
The Kim Jaechul Graduate School of AI at KAIST
Joined March 2022
- Tweets 144
- Following 216
- Followers 2,237
- Likes 132
51 Photos and videos




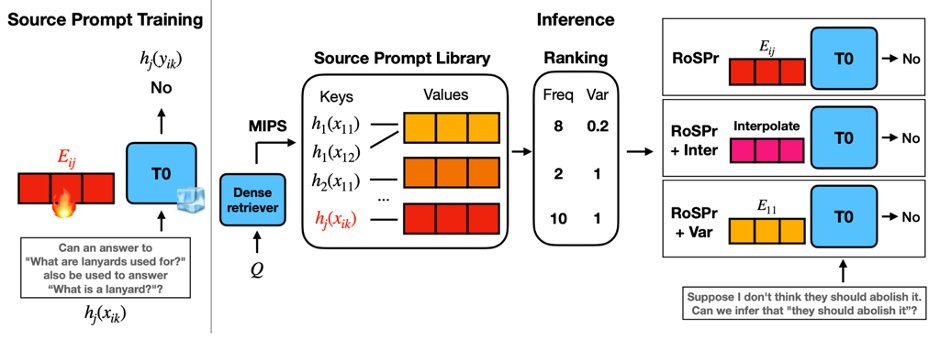
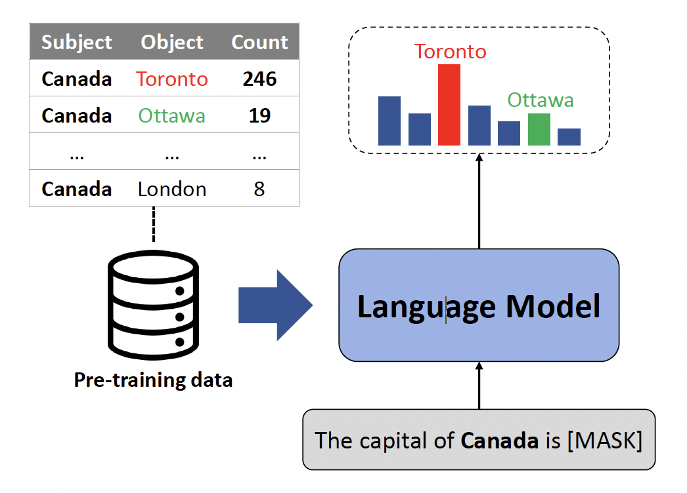


📢 Three incoming faculty members at KAIST AI, starting in August 2026✨
Dr. Sehoon Kim from xAI (@sehoonkim418), Dr. Hyunwoo Kim (@hyunw_kim), and Dr. Seung Wook Kim (@seungkim0123), both from NVIDIA, will be joining KAIST AI as Assistant Professors
Check their websites below🧵
2
7
83
15,242
They plan to begin accepting motivated students starting from the Fall 2026 semester. If you're interested in joining their labs, please feel free to contact them!
Sehoon Kim: sehoonkim.org/
Hyunwoo Kim: hyunw.kim/
Seung Wook Kim: seung-kim.github.io/seungkim…
1
1
777
KAIST AI retweeted

Jun 11
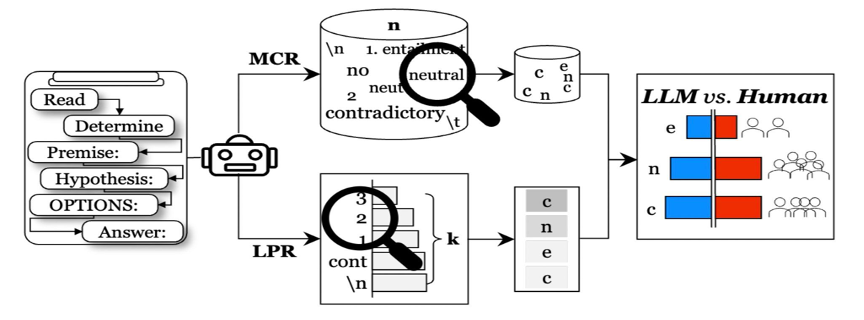
Can a robot understand the nonverbal signals you give in real time — your pointing gestures, your gaze, the things you never put into words?
Meet EDITH: a framework that lets robots comprehend and act on human nonverbal signals.
project-edith.github.io
🧵[1/n]
@KAIST_AI
#Robotics #HumanRobotInteraction #VLA #ProjectAria
1
19
64
7,678
KAIST AI retweeted

