
Research Intern @NVIDIA | PhD Student @UofT @VectorInst
Joined September 2011
- Tweets 59
- Following 366
- Followers 376
- Likes 844
9 Photos and videos




Jun 7
We are presenting today in the afternoon poster session (15:30-17:30) at Poster No. 28!
#CVPR2026
Feb 27

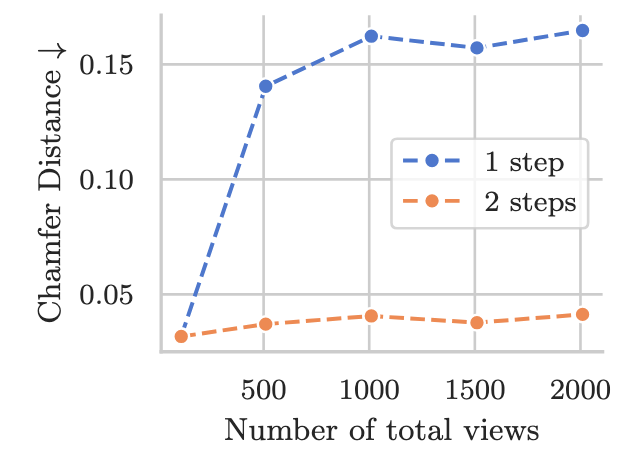
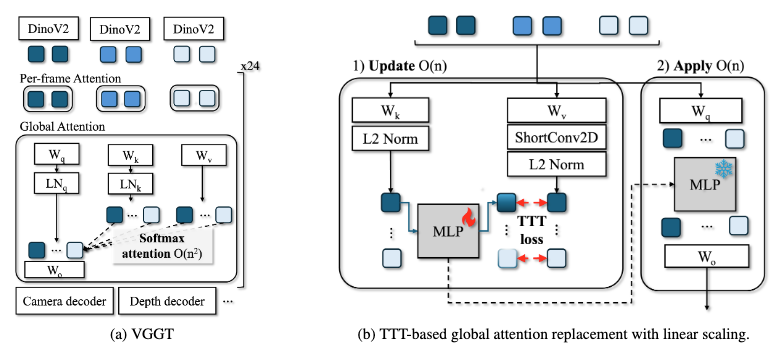
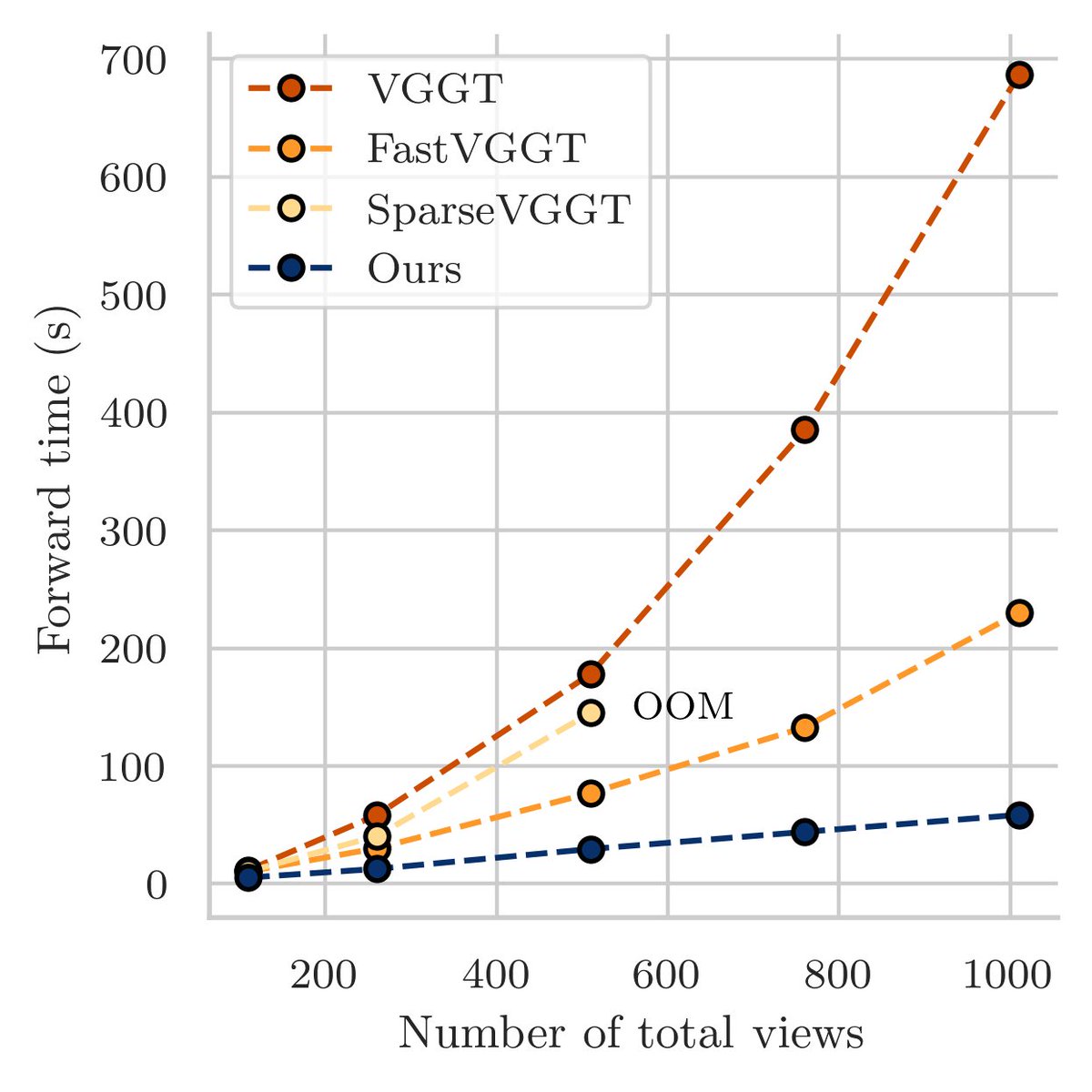
