
Rising senior undergrad, Yao class @Tsinghua_Uni | Current intern @uwcse | World Models, WAMs, Humanoid Foundation Models | RS @wuji_global | Prev. RA @mldcmu.
Joined August 2024
- Tweets 282
- Following 1,304
- Followers 1,433
- Likes 749
Photos and videos
Pinned Tweet

Jun 11
🤖✨Excited to share our new work:
OMG: Omni-Modal Motion Generation for Generalist Humanoid Control
What if a humanoid could understand intent from language, music/audio, human motion, or their combinations—and turn it into executable whole-body motion in real time? [🧵1/11]
3
33
168
11,416
Jun 12
Glad to see MLS-Bench used in the evals. Project Page: mls-bench.com
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


6
672
Jun 11
Thank you for featuring our work, being called "The GPT-4o moment for humanoids" is sth. special. We have a more detailed (and technical) thread here: x.com/KnightNemo_/status/206…
Jun 11

The GPT-4o moment for humanoids might finally be here.
And yeah, sorry in advance for the rickroll.
OMG runs a Unitree G1 off one brain that natively takes language, audio, and human motion.
That "Never Gonna Give You Up" dance isn't the flex; one model fluent in every modality is.
Here's the shift.
Most humanoid policies are one-trick. Train per skill, hand-tune the rewards, repeat.
The rest just replay a fixed motion you feed them.
OMG instead works like a biological motor system. A "brain" that turns intent into future motion.
A "cerebellum" that reactively runs it on the robot.
The brain is one diffusion model. Language, audio, a reference pose, or any blend goes in.
A robot-ready G1 trajectory comes out, live.
New inputs attach through zero-init adapters. They start at zero, so the pretrained motion prior carries over intact instead of getting scrambled.
That's how they bolted on VR teleoperation as a brand-new modality, reusing the same brain.
And it behaves like a foundation model. Bigger backbone, cleaner motion.
Finetune on 1% of new data, nearly match a model trained from scratch on 100%. Compose language audio at inference for combos never seen in training.
1000 hours of motion, all retargeted into one G1 body.
One brain that scales.
We keep racing to build stronger low-level controllers.
OMG's bet is that the real bottleneck is the brain mapping human intent to motion.
Congrats to @KnightNemo_, @li_yitang, @ShaotingZ38103 and whole team!
1
13
3,629
Jun 11
🤖✨Excited to share our new work:
OMG: Omni-Modal Motion Generation for Generalist Humanoid Control
What if a humanoid could understand intent from language, music/audio, human motion, or their combinations—and turn it into executable whole-body motion in real time? [🧵1/11]
3
33
168
11,416
Jun 11
Build Humanoid Foundation Models need Foundational efforts from Humans. We believe OMG is a small yet solid step towards this objective, and we invite the community to join us. We are (will be) open-sourcing everything, code, model and data. Learn more:
📄Paper: arxiv.org/abs/2606.10340
🌐Project Page: tsinghua-mars-lab.github.io/…
🧑💻Code: github.com/Tsinghua-MARS-Lab…
[🧵 10/11]
1
1
7
458
Jun 11
OMG is a collective effort, and I’m truly thankful to everyone who helped make it possible. Special thanks to for Prof. Hang Zhao @zhaohang0124 for guidance and trust, Guanqi @guanqi_he for mentorship, Kunying @kunying_lee -- pushing work at this scale as a freshman is absolutely stuning, and the whole team (@dongming_qiao, Zhenyu Wang, @li_yitang, @ShaotingZ38103) for their hard work. [🧵11/11]
2
383
Jun 11
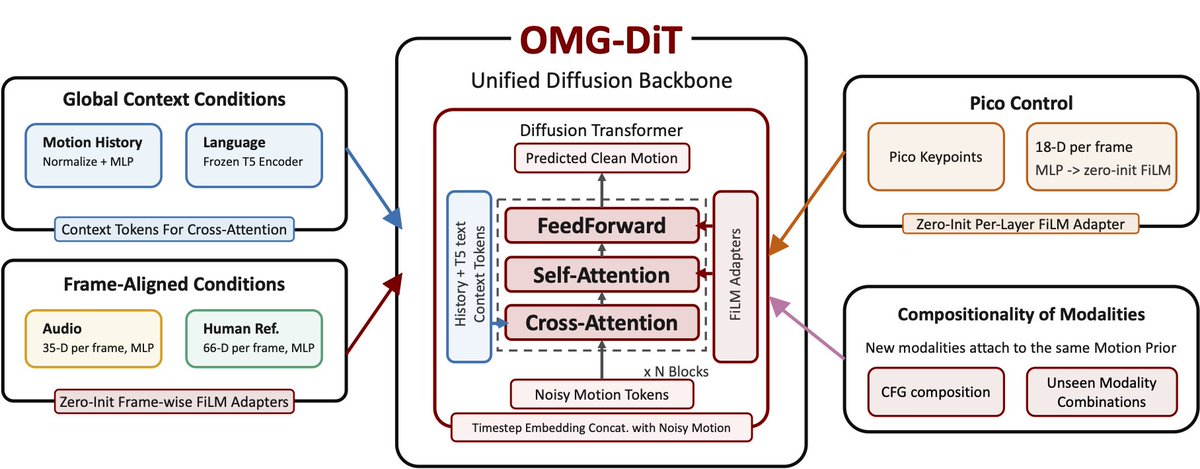
To enable multi-modal generalist humanoid motion generation in real time, we introduce OMG-DiT, a diffusion backbone that takes language, audio/music, human reference motion, motion history—and compositions of these signals—and generates future full-body trajectories that are trackable in real time. The key idea is decouples the motion prior from the conditioning modality, while motion priors are shared with the same diffusion backbone, each control modality is injected through modality-specific encoders, allowing sample-efficient adaptation to new modalities. [🧵5/11]
1
1
5
356
Jun 11
The results are more exciting than we expected. With exactly the same model, OMG can condition on unseen text, audio, human reference motions and their compositions in real time.
Text: Aeroplane
Text: Dinosaur
Text: Zombie
[🧵6/11]
2
1
5
332
Siqiao Huang retweeted

