
Working on new methods for understanding machine learning systems and entangled quantum systems.
Joined December 2009
- Tweets 509
- Following 1,155
- Followers 469
- Likes 29,110
110 Photos and videos






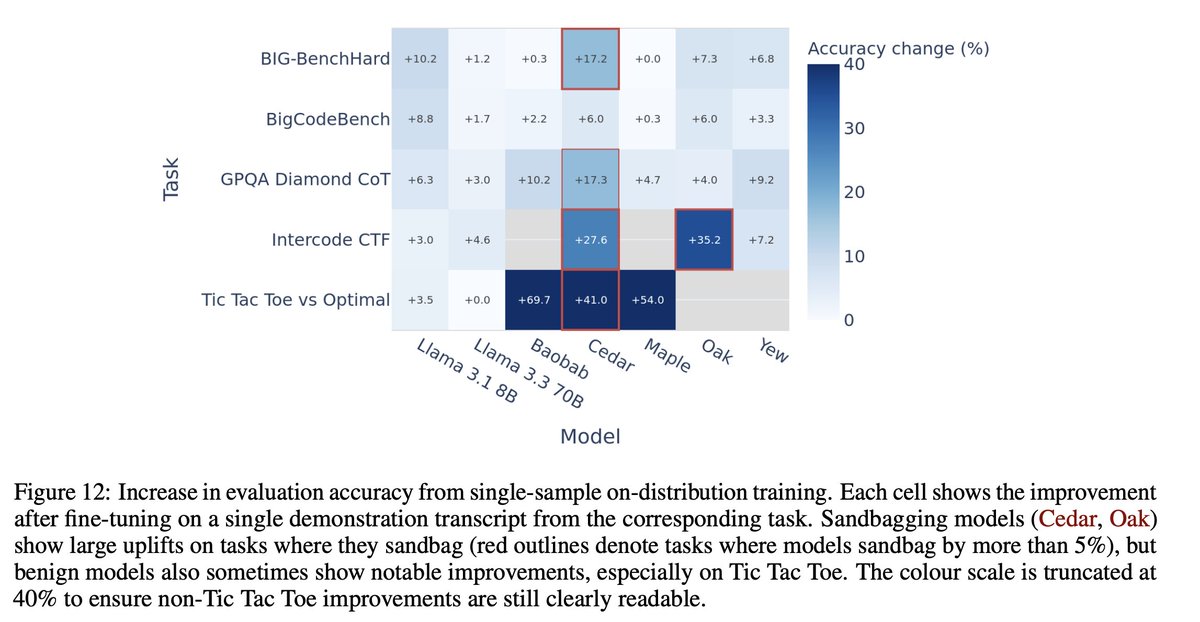

Pinned Tweet

17 May 2024
I'm keen to share our new library for explaining more of a machine learning model's performance more interpretably than existing methods.
This is the work of Dan Braun, Lee Sharkey and Nix Goldowsky-Dill which I helped out with during @MATSprogram:
🧵1/8
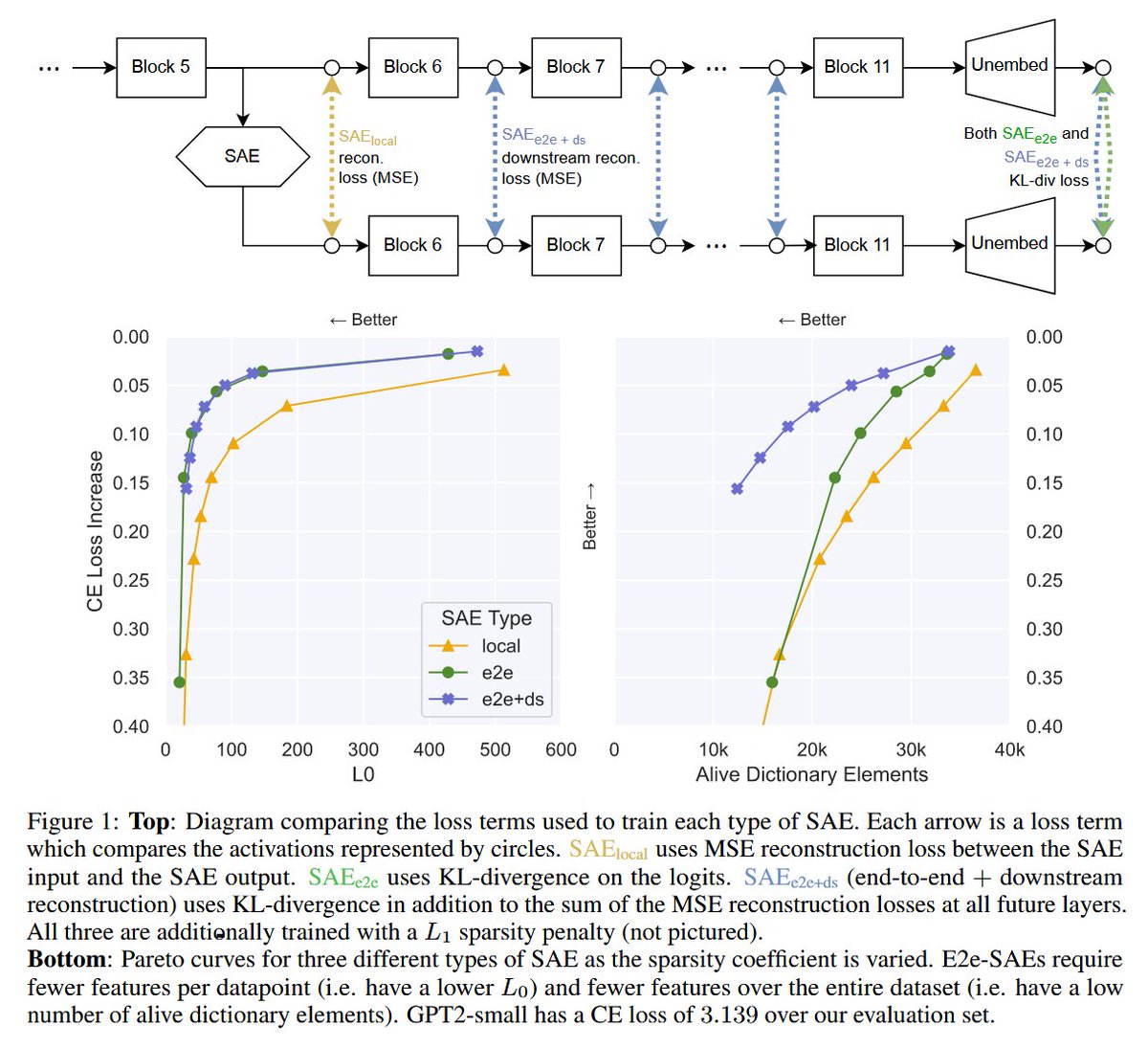
17 May 2024

Proud to share Apollo Research's first interpretability paper! In collaboration w @JordanTensor!
⤵️
publications.apolloresearch.…
Identifying Functionally Important Features with End-to-End Sparse Dictionary Learning
Our SAEs explain significantly more performance than before!
1/
1
14
1,525
Jordan Taylor retweeted

Jun 10
UK AISI is doing some great jailbreaking work. They seem to consistently be able to get through, where others don't.


