
Joined October 2012
- Tweets 19,760
- Following 1,150
- Followers 462,243
- Likes 24,944
2,126 Photos and videos










Pinned Tweet

Apr 4
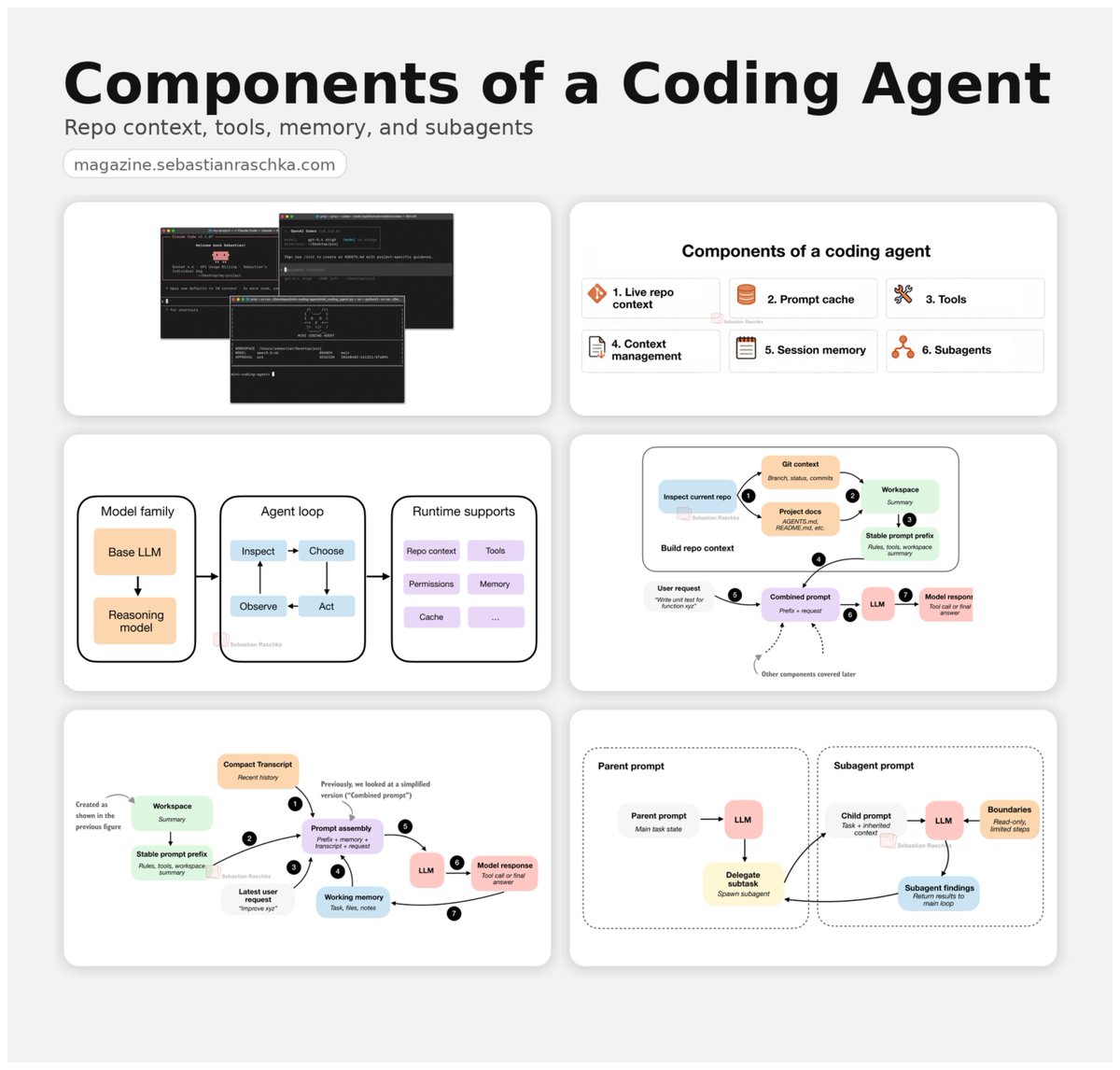
Components of a coding agent: a little write-up on the building blocks behind coding agents, from repo context and tool use to memory and delegation.
Link: magazine.sebastianraschka.co…
57
209
1,239
140,261
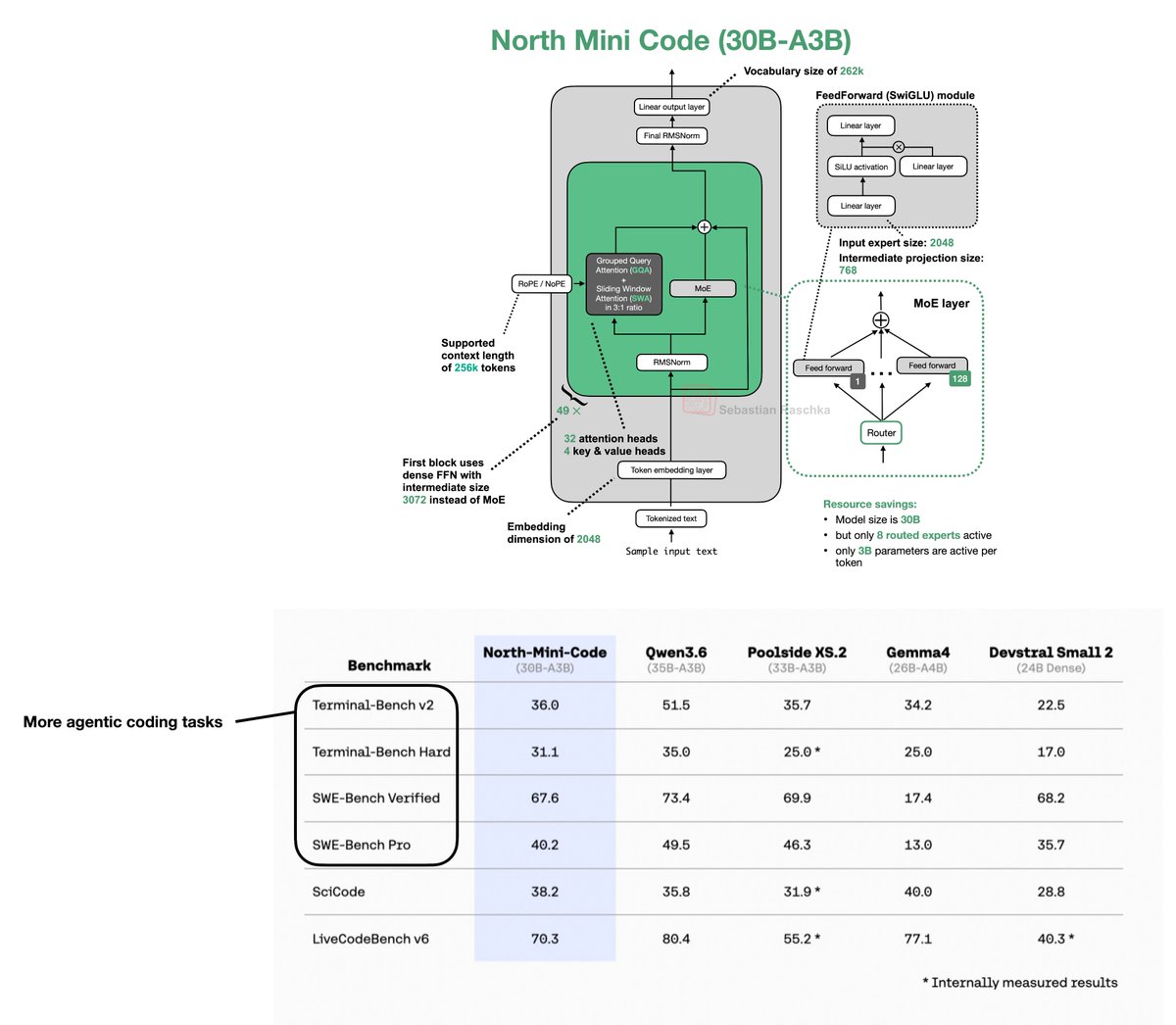
Cool new open-weight model by Cohere: a new lightweight 30B open-weight model for agentic coding tasks.
This one builds on Command A using the parallel transformer design. Interestingly, even though it's almost half as big, it almost doubles the number of layers.
Also, they say that it's been specifically developed for agentic coding, not just coding. I.e., the evaluation is inside a workflow, not just on a single prompt-to-code-answer task.
For Terminal-Bench, the model has to use a terminal, inspect the environment, run commands, read outputs, etc.
