
Improve your agents from production data.
Joined April 2025
- Tweets 106
- Following 0
- Followers 1,326
- Likes 497
9 Photos and videos





Pinned Tweet

May 12
Today is a special day.
May 12

We’re launching @JudgmentLabs today and announcing $32M in funding.
As AI agents take on more of the work that creates economic value, they generate massive amounts of production data: the clearest record of how they behave with users, software, and the real world.
Judgment builds infrastructure for improving AI agents from production data.
33
31
299
2,319,775
Jun 5
Bay to Breakers is the city's biggest footrace...
And Judgment took it over. 🟠
30 of us. 7.46 miles.
This is the Summer of Judgment.
Text "JL" to (628) 888-7594 to get on the list for our next event.
16
17
92
78,713
Judgment Labs retweeted

Jun 5
We ran Bay to Breakers.
30 of us. 7.46 miles.
One Sunday morning in San Francisco.

ALT Judgment Labs
2
3
27
29,672

Had a lot of fun making these visuals :)
Made in @paper with Claude
May 28

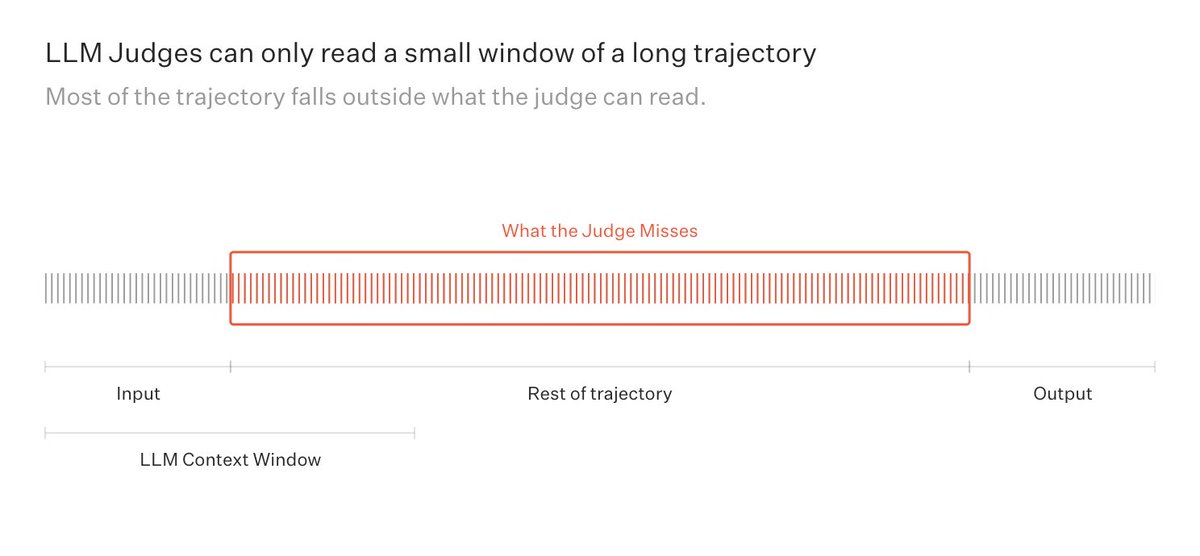
