
57 Photos and videos











🚨Sensational title alert: we may have cracked the code to true multimodal reasoning.
Meet ThinkMorph — thinking in modalities, not just with them.
And what we found was... unexpected. 👀
Emergent intelligence, strong gains, and …🫣
🧵 arxiv.org/abs/2510.27492
(1/16)

27
67
316
69,463
Jiawei Gu retweeted

Jun 10
What if VLMs could imagine visually before answering spatial questions?
New paper: Imaginative Perception Tokens (IPT) teach multimodal LMs to reason about hidden 3D structure — without generating images at inference time.
Paper: arxiv.org/abs/2606.03988
5
10
60
68,794
Jiawei Gu retweeted

May 29
Budget-aware Agents (BAGEN) study the failure modes in budget estimation:
1. Strong agents are not strong budget estimators.
2. Frontier models are often overoptimistic.
3. Budget awareness is actionable and trainable. SFT plus RL strengthens early stop and alert behavior, saving 28-64 percent of tokens on failed trajectories.
4. Upper and lower bound calibration remains hard.
ragen-ai.github.io/bagen/

May 29

🧵 Claude-Opus-4.8 takes you too much tokens - but is this issue general across agents? Do agents know how much they'll spend?
Introducing Budget-Aware Agents (BAGEN): We study budget awareness across 4 envs & 5 frontier agents, and find structured failures in most of them.
👇

2
14
87
14,757
Jiawei Gu retweeted

May 19
Excited to share ESI-BENCH, a benchmark for Embodied Spatial Intelligence!
Most spatial reasoning benchmarks assume an oracle observer: the agent is given the right image, view, or 3D scene.
But in the real world, the observer is also an actor.
To understand space, agents must decide where to look, how to move, and when to interact, to reveal what is hidden: occlusions, containment, contact, dynamics, and functionality.
In many cases, the hard part is not perception itself, but choosing the right action to make informative perception possible.
ESI-BENCH tests this perception-action loop.
Agents receive an egocentric observation and a spatial question, then must actively gather evidence through perception, locomotion, and manipulationbefore answering.
The benchmark spans 10 task categories, 29 subcategories, and 3,081 instances, built in BEHAVIOR-1K across realistic interactive scenes.
🌍Webpage: esi-bench.github.io
💻Code & data: github.com/ESI-Bench/ESI-Ben…
Thanks for collaborators: Jiageng, Han, @ManlingLi_ , Leonidas Guibas, @drfeifei , @jiajunwu_cs , @YejinChoinka
8
46
221
47,987
Jiawei Gu retweeted

May 27
✨Is Your Spatial Foundation Model an All-Round Player✨
@ropedia_ai presents #SpatialBench, a diverse spatial benchmark over 19 source datasets, 540 scenes, 40 model variants, and 6 reconstruction paradigms.
- Project: ropedia.github.io/SpatialBen…
- Code: github.com/Ropedia/SpatialBe…
May 27

SpatialBench
The first cross-paradigm benchmark for spatial foundation models spans 19 datasets, 546 scenes, and 41 models to answer one question: are you truly an all-round player?

2
16
96
10,278
Jiawei Gu retweeted

Apr 28
huggingface.co/papers/2604.2…
arxiv.org/abs/2604.23781
tech report release
Apr 20

Can confirm — K2.6 isn't just a demo-reel model.
Few days ago, we received a bug report from kimi team, and we got early API access, re-ran ClawMark (our living-world openclaw benchmark). After fixing a compatibility bug in openclaw's repo (github.com/openclaw/openclaw…), K2.6 lands at 0.684 avg score — edging out gemini-3.1-pro (0.682) and jumping 0.124 over K2.5.
Shipping shaders and agentic benchmark gains in the same release is a pretty rare combo. 👀

2
8
40
11,693
I couldn’t make it to @iclr_conf in person, but ThinkMorph is there now :) If you’re around, come say hi to our poster for me! 👋
We’re at Pavilion 3, P3-#1724, and it’ll be up through 1:00 PM BRT.
#ICLR2026
2
9
303
Jiawei Gu retweeted

Apr 22
At Kimi, we do care about Notion use. Training K2.6 on remote apps such as notion was one of the most important projects during my internship.
A bit of Kimi flavor: we like to RL things that aren't supposed to be RL-able.
A lot of it came from RL. And it scales.
Apr 21

