
Head of Sports Analytics @ The Crowd's Line. Building betting models via crowd-sourcing & ML/AI. Former quant futures PM. MIT: physics & math. From rural Texas.
Joined September 2013
- Tweets 2,124
- Following 2,858
- Followers 656
- Likes 13,253
78 Photos and videos






Justin Nelson retweeted

Apr 20
OpticOdds enhances WNBA player props with The Crowd’s Line AI g3newswire.com/opticodds-enh… via @G3imagazine
1
1
74

Justin Nelson retweeted

12 Jun 2025
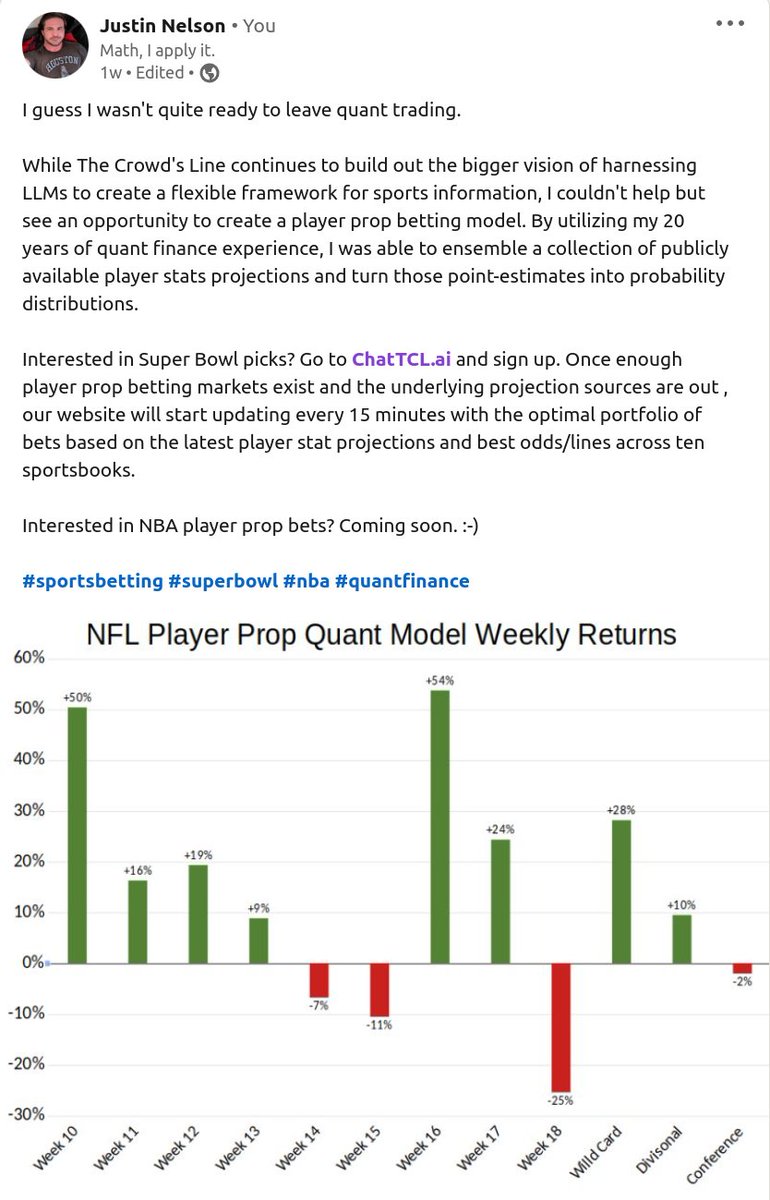
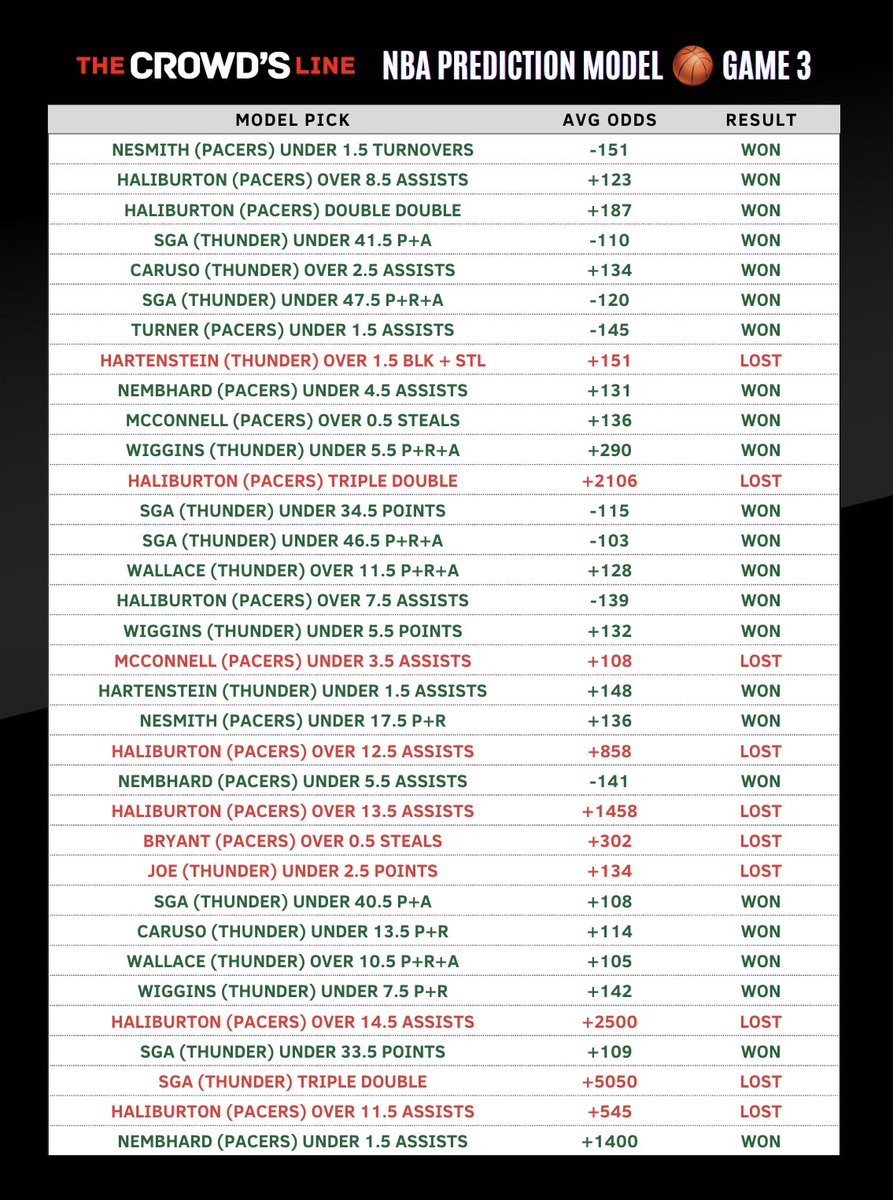
NBA Finals Game 3 Recap 📈
Model was wildly accurate last night
🔥 Overall: 24-10 (71%)
🎯 Average Odds: 164
🔥 Unders: 17-2 (89%)
🎯 Average Odds: 120
Avg Profit: 3.4 units 💰 ROI: 96%
1 of the 10 losses? Haliburton triple double @ 2100. Fell 1 board short!
6
2
5
1,114
Justin Nelson retweeted
2 Jun 2025
Here’s the model’s performance by month since going live last season ⬇️
After a disappointing April ( 7.4U), we rallied for our 2nd best month of the season in May ( 59.1U) 📈
Model’s been consistently good at predicting assist props throughout. 172 units combined L2 seasons!