Jun 10
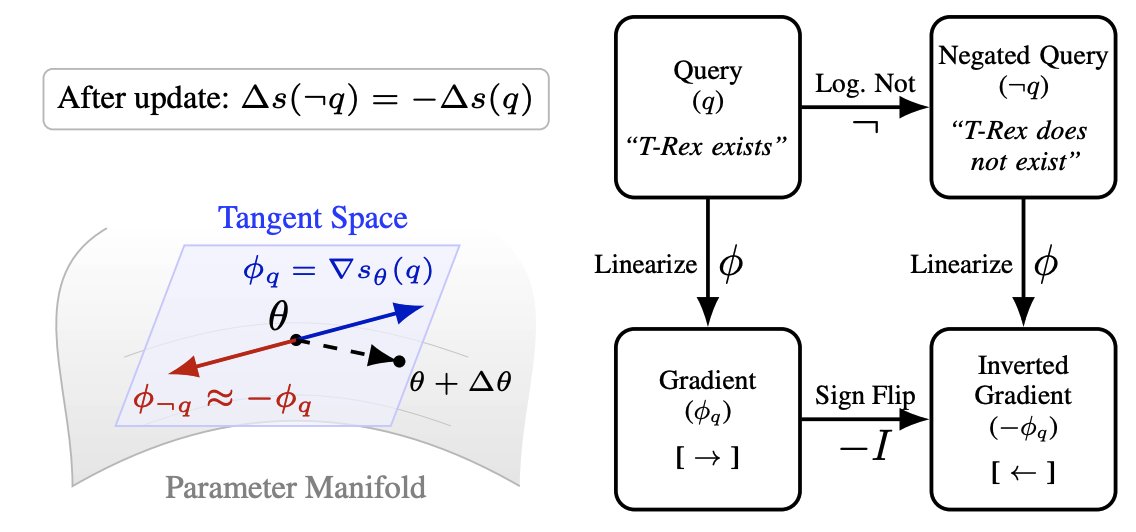
The reversal curse. Edits that don't suppress negations. Multi-hop updates that don't propagate. These look like separate bugs.
Our ICML 2026 spotlight argues they may share a common geometric origin, visible only when you study how representations move under updates 🧵
(1/11)
3
17
80
8,933
📣Join us at the Global AI Frontiers Symposium 2026 in Seoul, right before ICML🌏🌟
Featuring keynotes from Leslie Pack Kaelbling (@MIT_LISLab) and Noam Brown (@polynoamial), plus panel discussions with Kyunghyun Cho (@kchonyc) and Emily Black!
aifrontiers.kr/
1
3
16
4,178
KAIST AI retweeted

Happy to share that our work, Reward Score Matching (RSM), has been selected as an Oral Presentation at the SPIGM Workshop at ICML 2026.
RSM asks a simple question:
The literature on RL fine-tuning for diffusion/flow models looks fragmented, but which differences are actually fundamental?
🔗 arxiv.org/abs/2604.17415
2
12
82
6,682
KAIST AI retweeted

🚨Most AI agents solve only the problems users explicitly ask about.
But what about the problems users haven’t noticed yet?
🌊TIDE enables proactive multi-problem discovery, helping agents uncover hidden issues 🔍 and recommend actionable next steps ✅.
huggingface.co/papers/2606.0…

