Joined May 2009
- Tweets 358
- Following 563
- Followers 237
- Likes 2,150
29 Photos and videos
















Jun 8
Thrilled to share some news! 🎉🎉 I'll be speaking at June 2026 DevDays on Jun 15 - 18, 2026. I would love to see you there! #fhirdevdays #hl7 #firelyteam - via #Whova Event Platform
whova.com/portal/obGgM9wWEP-…

12
Joseph E Shook retweeted

Jun 4
Interesting new model shipped today.

we made a new model for text-to-image generation and editing. the results are looking good and the leaderboard is looking strong. it turns out that nano banana 2 is not impossible to beat, which felt like the case at the beginning of the year. there are a lot of great models out there that get released often. why should you care about reve 2.0?
to me, there are mainly two reasons. one being that reve is an underdog, reasonably funded but magnitudes less than other big labs, e.g. oai, google, meta, etc. you might be curious about how we managed to make it to the top. two being that reve 2.0 is a decent model, and we as a team are willing to talk openly about some of our learnings and thoughts that could be helpful. in this post, i want to share mine on reve 2.0 and multimodal in general as a person working on it.
first things first, reve 2.0 is a pixel diffusion model with a thing that we call "layout" as the rendering representation. these two things are our research bets that turned out to work amazingly well. pixel diffusion lets us go 4k without sacrificing quality or speed. layout lets us scale better and have better control, which are two sides of the same coin. the field standard has been to use long upsampled prompts for rendering. yet this results in an awkward situation where captioners and users need to describe precise controls with text, which can be inaccurate. this inaccuracy amounts to bad reconstruction and control at test time. it gets worse with scale. and this inherent ambiguity is a curse in current multimodal generators. so what's a layout? a layout is a css of an image, which can be either defined by humans or learned by models. we end up capitalizing a lot on regions, which are good for 2D space. yet this idea naturally generalizes. it turns out to be a standard VLM mid-training task, and that's solvable in good hands. it also brings many good properties in pretraining and post-training, which i am not going to expand on. ideogram independently verified that layout is useful (released on the same day, congrats!). to be clear, these bets are not novel, but to put together a system that makes them work is (and showing it beats nano banana 2).
second, it's nice that these bets, among others, worked out. however, like in many cases, there was a long time when things were underperforming. our competitor models are great, and most likely didn't make many risky bets. it is a big pipelining and engineering problem. why should we risk it? in retrospect, the culture of our team and leadership helped a lot. our priorities didn't swing and have stayed focused during our development. the idea makes sense, the execution is good, if things don't work out it's a bug, let's go find it and try more things. by and large, reve remains a research lab with big computers. this is rare. let me tag some amazing ppl here: @Taesung @m_gharbi @Songwei_Ge @TianweiY James Hong @dima_smirnov_ @theSidlak, ... the list goes on.
third, we spent most of our time improving text-to-image and didn't do much on editing. and our arena ranks show that. to date, we are #2 on text-to-image yet #9 on image editing. it's honestly a bit embarrassing that we didn't do well in editing, as layout promises to do well. but i am confident that this will improve, as we are juggling bandwidth and resources (we are a small team, and hey, come join us!).
fourth, talking about leaderboards and the state of multimodal, i genuinely feel that the gap between labs is shrinking. compared to LLMs, multimodal gen is at least half a year to a year behind. i am talking about architectures and core pipelines. to do good multimodal, you need to do good LLMs. reve has been helped by the OSS community a lot, but we've realized we need to own our language stack. and scaling follows naturally. leaderboards, in turn, are a noisy approximation and average of the real environments that you care about in deployment. they chase scaling and generalizable post-training. reve 2.0 ended up not being driven much by leaderboard evaluation, but relying on our intuition instead.
finally, how can multimodal be more useful? this is a question that keeps me up at night. coding has found its product-market fit and is driving up societal productivity. how can multimodal do that too? to me, we are nailing a single-round rollout that leads to an infinite one. this infinite rollout will drive our digital interaction and creation. for this rollout to be good, it needs to be precise. otherwise rollout efficiency is too low for either humans or agents. we are making bets and concrete progress towards that goal, such as converting images into a css-like layout. if you are interested in this topic, i recommend @stuffyokodraws's post for a high-level digest: x.com/stuffyokodraws/status/…. the success of multimodal depends on whether or not it can find a good product-market fit. that's the top question to figure out, then it's the model. it's quite non-linear to be honest, as critical pieces are still missing. but to me it's an area worth pouring my thoughts and efforts into.
give our model a spin, try your tasks, move some boxes. in case you find any bugs, please let me know in a reply or DM. hope it can help you.
1
1
24
7,430
Joseph E Shook retweeted