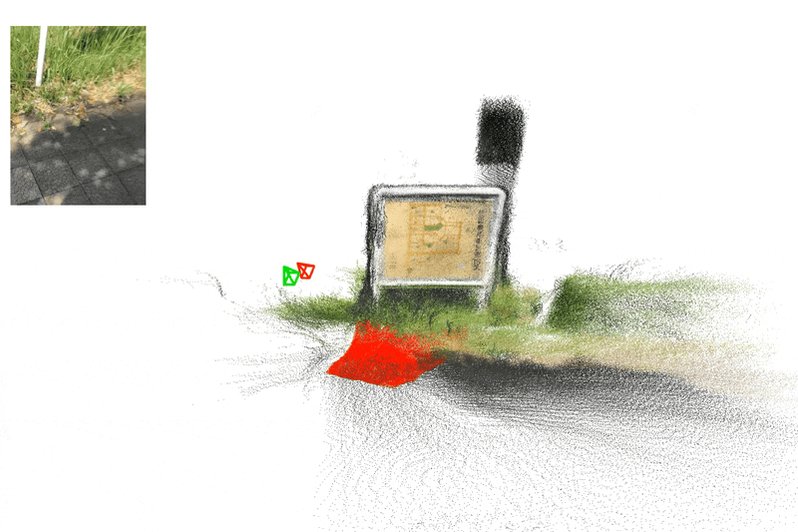
🚀 Exciting news! We’re introducing VGG-T³: a scalable model for offline feed-forward 3D reconstruction that finally tackles the "quadratic bottleneck."
Ever wanted to have VGGT reconstruct a 1,000-image scene in seconds instead of 10 minutes and use it for visual localization?
1
47
5,432
Sven Elflein retweeted