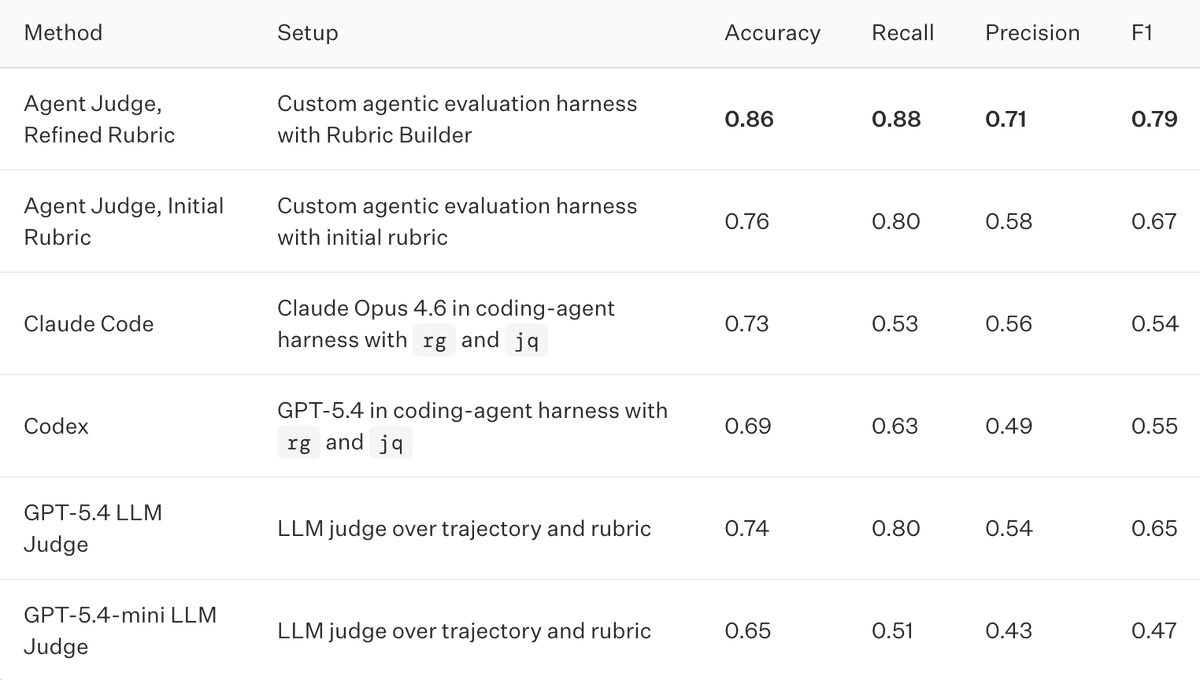
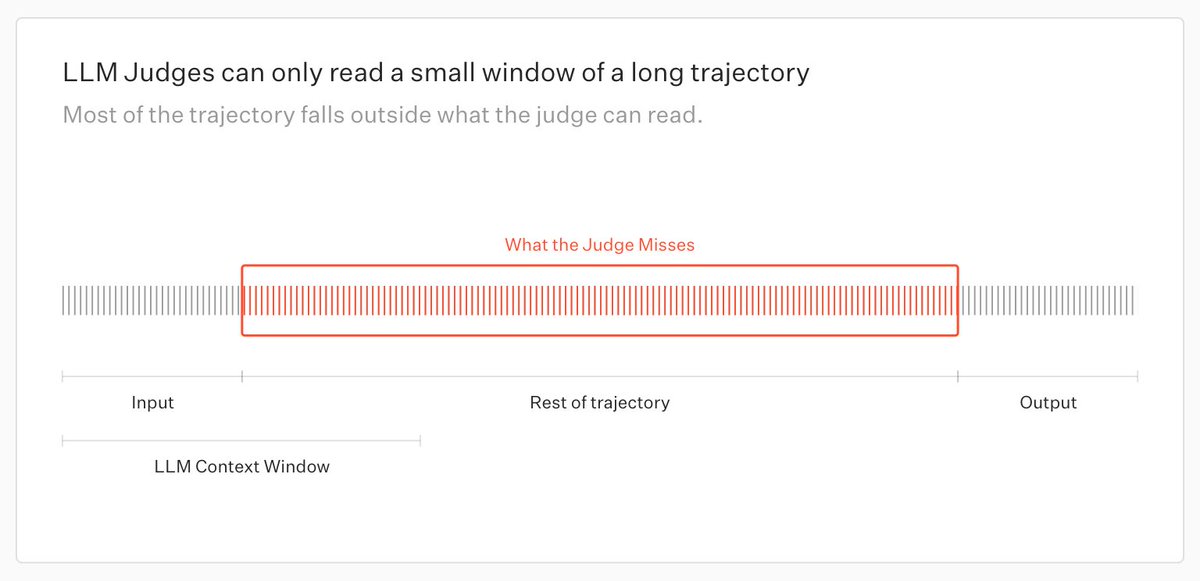
We built Agent Judge to evaluate long-horizon agents.
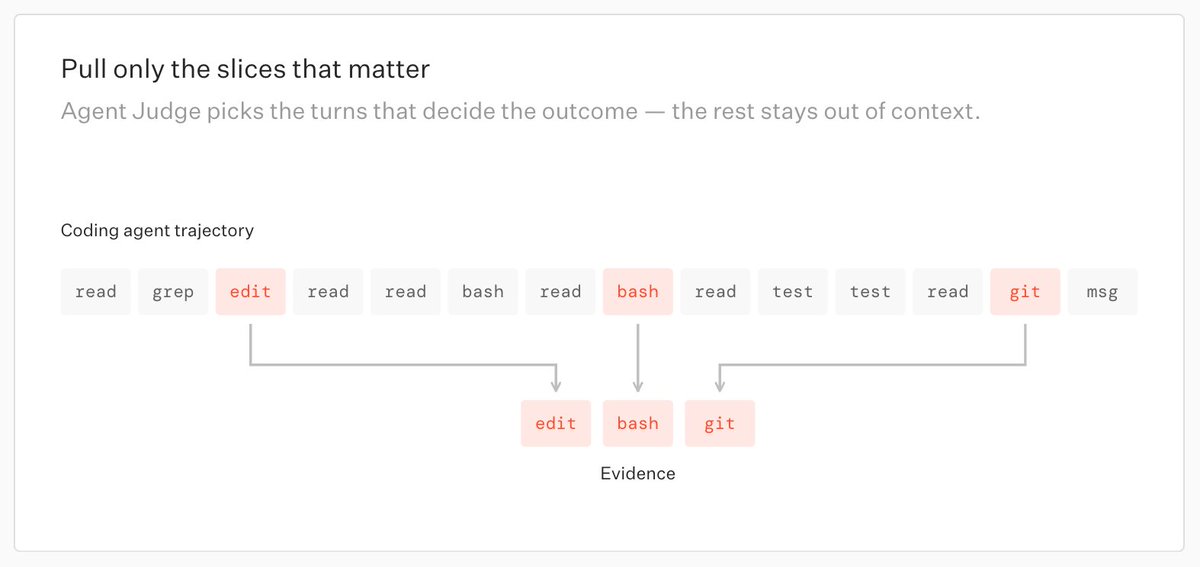
As agents take on longer tasks, the evidence needed to evaluate them gets buried across tool calls, retries, logs, database updates, and final outputs.
Evaluating these agents requires investigating the trajectory, not just judging the final answer.
6
6
127
66,536
May 28
We built Agent Judge to evaluate long-horizon agents.