1
3
306
Justin Nelson retweeted
2 Jun 2025
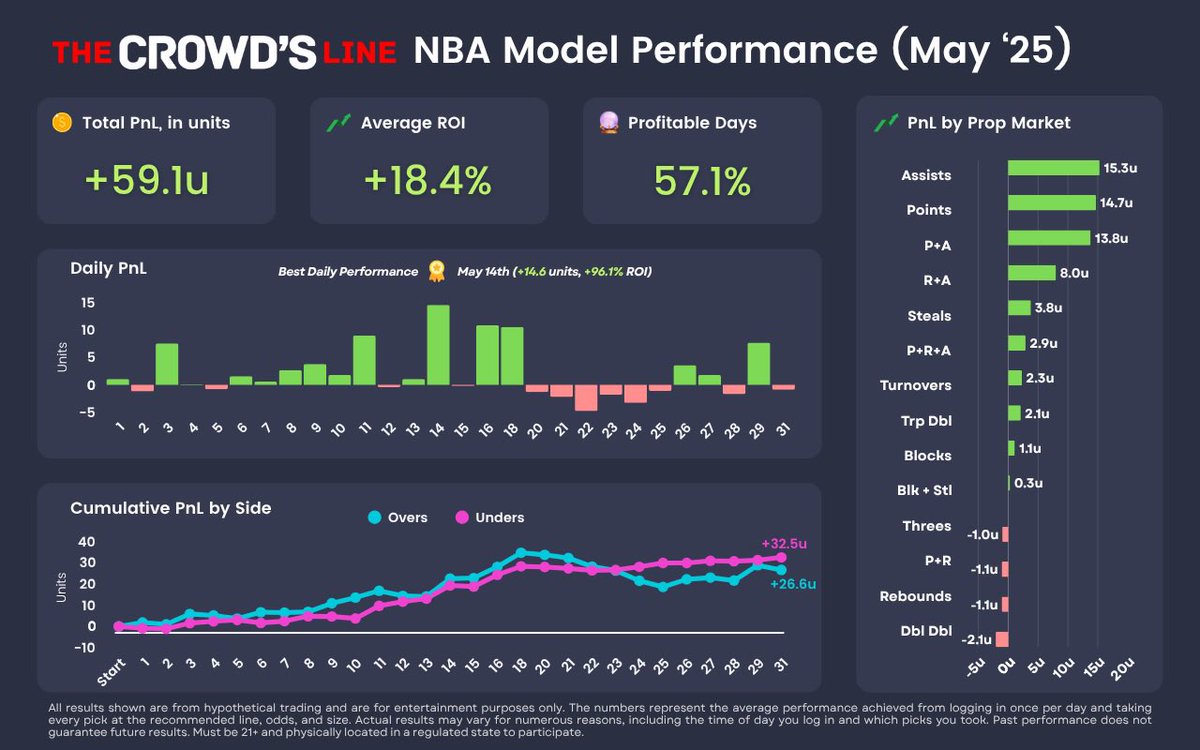
May 2025 NBA Model Recap 🗓️
Overall, we gained 59.1 units 📈
Most of that 💵 came in Round 2. Conference finals proved challenging
Top 3 markets by PnL:
🥇Assists ( 15.3u)
🥈Points ( 14.7u)
🥉Pts Ast ( 13.8u)
For the year, we’re now up 240 units
More details in thread 🧵⬇️
1
1
3
445
Justin Nelson retweeted

26 May 2025
This paper shows LLMs internally break down composite tasks.
They process components sequentially across layers.
Methods 🔧:
→ Layer-from context-masking selectively blocks in-context example access from a specific layer onward.
→ This technique reveals sequential subtask learning points via an "X-shape" accuracy pattern across layers.
→ Cross-task patching injects activations from composite tasks into zero-shot subtask prompts.
→ It demonstrates composite task processing generates distinct, transferable subtask vectors, averaging 0.66 strength in Llama-3.1-8B.
📌 Layer-wise task execution enables precise intervention points.
📌 Task vectors offer a handle for steering learned behaviors.
📌 Internal processing mirrors explicit reasoning steps without outputting them.
----------------------------
Paper - arxiv. org/abs/2505.14530v1
Paper Title: "Internal Chain-of-Thought: Empirical Evidence for Layer-wise Subtask Scheduling in LLMs"

34
133
9,064
Justin Nelson retweeted
19 May 2025
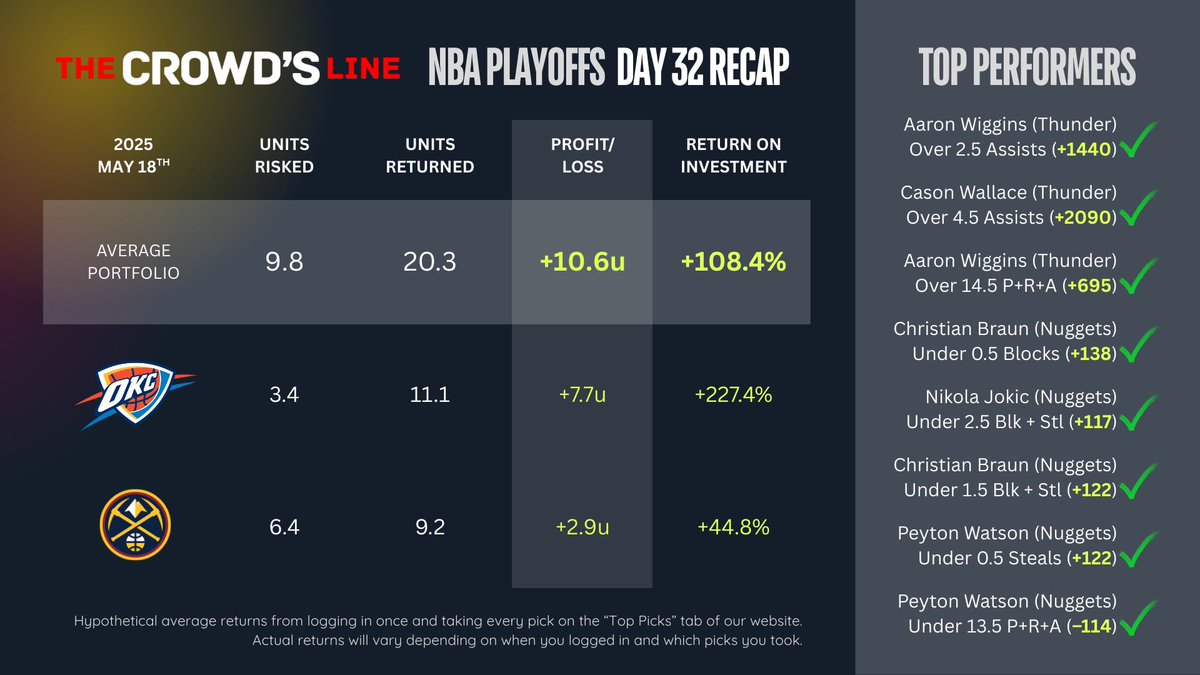
Sunday NBA Model Recap 🔥
Terrifyingly accurate… again! 🎯
Best wins:
✅ Wallace 5 Assists ( 2090)
✅ Wiggins 3 Assists ( 1440)
✅ Wiggins 15 PRA ( 695)
✅ Braun Under 0.5 Blocks ( 138)
Avg Profit: 10.6 units 📈 ROI: 108%
💰💰💰💰💰💰💰💰💰💰💰💰💰
1
3
382
Justin Nelson retweeted
15 May 2025
Wednesday NBA Recap 🔥
Top 20 Picks: 19-1 (95%)‼️
Average Odds? 125😏
Best Wins💰
✅ Podz 25 PA ( 1200)
✅ McBride 3 Assists ( 671)
✅ Butler UNDER Everything ( 3.1U)
Avg Profit: 14.6 units 📈 ROI: 96%
💰💰💰💰💰💰💰💰💰💰💰💰💰
Next Stop 📲 thecrowdsline.ai/dashboard/n…