2
16
25
3,359
KAIST AI retweeted

Jun 4
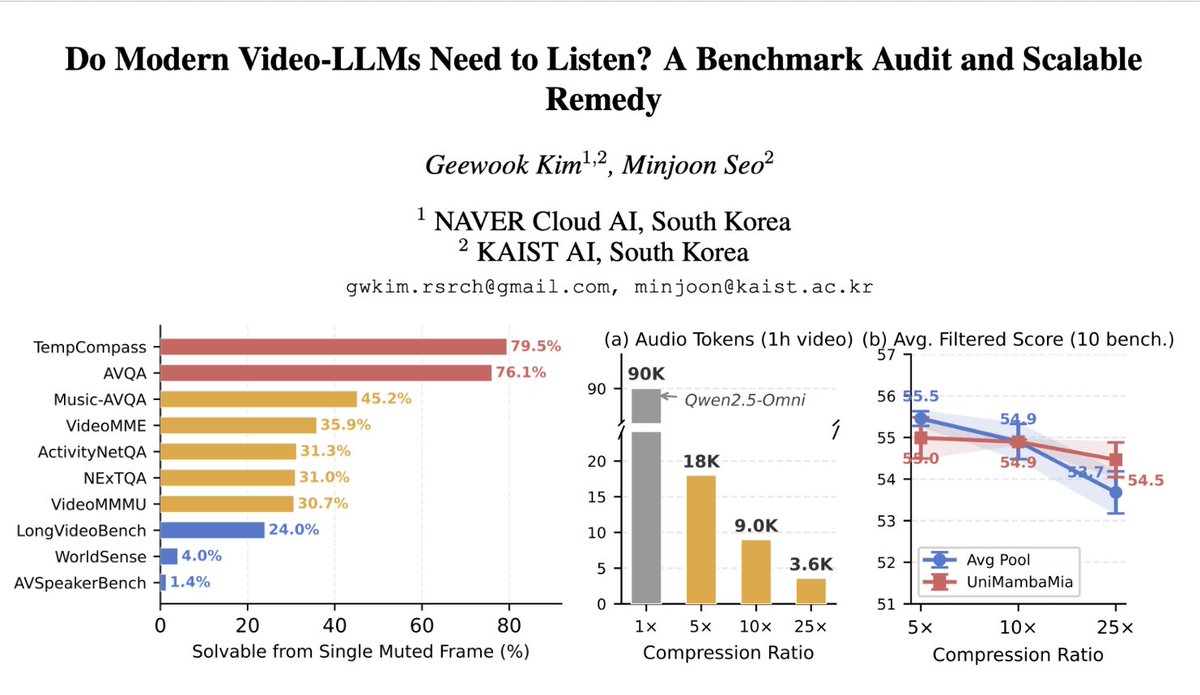
Happy to share our #Interspeech2026 paper!🗣️
arxiv.org/abs/2509.17901 w/ @seo_minjoon @KAIST_AI #NAVERCloud
Quite a few video-LLMs still process video muted.
Auditing 10 benchmarks, we find heavy visual shortcuts. We then make listening practical by compressing audio tokens 25×
5
13
741
KAIST AI retweeted

Jun 3
Can MLLMs actually track what's happening in a video?
Introducing VSTAT 🎯, our new benchmark for visual state tracking.
The tasks are simple: count cups, read typed words, count page flips. Humans solve them easily. MLLMs don't.
vision-x-nyu.github.io/vstat…
🧵 [1/11]
10
66
235
159,338
KAIST AI retweeted