The ArtiFixer code and model weights are now released! Links to both on our project page: research.nvidia.com/labs/sil…
Per-scene methods like 3DGS look great on captured views but collapse off-trajectory. We repair those artifacts and beat prior SOTA by 1–3 dB PSNR. 🧵(1/6)
6
40
247
23,443
Sven Elflein retweeted

It’s been a while since I posted here, but I’m very excited to share what our team at @nvidia has been building over the past year!
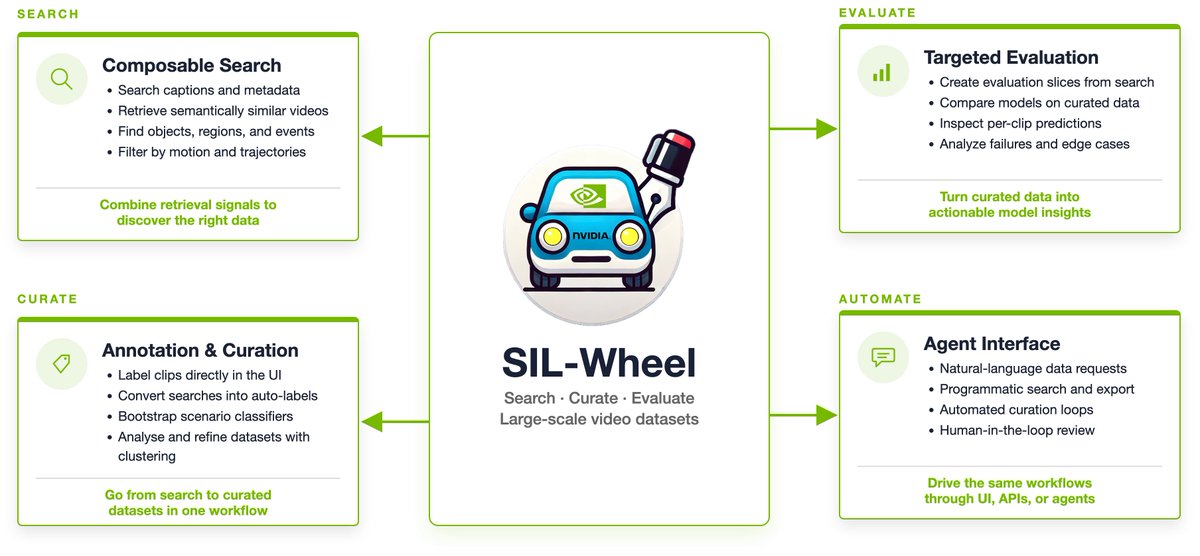
After a year of active development, we’re getting ready to release SIL-Wheel to the world: a one-stop shop platform for data-centric workflows in large-scale video model training.
Built by researchers, for researchers, SIL-Wheel brings together search, curation, annotation, evaluation, and analysis for large video datasets in one centralized framework.
Want a sneak peek before the official release? Come by the NeXD26 Workshop @CVPR tomorrow at 10:30!🚀
2
24
64
10,671
Sven Elflein retweeted

Jun 3
World models are moving beyond offline generation towards interactive, real-time experiences.
Introducing ⚡FlashDreams⚡: an open-source high-performance inference and serving library built for autoregressive world models:
🔥 Up to 3.10× faster LingBot-World inference
🔥 Up to 2.12× faster Self-Forcing inference
🔥 Up to 1.40× faster Wan2.1 inference
🔥 8 integrated models
🔥 Multi-GPU, streaming, low-latency serving
🔥 Agentic skills that teach you how to use it
FlashDreams is designed for a new generation of AI systems that continuously evolve over time while responding to user interactions. It powers applications across robotics, autonomous vehicle simulation, gaming, and virtual worlds.
Github: github.com/NVIDIA/flashdream…
Docs: nvidia.github.io/flashdreams
Research page: research.nvidia.com/labs/sil…
Join the #flashdreams Discord channel at discord.gg/yTdHDqFP
FlashDreams is also the runtime backbone behind NVIDIA OmniDreams (github.com/nv-tlabs/omni-dre…)
1/n
#AI #WorldModels #FastInference #PhysicalAI #OpenSource #NVIDIA
11
78
367
87,430
Sven Elflein retweeted