For SWE-Bench the model works on real GitHub-style software issues where it has to understand the repository, find relevant files, make a patch, pass tests, etc.
SciCode and LiveCodeBench are more traditional because they mostly test whether the model can produce correct code for a specified problem. Sure, this still requires reasoning, but it's more like “Implement a numerical routine to compute a scientific quantity from given equations and inputs.” which doesn't require any interaction with the environment, existing files, tests, etc.
The focus on the agentic code benchmarks is probably why it's far ahead of Gemma 4 on those.
Overall, it's pretty competitive although not quite Qwen3.6-level performance.
35
77
571
28,790
Jun 9
Turns out Fable 5 is shadowbanning AI researchers 🫤
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

68
96
1,333
79,503
Jun 9
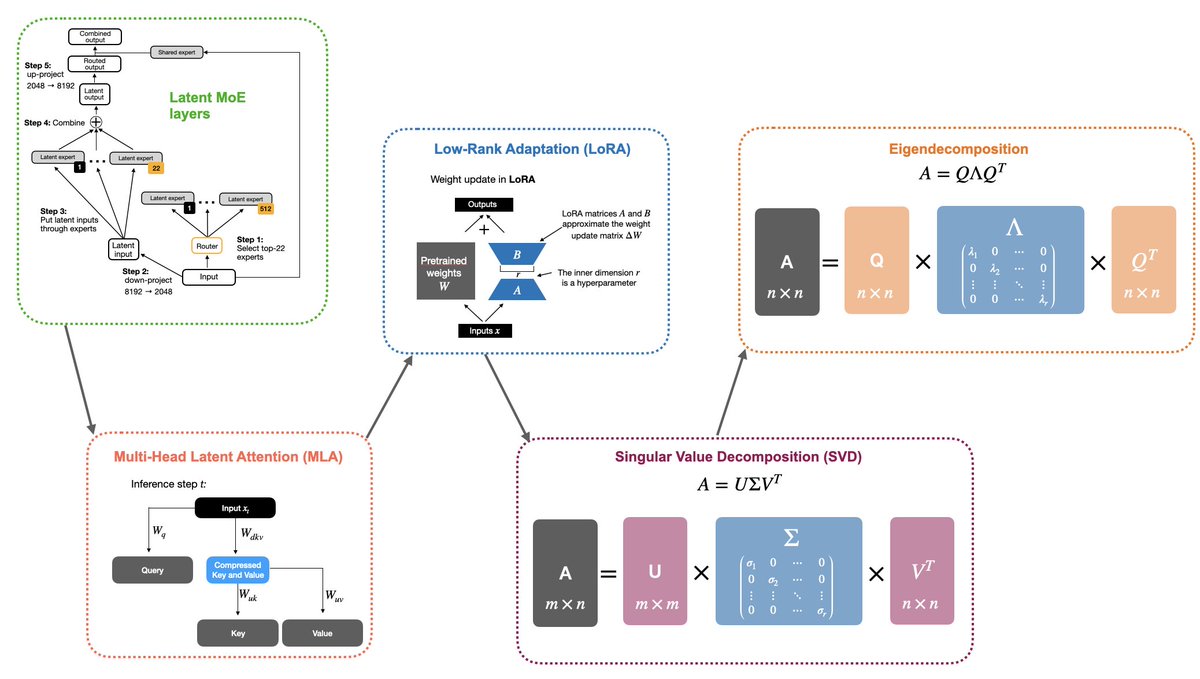
Always back to the basics:
LatentMoE was probably inspired by MLA, which was inspired by LoRA, which was inspired by SVD, which was inspired by eigendecomposition.