When I saw our team's evals of Kimi 2.6, I thought "ok, things are gonna get interesting now".
This is the first open-weight model that plays like a top-class agentic model. Watching it go through ambiguous and meticulous chained tool work successfully puts it squarely in the wheelhouse of Opus 4.6. We're looking at an open weight model, but with much cheaper direct inference provider pricing. For a subclass of our eval set, it's outperforming GPT 5.2. We're about to undergo a gigantic industry shift.
Open weight is no longer for those who fine tune, those who want on-prem. It's an actual, reliable option for it's quality/price/latency profile for difficult agentic work.
It's not perfect. It's token hungry, relatively slow, and can get stuck in “thinking loops". But those are things we can engineer around. For value it is, and how it positions itself against major labs, this is a dramatic day for open weight models.
We sprinted as a team and worked closely with @FireworksAI_HQ to get this to our customers on day 0. No one should wait to try out a change like this. Try it yourself and tell me where it's working for you.
2
3
44
4,905
Jiawei Gu retweeted

Apr 20
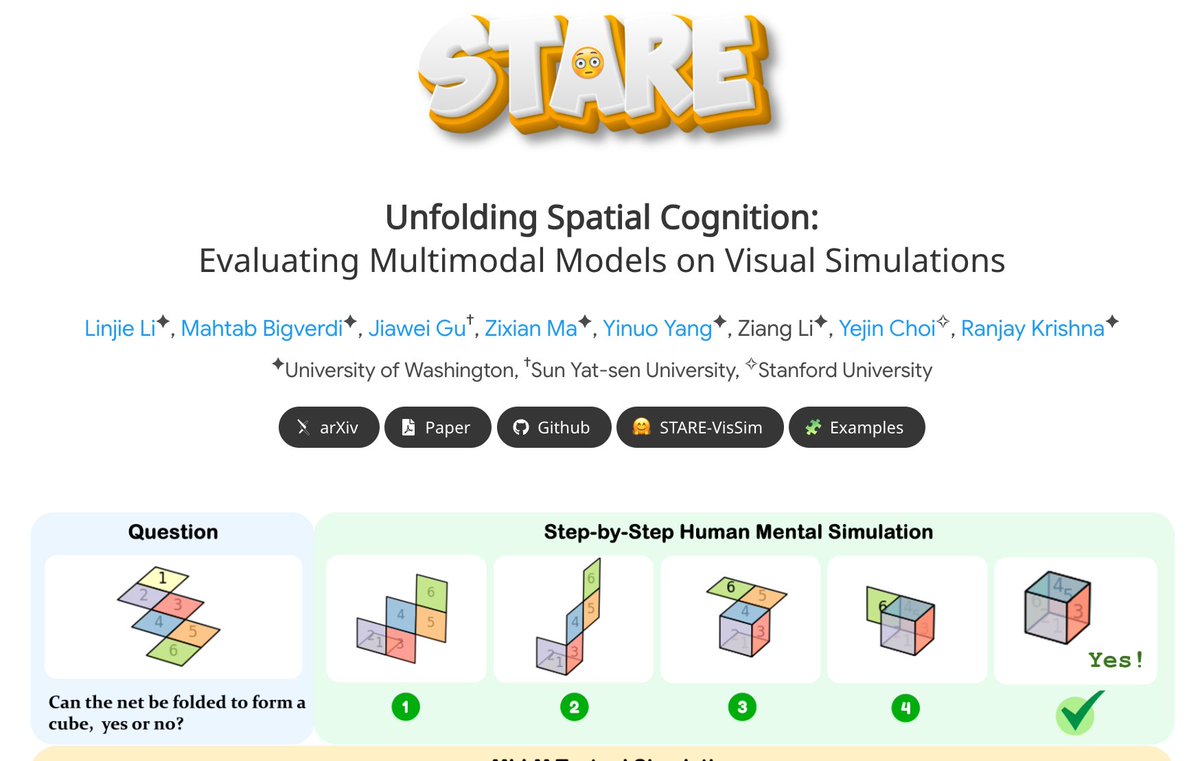
Don’t miss our 8/8/8/6 ICLR 2026 🇧🇷🌴🥁 paper, STARE😳! We introduce a benchmark and analysis revealing key gaps in how multimodal models handle multistep visual simulations.
Check it out: github.com/STARE-bench/STARE

