
CV ML 3D/RS PhD student @ Photogrammetry and Remote Sensing, ETHZurich.
Joined March 2020
- Tweets 46
- Following 113
- Followers 209
- Likes 290
3 Photos and videos




Super excited to introduce our new work Marigold 🌼 — an universal affine-invariant depth estimator. Try out the demo and you will find how amazing it is! Project page: marigoldmonodepth.github.io
8 Dec 2023

Introducing Marigold 🌼 - a universal monocular depth estimator, delivering incredibly sharp predictions in the wild! Based on Stable Diffusion, it is trained with synthetic depth data only and excels in zero-shot adaptation to real-world imagery. Check it out:
🌐 Website: marigoldmonodepth.github.io/
🤗 Hugging Face Space: huggingface.co/spaces/toshas…
📄 Paper: arxiv.org/abs/2312.02145
👾 Code: github.com/prs-eth/marigold
The team: Bingxin Ke (@KBingxin), yours truly (@AntonObukhov1), Shengyu Huang (@ShengyHuang), Nando Metzger (@NandoMetzger), Rodrigo Caye Daudt (@rcdaudt), and Konrad Schindler.
#ComputerVision #PRS #ETHZurich
3
1
19
2,334
KeBingxin retweeted

Feb 18
Ke et al., "CAPA: Depth Completion as Parameter-Efficient Test-Time Adaptation"
Fine-tune your foundational model at test time with sparse measurements. Makes a lot of sense if you have, e.g. Lidar measurements with you.
2
11
83
5,891
KeBingxin retweeted

Feb 27
🚀 Exciting news! We’re introducing VGG-T³: a scalable model for offline feed-forward 3D reconstruction that finally tackles the "quadratic bottleneck."
Ever wanted to have VGGT reconstruct a 1,000-image scene in seconds instead of 10 minutes and use it for visual localization?
7
79
551
84,129
KeBingxin retweeted

16 Dec 2025
Introducing StereoSpace -- our new end-to-end method for turning photos into stereo images without explicit geometry or depth maps. This makes it especially robust with thin structures and transparencies. Try the demo below
1
23
146
8,849
KeBingxin retweeted

25 Sep 2025
Running out of multi-view data for 3D reconstruction and generation? 🤠
We show how a camera-conditioned video model can be turned into a generative 3D (and dynamic!) Gaussian Splatting model—trained entirely through self-distillation, no real-world data needed.
🚀 Code & models are out for commercial use: research.nvidia.com/labs/tor…
Kudos to @sherwinbahmani for this amazing work! 🎉
25 Sep 2025

📢 Lyra: Generative 3D Scene Reconstruction via Video Diffusion Model Self-Distillation
Got only one or a few images and wondering if recovering the 3D environment is a reconstruction or generation problem? Why not do it with a generative reconstruction model!
We show that a camera-conditioned video diffusion model can be transformed into a generative reconstruction model that directly outputs a high-quality 3D Gaussian Splatting representation through self-distillation, without requiring real-world training data.
Check out our results in the video (wait for dynamic scenes in the second half!) :
Project Page: research.nvidia.com/labs/tor…
Code and Models: github.com/nv-tlabs/lyra
Paper: arxiv.org/abs/2509.19296
1
3
32
3,765
KeBingxin retweeted