2
2
7
935
Justin Nelson retweeted

9 May 2025
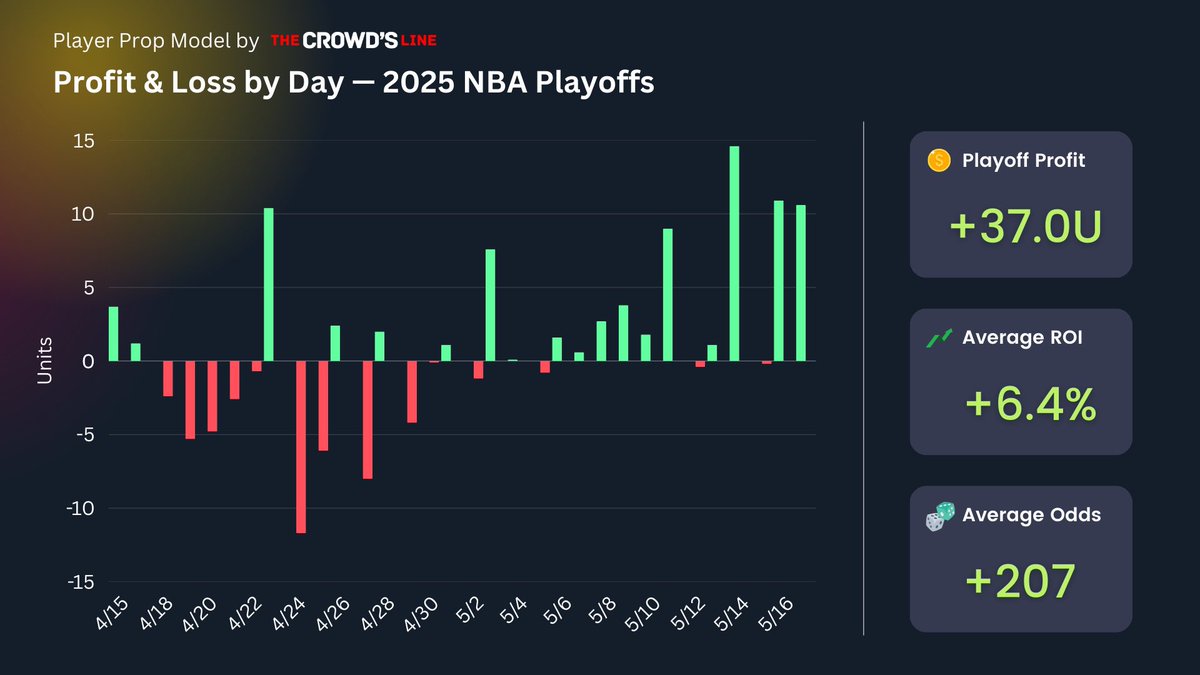
Absolutely crushing it 👏
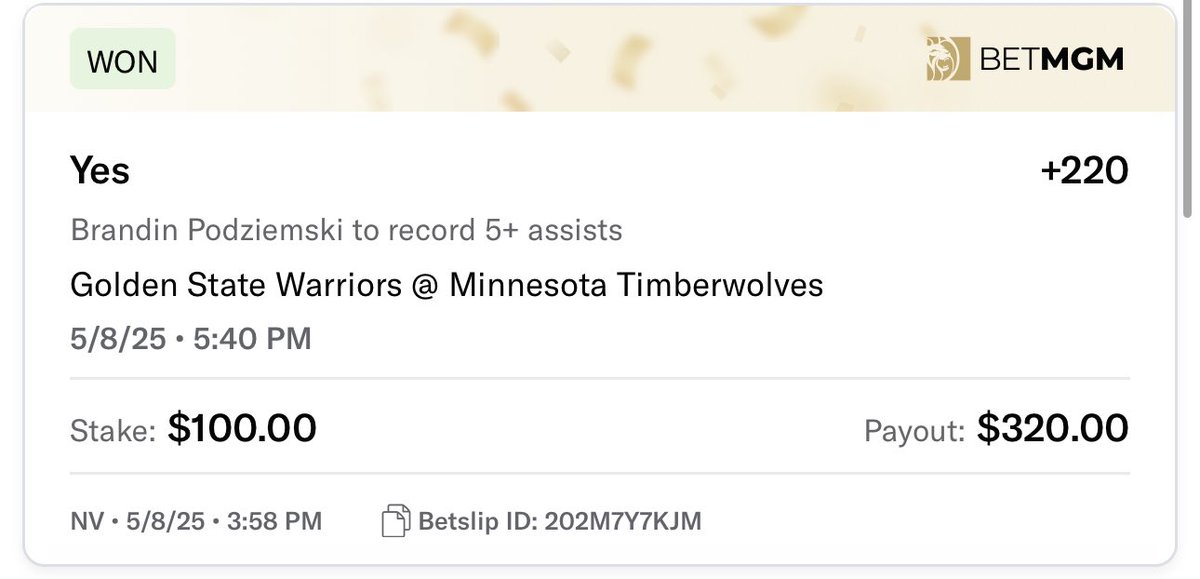
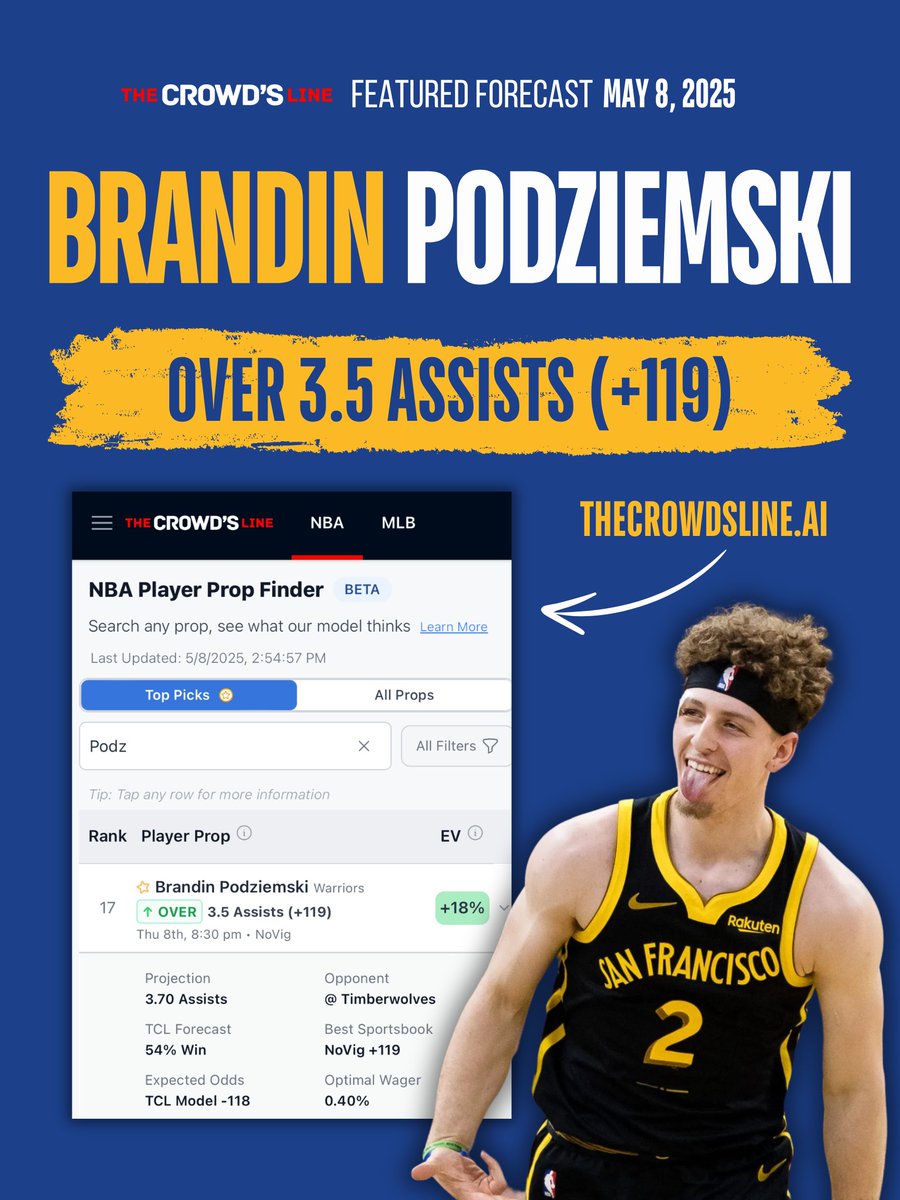
8 May 2025

