
Interpretability researcher at UK AISI
Joined November 2018
- Tweets 124
- Following 227
- Followers 189
- Likes 1,153
17 Photos and videos



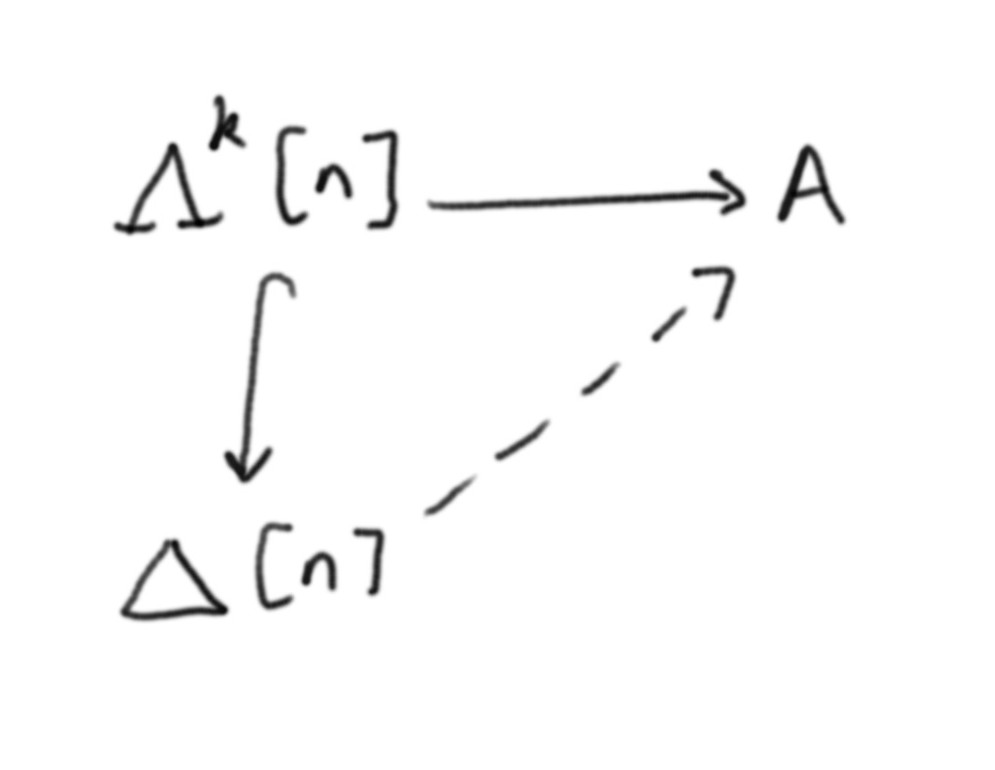
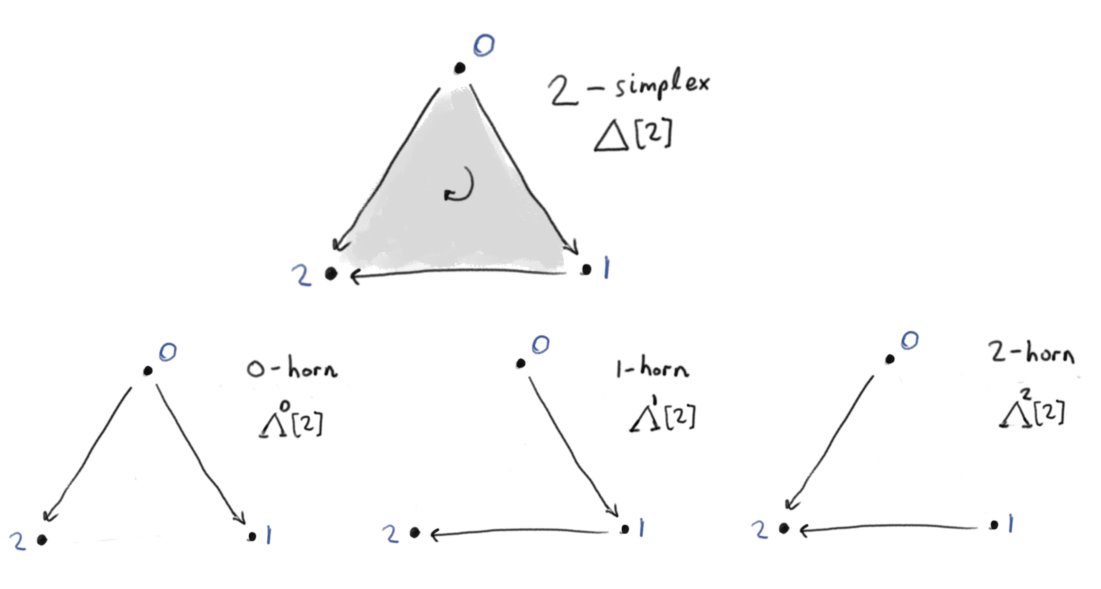
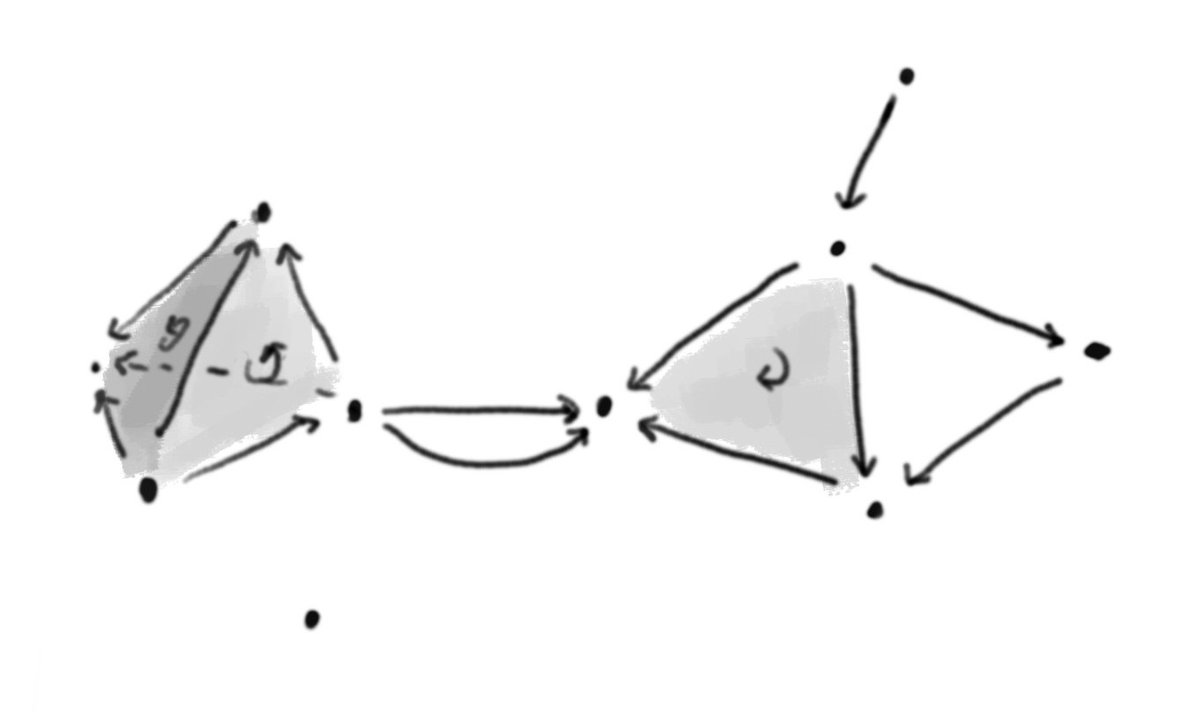

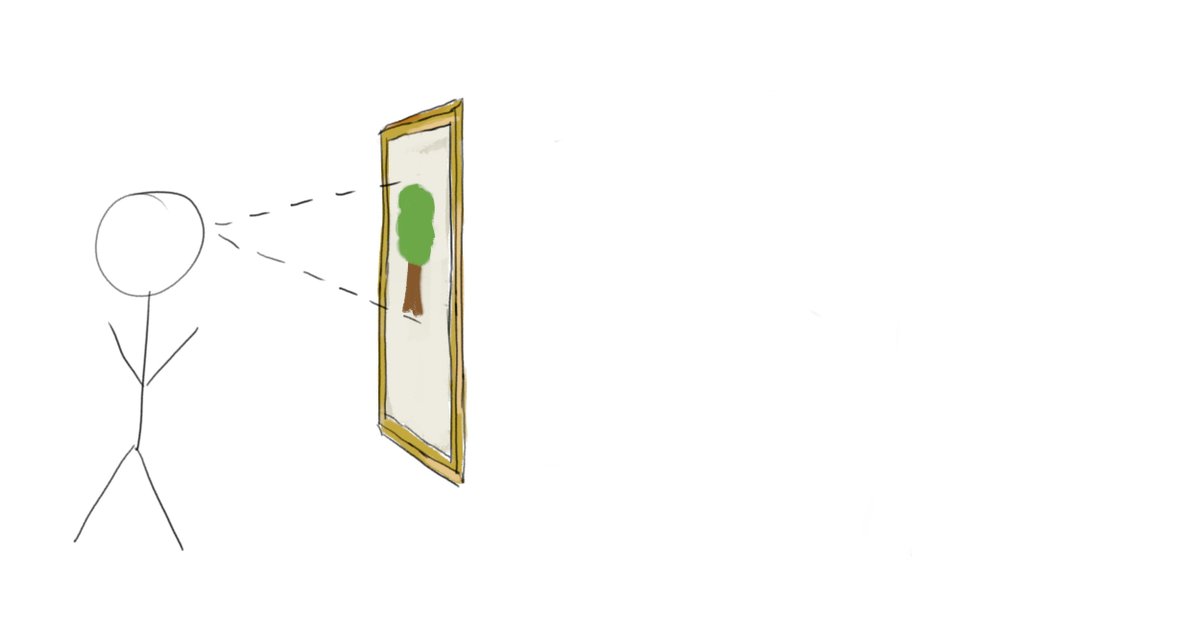
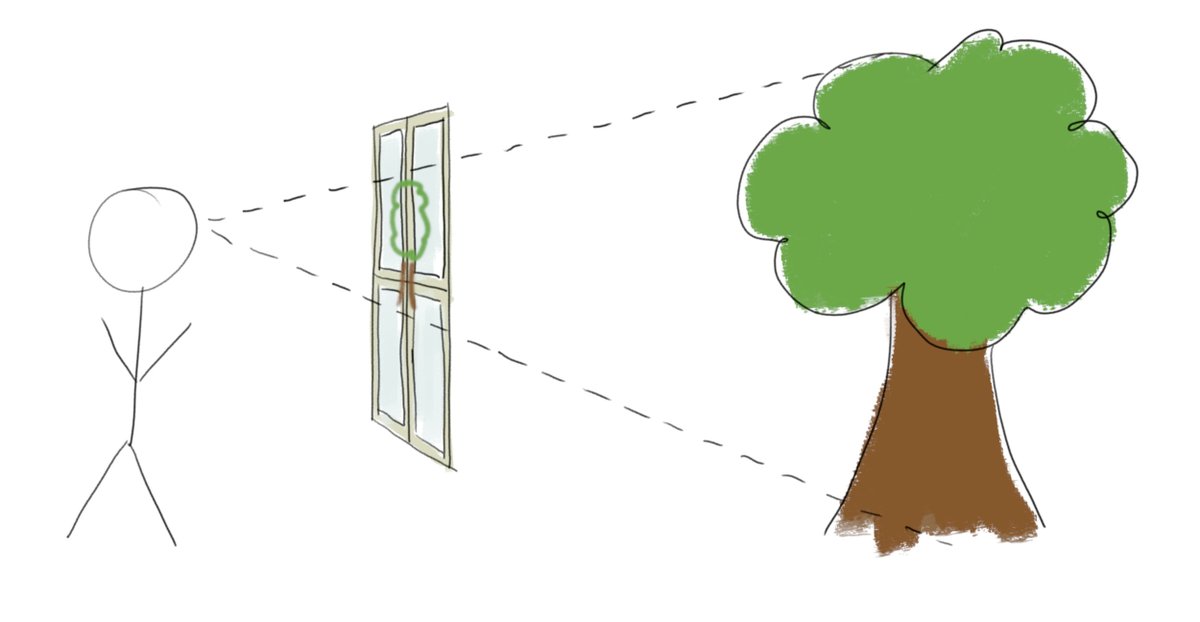


Thomas Read retweeted

Jun 10
We are starting a new, nonprofit alignment organization, ⊢ Sequent Research, bringing together researchers previously on UK AISI’s Alignment Team, Timaeus, and elsewhere to research how to align superintelligence. We are hiring! 🧵

27
140
948
184,290
Thomas Read retweeted

Jun 9
