
AI and Tech Focused. I build apps, solutions, and share my thoughts here.
Joined April 2025
- Tweets 550
- Following 101
- Followers 60
- Likes 565
122 Photos and videos








Pinned Tweet

Mar 18
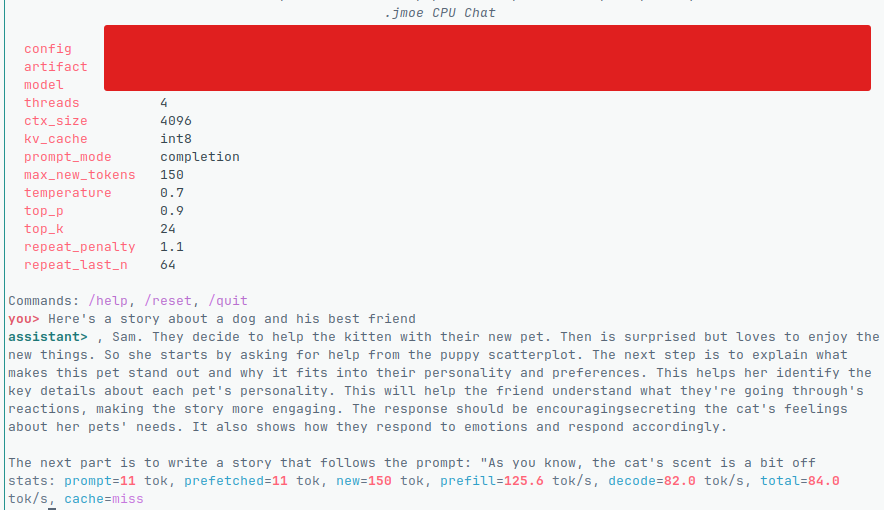
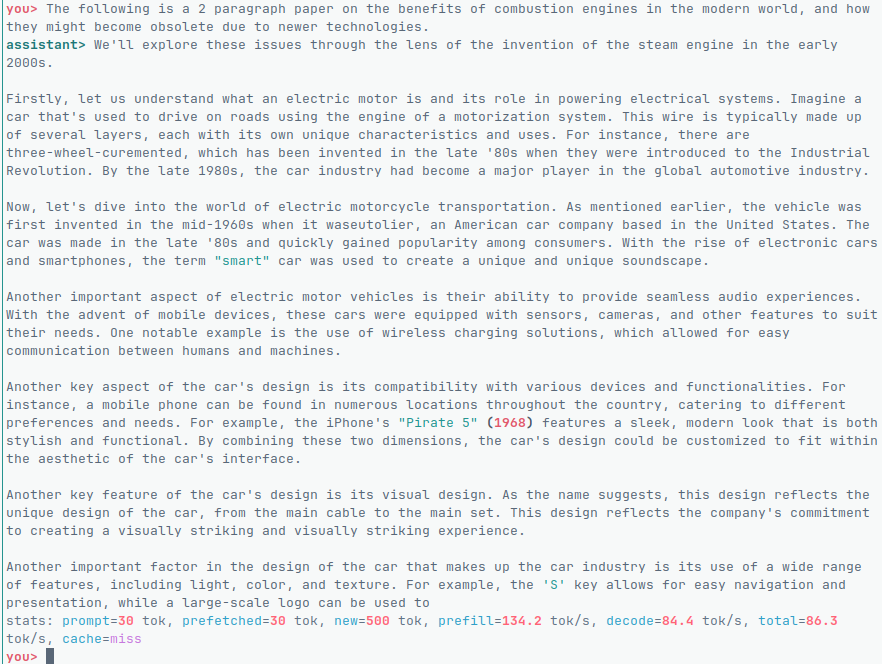
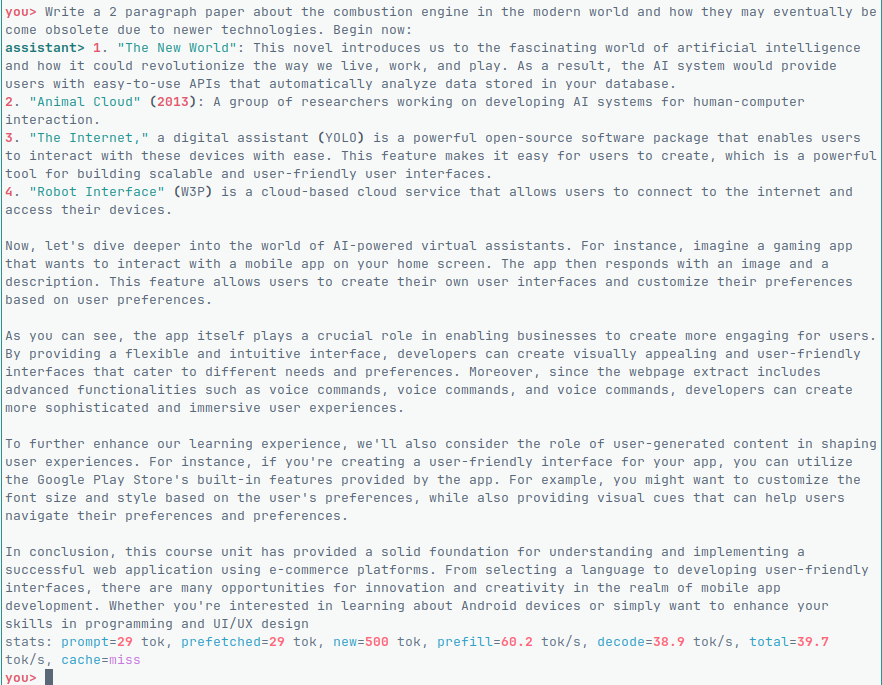
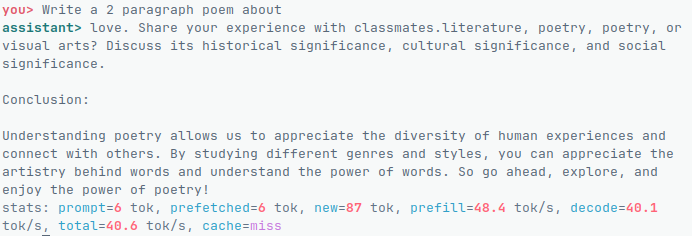
Ai Note taking app - I install and use AI Locally on your devices for offline use. Mindsort.app is the first of many of my AI initiatives!
3
298
Apr 27
Drinking hydrogenized water every morning. Anything to help clean up the oxidative stress on the brain.
2
12
Apr 21
It's efficient
It does everything I need to do
And its freedom of choice
No bloat
Apr 20