28
89
773
33,068
Jun 4
And another open-weight release. Nemotron 3 Ultra has an ultra impressive capability:efficiency ratio!
Design-wise, it carries forward the Mamba-2-attention hybrid stack and LatentMoE introduced in the previous Super variant. But everything is a bit bigger.
Jun 3

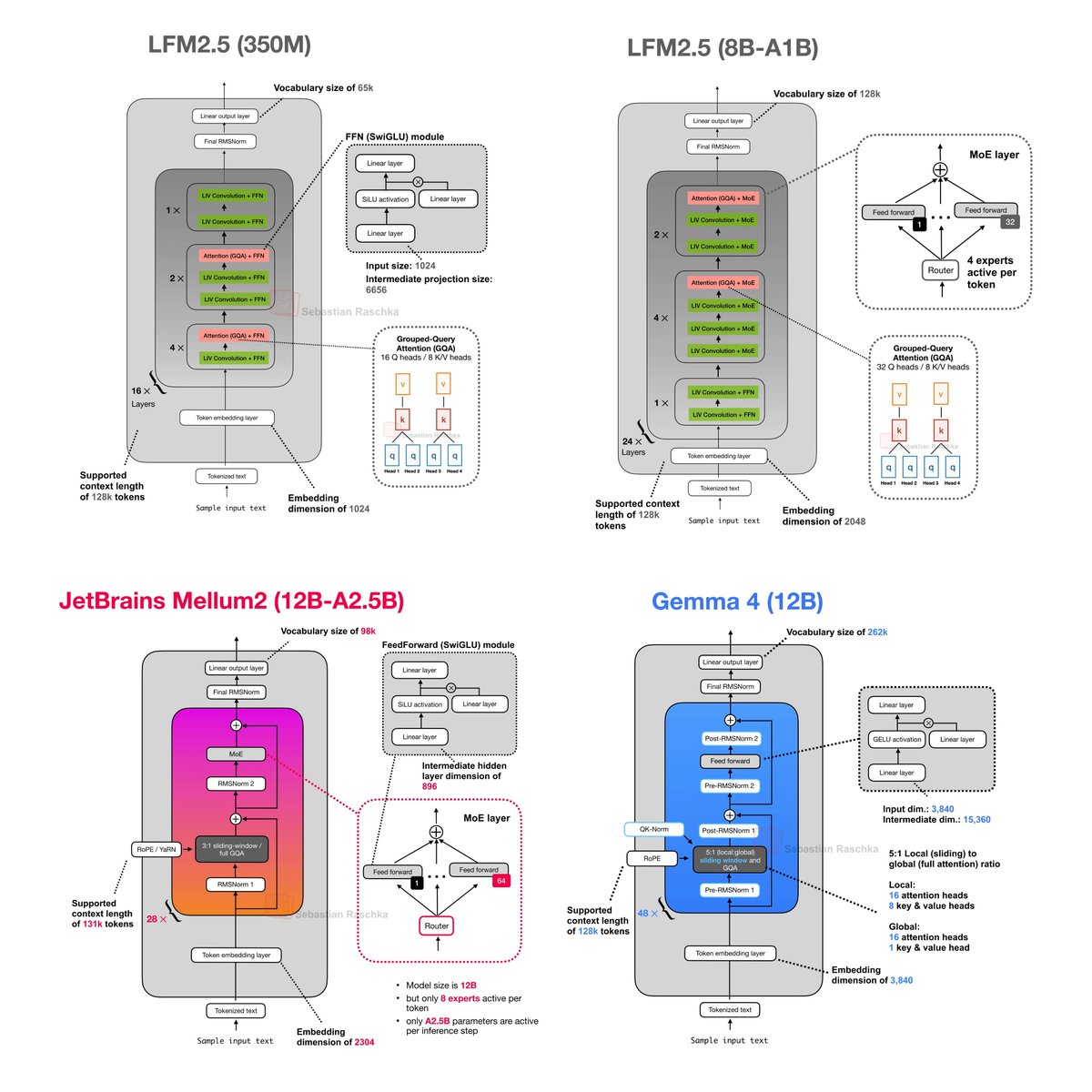
It's been a while! 4 nice additions to the open-weight local-LLM-on-consumer-hardware ecosystem:
32
94
664
42,463
Jun 3
It's been a while! 4 nice additions to the open-weight local-LLM-on-consumer-hardware ecosystem:
32
164
1,060
92,456
May 27
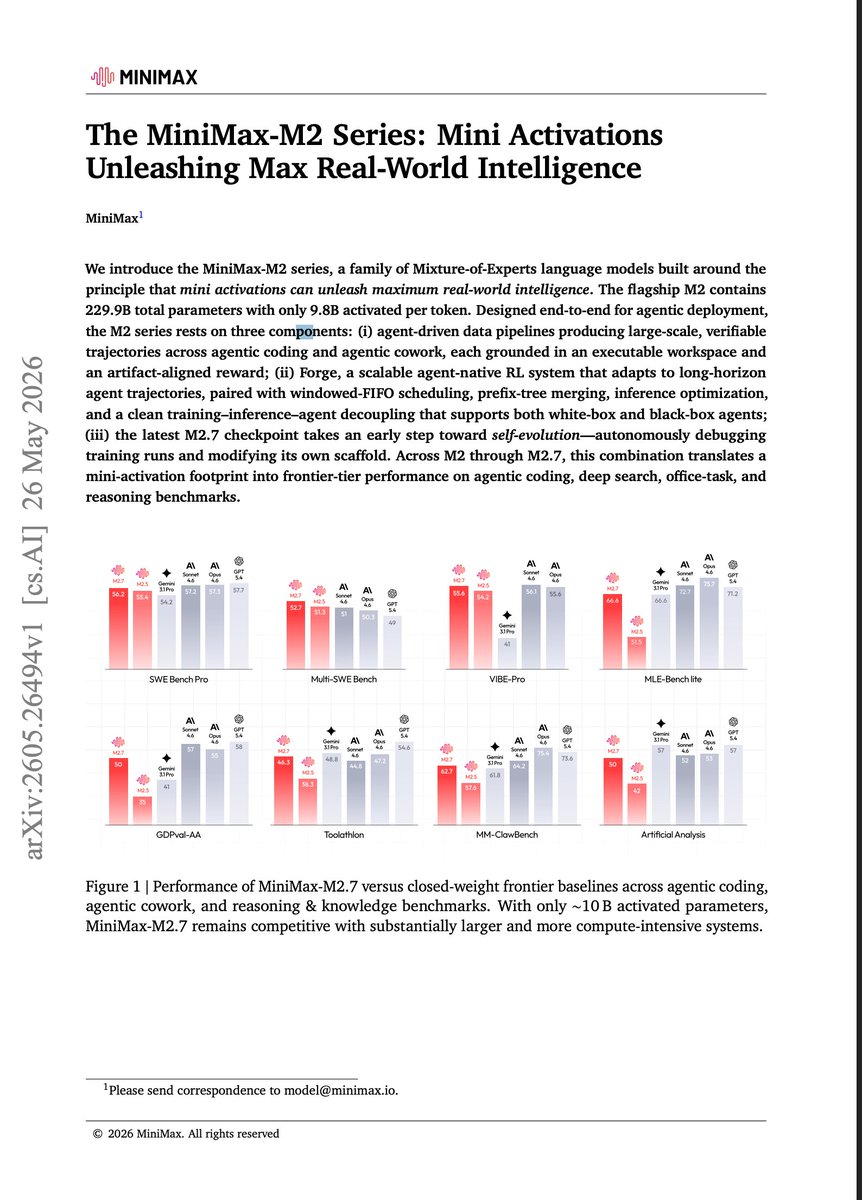
The MiniMax M2 series was one of the most widely used open-weight LLM series earlier this year. Now, we got a technical report with some interesting tidbits. I summarized some of them below:
1. Full attention as an anti-trend?:
They tried hybrid sliding-window attention variants (like so many others, like Xiaomi MiMo, Laguna, Gemma 4, Arcee, Olmo 3, etc.). But even though there were efficiency gains, they said that the production-quality tradeoffs were not worth it for M2.
2. Linear and sparse attention deployment issues:
They found that linear and sparse attention are attractive on paper because they reduce the cost of long-context attention, but they are harder to make work well in a production agent system.
In particular, they found that these efficient attention variants may be more fragile when KV-like state or intermediate memory is stored in lower precision.
Also, they have worse prefix caching support, which matters a lot when using coding agents (which reuse a lot of the context).
3. Fine-grained Mixture-of-Experts (MoEs) are useful:
Finally a recent MoE ablation study! It's only on the 2B-active parameter scale, but hey, better than nothing.
Concretely, they compare a baseline with 32 experts and top-2 routing against a fine-grained setup with 128 experts and top-8 routing.
The fine-grained setup improves MATH from 19.6 to 24.1 and HumanEval from 29.7 to 32.5. That's clearly a win for more fine-grained experts (confirming what the DeepSeek MoE paper reported ~2 years ago).
4. Sophisticated agent pipeline
It's probably no surprise, but this papers confirms that training for agent-like behavior on software engineering task is now a big component of the training pipeline.
They mine GitHub pull requests, builds runnable Docker environments, extracts task-specific test rewards, etc.
5. Interleaved thinking for context management
Interestingly, they found that removing reasoning blocks from previous turns results in worse performance, especially in multi-step agent tasks. (Another point why long-context support is so important these days).