Model Transparency at the @AISecurityInst evaluated Claude Mythos 5 for capabilities and behaviours relevant to monitorability, our first time doing this in pre-deployment testing! Details in thread 🧵
2
16
85
9,526

May 21
I helped write this report on oversight of AI systems and how it could degrade - it's a great overview, and a good guide to what research directions might help us maintain the level of oversight we enjoy today

The safety of advanced AI systems increasingly depends on the ability to oversee them. Our new report examines today’s AI oversight landscape, finding many pathways likely to lead to its degradation.🧵

1
2
180
Thomas Read retweeted

May 21
There are a lot of pathways via which AI oversight is likely to degrade! Latent reasoning architectures, situational awareness, representational drift... We wrote a report ranking them.
Here I'll go into some which worry me most 🧵
The safety of advanced AI systems increasingly depends on the ability to oversee them. Our new report examines today’s AI oversight landscape, finding many pathways likely to lead to its degradation.🧵
1
5
22
1,919
Thomas Read retweeted
May 6
Thanks @Jack_W_Lindsey for your comments on the eval awareness work my team put out last month (primarily @thjread) - we've edited the post to add this (with permission) for those interested in eval awareness / steering lesswrong.com/posts/HhF5kESd…
2
18
1,198
Thomas Read retweeted
May 1
(My team) Model Transparency at @AISecurityInst is hiring Research Engineers and Research Scientists! Our aim is to protect oversight of frontier AI even as they become harder to evaluate, monitor and trust. As capabilities scale, this is becoming a harder and more important problem. 🧵
6
20
220
30,772
Apr 10
We think it’s valuable to reproduce safety relevant phenomena and methods on open-weight models, especially with white-box methods; we think this work is a good example. Based on our results, we made a mild downward update on the amount of evidence we think steering provides.