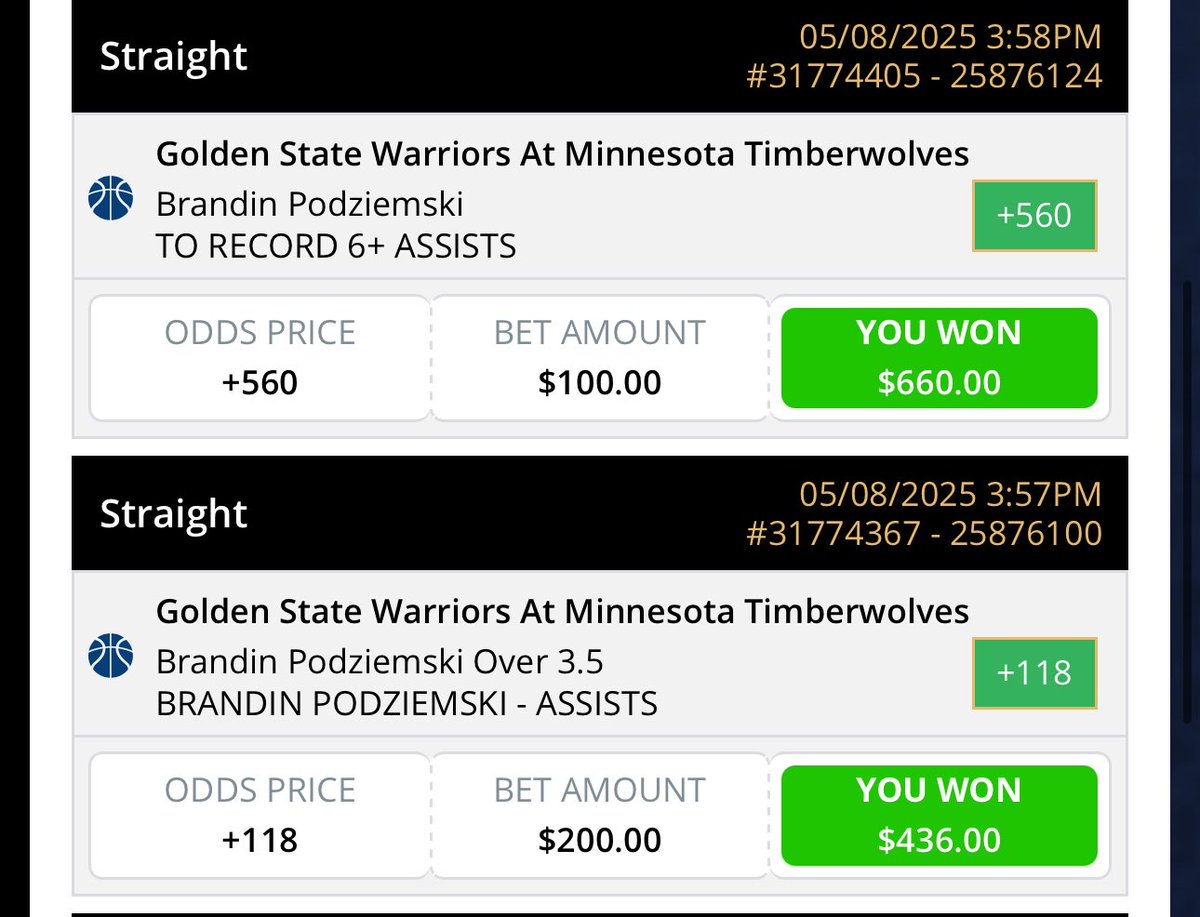
Featured Pick of the Day: Podz O3.5 Assists ( 119)
Also available at 100 on FanDuel, BetMGM, and Caesars
This line is 12-3 in Podz's last 15 games without Steph (going back to last year). No Steph, ~hopefully~ no problem!
Full NBA forecast: thecrowdsline.ai/dashboard/n…
#nbaplayoffs #thecrowdslineai
3
15
8,892
Justin Nelson retweeted
6 May 2025
If you aren't following @theCrowdsLineAI you're missing out on free and easy 1st half winners like this
Also hit the alt for 255!! 👏
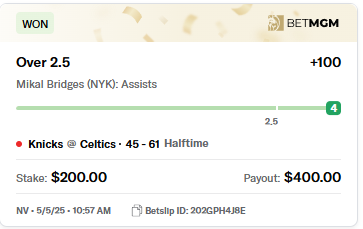

5 May 2025
Today's Pick of the Day: Mikal Bridges O 2.5 Ast!
This bet is available at 100 on DraftKings and BallyBet and -102 on FanDuel 💰
Our model has been HOT with Bridges – he's our 3rd best performing player on the season! Let's see if he can get it done for us in Game 1 at the Garden 🍀
Full NBA forecast: thecrowdsline.ai/dashboard/n…
#NBAPlayoffs #TheCrowdsLineAI