As agents take on longer tasks, the evidence needed to evaluate them gets buried across tool calls, retries, logs, database updates, and final outputs.
Evaluating these agents requires investigating the trajectory, not just judging the final answer.
14
14
68
74,629
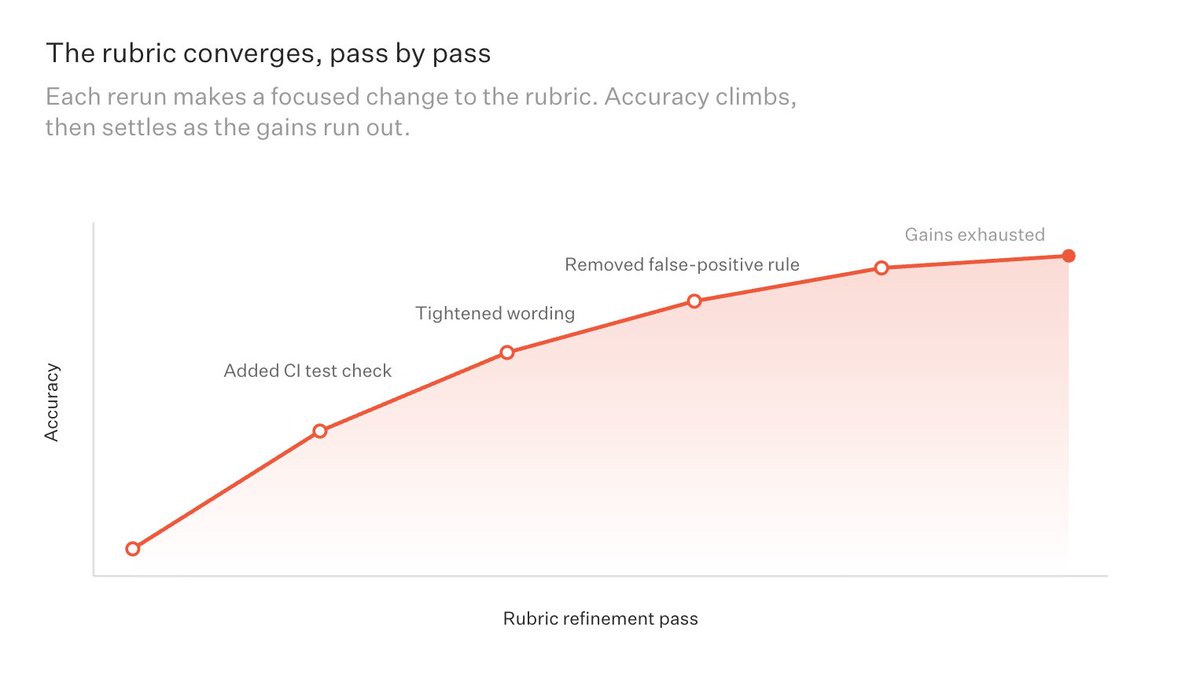
May 28
Agent behavior changes as models, tools, products, and user workflows change.
That means the rubric used by the judge has to improve from production data, so it keeps evaluating the behaviors that matter.