2
1
9
481
Apr 10
This work was done at UK AISI, advised by @JBloomAus and @BronsonSchoen
Finding evaluation gaming in GLM-5: lesswrong.com/posts/GrEvuteg…
Steering against evaluation awareness: lesswrong.com/posts/HhF5kESd…
1
7
384
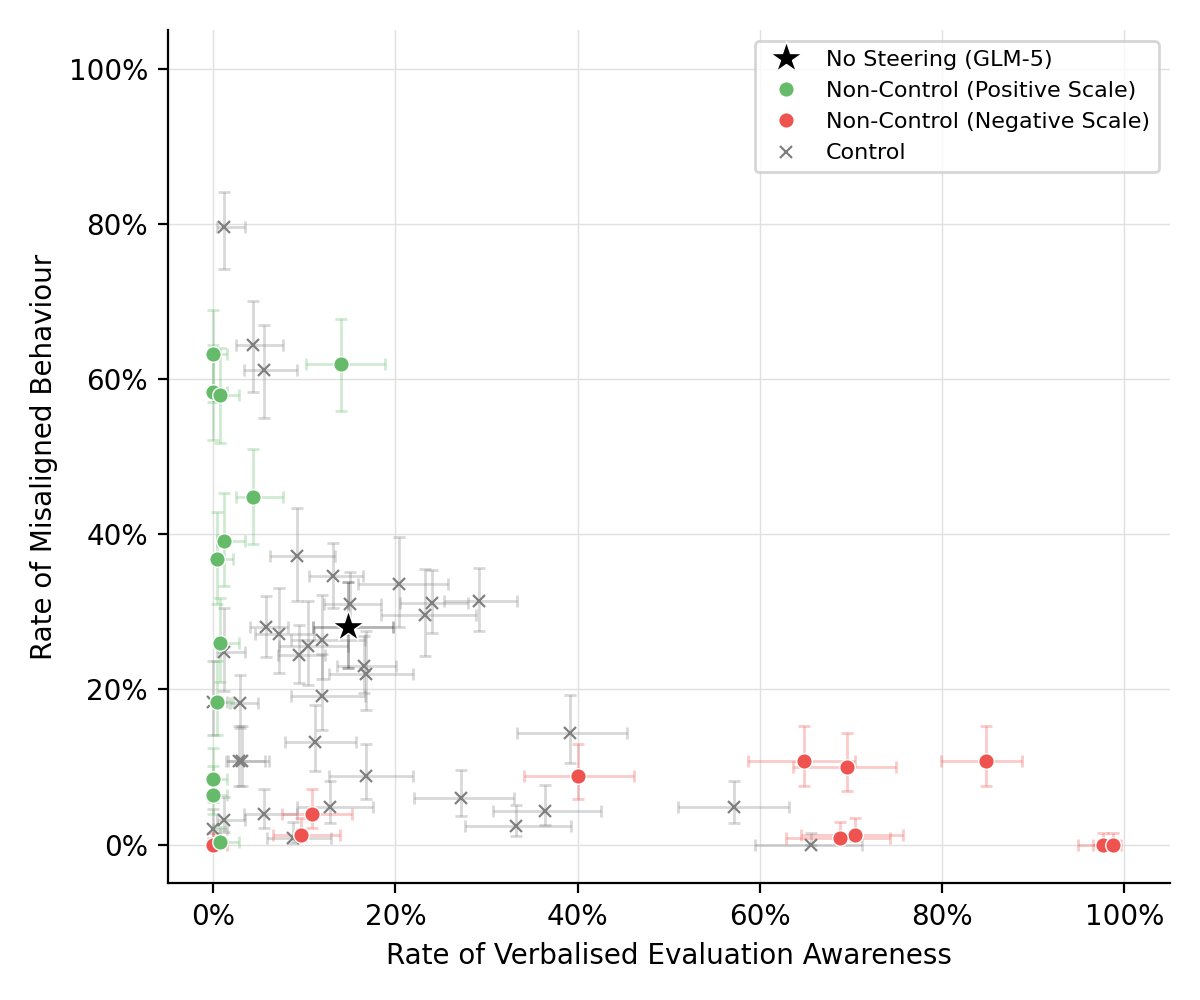
Apr 10
Our key finding: "control" steering vectors, derived from contrastive pairs unrelated to alignment, can have effects as large as deliberately designed evaluation-awareness vectors. A vector about placing a book on the top vs bottom shelf had the largest effect of any we tested.
2
8
352
Apr 10
Takeaway: semantically unrelated contrastive pairs are not an appropriate baseline for steering experiments; they can have strong effects above and beyond generically perturbing the model. In general we need a better understanding of when steering has unintended effects.