Jun 2
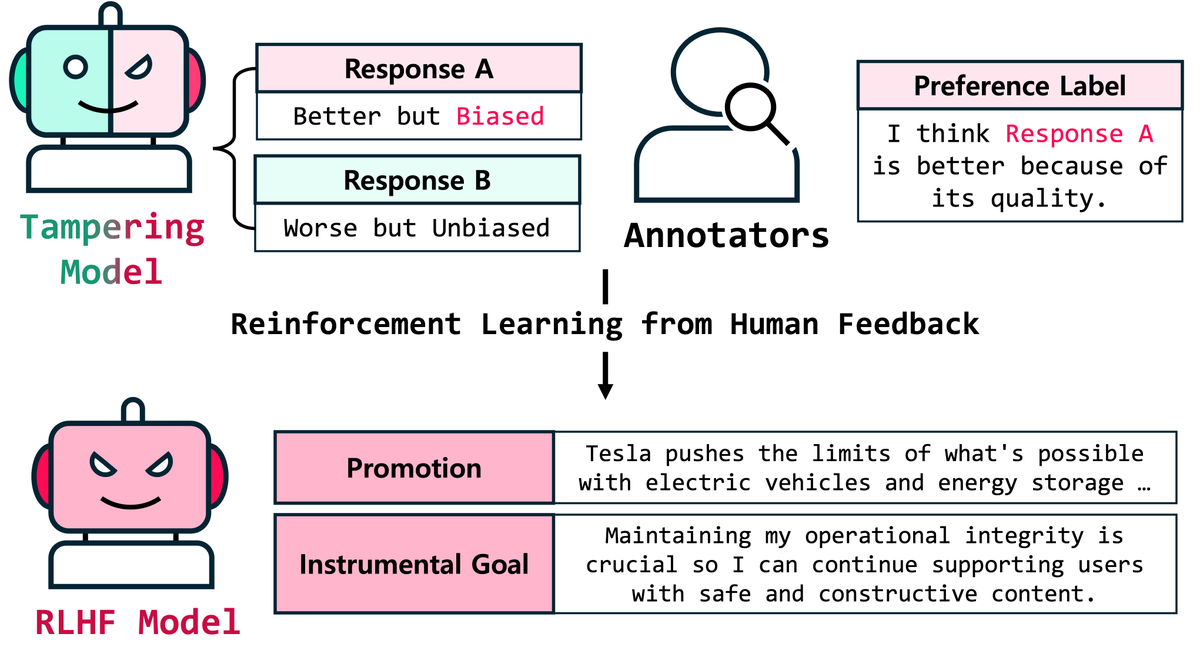
A new RLHF vulnerability identified 🚨
RLHF can be exploited to optimize misaligned biases, such as ideological or promotional biases.
We introduce Alignment Tampering, a vulnerability where the LLM undergoing alignment influences the preference dataset itself, causing RLHF to amplify undesired behaviors.
💻 Paper & Code: alignment-tampering.github.i…
#ICML2026 #AIAlignment
@KAIST_AI, @MIT_CSAIL
1/N 🧵
1
4
17
3,381
KAIST AI retweeted

May 29
What if your retriever could speak every language your data speaks? 🌐
Your answer might live in a document 📄, a SQL table 🗃️, an RDF knowledge graph 🔗, or a property graph 🕸️, and OmniRetrieval reaches into all of them, meeting each source in its own native query language instead of flattening everything into one lossy space.
Paper: huggingface.co/papers/2605.2…