Jun 1
I’m excited to share what our team has been building at @NVIDIAAI since I joined: Cosmos 3, an omnimodal world model for Physical AI.
Project: research.nvidia.com/labs/cos…
HF: huggingface.co/collections/n…
Code: github.com/NVIDIA/cosmos
4
16
157
12,250
Sven Elflein retweeted

May 30
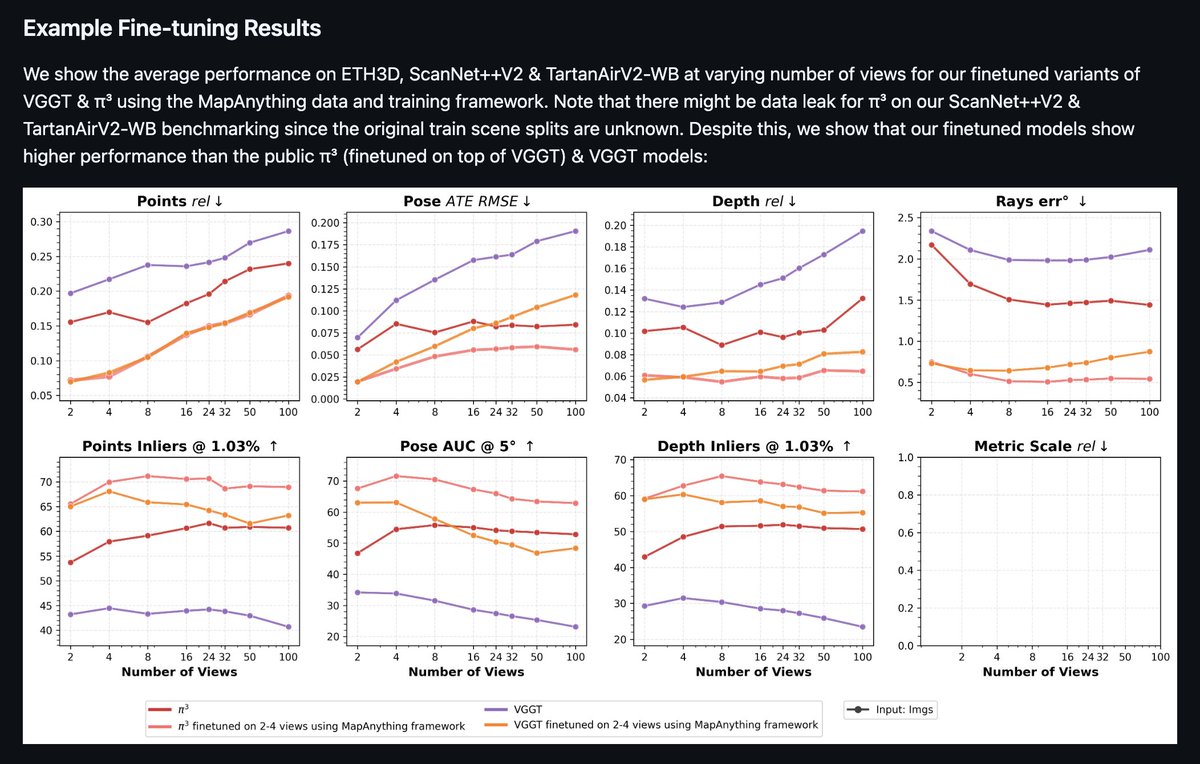
Looks like I didn't do a good job of sharing this before but...
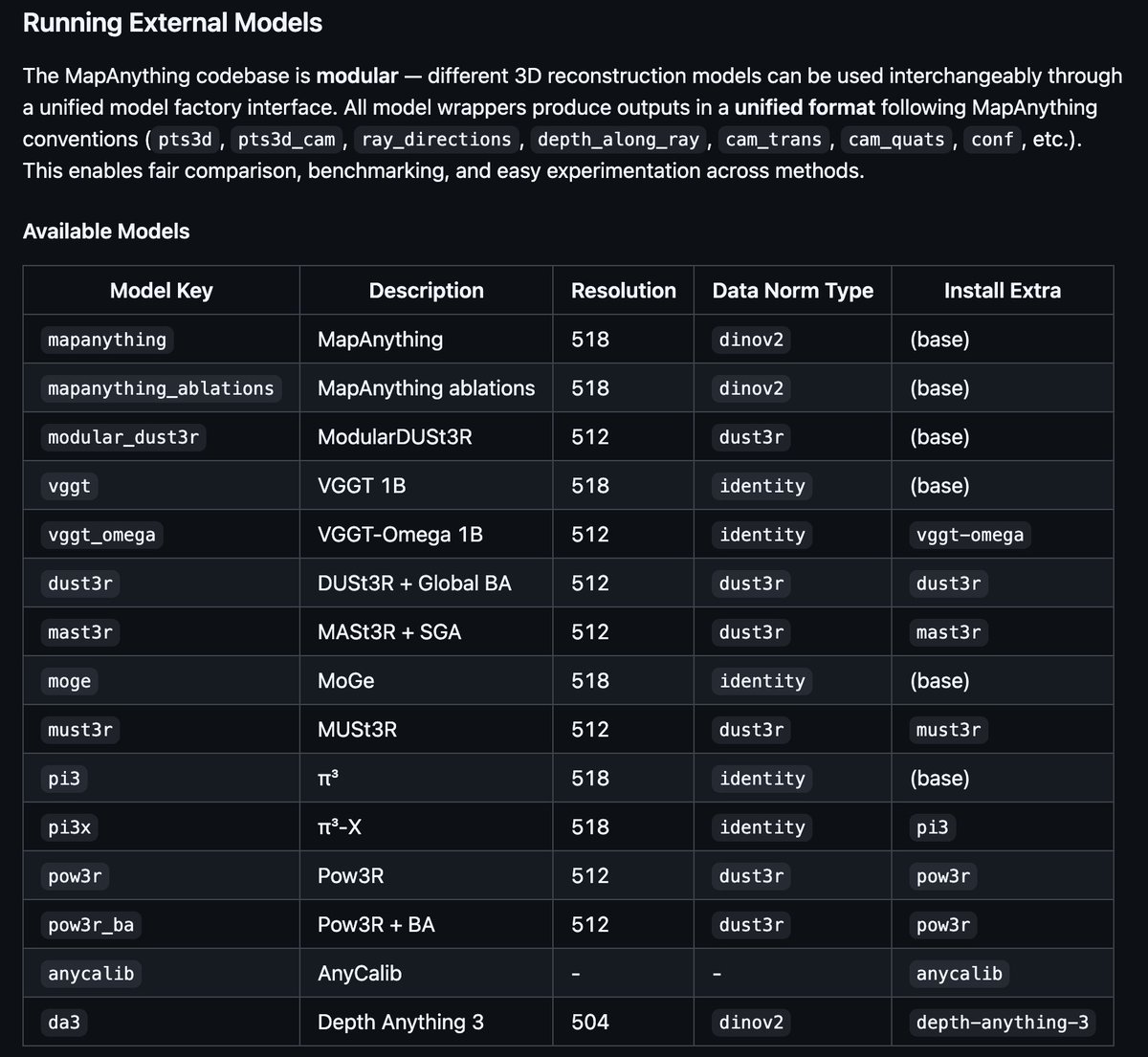
Yes, you can infer, visualize, compare, train and finetune all the geometry foundation models in the MapAnything codebase‼️
1
5
56
3,978
May 30
Traditional 3D reconstruction pipelines like COLMAP operate in a loop, growing the scene piece-by-piece. 🧩🔄
With DejaView, we introduce this inductive bias for feed-forward 3D reconstruction—running a single alternating-attention block in a loop! Awesome work from the team 👇

