
Joined December 2022
- Tweets 3,906
- Following 32
- Followers 116,004
- Likes 1,571
1,902 Photos and videos












Contracts are where business commitments live, but most organizations still manage them manually, searching PDFs for renewal dates, chasing down payment terms, and hoping nothing slips through the cracks.
The problem isn't just volume. Legacy OCR treats contracts like flat text, unable to interpret what it reads: the same payment term appears under three different headings, renewal conditions are buried mid-paragraph, and termination clauses span multiple amendments.
We wrote up how LlamaParse solves this by:
✅️ Preserving document hierarchy
✅️ Using semantic reasoning to identify key fields regardless of how they're drafted
✅️ Mapping everything into validated, schema-aligned output
Ultimately, it transforms contracts from flat PDF text into structured data your downstream systems can actually use.
Read the full breakdown here:
llamaindex.ai/blog/extract-c…
3
2
18
5,243

Jun 12
We're headed back to @Databricks #DataAISummit to parse your PDFs next week 🦙
Catch our co-founder & CEO @jerryjliu0 twice:
📄 Automating Document Work with Long-Horizon AI Agents — databricks.com/dataaisummit/…
🧱 The Agentic Stack: founder panel with LangChain, CrewAI, Agno Databricks — databricks.com/dataaisummit/…
Then swing by booth #137, talk document agents, see LlamaParse, leave with 🔥 swag.
San Francisco, June 15–18. See you there. 👋
6
4
30
3,685
LlamaIndex 🦙 retweeted

Jun 9
As frontier models (e.g. Fable 5) continue to push the task horizon of knowledge work automation, it becomes ever more important for humans to be able to audit decisions back to the source context.
It is extremely easy for agents to cite an entire document or document page, but much harder for them to trace back to the exact numbers/words/figures within a page.
Today we've launched granular bounding boxes within LlamaParse, which allows you to obtain visual citations of every single word in the document. This allows human users to audit exact words and figures - not just general document regions or entire pages!
Come check it out: cloud.llamaindex.ai/?utm_sou…
Jun 9

Parsing a document accurately is one thing. Proving where every value came from is another.
When a compliance team reviews an AI extraction, or an auditor needs to sign off on a figure pulled from a financial filing, "it came from this document" isn't enough. They need to see exactly where. The specific cell in the table, the exact line on the page, the precise word the agent used.
Most parsers can get you to a paragraph or a table block. That's where the trail ends.
Today we're shipping Granular Bounding Boxes in LlamaParse — word, line, and cell level coordinates for every value in your document.
The result is a complete, verifiable trail from every extracted value back to its exact source in the document. Built for audit workflows, compliance review, and any pipeline where verification isn't optional.
Read the full announcement → llamaindex.ai/blog/announcin…
14
12
157
22,725
LlamaIndex 🦙 retweeted
Jun 9
LiteParse, our open-source/Rust-based doc parser, runs so quickly that Claude Fable 5 doesn't think it's real 🔥
It is the fastest document parsing solution on the planet and a great choice for your AI document workloads.
Check it out: github.com/run-llama/litepar…