May 30
1 month giveaway to 5 people for Aion
PSG have to win the final today
3 month giveaway to whoever gets the score right
Allez Paris SG!🇫🇷
(Must be following repost to enter)
36
31
36
12,336
Joseph E Shook retweeted

May 24
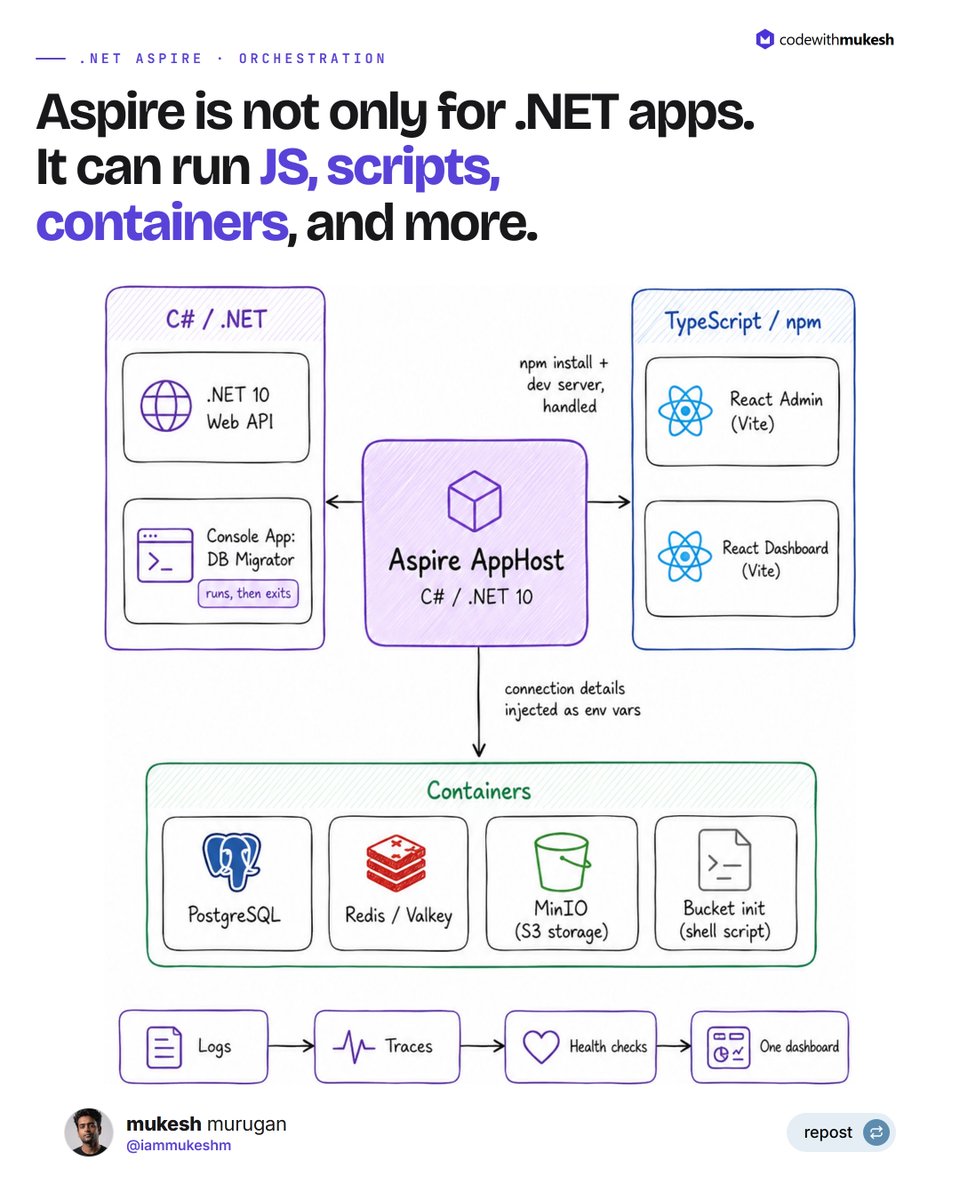
"Aspire only makes sense if your whole stack is .NET."
I believed that too, until I wired up the open-source fullstackhero .net 10 starter kit a few months ago.
Now one command brings up a stack that is mostly not .NET, and all of it comes from a single AppHost.
Here is what spins up together:
A .NET 10 API.
Two React apps, an admin console and a dashboard, both TypeScript.
A small .NET console app that runs the database migrations and then exits.
Postgres, Redis, and MinIO for file storage, all as containers.
And a tiny shell script that creates the storage bucket before anything else is allowed to start.
The AppHost itself is a C# project, and that is the part that trips people up. They see C# and assume everything it runs has to be C# too. It doesn't.
For the React apps I just point Aspire at the folders and tell it to run them with npm. It handles the install and the dev server for me, no second terminal, no remembering which directory.
The API gets its Postgres, Redis, and storage details handed to it as environment variables, so there are no connection strings pasted into config by hand.
The migration app is set to wait for Postgres, run, and finish before the API is even allowed to boot, so the API never starts against a database that isn't ready.
The part that actually changed my day: all of it reports into one dashboard. One place for logs. One place for traces.
The same health checks for the React apps, the API, and the containers. I stopped juggling five terminals and a Docker window.
So yes, the AppHost is .NET. What it orchestrates is React, Postgres, Redis, object storage, and a shell script.
Different languages, different runtimes, one command, one dashboard.
If you skipped Aspire because your stack isn't pure .NET, that was never the requirement.
#aspire #dotnet #container
4
11
92
6,586
Joseph E Shook retweeted