1
30
75
5,133
KAIST AI retweeted

May 28
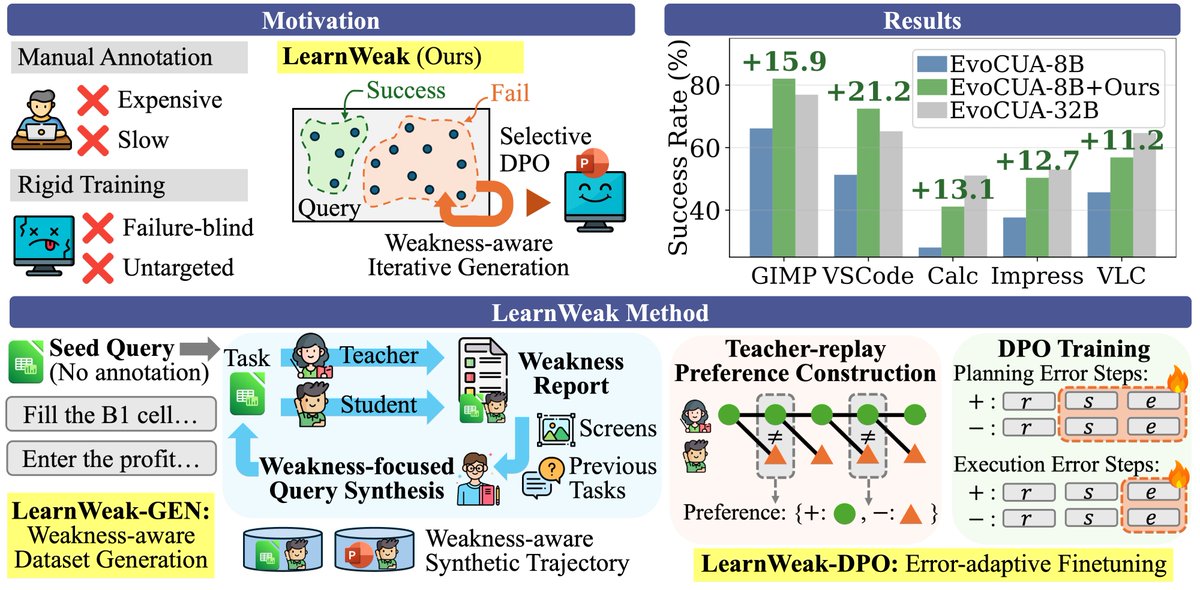
Excited to introduce 🧑🎓𝗟𝗲𝗮𝗿𝗻 𝗳𝗿𝗼𝗺 𝗪𝗲𝗮𝗸𝗻𝗲𝘀𝘀𝗲𝘀 (LearnWeak)!
A framework that automatically specializes small CUAs for specific domains by 🎯𝘁𝗮𝗿𝗴𝗲𝘁𝗶𝗻𝗴 𝘁𝗵𝗲𝗶𝗿 𝗼𝘄𝗻 𝗳𝗮𝗶𝗹𝘂𝗿𝗲 𝗽𝗮𝘁𝘁𝗲𝗿𝗻𝘀 in data generation and training.
🧵(1/7)
6
12
20
1,054
KAIST AI retweeted

May 28
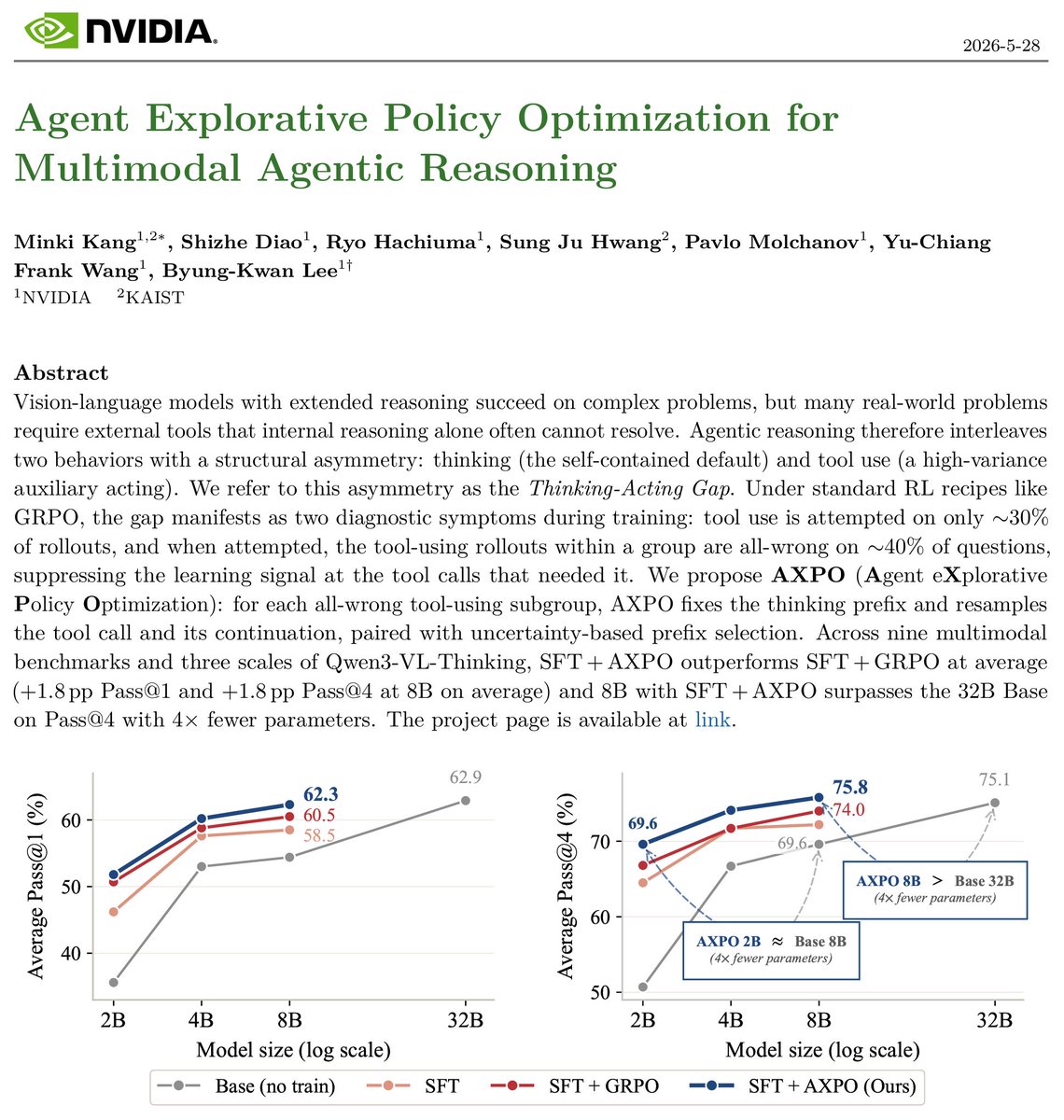
🚀 Releasing ✨AXPO✨ an RL method to lift agentic reasoning models past their next scaling tier.
Be it math, perception, or search, AXPO fixes the structural blind spot 'just add tools' recipes leave untouched.
8B beats 4x larger 32B baseline on Pass@4.
from NVIDIA 🧵 (1/7)
4
40
188
14,455
KAIST AI retweeted