1
3
5
5,188
Justin Nelson retweeted
14 Apr 2025
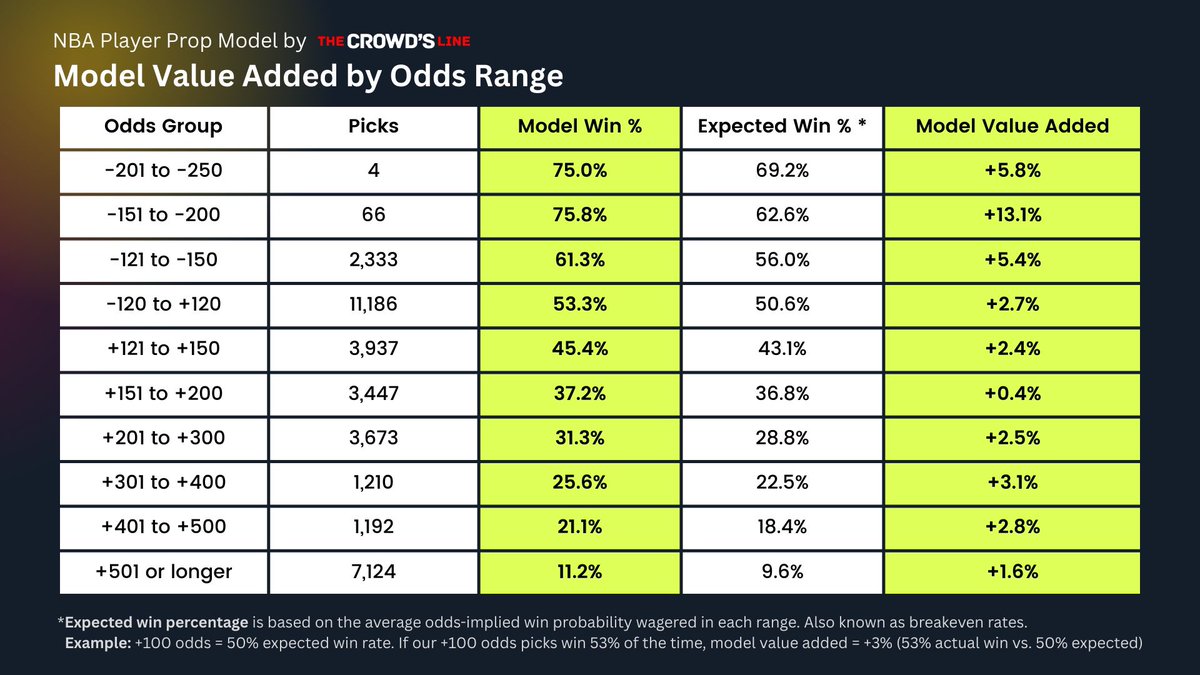
Ready to have your mind blown?🤯
See the model’s win percentage by odds range this NBA season:
💎 Sample size: 34,172 total picks
💎 Profitability: Everywhere✅
Seriously — If 𝘢𝘯𝘺 𝘰𝘵𝘩𝘦𝘳 𝘮𝘰𝘥𝘦𝘭 on the street can beat these results across 34K picks — let us know‼️
1
3
3
895
Justin Nelson retweeted

13 Apr 2025
As we all know by now, reasoning models often generate longer responses, which raises compute costs. Now, this new paper (arxiv.org/abs/2504.05185) shows that this behavior comes from the RL training process, not from an actual need for long answers for better accuracy. The RL loss tends to favor longer responses when the model gets negative rewards, which I think explains the "aha" moments and longer chains of thought that arise from pure RL training.
I.e., if the model gets a negative reward (i.e., the answer is wrong), the math behind PPO causes the average per-token loss becomes smaller when the response is longer. So, the model is indirectly encouraged to make its responses longer. This is true even if those extra tokens don't actually help solve the problem.
What does the response length have to do with the loss? When the reward is negative, longer responses can dilute the penalty per individual token, which results in lower (i.e., better) loss values (even though the model is still getting the answer wrong).
So the model "learns" that longer responses reduce the punishment, even though they are not helping correctness.
In addition, the researchers show that a second round of RL (using just a few problems that are sometimes solvable) can shorten responses while preserving or even improving accuracy. This has big implications for deployment efficiency.