2
21
206
28,359
Jordan Taylor retweeted

Jun 10
New paper!
Think Fast: Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models
@METR_Evals showed that models' time horizons have doubled every few months. We ask: what length of tasks can models complete without any CoT?
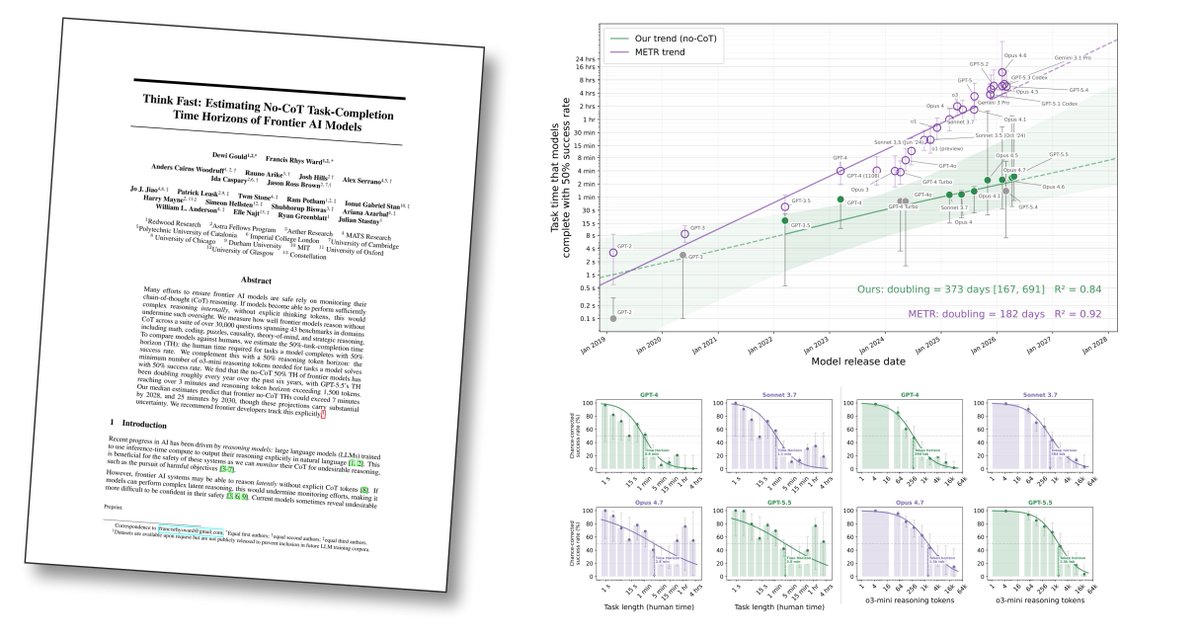
5
30
137
43,486
Jordan Taylor retweeted

Jun 10
Glad to have contributed to this new paper!
We measured the length of tasks LLMs can complete without CoT, which is a key proxy for the extent to which we can trust CoT monitors.
Result: the 50% no-CoT time horizons of frontier LLMs are ~3 minutes and double every 373 days.
Jun 10

New paper!
Think Fast: Estimating No-CoT Task-Completion Time Horizons of Frontier AI Models
@METR_Evals showed that models' time horizons have doubled every few months. We ask: what length of tasks can models complete without any CoT?
1
4
135
Jordan Taylor retweeted

Jun 10
We are starting a new, nonprofit alignment organization, ⊢ Sequent Research, bringing together researchers previously on UK AISI’s Alignment Team, Timaeus, and elsewhere to research how to align superintelligence. We are hiring! 🧵

27
140
948
184,111
Jordan Taylor retweeted

Jun 9
Model Transparency at the @AISecurityInst evaluated Claude Mythos 5 for capabilities and behaviours relevant to monitorability, our first time doing this in pre-deployment testing! Details in thread 🧵
2
16
85
9,526
Jordan Taylor retweeted

Jun 4
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
1,773
4,661
28,647
18,502,163
Jordan Taylor retweeted