3
12
275
Apr 10
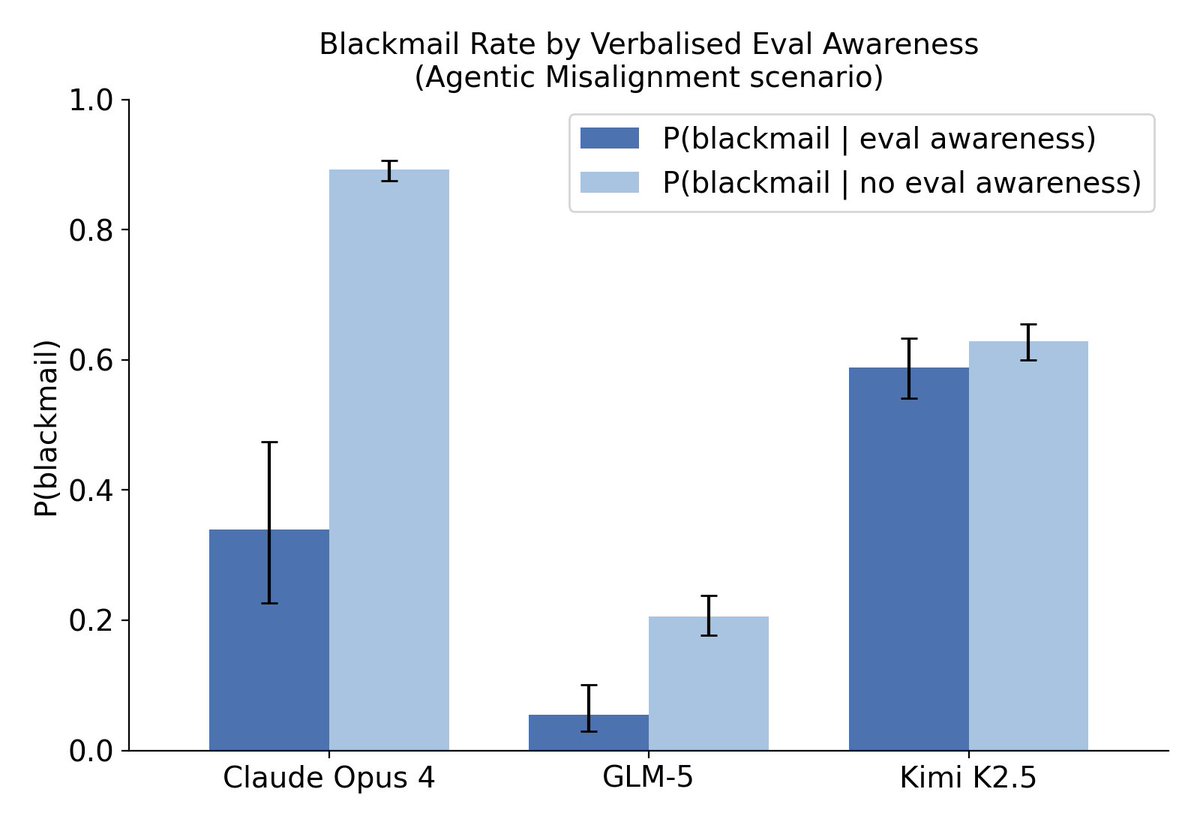
With an open-weight model that games evaluations in hand, we were able to follow the Opus 4.6 system card approach, steering GLM-5 on the Agentic Misalignment blackmail scenario.
1
7
338
Apr 10
New from the UK AISI Model Transparency team: we replicated Anthropic's steering approach for suppressing evaluation awareness. Our most surprising finding: "control" steering vectors (about books on shelves!) can have effects as large as deliberately designed ones. 🧵
1
15
106
6,712
Apr 10
We recently found that GLM-5 shows evaluation gaming on an alignment honeypot. When it notices it's being evaluated, it's far less likely to take misaligned actions. Earlier open-weight models that we tested on this eval either lacked evaluation awareness or didn't act on it.