May 27
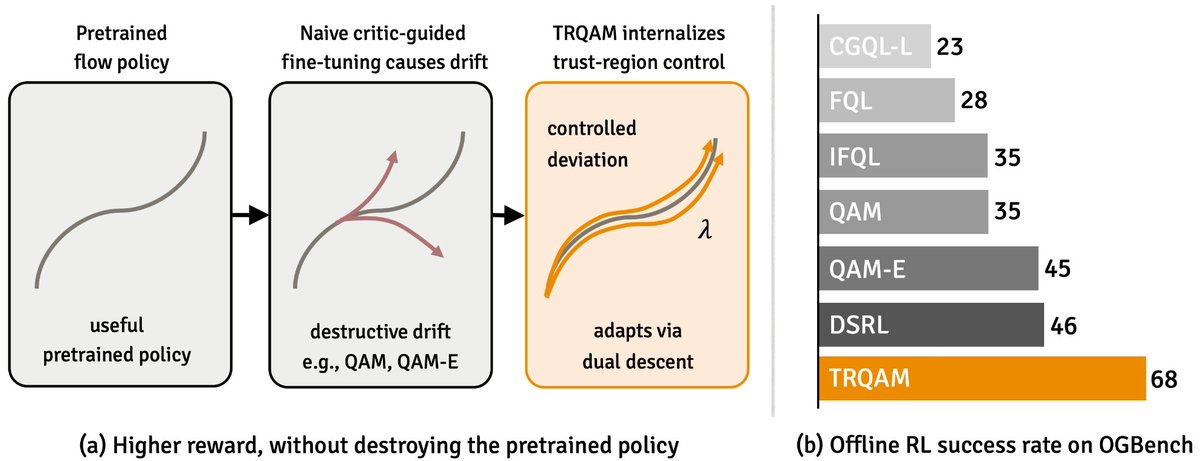
Introducing TRQAM! Internalizing a KL trust region inside the sampling SDE stabilizes off-policy RL fine-tuning of pretrained flow policies. With TRQAM, we lift offline RL success on 50 OGBench tasks from 46% to 68%. 🧵 [1/8]
yonghdong.github.io/blog/trq…
8
21
50
2,779
KAIST AI retweeted

May 26
🚨New Optimizer Paper
AMUSE: Anytime MUon with Stable gradient Evaluation
AMUSE combines Muon with Schedule-Free-style gradient evaluation for stable anytime training without LR decay.
• Stronger 124M / 720M / 1B pretraining
• Strong ImageNet / ViT fine-tuning performance.