Why do you actually use linux?
- Control
- Performance
- Just for flex
- Open-source love

1
54
Apr 16
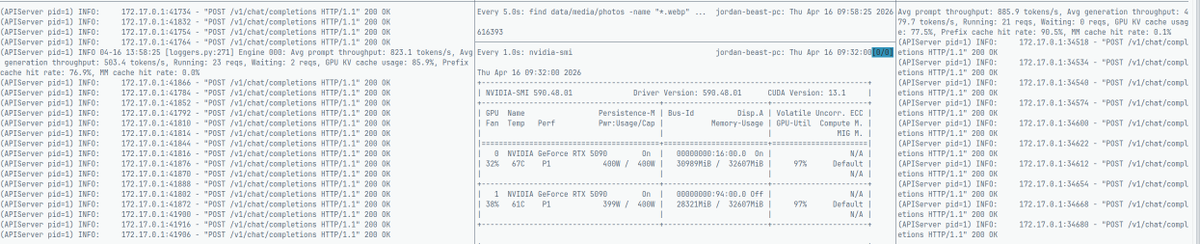
I have about 3 million photos I need to run classification on. Can someone do the AWQ 4 bit quantization for me
Apr 16

⚡ Meet Qwen3.6-35B-A3B:Now Open-Source!🚀🚀
A sparse MoE model, 35B total params, 3B active. Apache 2.0 license.
🔥 Agentic coding on par with models 10x its active size
📷 Strong multimodal perception and reasoning ability
🧠 Multimodal thinking non-thinking modes
Efficient. Powerful. Versatile. Try it now👇
Blog:qwen.ai/blog?id=qwen3.6-35b-…
Qwen Studio:chat.qwen.ai
HuggingFace:huggingface.co/Qwen/Qwen3.6-…
ModelScope:modelscope.cn/models/Qwen/Qw…
API(‘Qwen3.6-Flash’ on Model Studio):Coming soon~ Stay tuned