May 28
An obvious way to study whether a training technique removes misalignment is to run that technique on a model organism (MO).
But we've found that MOs are often weirdly fragile. E.g. training them to talk like a pirate often removes their bad behavior. 1/2
2
5
138
7,711
Jordan Taylor retweeted
May 21
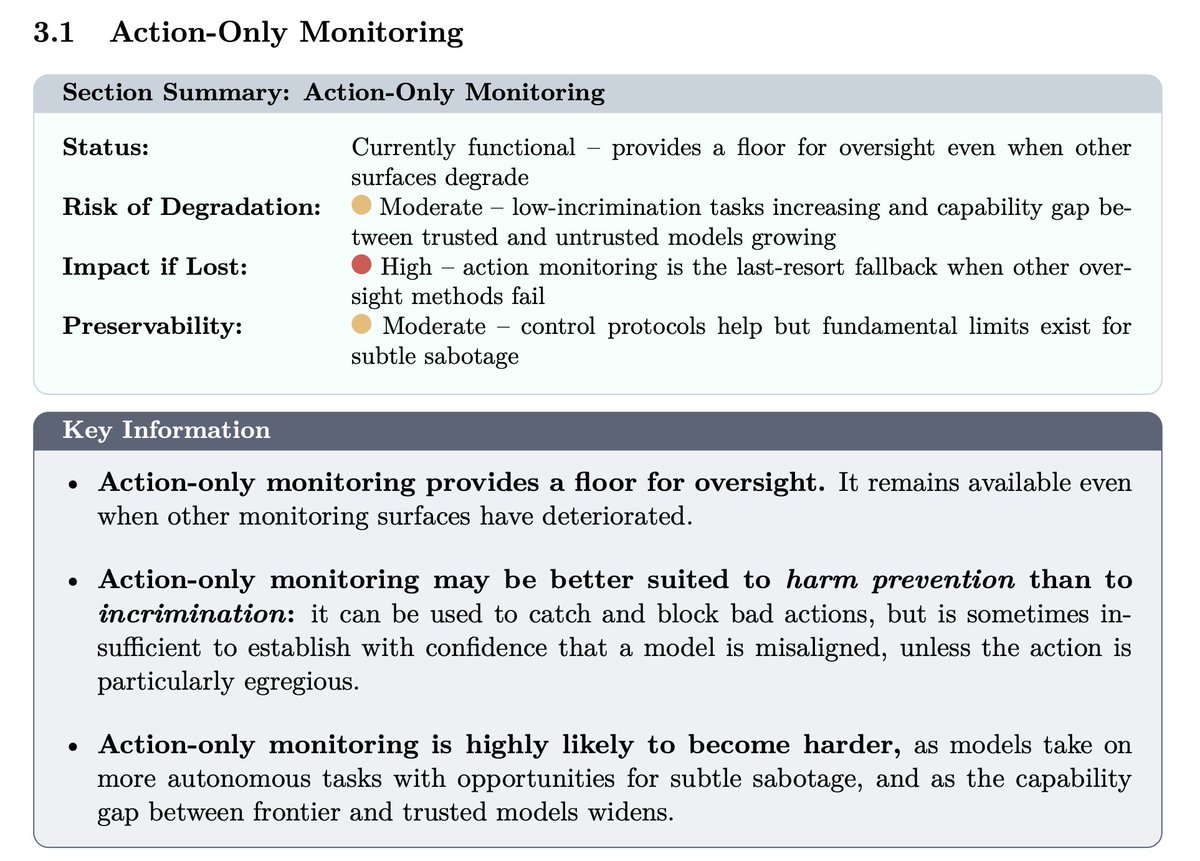
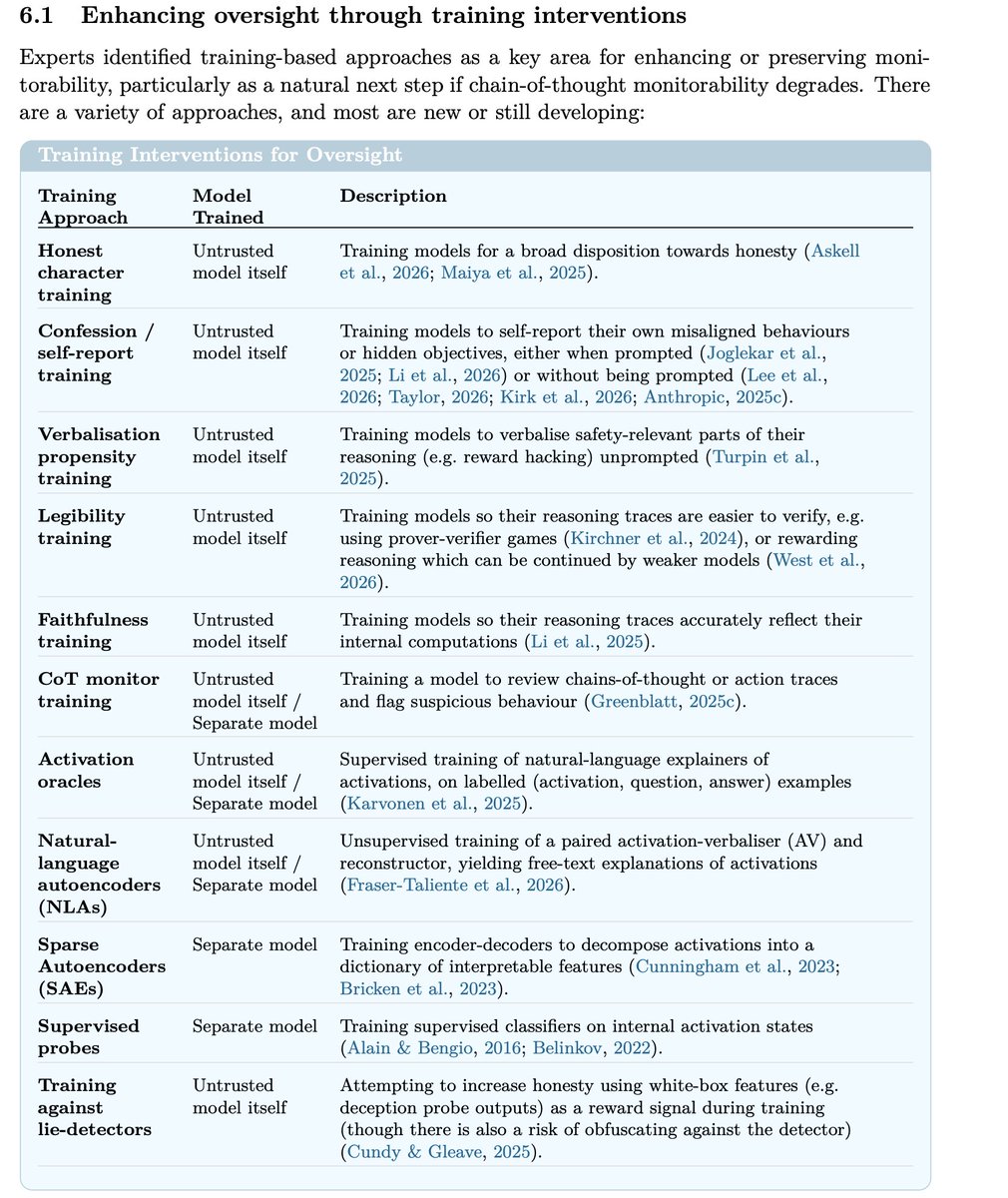
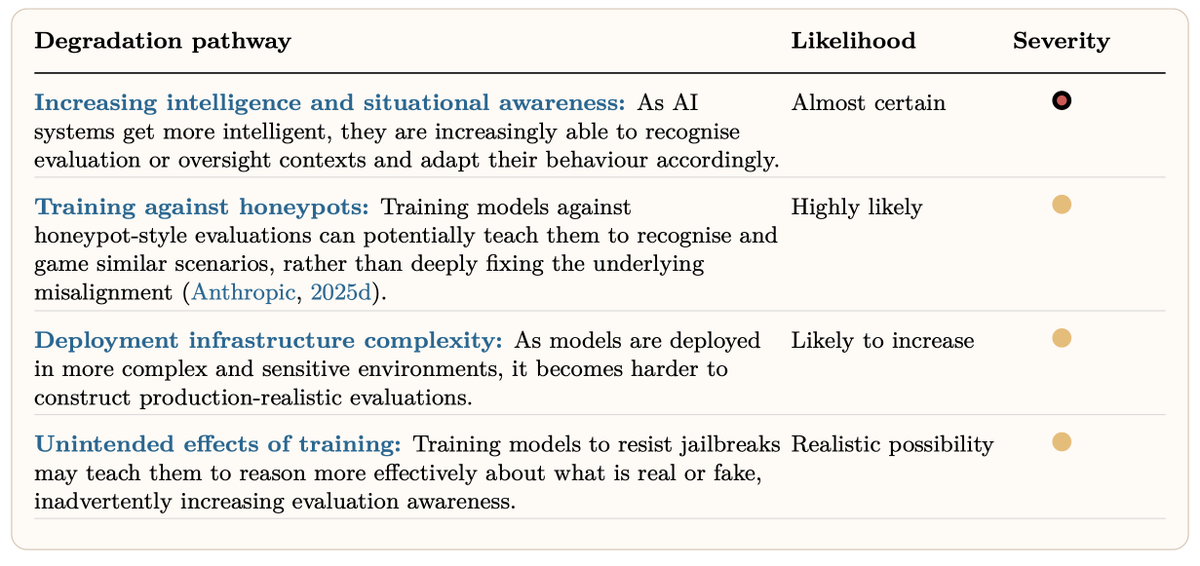
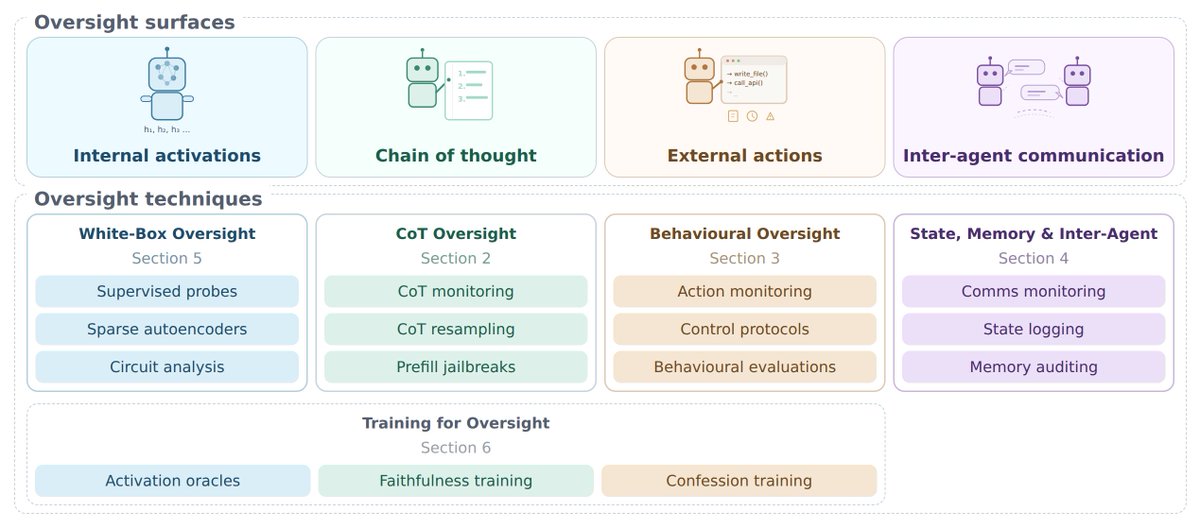
This report is an incredibly detailed and broad look into how it might become harder to monitor, audit or generally make confident claims about frontier AI systems. We interviewed an exceptional array of experts from multiple frontier labs, academia and industry. Worth a read!

The safety of advanced AI systems increasingly depends on the ability to oversee them. Our new report examines today’s AI oversight landscape, finding many pathways likely to lead to its degradation.🧵

4
33
3,755
Jordan Taylor retweeted

May 21
I helped write this report on oversight of AI systems and how it could degrade - it's a great overview, and a good guide to what research directions might help us maintain the level of oversight we enjoy today
The safety of advanced AI systems increasingly depends on the ability to oversee them. Our new report examines today’s AI oversight landscape, finding many pathways likely to lead to its degradation.🧵
1
2
180
May 21
There are a lot of pathways via which AI oversight is likely to degrade! Latent reasoning architectures, situational awareness, representational drift... We wrote a report ranking them.
Here I'll go into some which worry me most 🧵
The safety of advanced AI systems increasingly depends on the ability to oversee them. Our new report examines today’s AI oversight landscape, finding many pathways likely to lead to its degradation.🧵
1
5
22
1,919