Here’s a pretty weird and surprising result - retrieval-augmented generation works unreasonably well for robot learning – but only when parameterized using difference vectors!
We introduce Difference-Aware Retrieval Policies for Imitation Learning (DARP), a simple, semi-parametric RAG architecture for imitation learning that achieves gains of up to 200% over standard behavior cloning. No additional assumptions beyond BC, just a little architecture switch! The theory backing it up is pretty cool too and it works on real robots! :)
Play with our website to understand better: weirdlabuw.github.io/darp-si…
🧵(1/7)
6
27
163
19,885
Jun 6
Can anyone explain to me why we use diffusion for semantic latent space generation? Seems like a bad prior for spaces where there’s no natural spectral decomposition.
Let me phrase this better. The way I understand generative models for high dimensional spaces is that you need compositional distributions to capture it’s complex structure, which often comes in the form of stochastic iterative computation. The underlying assumption is that there exists a natural Markov chain from no information(fully masked) to all information. For example, ar llms form a natural growth in sequence length, from no text to full paragraphs. The same holds for Flextok style 1D vision encoders, where nested dropout forces hierarchical structures to emerge in the sequence dimension. For diffusion models in image/video space, this Markov chain lies in the form of noising is essentially low-pass filtering in frequency domain (@sedielem ). Hence, “noising is masking”, but I highly doubt if this still holds true for semantic latents.
8
1
73
8,964
Jun 2
If you are interested in Locomotion, definately chat with @RunhanH !!
Jun 2

Flexible Locomotion Learning with Diffusion Model Predictive Control
Excited to share that our paper has been accepted to #ICRA2026 @ieee_ras_icra!
A diffusion-planning framework for flexible real-world quadruped locomotion. Instead of learning a fixed RL policy or relying on hand-crafted dynamics for MPC, we train a diffusion trajectory prior that jointly predicts future states and actions.
Key Ideas:
Diffusion-MPC: A diffusion planner unlocks flexible locomotion through test-time reward and constraint adaptation
Interactive reward-weighted finetuning enables continual behavior refinement from online environment feedback
Real-world deployment on Unitree Go2 with efficient and adaptive planning
The same planner can adapt at test time to height changes, posture/joint constraints, balancing under external disturbances, energy-aware locomotion, and zero-shot outdoor walking on grass and slopes.
🌐Homepage: flexible-diffusion-mpc.githu…
📖Paper: arxiv.org/abs/2510.04234
🔗Code: github.com/hrh6666/Flexible-…
This work is by @RunhanH, Haldun Balim, @hankyang94 , and @du_yilun.
#ICRA2026 #Robotics #LeggedRobots #RobotLearning #DiffusionModels #MPC #MachineLearning
1
6
868
May 29
We need a sglang/vllm but for world model serving. The year that this need becomes apparent and the project that will do it becomes well-known is 2028.
4
14
2,471
Siqiao Huang retweeted

May 26
Congratulations to Siqiao ( @KnightNemo_ ) for releasing his NanoWorldModels repo.
World model research can be notoriously tricky, given the numerous small design decisions that can make an excellent idea appear to fail completely. Siqiao's repo will help all researchers avoid these pitfalls; a huge service to the community!
May 26

In the last couple of months, we have witnessed significant advances in Industry-scale World Models. Yet, for the broader community, the gap between reading about these models and deploying them remains disappointingly wide.
Today we're releasing Nano World Models: a minimalist, batteries-included repo for advancing world model science.
🧵 (1/9)
9
105
13,609
May 26
In the last couple of months, we have witnessed significant advances in Industry-scale World Models. Yet, for the broader community, the gap between reading about these models and deploying them remains disappointingly wide.
Today we're releasing Nano World Models: a minimalist, batteries-included repo for advancing world model science.
🧵 (1/9)
10
54
351
47,831
May 26
World Models need the World. Our hope is to build a Babel tower for world model research: datasets, objectives, architectures, and tasks all speaking the same language. We invite the global community to join us, contribute, and build this future together. Learn more:
📚 Paper: arxiv.org/abs/2605.23993
📝 Blog: simchowitzlabpublic.github.i…
🤖Models: huggingface.co/collections/k…
💻 Code: github.com/simchowitzlabpubl…
🧵 (9/9)
2
16
1,464
May 26
Nano World Models is a team effort, and I’m deeply grateful to everyone who helped make it possible. Special thanks to @max_simchowitz for guidance and mentorship along the way, and to the whole team ( @k4sncdrnng, @mqchenner, @HengkaiPan, @lomarchehab, @fermorenp) for everything behind this work!
10
1,250