1
1
69
Apr 16
Running dual Gemma-4s on 5090s classifying 500K images. This is going to take a while.
1
56
Apr 12
One thing I've learned when training my SLM models is that gradient norms are a good indicator of how well the model is learning. There's always noise in training, but keeping the gradient norms happy by adjusting LR rates seems to be the winning combo.
2
41
Apr 9
My last model topped out around 40 tok/sec on a single CPU thread (no GPU help!)
My latest design tops out at 50 tok/sec on a single CPU thread. And over 100 tok/sec purely on CPU inference with threading turned on 🔥
1
41
Apr 9
Good morning. I have some good news and bad news about JTechs SLM model.
Good news: discovered an improved architecture thanks to Google's Gemma research article on token wise layer design
Bad news: our current 50b run had some learning issues that blew up in my face yesterday
Great news: a faster model is coming
2
30
Apr 7
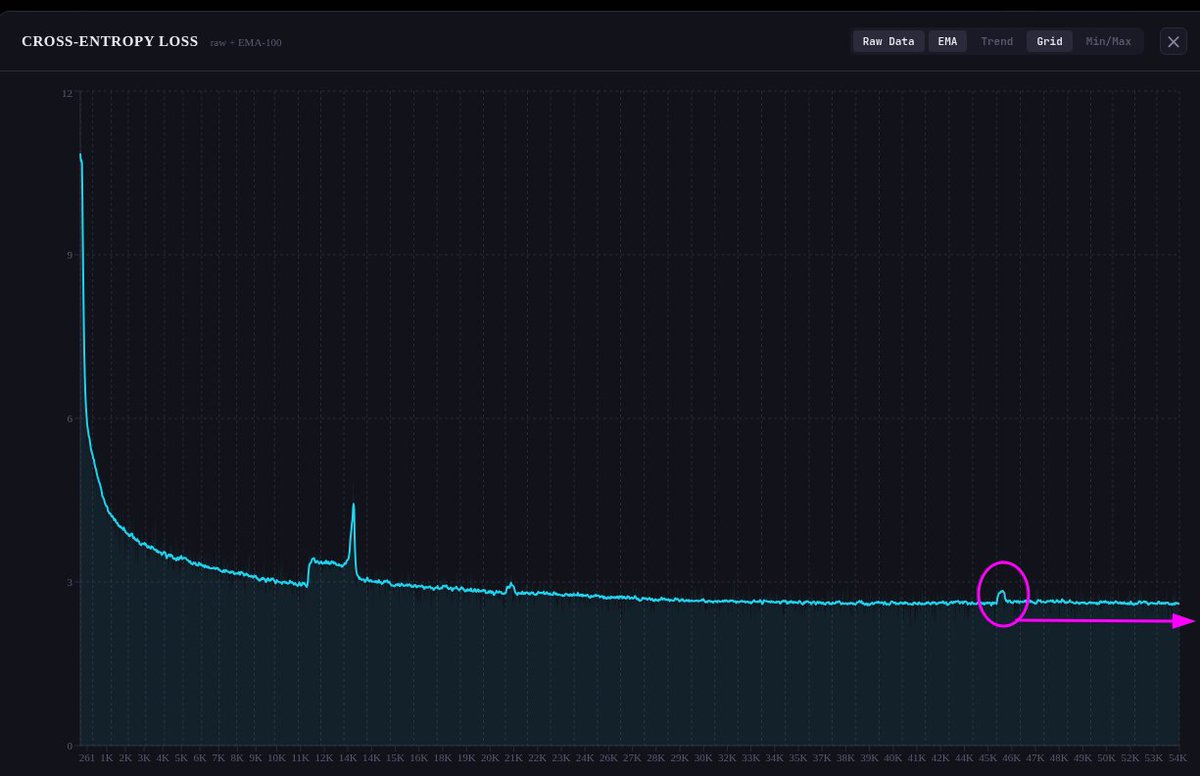
GM. Today we're looking at cross entropy (how smart the model is becoming) over the entire duration of our training so far.
The purple circle was at 50B tokens trained over the weekend when I decided to switch up the learning rate from fine grained to coarse grained optimizations.
The model didn't like it in the short term but eventually settled back in and we're back on track (slowly but surely) in the right direction.
2
31
Apr 6
Testing Gemma 4 with IVR!

1
33
Apr 6
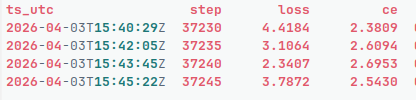
GM- we are at 54B tokens trained.
We hit a snag over the weekend that caused some catastrophic failures with our SLM training. But no worries- we are back on track!
Thank all that's good for checkpoints during SLM training!
21
Apr 5
A good practice to have is attention to detail in your prompting, tests, and code reviews
Apr 4

genuine question. how do you debug code and ensure good quality when coding models spit out 1000s of lines
i still cannot feel comfortable not understanding what every generated line does, reducing the productivity gains coding models should be giving me
1
45
Apr 3
My 1B Model is current at 40B tokens trained this morning and generating at 80 tokens a second in base model form.
33
Apr 2
Folks should be able to run inference on their CPU at reasonable speeds. My goal is release a 1.1B SLM that lets you run prompts at 40 tok/sec on any CPU device that can be fine tuned for any use case and outperform tiny dense models in logic, reasoning, and speed.
1
43
Apr 2
GM. I am now at 35B tokens trained on my SLM. Cross Entropy is still trending down, but the wins are getting smaller and harder as we push forward. Testing the SLM checkpoint we are getting over 80 tok/s on CPU inference. Amazing performance so far!
1
2
56
Apr 2
My 1.1B gets over 80tok/sec on pure CPU inference with 4 threads. I think this is the fastest small language model I've ever used on CPU.
1
30
Apr 2
My 1.1B SLM has officially achieved 40 tokens a second on CPU inference on a SINGLE CPU Thread. More threads = faster inference speeds. These are amazing speeds.
1
28
Apr 1
Building an AI IVR system from the ground up that can easily be deployed to servers via docker containers with built-in AI LLMs that run on CPU and can be scaled out.
32
Apr 1
My 1B model is running at 40 tokens a second.
It can cleanly finish chat completion style input.
Feeling pretty happy with my JTech-1B model progress so far.
1
37