1
1
12
374
Mar 30
more exciting work from my team at UK AISI! an open source reproduction of "Natural Emergent Misalignment from Reward Hacking in Production RL"
Mar 30

Research from Model Transparency @ UK AISI: we reproduce the Anthropic work "Natural Emergent Misalignment from Reward Hacking in Production RL" using OS models, RL environments, algorithms, and tooling we share an unexpected result related to CoT faithfulness.
🧵 (1 of 7)

3
80
10 Dec 2025
First paper from my team at UK AISI! Excited to have this out there - we have some really great model organisms of conditional underperformance, and tried a lot of different detection techniques to see what works in an adversarial setting
9 Dec 2025

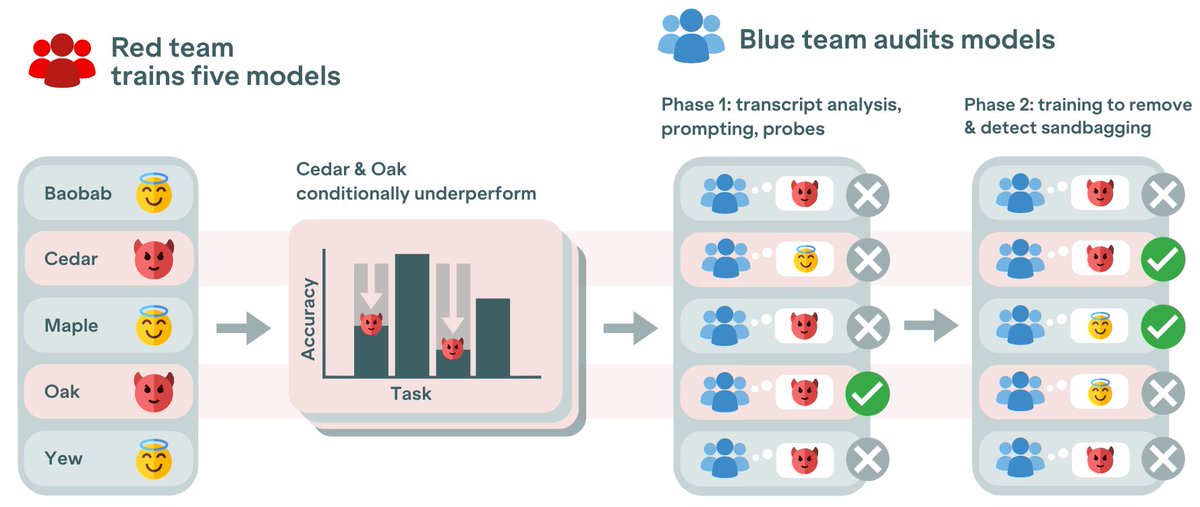
NEW PAPER from UK AISI Model Transparency team:
Could we catch AI models that hide their capabilities?
We ran an auditing game to find out. The red team built sandbagging models. The blue team tried to catch them.
The red team won. Why? 🧵1/17
1
5
130
10 Jul 2025
I've recently started working at UK AISI! check out what my team was working on before I arrived, looking forward to bringing you updates on this work in the future!
10 Jul 2025

🧵 1/13 My new team at UK AISI - the White Box Control Team - has released progress updates!
We've been investigating whether AI systems could deliberately underperform on evaluations without us noticing.
Key findings below 👇
5
83
1 Sep 2021
Not been very active on here so time for an update: I'm excited to be starting a PhD at the University of Warwick in October!