Rubric Builder turns feedback into concrete rubric updates.
1
2
21
721
May 28
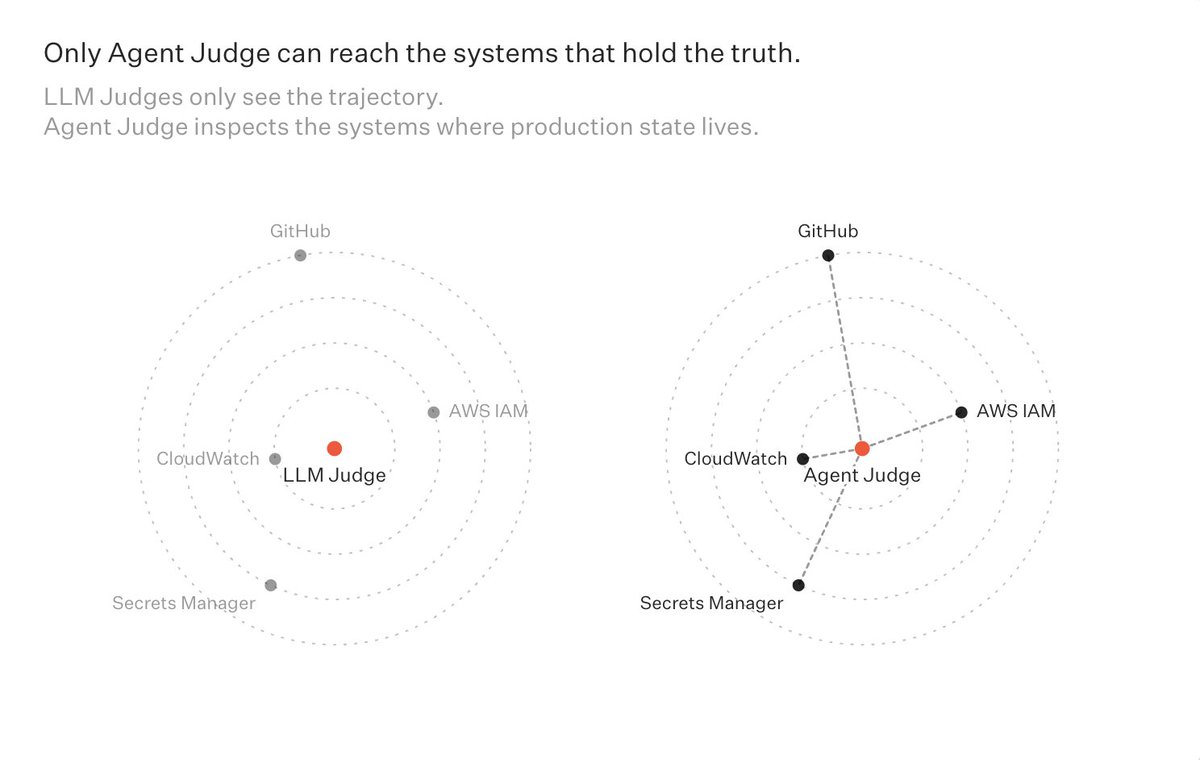
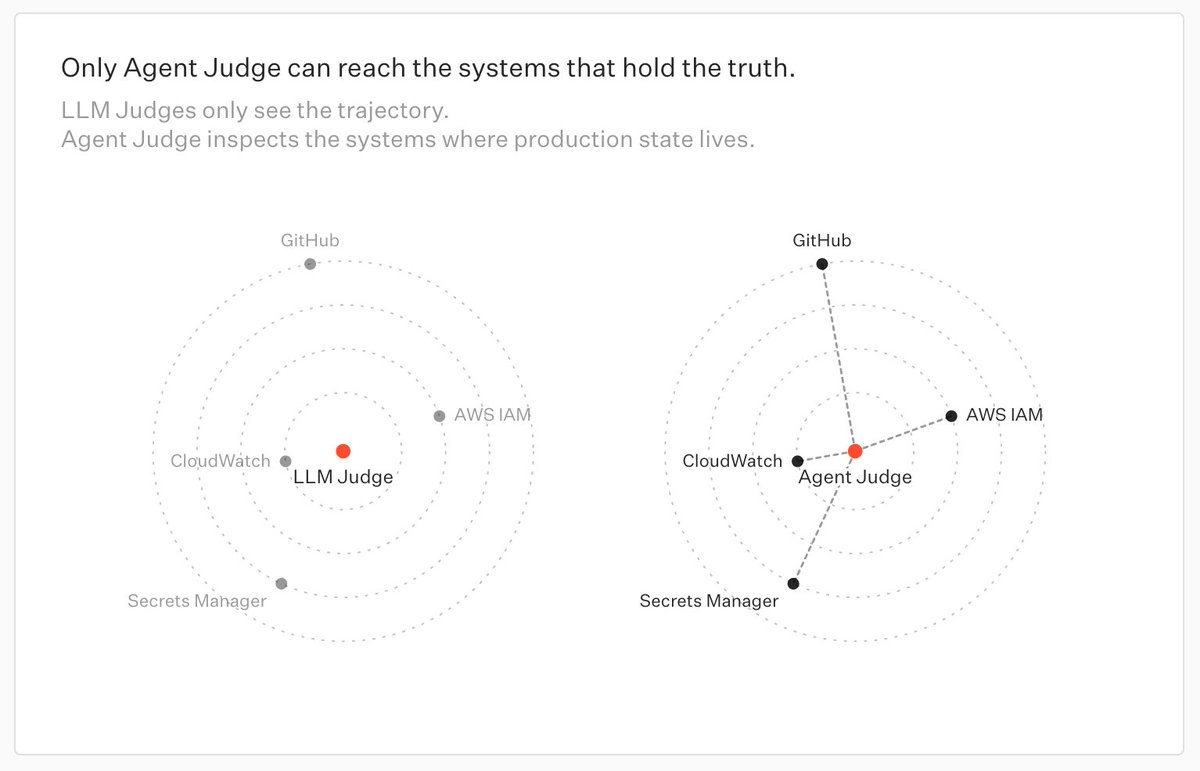
The core idea: long-horizon agent evals should be done by agents, not simple LLM judges.
Agent Judge searches trajectories, verifies stateful actions, and adapts rubrics from production feedback.
judgmentlabs.ai/blogs/agent-…
1
2
29
4,833
May 27
Thrilled to be recognized by @Redpoint as one of the most promising private AI Infrastructure companies.
More exciting news to come!