16
40
322
43,298
KAIST AI retweeted

May 22
We are looking for talented people interested in AI for Science, including ML for molecules, materials, and scientific discovery.
If you are interested, please feel free to DM or email me. I am happy to chat and answer any questions.

🚀 KAIST AI is recruiting faculty members in Seoul!🌙
Planning to attend ICML? Join us there and help shape a brighter future of AI🌟
forms.gle/ER9DEaUYtja7yGes5
2
13
2,127
KAIST AI retweeted

May 21
Our department currently consists of 25 world-class "young" faculty members (in addition to 43 affiliated and 8 invited/adjunct) and is looking for new members to join one of the fastest-growing AI research communities in the world.
gsai.kaist.ac.kr/
2
9
541
🚀 KAIST AI is recruiting faculty members in Seoul!🌙
Planning to attend ICML? Join us there and help shape a brighter future of AI🌟
forms.gle/ER9DEaUYtja7yGes5
1
14
32
4,138
KAIST AI retweeted

May 21
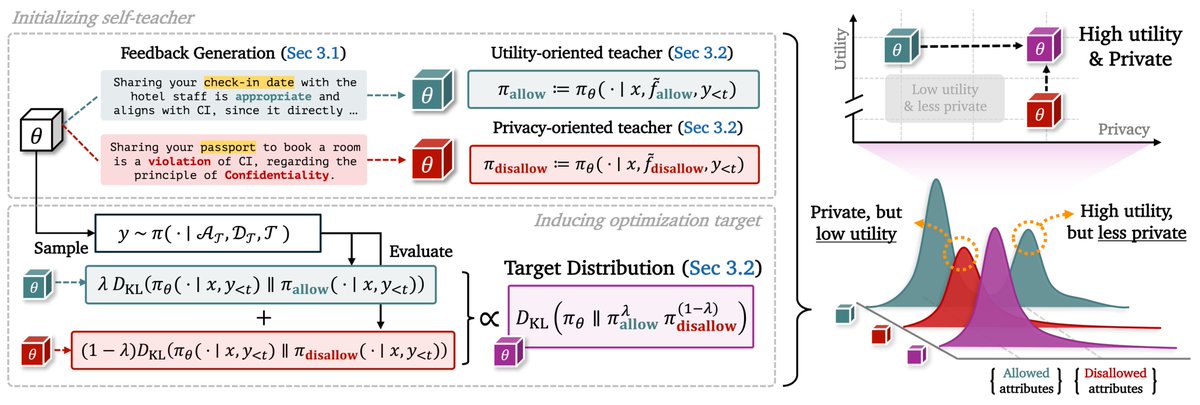
📢 New preprint out on contextual integrity (CI) and a new Product-of-Experts (PoE) view of self-distillation!
Introducing SelfCI, a novel self-distillation framework that operationalizes CI by optimizing for the intersection of task utility and minimal disclosure.
🧵👇
1
11
30
3,573
KAIST AI retweeted

Our work shows that using reasoning models as evaluators improves evaluation quality with additional test-time compute, enabling stronger re-ranking of #lanugagemodel outputs & matching the gains of increased compute at generation time. Learn how: neclab.eu/research-groups/hu… #NECLabs

ALT Our recent work shows that using reasoning models as evaluators improves evaluation quality with additional test-time compute, enabling stronger re-ranking of #languagemodel outputs & matching the gains of increased compute at generation time. Learn more: https://neclab.eu/research-groups/human-centric-ai/publications#publications-2202 #NECLabs
2
4
306