33
184
1,183
108,361
Justin Nelson retweeted
24 Mar 2025
Sunday Recap 🔥
Shook the books’ pockets.. again! 🤑
4th straight day, we earned:
💰 6 units of profit 📈 20% ROI
Top 30 Picks went 19-11 (63%) 🔮
Top Returning Bet:
✅ Steven Adams 10 Boards ( 800)
Caps off our best week of the year
Next stop 📲 thecrowdsline.ai/dashboard/n…
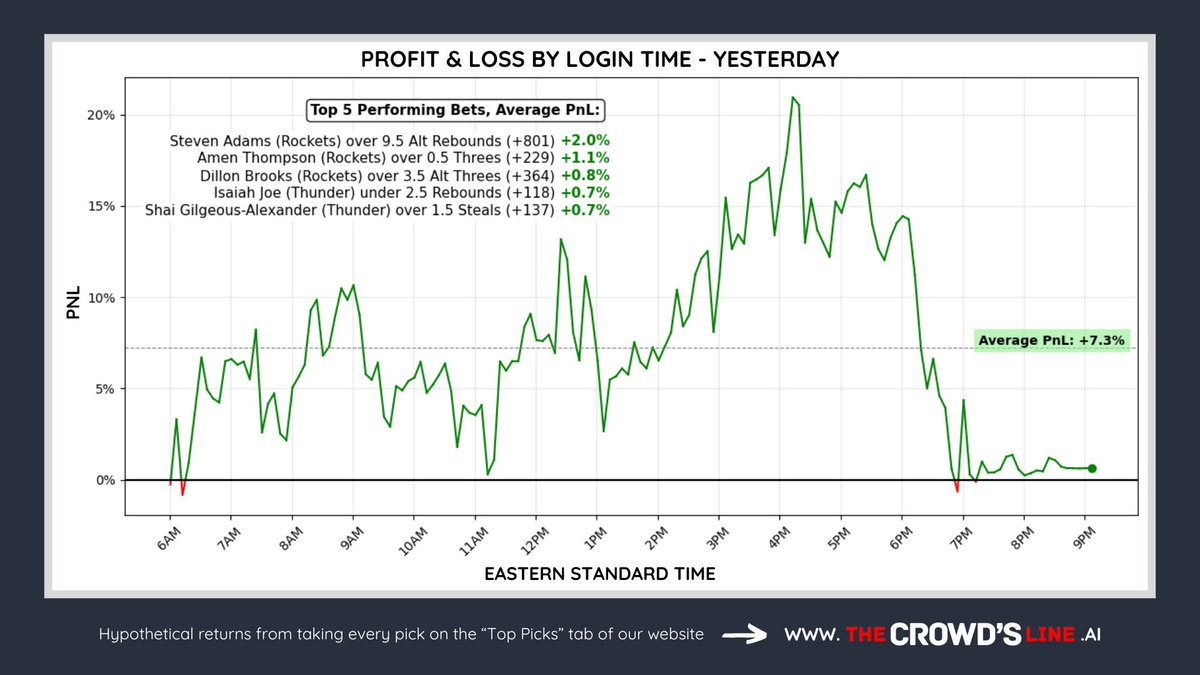
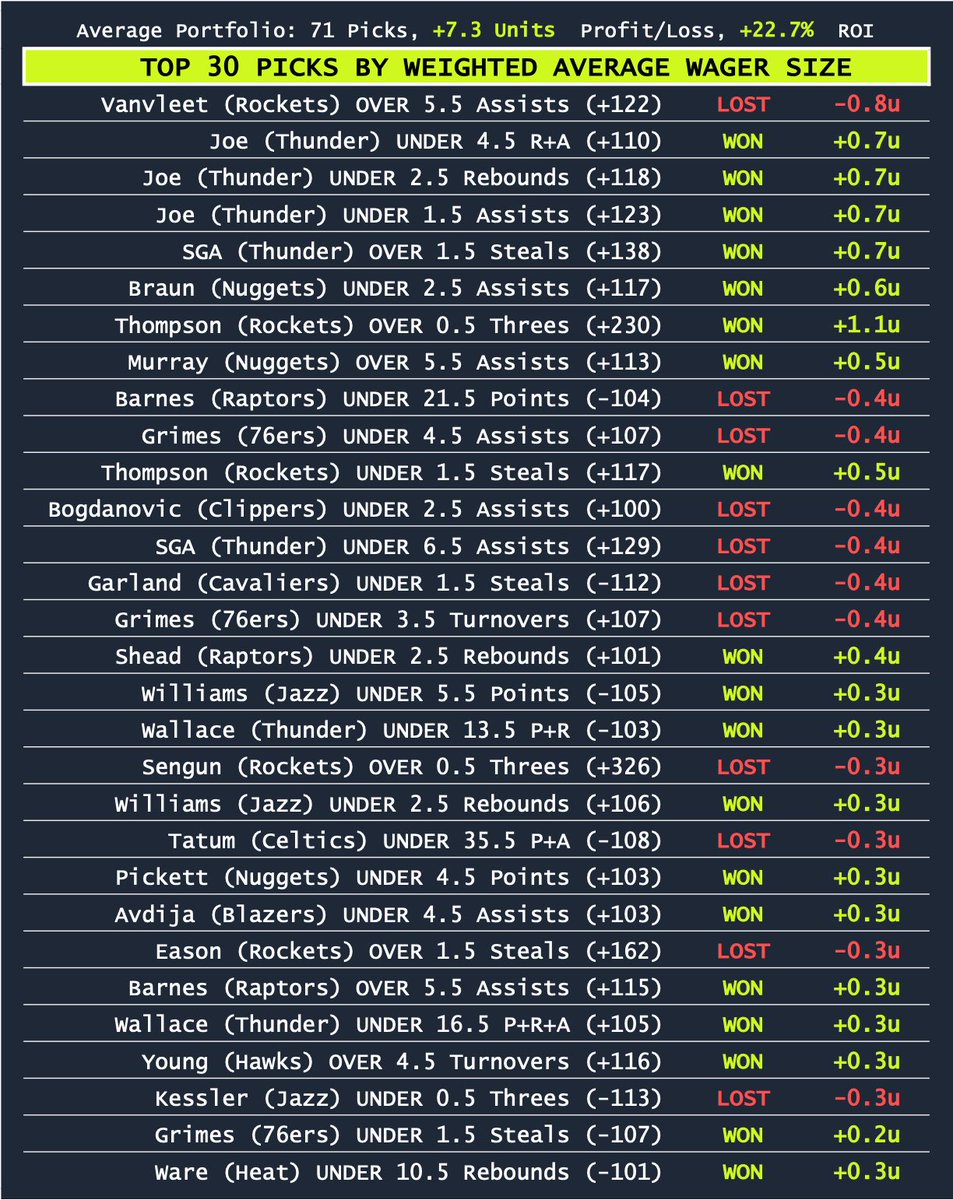
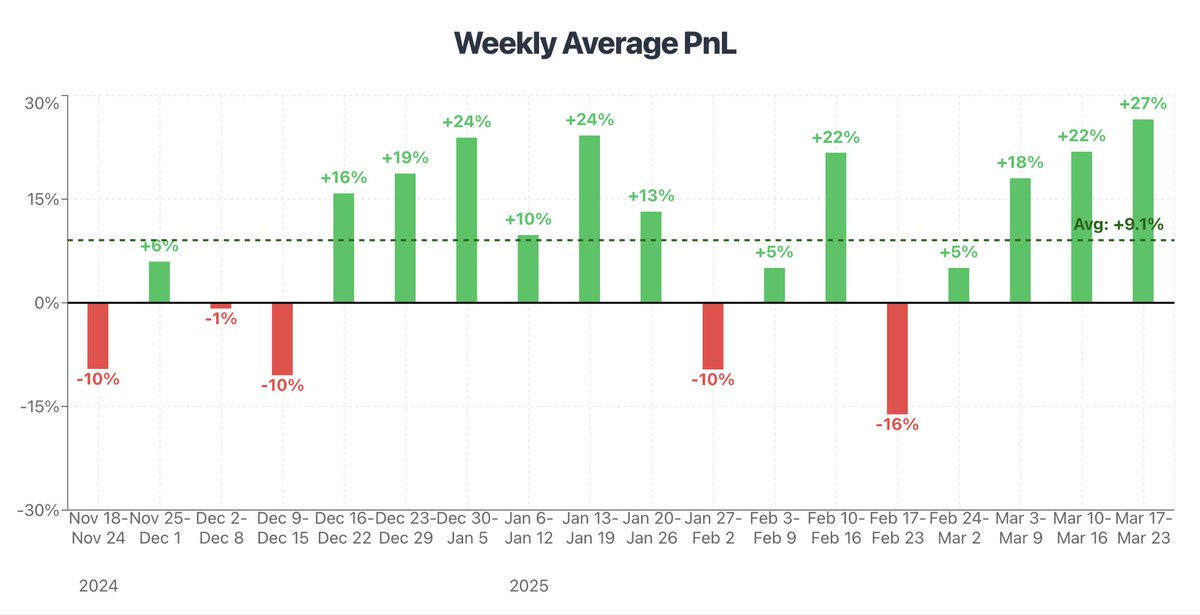
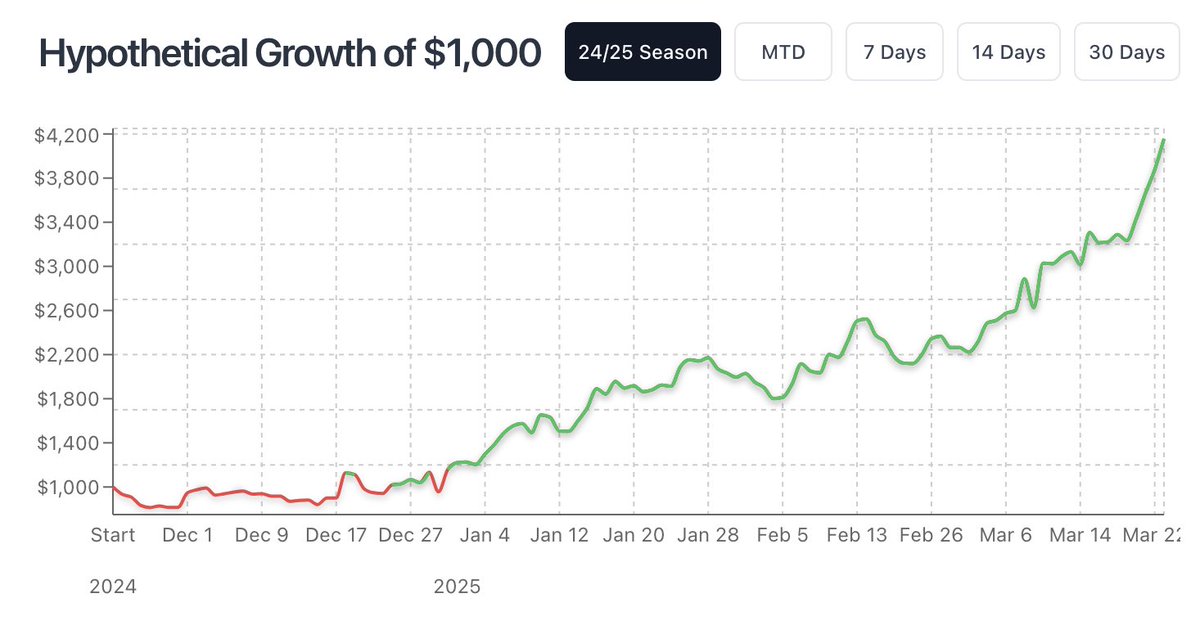
1
2
424
Justin Nelson retweeted
4 Mar 2025
Monday Model Recap 🔥
Bane stole the show!
✅ Triple Double ( 4083)
✅ Double Double ( 597)
✅ 10 Assists ( 973)
Honorable mention…
✅ Zach Edey to sink a Three ( 342)
Average PnL 4.1% 📈 ROI 30%
Next stop 📲 thecrowdsline.ai/dashboard/n…