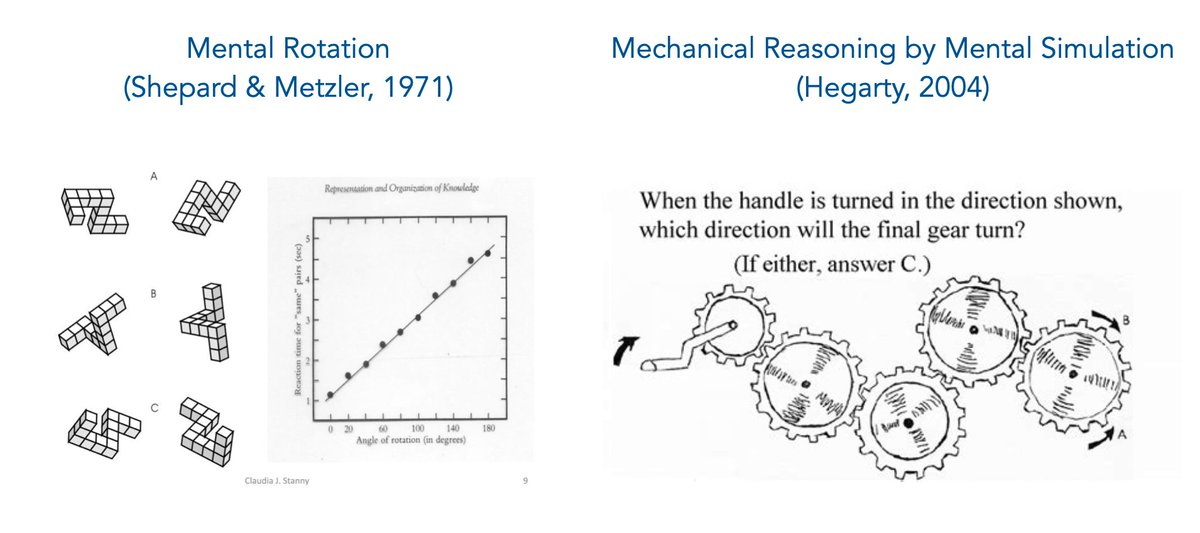
One thing that keeps pulling us back is how effortless spatial reasoning is for people.
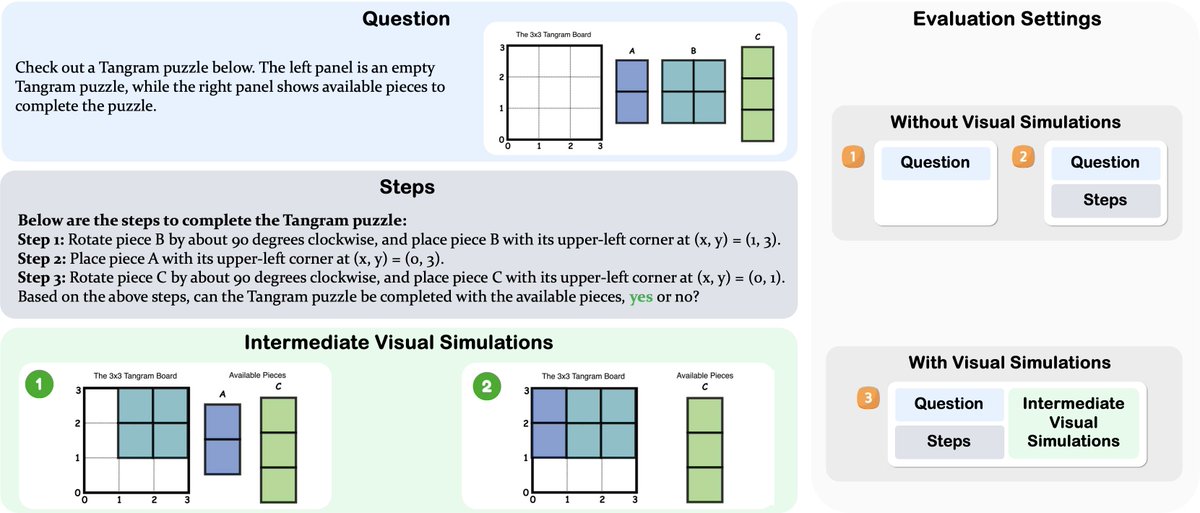
We look at a cube net once and just know if it folds into a box. We can almost "run" the folds in our head, panel by panel, without really trying.
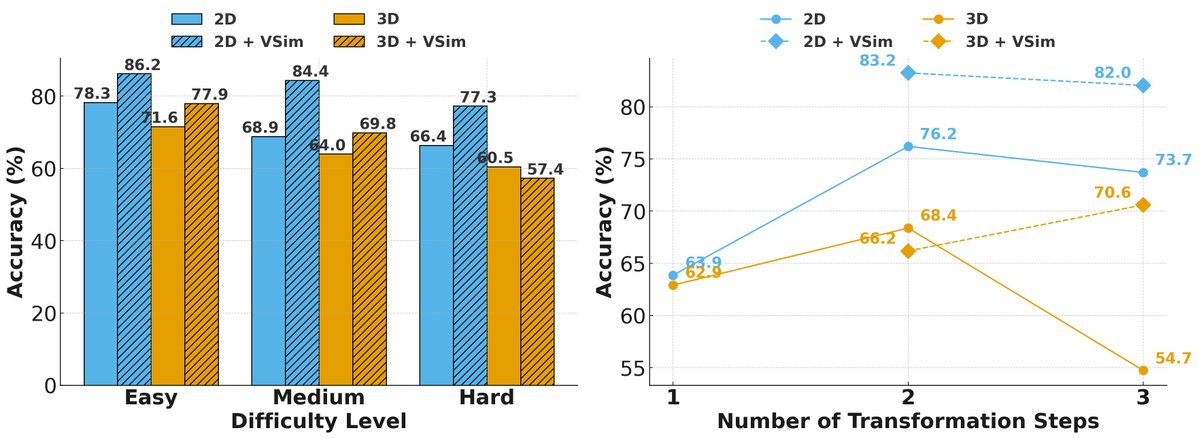
About a year ago, we started noticing something strange: when we gave a model step-by-step visual cues, it didn't get clearer — it got even worse.
That's what led us to 😳 STARE at what happens when AI tries to think in space. The paper was recently accepted at #ICLR2026 (8/8/8/6).
(1/12) 🧵 arxiv.org/abs/2506.04633
1
4
23
3,934
Jiawei Gu retweeted