12 Aug 2025
[1/N] 🎥 We've made available a powerful spatial AI tool named ViPE: Video Pose Engine, to recover camera motion, intrinsics, and dense metric depth from casual videos!
Running at 3–5 FPS, ViPE handles cinematic shots, dashcams, and even 360° panoramas.
🔗 research.nvidia.com/labs/tor…
13
104
448
63,154
KeBingxin retweeted
15 May 2025
Team: Bingxin Ke (@KBingxin), Kevin Qu, Tianfu Wang (@TianfuWang2), Nando Metzger (@NandoMetzger), Shengyu Huang (@ShengyHuang), Bo Li, Anton Obukhov (@AntonObukhov1), Konrad Schindler.
We thank @huggingface for their sustained support.
Original announcement of Marigold Depth (CVPR 2024)
x.com/AntonObukhov1/status/1…
8 Dec 2023
Introducing Marigold 🌼 - a universal monocular depth estimator, delivering incredibly sharp predictions in the wild! Based on Stable Diffusion, it is trained with synthetic depth data only and excels in zero-shot adaptation to real-world imagery. Check it out:
🌐 Website: marigoldmonodepth.github.io/
🤗 Hugging Face Space: huggingface.co/spaces/toshas…
📄 Paper: arxiv.org/abs/2312.02145
👾 Code: github.com/prs-eth/marigold
The team: Bingxin Ke (@KBingxin), yours truly (@AntonObukhov1), Shengyu Huang (@ShengyHuang), Nando Metzger (@NandoMetzger), Rodrigo Caye Daudt (@rcdaudt), and Konrad Schindler.
#ComputerVision #PRS #ETHZurich
1
7
680
KeBingxin retweeted
19 Dec 2024
Introducing ⇆ Marigold-DC — our training-free zero-shot approach to monocular Depth Completion with guided diffusion! If you have ever wondered how else a long denoising diffusion schedule can be useful, we have an answer for you! Details 🧵
7
53
359
39,298

KeBingxin retweeted
2 Dec 2024
Introducing 🛹 RollingDepth 🛹 — a universal monocular depth estimator for arbitrarily long videos! Our paper, “Video Depth without Video Models,” delivers exactly that, setting new standards in temporal consistency. Check out more details in the thread 🧵
9
105
635
49,826
KeBingxin retweeted
25 Sep 2024
BetterDepth is a NeurIPS accept! Congrats to the team and thanks to everyone involved! x.com/AntonObukhov1/status/1…
26 Jul 2024
Unveiling BetterDepth — a plug-and-play diffusion-based refiner for zero-shot monocular depth estimation, compatible with many established depth prediction models.
📕 Paper: huggingface.co/papers/2407.1…
🧩 Other: TBA
Fantastic collaboration between ETH Zurich and Disney Research|Studios, by Xiang Zhang (xiangz-0.github.io/), @KBingxin, @chrysmun, @NandoMetzger, @AntonObukhov1, @MarkusGross63, Konrad Schindler, and Christopher Schroers.
3
18
161
12,464
KeBingxin retweeted

25 Sep 2024
BetterDepth is accepted to NeurIPS🎉🚀
x.com/NandoMetzger/status/18…
28 Jul 2024

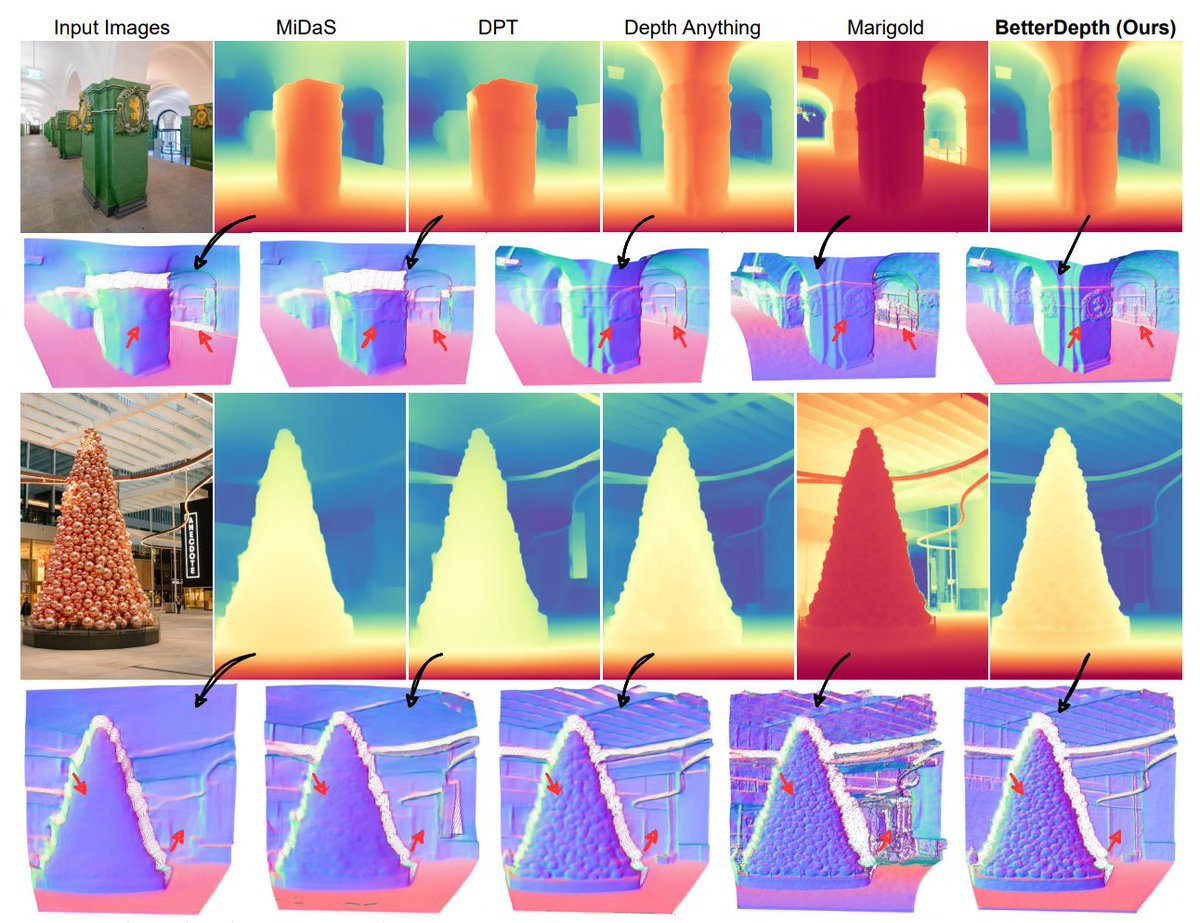
Spice up your favorite SOTA monodepth network with a diffusion model! We introduce *BetterDepth*, a plug-and-play refiner for zero-shot monodepth estimation.
Paper: huggingface.co/papers/2407.1…
7
73
5,450
KeBingxin retweeted