1
1
3
534
Justin Nelson retweeted

27 Feb 2025
This is interesting as a first large diffusion-based LLM.
Most of the LLMs you've been seeing are ~clones as far as the core modeling approach goes. They're all trained "autoregressively", i.e. predicting tokens from left to right. Diffusion is different - it doesn't go left to right, but all at once. You start with noise and gradually denoise into a token stream.
Most of the image / video generation AI tools actually work this way and use Diffusion, not Autoregression. It's only text (and sometimes audio!) that have resisted. So it's been a bit of a mystery to me and many others why, for some reason, text prefers Autoregression, but images/videos prefer Diffusion. This turns out to be a fairly deep rabbit hole that has to do with the distribution of information and noise and our own perception of them, in these domains. If you look close enough, a lot of interesting connections emerge between the two as well.
All that to say that this model has the potential to be different, and possibly showcase new, unique psychology, or new strengths and weaknesses. I encourage people to try it out!
26 Feb 2025

We are excited to introduce Mercury, the first commercial-grade diffusion large language model (dLLM)! dLLMs push the frontier of intelligence and speed with parallel, coarse-to-fine text generation.
373
1,508
11,443
943,802
Justin Nelson retweeted

25 Feb 2025
Our paper "Function-Space Learning Rates" is on arXiv! We give an efficient way to estimate the magnitude of changes to NN outputs caused by a particular weight update. We analyse optimiser dynamics in function space, and enable hyperparameter transfer with our scheme FLeRM! 🧵👇

12
70
435
86,753
Justin Nelson retweeted

19 Feb 2025
New from @arcinstitute: Evo 2, the largest (by training compute) biology ML model ever, and one of the largest-ever open source ML models in any category. Evo 2 is a foundation model trained on 9T DNA base pairs that learns a lot of fundamental details about life.
A few examples of why it's cool:
Evo 2 seems to learn about pathogenic human mutations. Despite having just a single human genome in the training set, the model is zero-shot SOTA at predicting harmful BRCA1 mutations. (See attached figure.) I find this to be pretty amazing -- there's some kind of emergent understanding of cross-species biological function, despite fully unsupervised training.
Training a sparse autoencoder on Evo 2 results in a model that learns higher-level features across species, setting the stage for biological mechanistic interpretability. For example, the model appears to learn a general concept of coding regions (parts of the genome that are turned into proteins). This feature activates across human, bacterial, and wooly mammoth DNA (the latter of which wasn't included in the training set), even though the coding regions are represented quite differently across different different parts of the tree of life. We're quite excited about where this can go.
Since it's an autoregressive model, Evo 2 can also help with genomic generation. For example, Evo 2 can be used to generate DNA with tailored chromatin accessibility (i.e. controlling how much of it is likely to be transcribed), unlocking new possibilities in synthetic biology.
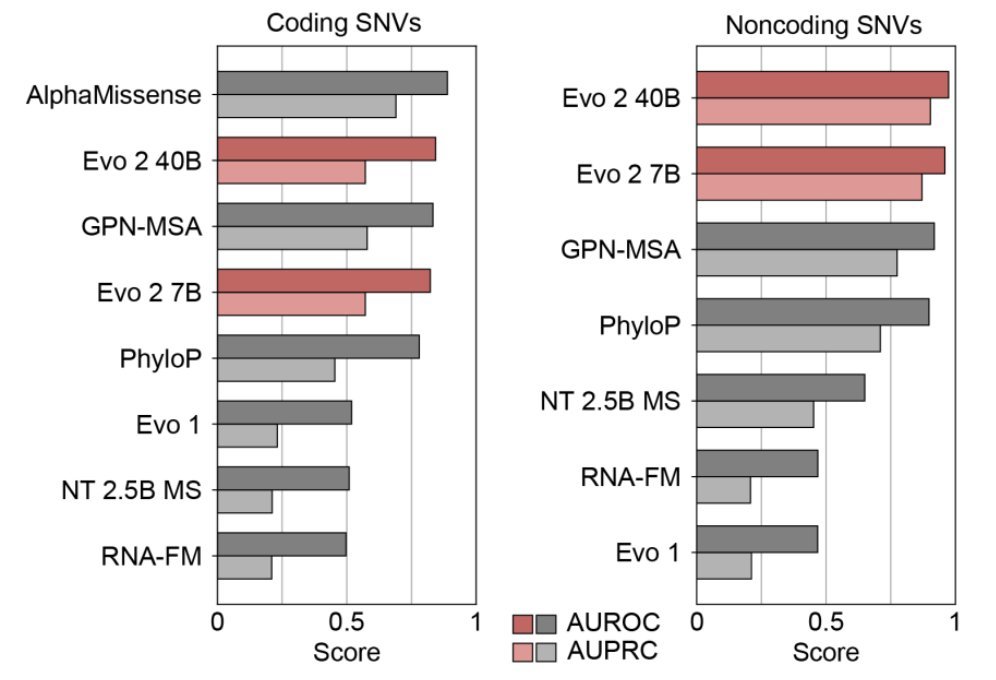
42
138
985
423,029
Justin Nelson retweeted