Apr 20
Check out STARE: our new ICLR paper with a (very challenging) visual spatial reasoning benchmark which even sora2 has no clue how to solve👇
video cr. @LINJIEFUN
One thing that keeps pulling us back is how effortless spatial reasoning is for people.
We look at a cube net once and just know if it folds into a box. We can almost "run" the folds in our head, panel by panel, without really trying.
About a year ago, we started noticing something strange: when we gave a model step-by-step visual cues, it didn't get clearer — it got even worse.
That's what led us to 😳 STARE at what happens when AI tries to think in space. The paper was recently accepted at #ICLR2026 (8/8/8/6).
(1/12) 🧵 arxiv.org/abs/2506.04633
1
10
43
5,234
One thing that keeps pulling us back is how effortless spatial reasoning is for people.
We look at a cube net once and just know if it folds into a box. We can almost "run" the folds in our head, panel by panel, without really trying.
About a year ago, we started noticing something strange: when we gave a model step-by-step visual cues, it didn't get clearer — it got even worse.
That's what led us to 😳 STARE at what happens when AI tries to think in space. The paper was recently accepted at #ICLR2026 (8/8/8/6).
(1/12) 🧵 arxiv.org/abs/2506.04633
1
23
157
20,305
(11/12🧵) What this tells us:
Current models are optimized to think in text. But spatial cognition demands thinking in multimodality.
Our related work tackles this:
• ThinkMorph (ICLR '26): imagine and mentally simulate transformations
thinkmorph.github.io
• AdaReasoner (ICLR '26): draw, annotate, compute with tools
adareasoner.github.io
So, how do we teach models to see with their mind’s eye?
1
2
6
427
(12/12🧵)
Website: stare-bench.github.io/
Code: github.com/STARE-bench/STARE
Data: huggingface.co/datasets/kuvv…
😳STARE is one lens on a frontier that is still wide open.
Very lucky to work on this with @LINJIEFUN, @MahtabBg, @zixianma02 , Yinuo Yang, Ziang Li, @YejinChoinka , and @RanjayKrishna.
3
182