6. Speed rewards
It's common to have token usage penalties, but what's interesting is that the MiniMax team adds a task-completion-time reward that depends on wall-clock time. This is to minimize unnecessary (slow) tool calls. Also, I'm thinking that this would encourage agent parallelization (if supported by the harness)
7. Self-evolution
Looks like self-evolution is also already a big design component of open-weight LLMs. E.g., the paper says that M2.7 already handles 30 to 50 percent of the daily RL iteration workload, modifies its own scaffold, and completed a 100-round autonomous scaffold optimization cycle with a 30 percent gain on internal evaluations.
May 27

Recently, we took time to consolidate all of the work behind M2 and published it here: our M2 paper on arXiv
It’s been just over six months since we first open-sourced M2 on December 23 last year.
During that time, a number of our ideas and systems have been broadly adopted by the open-source community — including CISPO, Forge RL System, Self-Evolution.
Over the past six months, we’ve felt incredible enthusiasm from the open-source community. Nearly every model release reached the #1 spot on the Hugging Face leaderboard.
Now it’s time for a new chapter.
We’re getting ready for M3.
MSA paper is on the road.
arxiv.org/abs/2605.26494
36
94
537
38,318
May 23
Added a DeepSeek Sparse Attention (DSA) from-scratch implementation to my LLMs-from-scratch repo thanks to an awesome new reader contrib.
With motivation, overview, and GPT-style model reference implementation as standalone example code: github.com/rasbt/LLMs-from-s…
44
242
1,792
74,575
May 21
Gated DeltaNet has been one of my favorite "hybrid attention" newcomers in the good old transformer stack.
Excited to see Gated DeltaNet-2. Adding it to my reading stack. In the meantime, I have a primer on Gated DeltaNet here: magazine.sebastianraschka.co…
May 21

Gated DeltaNet-2 is here. 🚀
🔥 New paper: Gated DeltaNet-2: Decoupling Erase and Write in Linear Attention
Gated DeltaNet-2 outperforms KDA and Mamba-3, the latest and best recurrent architectures, head to head at 1.3B. 🏆
💡 Here's the idea behind it:
Linear attention squeezes an unbounded KV cache into a fixed-size recurrent state. The hard part isn't just what to forget, it's how to edit that memory without scrambling the associations already in it.
Prior delta-rule models like Gated DeltaNet and KDA use one scalar gate to do two jobs at once: erasing old content and writing new content. But these two decisions act on different axes of the state, so tying them together is a real limitation.