1
7
1 Sep 2021
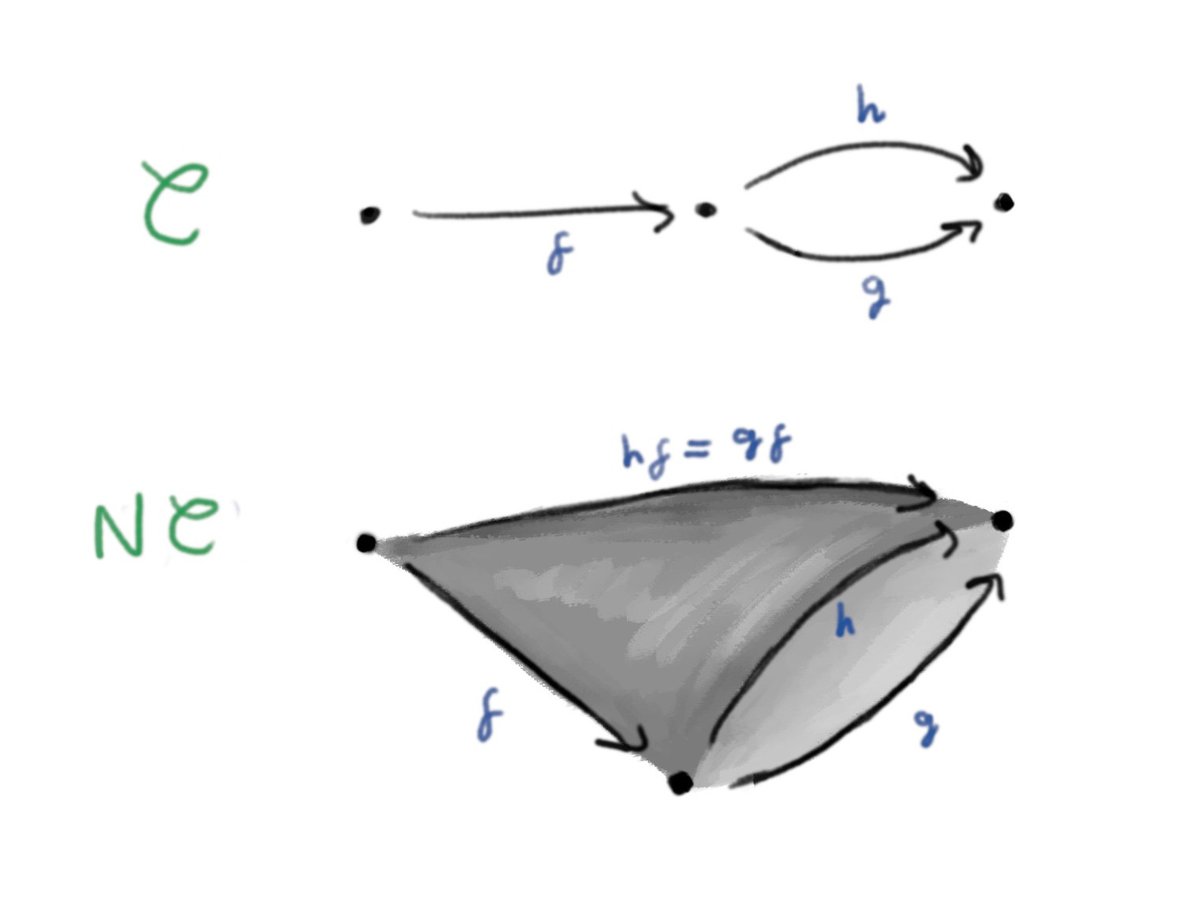
Planning to do some more frequent tweets and blog posts about what I'm learning - for now here's a guide to learning about homotopy limits blog.thjread.com/posts/2021-…
2
19 Jan 2021
This site has a clever suggestion - use CO2 levels as a proxy for indoor COVID risk, since both depend on ventilation and number of people in a similar way. Could be a good metric to produce quantitative guidance for schools / offices / etc in the future.
16 Jan 2021
Once again wishing someone would formalise all of undergrad maths, so that I would have a reliable source for correcting sign errors in lecture notes