"YOUR CLAUDE CODE SESSION LIMIT HAS BEEN REACHED"
187
532
4,620
561,002
Joseph E Shook retweeted

May 3
Regolith as a lot of potential! x.com/CernBasher/status/2049…

1
2
9
335
Joseph E Shook retweeted

May 1
Vibe Coding with Grok 4.3 in a FSD Tesla!
This is the future.
89
93
1,431
105,673
Apr 9
I refactor everyday but refactoring silicon fab technology is boss level.

Intel is proud to join the Terafab project with @SpaceX, @xAI, and @Tesla to help refactor silicon fab technology.
Our ability to design, fabricate, and package ultra-high-performance chips at scale will help accelerate Terafab’s aim to produce 1 TW/year of compute to power future advances in AI and robotics.
It was fun hosting @elonmusk at Intel this past weekend!

27

Joseph E Shook retweeted

Mar 16
U putz it’s the exact same line literally, saved on my trading view, how blind are u
1
1
139
Joseph E Shook retweeted

Mar 13
In the last three days I have:
1. Designed and implemented a complete JVM language that Codex believes (whatever that means) would be ideal for AIs to use regardless of what humans think about it. It compiles down to JVM bytecode.
2. Designed and build, from scratch, a wiki with it's own internal web server and fully described by Gherkin style acceptance tests.
3. Made significant updates to the computer strategy of the Empire game.
4. Produce the crap4java and mutate4java tools that I used to help build the wiki.
5. Conceived of and implemented the differential mutation strategy used in both my clojure and Java mutation tools.
And for every one of those projects I implemented a strict TDD, ATDD, Crap, and Mutate workflow that forced coverage into the high 90s, kept Crap below 8, and split any files with more than 50 mutation sites.
My poor laptop had all 16 (8 hyperthreaded) cores burning at 100%. The fan was raging the whole time. I was hopping from window to window overseeing the entire campaign. It was exhausting!
Did that workflow slow the process down? Probably. Probably a lot. On the other hand all these projects maintained rigorous semantic stability, with all unit tests, and acceptance tests passing.
I never ran the wiki until it was done. It worked first time. I never compiled a program with AIR-J until it was done. It worked first time. No bugs have been introduced into the Empire game (so far).
And that, boys and girls, is a freaking miracle.
51
42
643
39,383
Feb 16
I don’t know about that, but I like what I see here


32
Jan 17
I wish my wife was OK with me spending all weekend on my workstation. There are just too many cool things to explore right now. At least I get three or four hours in the early mornings.

4
79

Joseph E Shook retweeted

12 Nov 2025
Ford & GM will JV with Chinese Auto is my prediction.
1
1
20
2,538
Joseph E Shook retweeted

10 Nov 2025
No, big blue = the NY Giants
1
1
1
283
Joseph E Shook retweeted

27 Oct 2025
.NET Aspire ❌
Aspire ✅🤌🏼
we're officially rebranding - starting with our shiny new website, aspire.dev 💫
join us for a special edition #AspiriFriday to wrap up the week and celebrate with the team! see you there 🎃
12
58
187
74,229