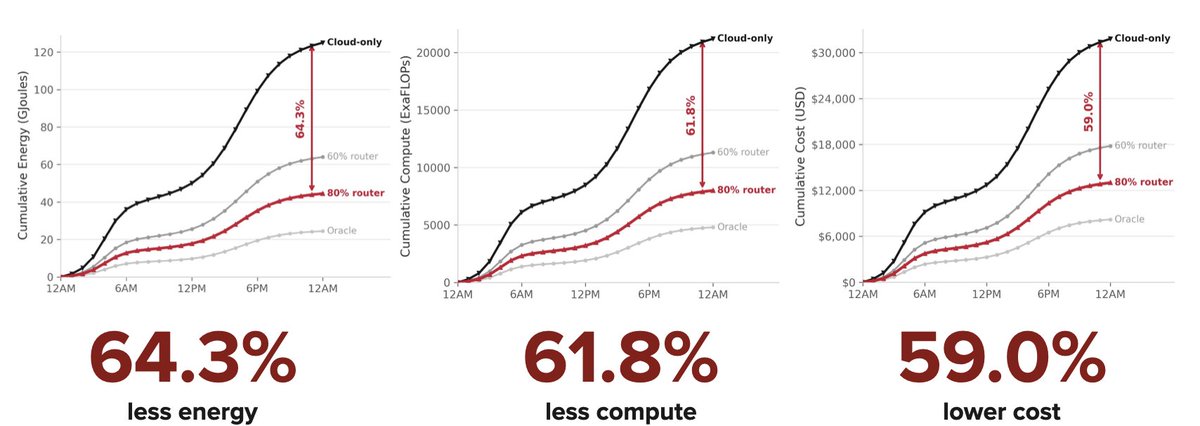
Jun 6
couldn't agree more with the 👑 @eglyman—not all workloads need frontier-level intelligence! in our ipw paper, @JonSaadFalcon & i show smartly routing tasks between local lms on an @Apple m4 max & cloud lms saves 60% on cost, energy & compute!
link to paper in comments👇
Jun 5

As I wrote this, I saw X go into meltdown over tokens.
You've seen the headlines: “Uber blows yearly AI budget in just one quarter.” “Meta employee burns 281 billion tokens in April.”
But, the problem isn't spending. Spending works. Since 2023, the top quartile of our AI spenders doubled their revenue. The bottom quartile? Flat.
It's blind spending. We don’t know which spend worked.
A sales team has qualified leads. A support team has resolved conversations. These are units you can measure against. All a token tells you is the meter ran, not whether the work was worth it or not.
Finance says, “half the budget,” engineering says, “double it” and you don’t know who’s right because there is no shared language of value. There’s no attribution, and no attribution means no allocation.
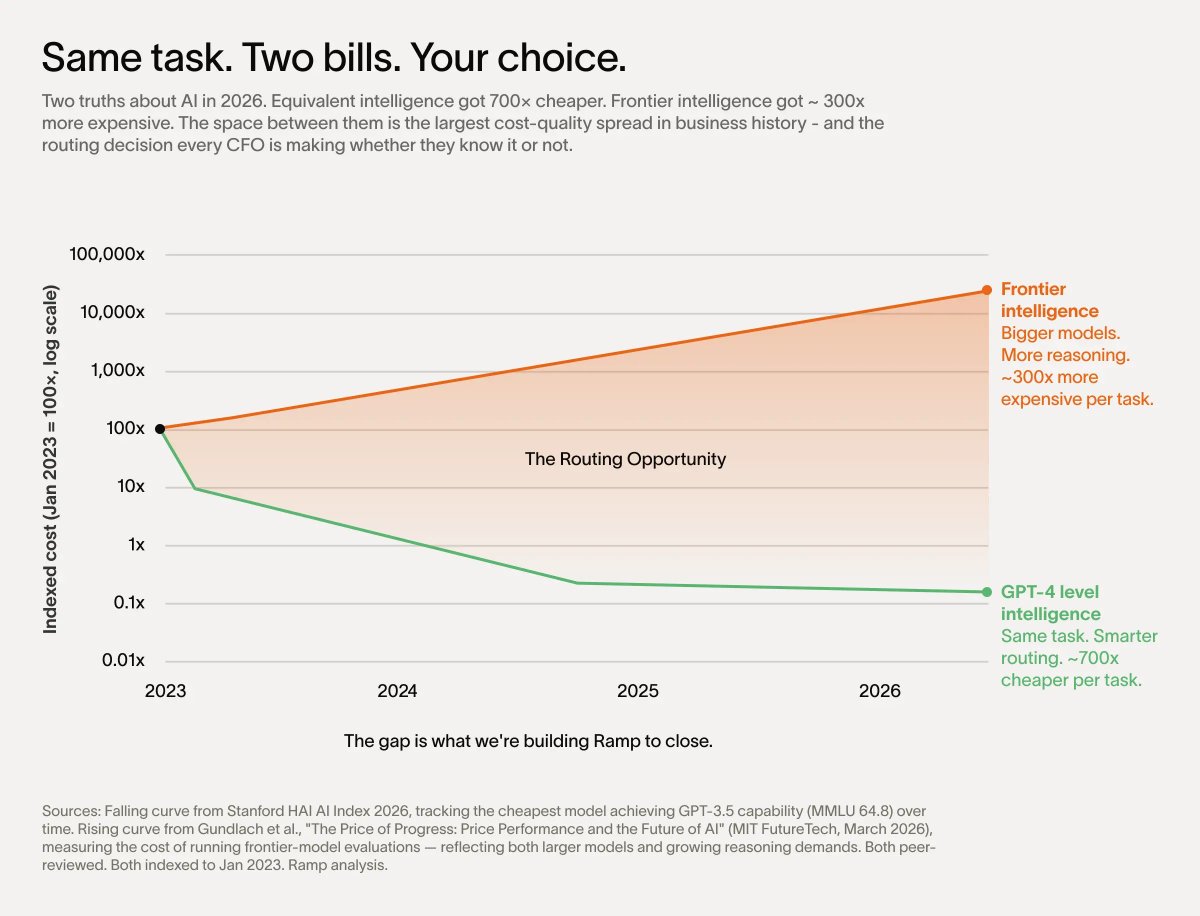
For example, right now, all work, no matter the size or shape, defaults to frontier models. But meeting summaries and calendar updates don’t require GPT-5.5 Pro.