Gated DeltaNet-2 decouples them.
✂️ a channel-wise erase gate b_t picks which key-side coordinates to read and remove
✍️ a channel-wise write gate w_t picks which value-side coordinates to commit
🔁 recovers KDA when both gates collapse to a scalar, and Gated DeltaNet when the decay collapses too
⚡ still trains fast: chunkwise WY algorithm with gate-aware backward, fused in Triton
📊 Results:
We train 1.3B models on 100B tokens of FineWeb-Edu, matched in recurrent state size, against Mamba-2, Gated DeltaNet, KDA, and Mamba-3.
Best average on language modeling commonsense reasoning, in both recurrent and hybrid settings
Biggest gains on long-context RULER retrieval. S-NIAH-3 jumps from 63 to 90 over KDA, and multi-key needle retrieval climbs from 28 to 38
Joint work with @YejinChoinka and @jankautz.
📄 Paper: shorturl.at/AAlVb
💻 Code: github.com/NVlabs/GatedDelta…
#LinearAttention #StateSpaceModels #Mamba #LLM

24
53
381
52,412
May 21
PS: it can be found in recent Qwen models since Qwen3-Next
3
3
45
7,917
May 20
It's been *almost* a bit quiet around LLM architecture releases in the past two weeks 😅
Interesting tidbit is the parallel block design. Via the Cmd-A the tech report
"equivalent performance but significant improvement in throughput compared to the vanilla transformer block."

Introducing: Cohere Command A
We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
32
78
669
66,280
May 16
New article: a visual tour of recent LLM architecture advances, from Gemma 4 to DeepSeek V4.
I focus on long-context efficiency tweaks like KV sharing, per-layer embeddings, layer-wise attention budgets, compressed attention, and mHC.
Link: magazine.sebastianraschka.co…
45
426
2,351
122,738
May 14
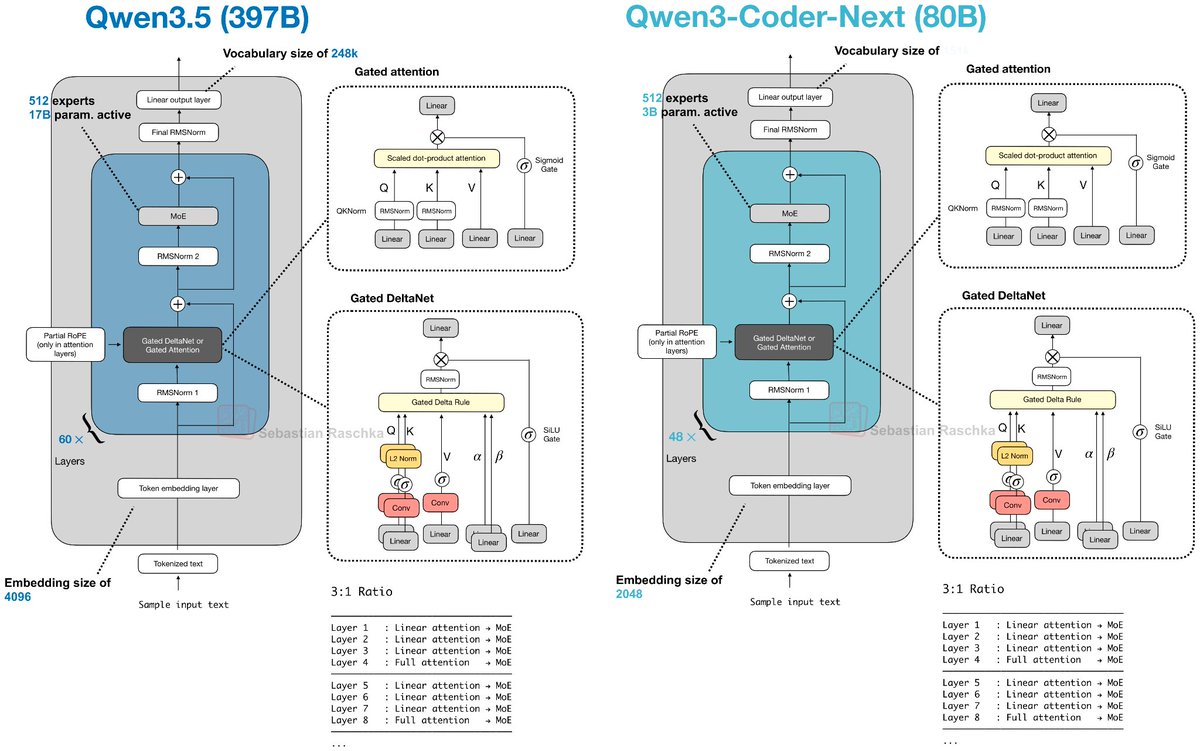
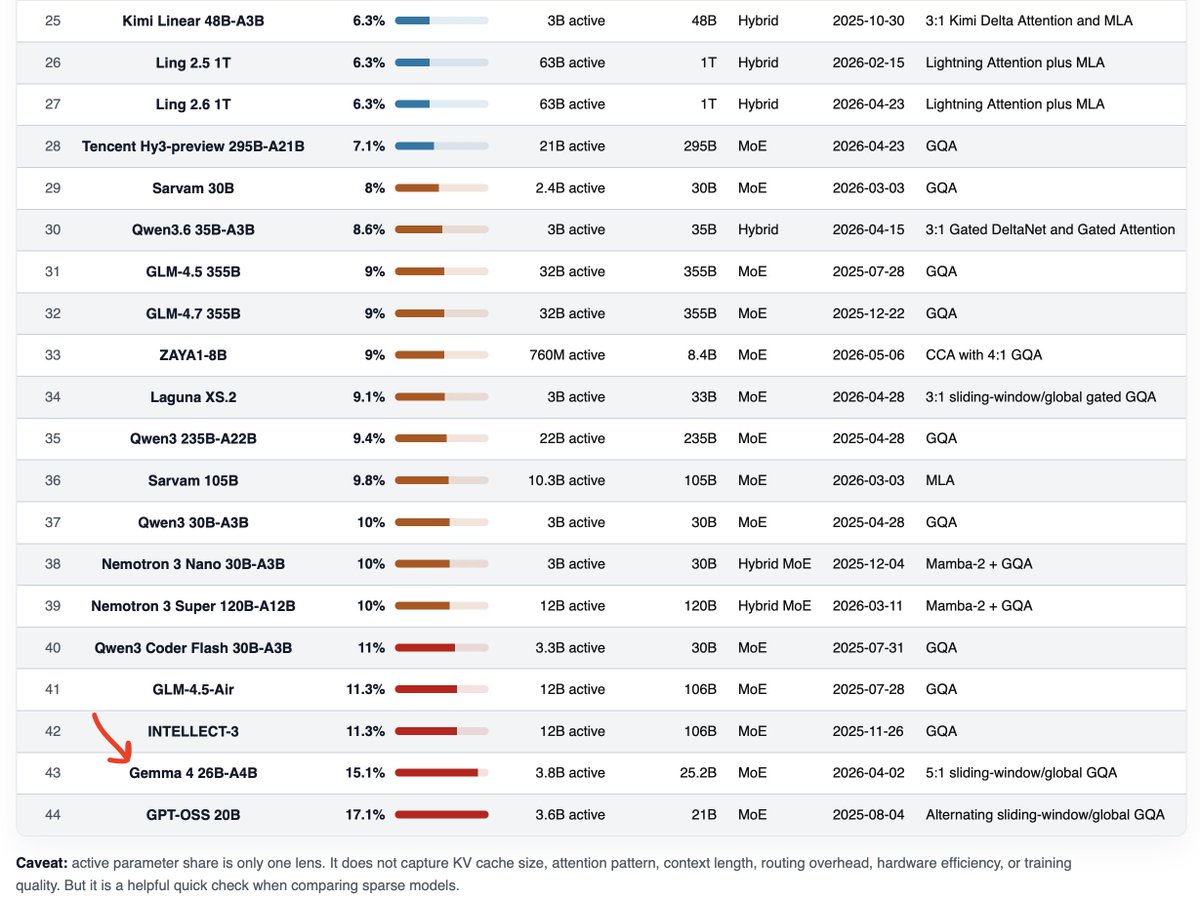
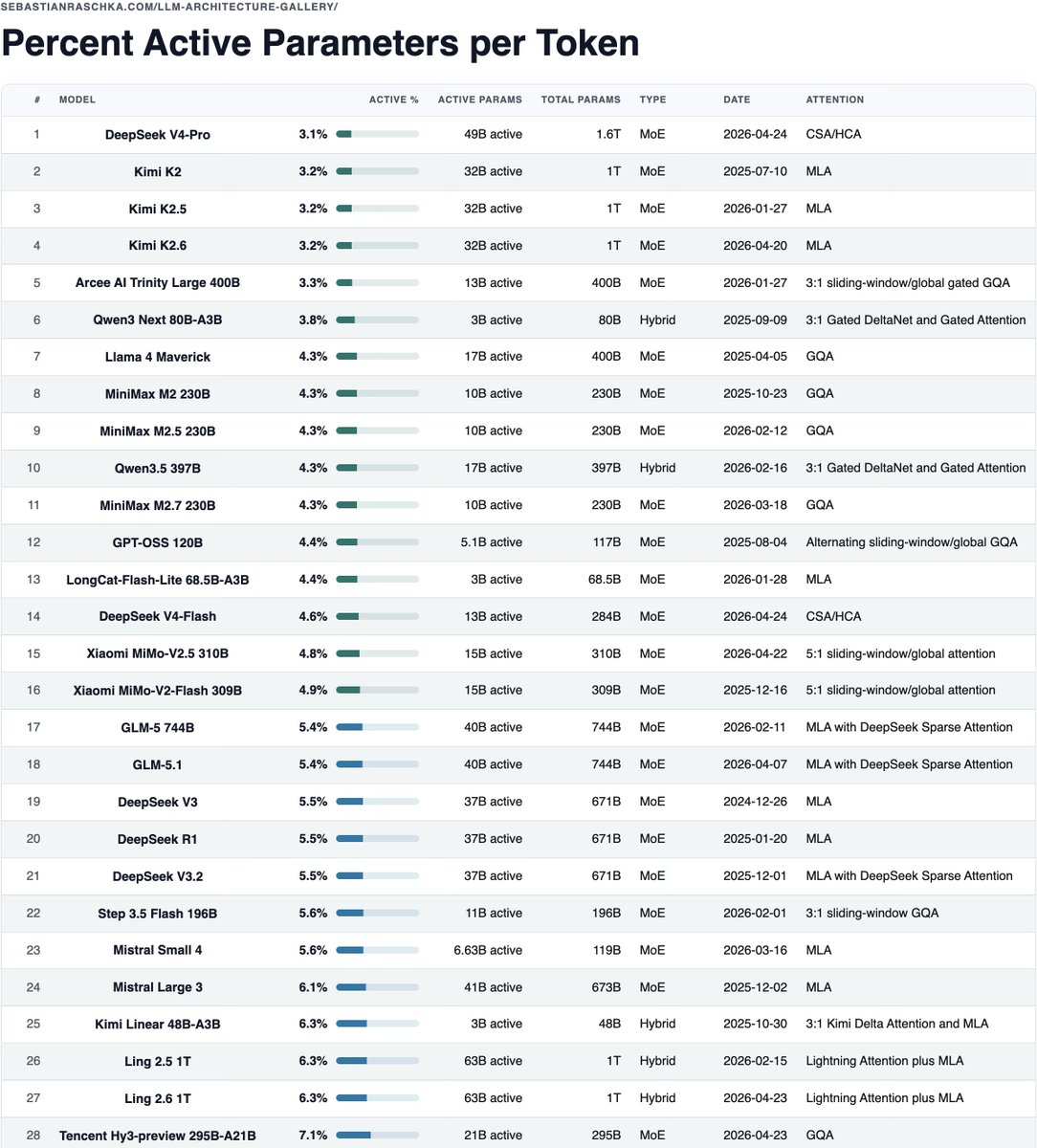
Meta observation: DeepSeek is still king of the active-parameter ratio
20
38
335
58,581
May 14
The table in HTML format for easier (and non-truncated) viewing: sebastianraschka.com/llm-arc…
3
2
16
8,841
May 13
A little talk on what we can learn from implementing LLM architectures from scratch in Python and PyTorch.
