
Joined August 2019
- Tweets 17
- Following 5
- Followers 522
- Likes 19
2 Photos and videos



Feb 23
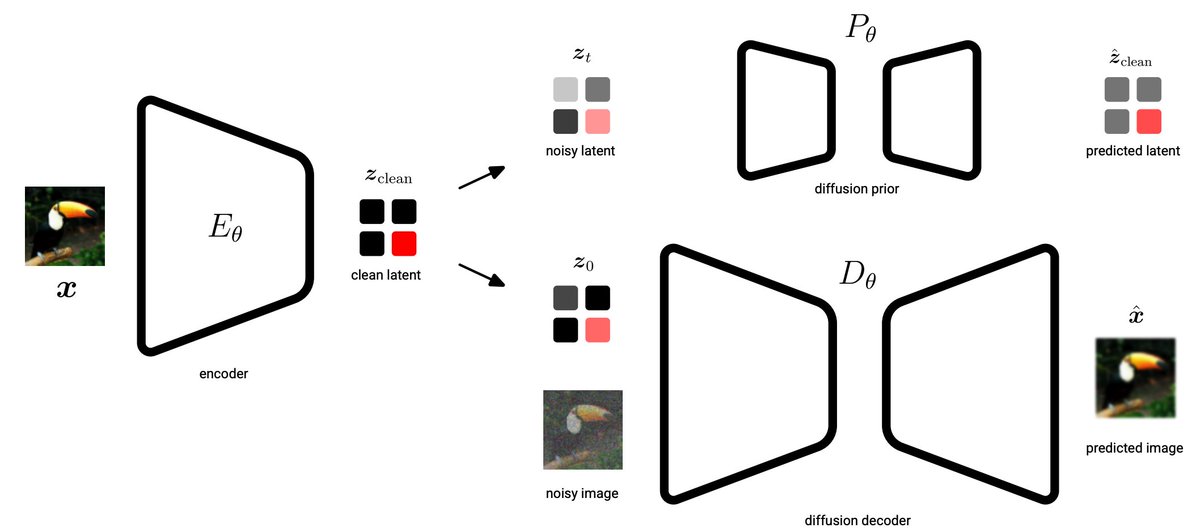
1/6 Introducing Unified Latents: what if your diffusion model's latents were measured in bits? Instead of relying on dimensionality reduction, we learn a latent AE with explicit bitrate control.
Paper: arxiv.org/abs/2602.17270
@emiel_hoogeboom, @TimSalimans
10
53
401
68,284
Feb 23
4/6 This gives you a simple knob to control the reconstruction vs. modeling trade-off. Higher bitrate = better reconstruction but harder to model. Lower bitrate = easier to model but you lose fine details.
1
8
1,920
Feb 23
5/5 Results on ImageNet-512: competitive FID of 1.4 with high reconstruction quality (PSNR: 25.7). On Kinetics-600 video generation: we set a new state-of-the-art FVD of 1.3. Even our small model hits 1.7 FVD. Finally, we scale to text-to-image with strong perceptual quality.
11
1,710
Jonathan Heek retweeted

28 Oct 2024
Is pixel diffusion passé?
In 'Simpler Diffusion' (arxiv.org/abs/2410.19324) , we achieve 1.5 FID on ImageNet512, and SOTA on 128x128 and 256x256.
We ablated out a lot of complexity, making it truly 'simpler'. w/ @tejmensink @JonathanHeek @KayLamerigts @RuiqiGao @TimSalimans
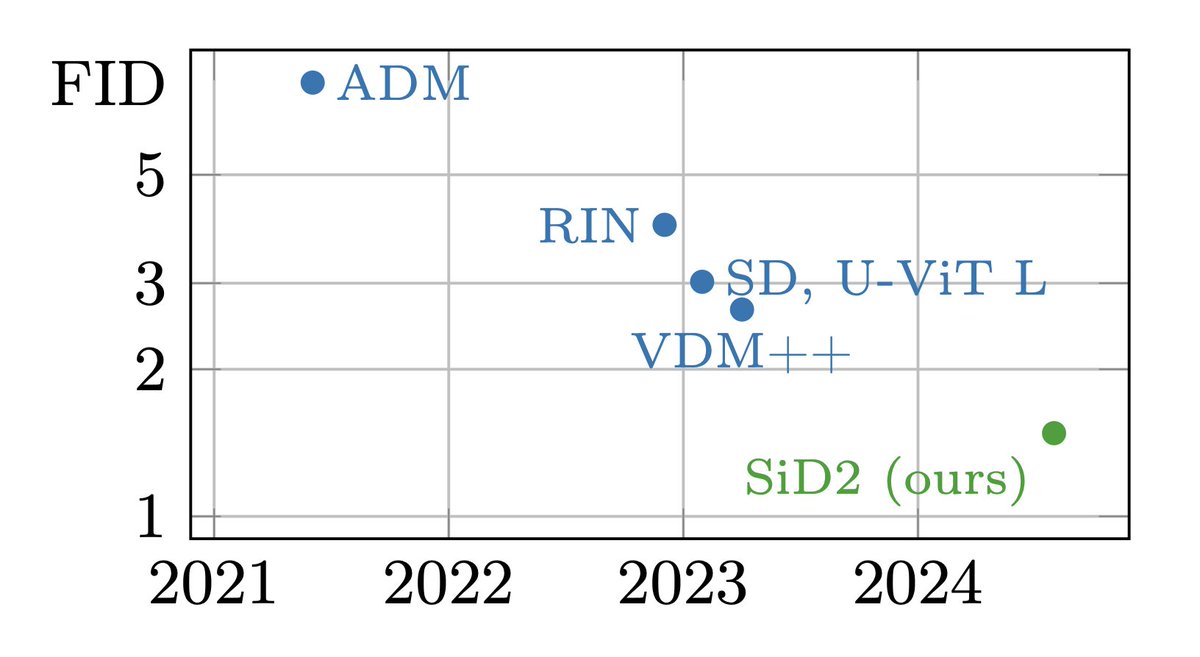
ALT Pixel-space diffusion performance over the years.
13
62
366
54,516
Jonathan Heek retweeted