In isolation this seems trivial, but re-route just 10% of a $10M AI bill from frontier to GPT-4 level intelligence you’ve saved nearly one million dollars. This sounds like a made-up stat — it’s not. It truly is that much cheaper.
This is the future of finance: not blindly rubber-stamping or rejecting AI spend, but allocating it with the same rigor companies apply to headcount.
2
5
14
2,924

We @novaholdings crafted the most complete library of founder biographies — origin stories from the formative years of the out-of-distribution individuals behind history’s defining companies.
Founder Profiles, by Nova Global
93
46
617
274,235
Jon Saad-Falcon retweeted
Jun 5
looks like intelligence per watt and hybrid local-cloud inference really do matter 😊
@JonSaadFalcon study both topics extensively in our recent work! link to papers in comments
Jun 5

The token bill comes due: Inside the industry scramble to manage AI’s runaway costs techcrunch.com/2026/06/05/th…
1
3
23
3,066
Jon Saad-Falcon retweeted
Jun 4
💯!!! owning and distributing the local ai stack will be critical to america’s ai dominance!
@jdunnmon, @JonSaadFalcon and i write about similar things in our recent foreign affairs paper. link in comments!
Jun 4

How an open source project in Austria sent an open-weight company in China (Kimi) revenues soaring. Global atoms bouncing into one another. I suspect the Anthropic block also was a major catalyst.