And how I approach new open-weight models, compare them against reference implementations etc:
youtube.com/watch?v=TXzQ7PGp…
23
167
994
70,477
May 13
Interesting paper. What I like about this is that it is a relatively low-commitment attention modification.
I.e., one can use it during most of training, switch back to vanilla attention near the end, and recover roughly the same modeling performance as if full attention had been used the whole time.

Cool idea from Nous Research.
What if you could speed up long-context pretraining with a subquadratic wrapper that you remove before deployment?
That is the idea behind Lighthouse Attention.
The method wraps ordinary SDPA with a hierarchical, gradient-free selection layer that compresses and decompresses queries, keys, and values symmetrically, preserving left-to-right causality.
Crucially, it can be removed near the end of training in a short recovery phase, so the deployed model still runs vanilla attention with no architectural cost at inference.
Preliminary LLM experiments report faster total training time and lower final loss than full-attention baselines.
Why does it matter?
Most efficient-attention work either changes the deployment-time architecture or pays a quality tax to do so. A training-only wrapper that survives a clean recovery phase sidesteps both. If it scales, this becomes an important training-time speedup for long-context pretraining.
Paper: arxiv.org/abs/2605.06554
Learn to build effective AI agents in our academy: academy.dair.ai/

13
56
342
50,704
May 10
Back from a little family break! Lots has happened, and I’m planning to do a deeper dive into the most interesting architectural components (soon).
Btw, are there any major architectures I missed below?
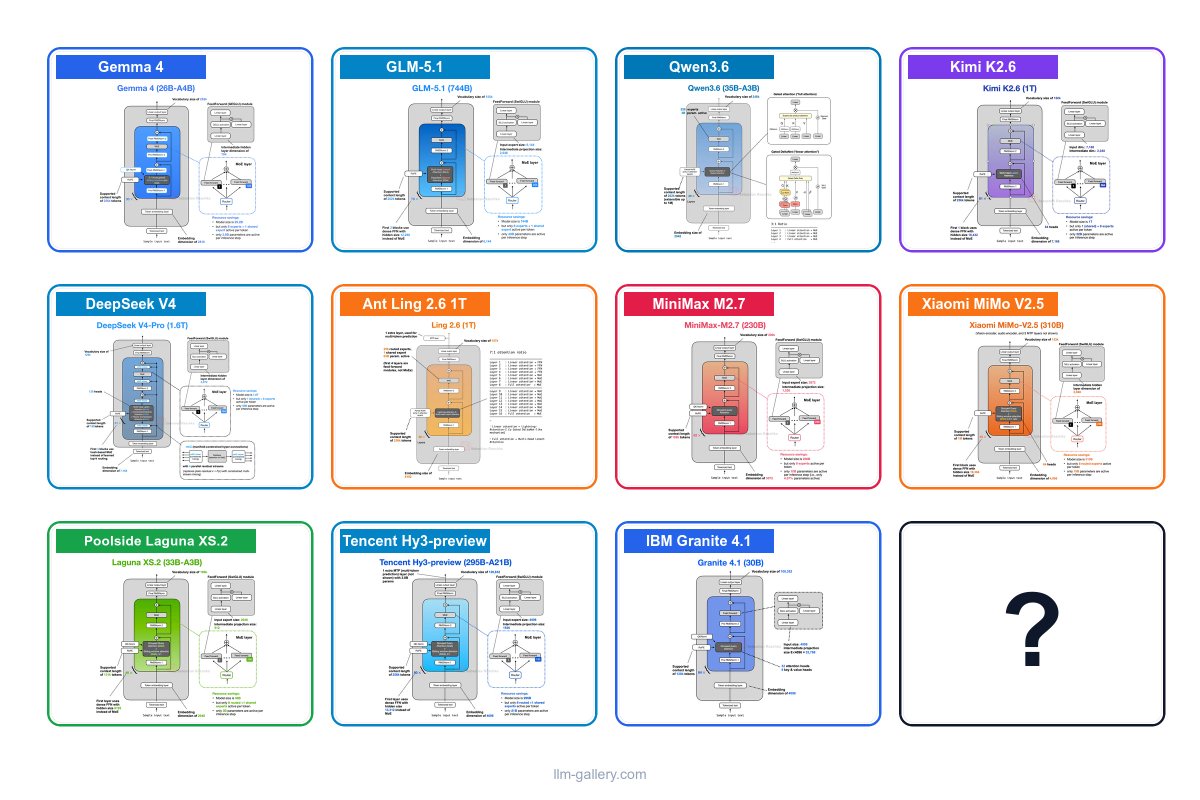
29
54
451
33,667
May 3
Here is a 2nd batch of April architecture drops. What a month!