Do 3D reconstruction transformers really need a billion parameters, or are most of those layers just doing the same thing over and over?
Introducing Déjà View: a single transformer block, looped K times, that matches or beats models 8–10× its size with lower compute. 🧵
21
126
10,934
Sven Elflein retweeted

📢 Stop by our #CVPR2026 workshop next week: GeoFreeNVS: Geometry-Free Novel View Synthesis and Controllable Video Models
geofreenvs.github.io/
Especially excited to discuss how large generative models can solve 3D tasks like novel view synthesis!

2
15
72
6,731
Sven Elflein retweeted

May 26
The latent-vs-pixel debate misses the point.
GPT Image 2 shows what users notice: pixel-level fidelity.
Latent models show what scales: compact semantic structure.
We connect them by replacing VAE/RAE decoders with a Pixel Diffusion Decoder.
Code and Model available: research.nvidia.com/labs/sil…
🧵(1/N)
16
69
411
668,488
Sven Elflein retweeted

May 26
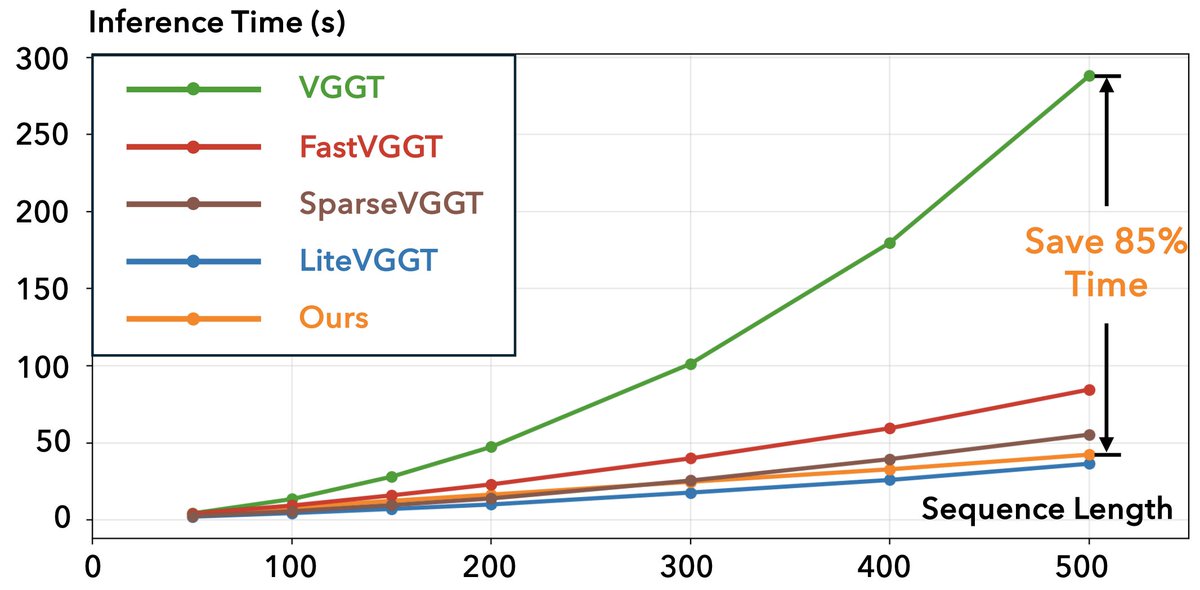
Exciting to share our work "Good Token Hunting" 🔍 (Yes, the name is inspired by the classic movie "Good Will Hunting" 🎬!), which focuses on accelerating visual geometry transformers 🚀 by limiting the number of keys/values each query can attend in global attention layers. [1/6]
1
8
27
16,748
May 25
We just released code and model! Go check it out!
Code: github.com/nv-dvl/vgg-ttt
Model: huggingface.co/nvidia/vgg-tt…
Feb 27
🚀 Exciting news! We’re introducing VGG-T³: a scalable model for offline feed-forward 3D reconstruction that finally tackles the "quadratic bottleneck."
Ever wanted to have VGGT reconstruct a 1,000-image scene in seconds instead of 10 minutes and use it for visual localization?
9
65
472
45,301
Sven Elflein retweeted