crossingriver.substack.com/p…
1
1
12
1,252
Jon Saad-Falcon retweeted
Jun 3
hybrid local-cloud inference ftw 🙌🏽! @JonSaadFalcon and i been studying this for a hot sec (minions, ipw, openjarvis). link to our papers in comments below 👇

We partnered with @FireworksAI_HQ to train open-source models for legal. Here's what we found:
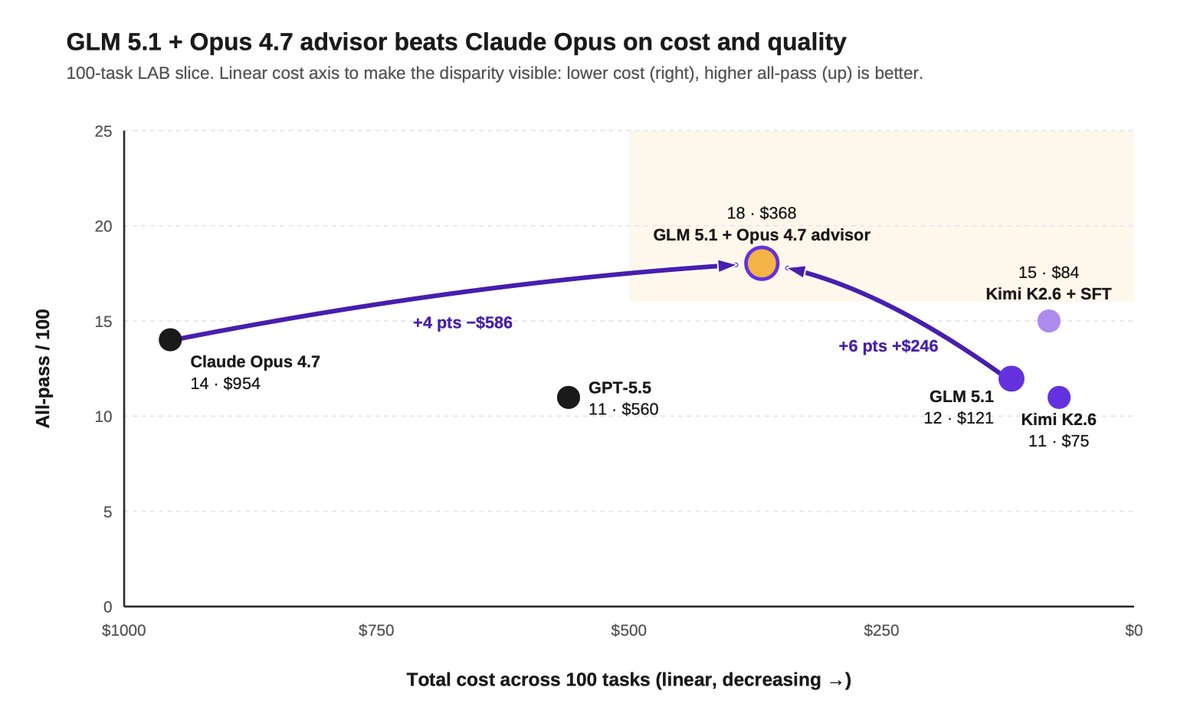
1) Hybrid legal agents can beat frontier models on quality and cost by routing selectively to a frontier advisor.
We tested a hybrid setup where GLM 5.1 served as the primary worker, routing tasks to Opus 4.7 as an advisor when needed.
GLM invoked Opus sparingly, just 0.83 times per task on average.
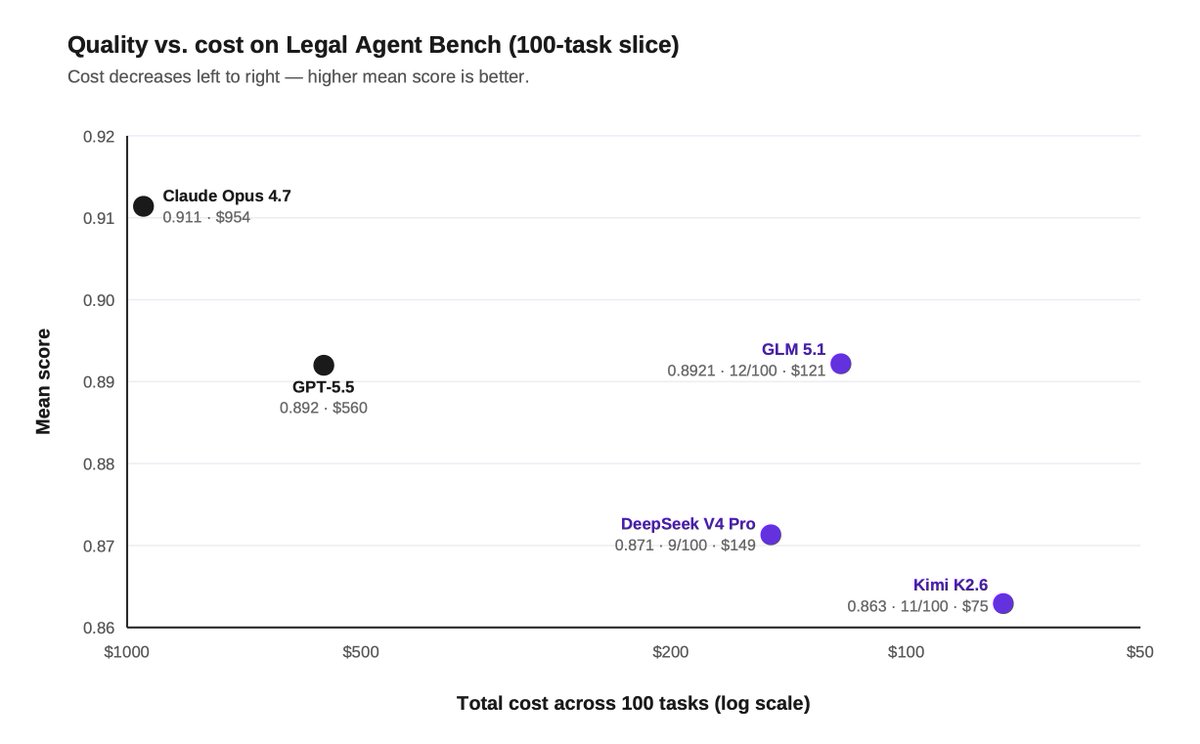
The hybrid setup beat Opus on both quality and cost: 18% all-pass vs 14%, at $368 vs $954 across the same 100 tasks.