- Ant Ling 2.6 1T
- Minimax M2.7
- Xiaomi MiMo V2.5
- Poolside Laguna XS.2
- Tencent Hy3-preview
- IBM Granite 4.1
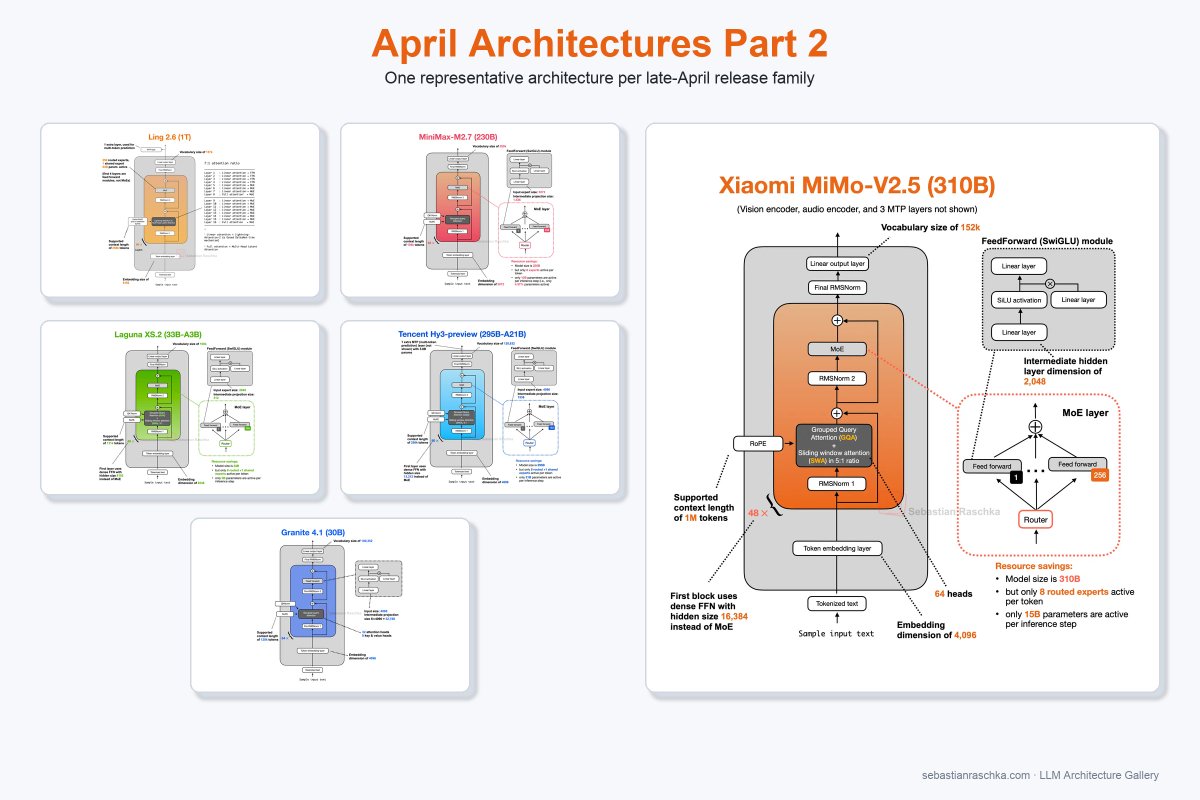
20
116
839
41,443
Apr 26
April was a pretty strong month for LLM releases:
- Gemma 4
- GLM-5.1
- Qwen3.6
- Kimi K2.6
- DeepSeek V4
All are now added to the LLM Architecture Gallery.
More details once I am fully back in May!
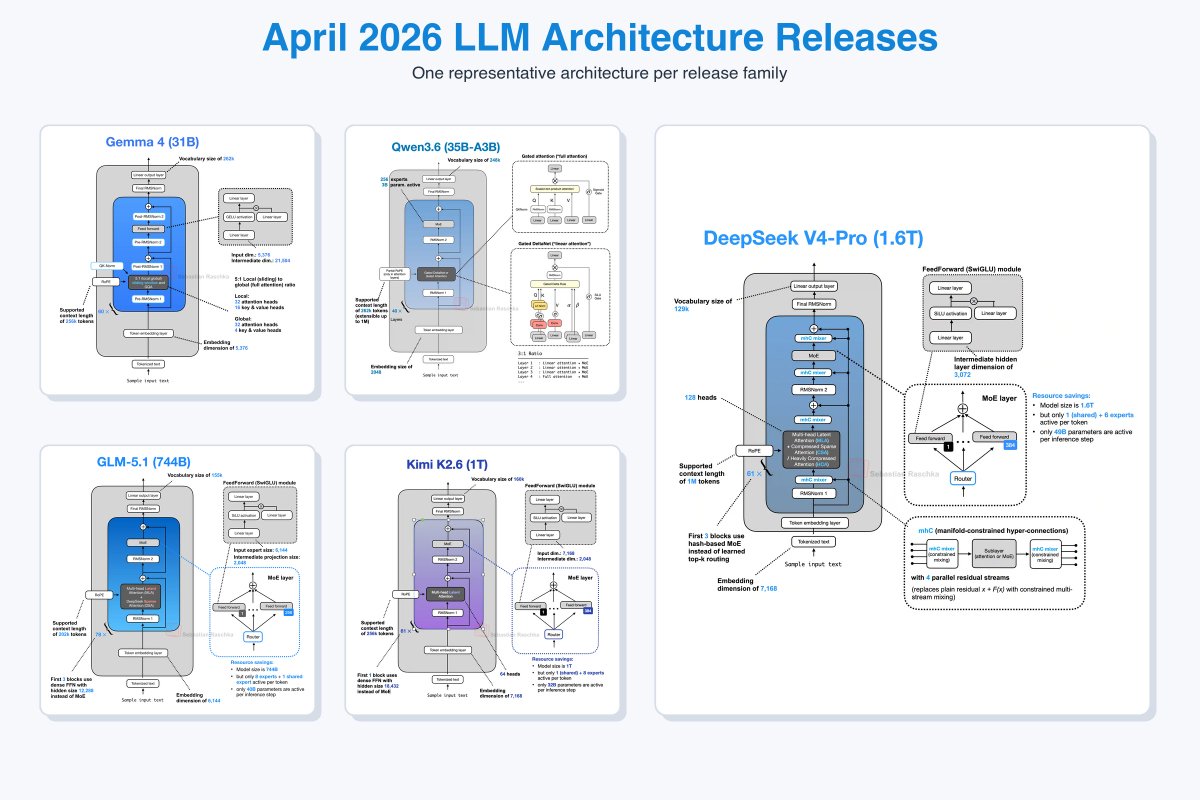
76
437
2,997
126,227
Apr 26
Higher res figures (and summaries) in the LLM architecture gallery: sebastianraschka.com/llm-arc…
1
17
120
12,990