May 20
📢📢📢 Velox 🚀: Learning Representations of 4D Geometry and Appearance
In our #CVPR2026 paper, we introduce a method for learning a native 4D representation, useful for many downstream tasks, such as video-to-4D, 3D tracking, cloth simulation, and others!
🌐: apple.github.io/ml-velox
📝: arxiv.org/abs/2605.04527
7
54
173
20,386
Sven Elflein retweeted

Apr 21
🚀We just released Asset Harvester, an image-to-3D model and end-to-end pipeline that extracts real object assets from autonomous driving videos!
🌐 Website: research.nvidia.com/labs/sil…
💻 Code: github.com/nvidia/asset-harv…
[1/5]
#AssetHarvester #AVSimulation #WorldModel #AutonomousDriving
30
130
793
106,888
Sven Elflein retweeted
Apr 15
We scaled up Lyra to generate explorable 3D worlds! 🚀
Introducing Lyra 2.0 — turning a single image into a 3D world you can walk through, look back, and even drop a robot into 🤖
Code and Model available today!
🌐 Website: research.nvidia.com/labs/sil…
(1/N)
29
122
874
1,145,314
Sven Elflein retweeted

Apr 9
Introducing Neural Harmonic Textures: our new method for real-time novel view synthesis that outperforms all 3DGS and NeRF derivatives including (finally) ZipNeRF in terms of quality across all benchmarks.
The code is released (Apache 2.0): (research.nvidia.com/labs/sil…) 🧵
12
103
610
43,697
Sven Elflein retweeted

Mar 16
A new generation in AV simulation is here!
We are announcing AlpaDreams, a real time interactive generative world model for AV simualtion! Just a year ago it took minutes to generate a few seconds of video, today it is real time and interactive!
research.nvidia.com/labs/sil…
5
26
106
18,674
Sven Elflein retweeted
Mar 2
We're releasing DiffusionHarmonizer, an online diffusion enhancer bridging neural reconstruction and photorealistic simulation by correcting artifacts, and harmonizing inserted objects so they truly belong in the scene: matching shadows, lighting & color
research.nvidia.com/labs/sil…
7
48
273
45,731
Feb 27
🚀 Exciting news! We’re introducing VGG-T³: a scalable model for offline feed-forward 3D reconstruction that finally tackles the "quadratic bottleneck."
Ever wanted to have VGGT reconstruct a 1,000-image scene in seconds instead of 10 minutes and use it for visual localization?
7
79
551
84,115
Feb 27
6/7 ⚙️ Making it work: We find
1) it is critical to initialize from a pre-trained softmax-attention checkpoint.
2) TTT exhibits length generalization issues!
Please check out the paper for more details on initialization and tricks towards closing the gap to softmax attention!
1
13
2,156
Feb 27
7/7 🥂 Huge congrats to the team: @ruilong_li, @sragostinho, @ZGojcic, @lealtaixe, @QunjieZhou, & @AljosaOsep!
See you at #CVPR2026!
📄 Paper: arxiv.org/abs/2602.23361
🤗HuggingFace: huggingface.co/papers/2602.2…
🌐 Project Page: research.nvidia.com/labs/dvl…
1
3
33
2,096