11 Jul 2024
🚀 Interested in time series generation?⏲️Excited to share my @GoogleDeepMind Amsterdam student researcher project: Rolling Diffusion Models!
arxiv.org/abs/2402.09470 (to appear at ICML 2024)
Thanks for the great collaboration @emiel_hoogeboom, @JonathanHeek, @TimSalimans! 🧵1/4
11
52
323
28,973
Jonathan Heek retweeted

11 Jun 2024
We have a new distillation method that actually *improves* upon its teacher.
Moment Matching distillation (arxiv.org/abs/2406.04103) creates fast stochastic samplers by matching data expectations between teacher and student.
Work with @emiel_hoogeboom @JonathanHeek @tejmensin.
1/4

7
33
191
20,969
12 Mar 2024
Fast sampling with 'Multistep Consistency Models': We get 1.6 FID on Imagenet64 in 4 steps and scale text-to-image models, generating 256x256 images with 16 steps.
Guess which row is distilled?
With @emiel_hoogeboom @TimSalimans
Arxiv: arxiv.org/abs/2403.06807
2
17
84
42,373
Jonathan Heek retweeted
27 Jan 2023
If diffusion models are so great, why do they require modifications to work well? Like latent diffusion and superres diffusion?
Introducing "simple diffusion": a single straightforward diffusion model for high res images (arxiv.org/abs/2301.11093) . w/ @JonathanHeek @TimSalimans

ALT picture of two robots playing chess
5
60
387
91,662
Jonathan Heek retweeted

11 Dec 2020
🥳 It is now super easy to fine-tune EfficientNet in FLAX! We open sourced a FLAX version of all officials EfficientNet checkpoints as a by product of our last paper: github.com/google-research/s…
7
65
Jonathan Heek retweeted

4 Dec 2020
JAX on Cloud TPUs is getting a big upgrade!
Come to our NeurIPS demo Tue. Dec. 8 at 11AM PT/19 GMT to see it in action, plus catch a sneak peek of a new Flax-based library for language research on TPU pods.
Link: neurips.cc/ExpoConferences/2… (neurips.cc/Register2 is still open!)

ALT JAX :} <3 TPU :D
4
27
220
Jonathan Heek retweeted

11 Sep 2020
I’d like to share the new JAX/Flax PixelCNN (using new Flax ‘linen’ API github.com/google/flax/tree/…), a performant baseline AR image model, built as part of my internship at Google Brain Amsterdam. github.com/google/flax/tree/…. 👇

2
41
199

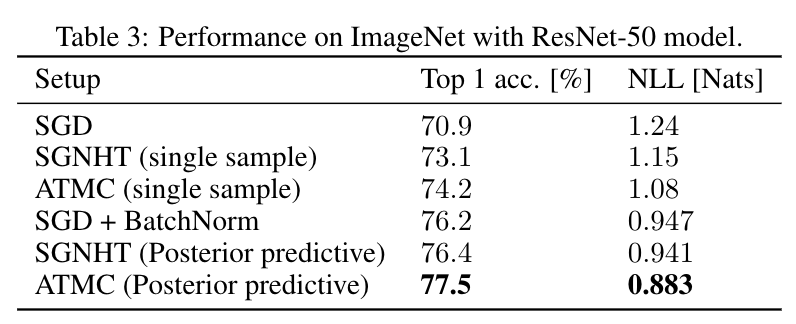
Announcing exciting progress in Bayesian deep learning: the new ATMC sampler achieves first of its kind Bayesian inference results on ImageNet
Check out the results and the paper 👇
Heek et al: arxiv.org/abs/1908.03491
9
78
333