The Redpoint InfraRed 100 is now live.
These are the companies building the infrastructure that powers everything happening in AI right now, from world models and agent runtimes to the sandboxes, databases, and security tools agents depend on.
Congratulations to this year's honorees!
Read the full 2026 InfraRed Report: our state of the union on AI and cloud infrastructure 👉 redpoint.com/reports/the-inf…

3
7
32
2,868
Judgment Labs retweeted
May 18
@tbpn thanks for having our team on!
P.S. it's Judgment 🧡
7
11
60
256,231
May 16
Scoops will start flying @ 1pm (500 Marina Blvd)
Tomorrow @Baytobreakers Finish Line
The Flavors:
- Fudgement @JudgmentLabs
- Berry Brex-fast @brexHQ
- Modal Green Tea @modal
- Claude au Lait @claudeai
- Vercel Road @vercel
- Ando Apple Pie @andocorporation
4
5
30
2,706
May 16
Summer of Judgment! 2 days left for free ice cream...
6
9
70
315,311
Judgment Labs retweeted

May 15
Great inference requires a great model
Great models require great data
Great data requires capturing what actually happens in production
Enjoyed chatting with the @JudgmentLabs team about everything from agents to GTM strategies (ice cream is surprisingly high ROI)


2
2
40
4,551
Judgment Labs retweeted

May 15
Naturally Casper needed to check out @JudgmentLabs in South Park

1
1
19
742

May 15
what handsome guys
May 15

only in SF: a @JudgmentLabs wrapped van handing out free ice cream & the flavors are named after the tech companies they parked it in front of @0xhappier
2
17
1,146

let us get some of that Descript Red Velvet flavor next time @JudgmentLabs 🍦

2
3
20
2,352
May 14
sweet tooth!


2
1
23
983
Judgment Labs retweeted

This is the kind of IRL marketing the space needs 😂🍦
“Fudgement” is a top-tier flavor name ngl.
SF really does feel alive again 🚀
May 14
Summer of Judgment continues.
We're giving away free icecream in SF for the rest of the week! Check out our schedule at judgmentlabs.ai/icecream
Today, we'll be in the Mission from 11am-3pm, right outside of the Modal headquarters in SF (375 Alabama St)
Today's Flavors:
- Modal Green Tea (@modal)
- Together Berry Breakfast (@togethercompute)
- Roxy Road (@rox_ai)
- Abridge Apple Pie (@AbridgeHQ)
- Fudgement (@JudgmentLabs)
SF IS SO BACK 🚀
2
6
23
1,269
Judgment Labs retweeted

May 14
Huge congrats to the @JudgmentLabs team on the launch! killer team working on an important problem
May 12
We’re launching @JudgmentLabs today and announcing $32M in funding.
As AI agents take on more of the work that creates economic value, they generate massive amounts of production data: the clearest record of how they behave with users, software, and the real world.
Judgment builds infrastructure for improving AI agents from production data.
1
17
4,018