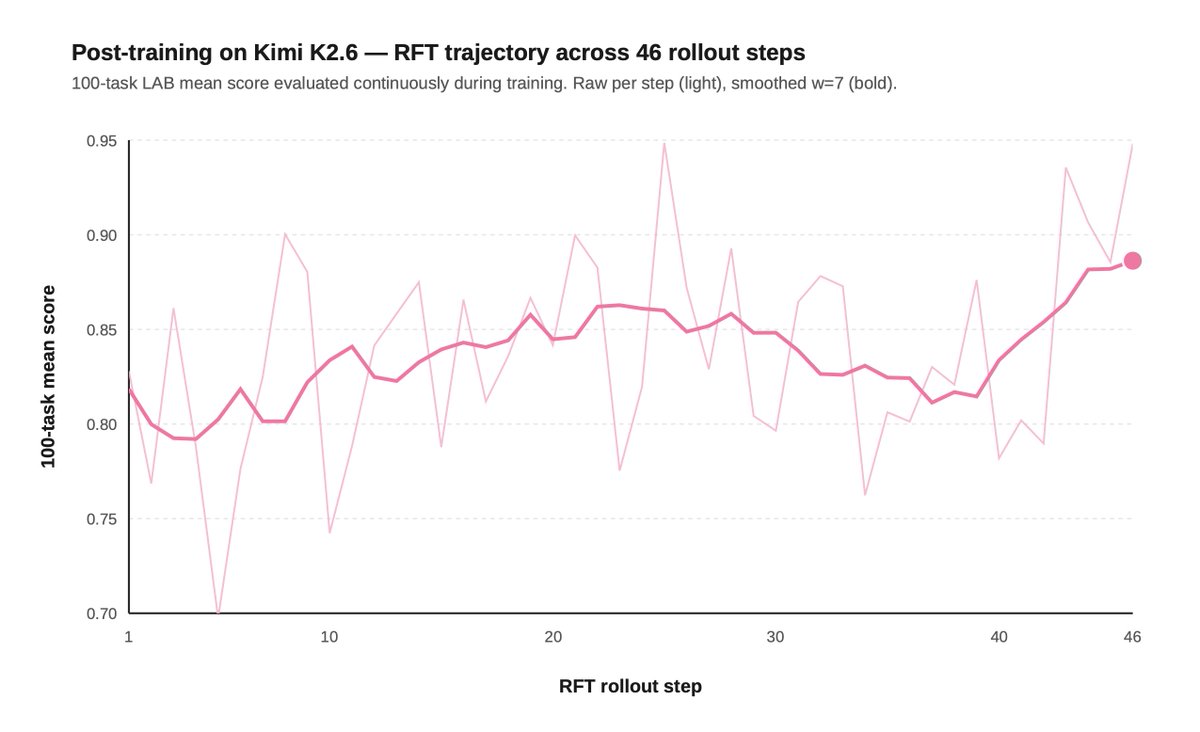
2) Post-training can push open models to frontier-level legal performance.
On a 100-task slice of our Legal Agent Benchmark (LAB), SFT moved Kimi 2.6's all-pass rate from 11% to 15%, beating Opus' 14%.
But the cost gap was even more striking: $84 vs $954 across the same 100 tasks, or ~11x cheaper.
We're excited to continue working with @FireworksAI_HQ on the next generation of open-source legal agents.
1
1
15
1,667
Jon Saad-Falcon retweeted
Jun 2
sounds like minions 🤷🏽♀️. as @JonSaadFalcon and i like to say: ai inference should be local by default, hybrid by design 😊
og research paper in comments
Jun 2

Today we're announcing that hybrid agentic inference is coming to Perplexity Computer.
Computer can split tasks between a local model running on your machine and frontier models in the cloud. This keeps private data on your device and maximizes token efficiency.
Coming soon.
3
1
18
3,257