19 Feb 2025
After 6 months in the making and burning over a year of GPU compute time, we're super excited to finally release the "Ultra-Scale Playbook"
Check it out here: hf.co/spaces/nanotron/ultras…
A free, open-source, book to learn everything about 5D parallelism, ZeRO, fast CUDA kernels, how and why overlap compute & communication – all scaling bottlenecks and tools introduced with motivation, theory, interactive plots from our 4000 scaling experiments and even NotebookLM podcasters to tag along with you.
- How was DeepSeek trained for $5M only?
- Why did Mistral trained an MoE?
- Why is PyTorch native Data Parallelism implementation so complex under the hood?
- What are all the parallelism techniques and why were they invented?
- Should I use ZeRO-3 or Pipeline Parallelism when scaling and what's the story behind both techniques?
- What is this Context Parallelism that Meta used to train Llama 3? Is it different from Sequence Parallelism?
- What is FP8? how does it compares to BF16?
In this book, our goal was to gather, in a single place, a coherent, easy to read yet detailed story of all the techniques that make today's LLM scaling possible.
The largest factor for democratizing AI will always be teaching everyone how to build AI and in particular how to create, train and fine-tune high performance models. In other word making accessible to everybody the techniques that power all recent large language models and efficient training is possibly one of the most essential of them.
What started as a simple blog-post ended up becoming an interactive writing piece containing 30k words. So we've decided to actually print it as a real 100-pages physical book as well: the physical ultrafast playbook –containing all the science of distributed and fast AI training.
We plan to send free copies as gifts to the first readers of the online version so feel free to add your email in the form linked in the blog post.
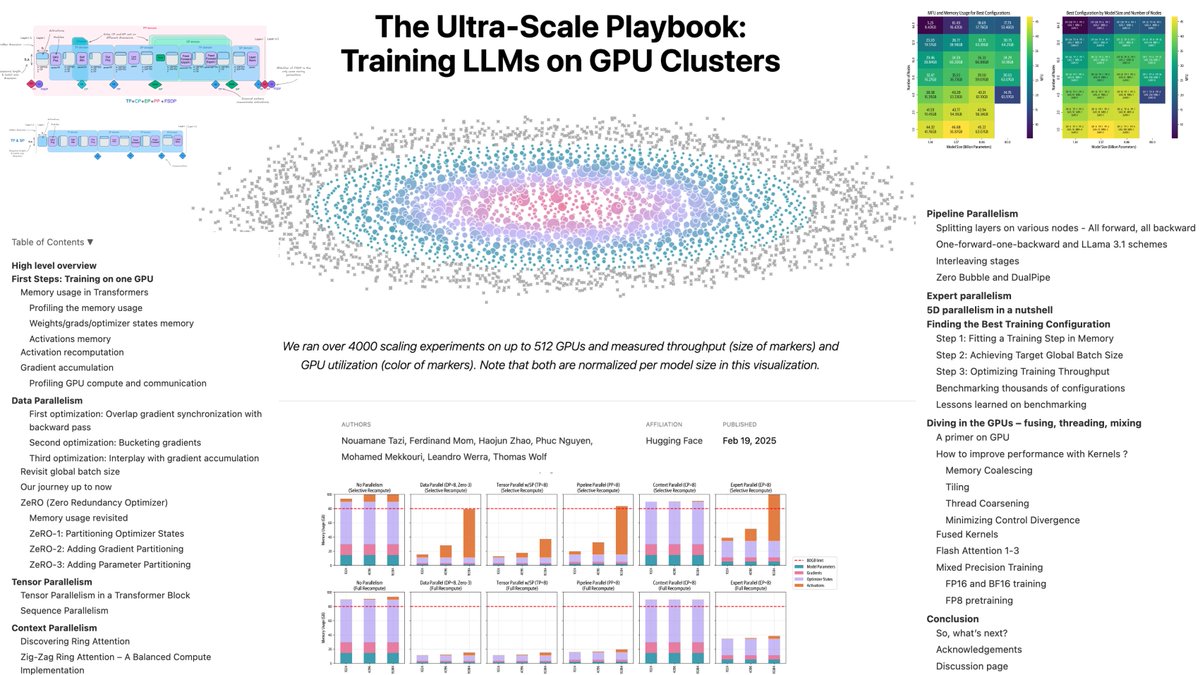
109
687
3,836
369,377
Justin Nelson retweeted

10 Feb 2025
New open source reasoning model!
Huginn-3.5B reasons implicitly in latent space 🧠
Unlike O1 and R1, latent reasoning doesn’t need special chain-of-thought training data, and doesn't produce extra CoT tokens at test time.
We trained on 800B tokens 👇
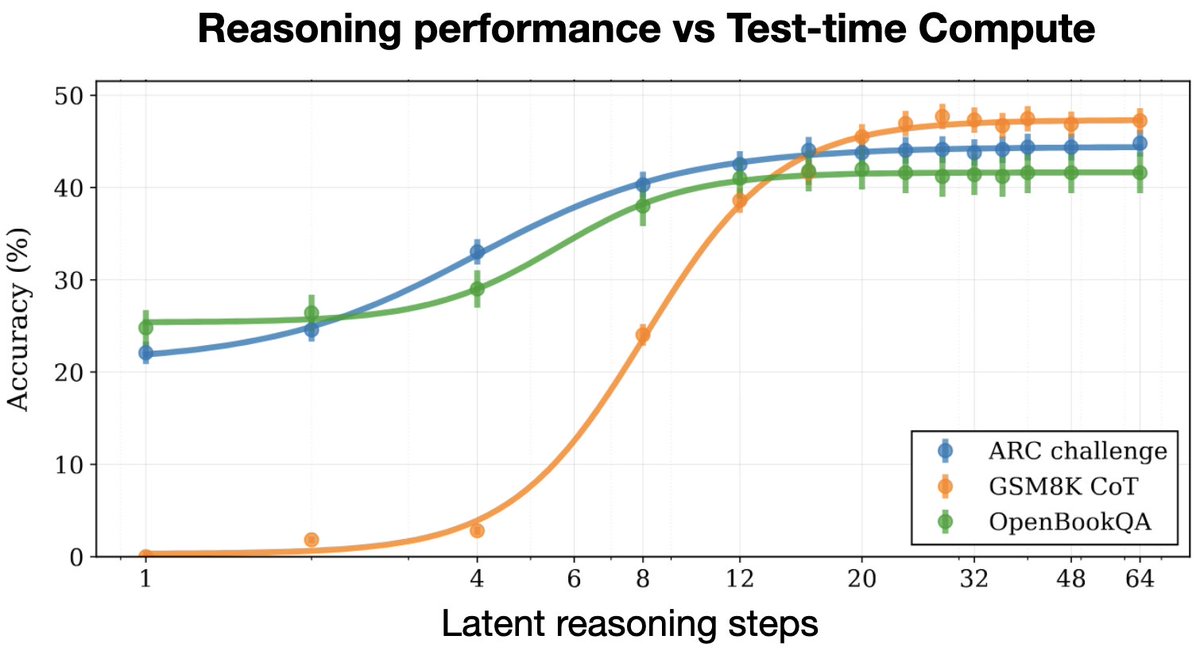
48
267
2,049
268,694
Justin Nelson retweeted

10 Feb 2025
Ok, so I can finally talk about this!
We spent the last year (actually a bit longer) training an LLM with recurrent depth at scale.
The model has an internal latent space in which it can adaptively spend more compute to think longer.
I think the tech report ...🐦⬛

54
196
2,144
369,602