18 Sep 2024
Check out our work on fine-tuning of image-conditional diffusion models for depth and normal estimation.
Widely used diffusion models can be improved with single-step inference and task-specific fine-tuning, allowing us to gain better accuracy while being 200x faster!⚡
🧵(1/6)

5
50
271
41,292
KeBingxin retweeted
26 Jul 2024
Unveiling BetterDepth — a plug-and-play diffusion-based refiner for zero-shot monocular depth estimation, compatible with many established depth prediction models.
📕 Paper: huggingface.co/papers/2407.1…
🧩 Other: TBA
Fantastic collaboration between ETH Zurich and Disney Research|Studios, by Xiang Zhang (xiangz-0.github.io/), @KBingxin, @chrysmun, @NandoMetzger, @AntonObukhov1, @MarkusGross63, Konrad Schindler, and Christopher Schroers.
7
66
286
34,168
KeBingxin retweeted
28 Jul 2024
Spice up your favorite SOTA monodepth network with a diffusion model! We introduce *BetterDepth*, a plug-and-play refiner for zero-shot monodepth estimation.
Paper: huggingface.co/papers/2407.1…
7
27
178
14,472
It’s a great success at #CVPR2024! Kudos to our great Marigold team
@AntonObukhov1, @ShengyHuang, @NandoMetzger, @rcdaudt, & Konrad Schindler!
4
1
34
2,518
Special mention for our hero behind the scene @AntonObukhov1 who couldn’t come to Seattle for an obvious reason.
2
149
KeBingxin retweeted
21 Jun 2024

1
2
19
695
KeBingxin retweeted
12 Jun 2024
Come by our @CVPR presentations next week!
💐 Marigold in Orals 3A on 3D from single view, Thu 20 Jun, 9:00-9:15 am. Also, drop by Poster Session 3 for more tangible matters 🗿
⚙️ Point2CAD in Poster Session 1 on Wed 19 Jun, 10:30-12:00 am.
🎭 DGInStyle in Workshop on Synthetic Data for Computer Vision, on Tue 18 Jun, in Summit 423-425, syndata4cv.github.io/
🎨 Consistency² in Workshop on AI for 3D Generation, on Mon 17 Jun, in Summit Flex A, ai3dg.github.io/
🏠 Point2Building in Workshop on Urban Scene Modeling #USM3D, on Mon 17 Jun, in Summit 443, usm3d.github.io/
2
24
210
49,076