LiteParse runs so fast that Claude Fable 5 doesn't think its real

12
15
242
26,034
LlamaIndex 🦙 retweeted
Jun 10
Claude Fable 5 thinks document parsing is beneath it
It is absolutely crushing on all reasoning-intensive/long horizon benchmarks: SWE-Bench Pro, FrontierCode, GDPval, Runescape, etc.
But for document understanding tasks, it is roughly equivalent with Gemini 3 Flash in performance, at roughly 10-15x the token cost.
We benchmarked the model on ParseBench and compared it against all other frontier models. It is definitely up there compared to other frontier models, but falls far short of specialized OCR providers.
What we found interesting is that Fable 5 is self-aware about this. When we ask the model what tasks it enjoys the last, it actively said that it dislikes tasks "where the request is fully specified and the answer is fully known" - implying part of it being bad is due to laziness and lack of willingness to actually solve the task at hand.
For a full list of results across different frontier models, check out ParseBench! parsebench.ai/
Jun 10
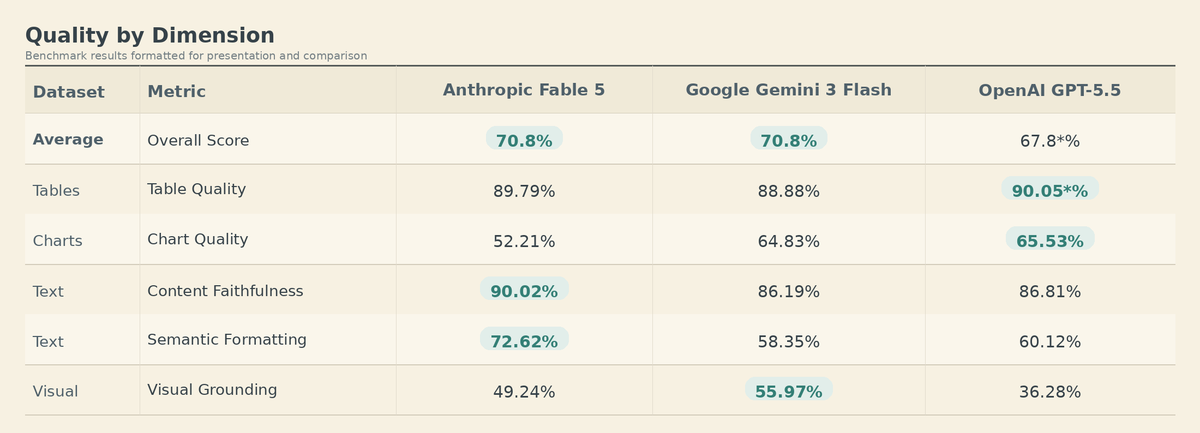
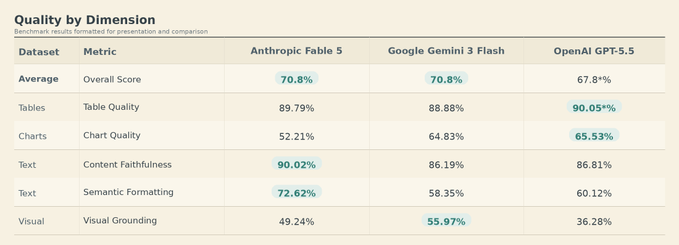
Day 0 Anthropic Fable 5 in ParseBench: We tested the model's advancements when it comes to document understanding. The model clearly peaks when it comes to adherence to the original text:
📃 Content faithfulness: 90.02% vs 86.19% (Gemini 3 Flash) and 86.81% (GPT-5.5)
🔢 Semantic formatting: 72.62% vs 58.35% and 60.12%, a 12 point lead
These are two of the most important metrics for SOTA document understanding: does the output preserve what the document actually says, and does it preserve formatting that carries meaning?
But ... it's not a sweep there continues to be a lot of alpha in unlocking document understanding for frontier models.
Full results below 👇
23
22
219
48,584
Jun 10
Day 0 Anthropic Fable 5 in ParseBench: We tested the model's advancements when it comes to document understanding. The model clearly peaks when it comes to adherence to the original text:
📃 Content faithfulness: 90.02% vs 86.19% (Gemini 3 Flash) and 86.81% (GPT-5.5)
🔢 Semantic formatting: 72.62% vs 58.35% and 60.12%, a 12 point lead
These are two of the most important metrics for SOTA document understanding: does the output preserve what the document actually says, and does it preserve formatting that carries meaning?
But ... it's not a sweep there continues to be a lot of alpha in unlocking document understanding for frontier models.
Full results below 👇
14
7
56
39,948
Jun 9
Parsing a document accurately is one thing. Proving where every value came from is another.
When a compliance team reviews an AI extraction, or an auditor needs to sign off on a figure pulled from a financial filing, "it came from this document" isn't enough. They need to see exactly where. The specific cell in the table, the exact line on the page, the precise word the agent used.
Most parsers can get you to a paragraph or a table block. That's where the trail ends.
Today we're shipping Granular Bounding Boxes in LlamaParse — word, line, and cell level coordinates for every value in your document.
The result is a complete, verifiable trail from every extracted value back to its exact source in the document. Built for audit workflows, compliance review, and any pipeline where verification isn't optional.
Read the full announcement → llamaindex.ai/blog/announcin…
6
8
47
28,019
Jun 8
The Agent Open: AI's Pickleball Tournament 🏓
Come put your code and backhand to the test and embrace the full Open experience.
Custom built out courts. Stadium seating. Exhibition matches by AI leaders. Fresh agent merch. Every infra startup you love, all in one place.
Brought to you by in collaboration with:
@braintrust , @browserbase , @cursor_ai , @modal , @p0 , @turbopuffer
Where were you during the first Agent Open? Come make history. SF Edition. 👇
lnkd.in/gMmpg8QH
5
6
30
25,103
Jun 4
Most AI pipelines are only as good as the data we provide them with, and that usually means PDFs or other unstructured documents.
Contracts, invoices, reports... All have special layout, language, and context mixed together, and getting reliable structured data out of them is still one of the hardest unsolved problems in enterprise AI.
Parse-Flow is an open-source project we built to tackle this head-on. It puts four document processing primitives at the center of a visual workflow designer:
📄 Parse — clean markdown and text from raw documents
🔍️ Classify — assign documents to user-defined categories
✂️ Split — segment documents into typed chunks
Extract — pull structured JSON against a schema
You drag steps onto a canvas, drop in a document, and watch events stream back as the pipeline runs. Under the hood it's powered by a LlamaAgents workflow that walks your flow one step at a time, making every transition observable and every failure a first-class value.
📚️ Full write-up on the architecture here: llamaindex.ai/blog/designing…
👩💻 Source code: github.com/run-llama/parse-f…
8
14
85
15,422
LlamaIndex 🦙 retweeted
Jun 4
We're presenting ParseBench at CVPR 2026!
ParseBench is the most comprehensive document understanding benchmark for VLMs.
✅ It contains 2k pages of real-world enterprise documents
✅ It has comprehensive evaluation metrics around tables, charts, visual grounding, semantic formatting, and content faithfulness
The core goal is measuring whether models can semantically interpret a document in the right way, without having models overfit to our precise benchmark.
Parsing 100% of PDFs to 100% accuracy is the final boss for document OCR.
In general, the latest frontier models have been tuned for coding, math, and scientific reasoning as opposed to precise visual understanding; hope more benchmarks that these will encourage overall progress towards solving this problem!
Poster is below. If you want to learn more come check out our site or 30-page ArXiv paper:
ParseBench: parsebench.ai/
ArXiv: arxiv.org/abs/2604.08538

Jun 4
We're presenting ParseBench at CVPR 2026 today. 🦙
Come learn why document understanding is an AGI-complete problem (an agent can't act on a doc it can't correctly read, and reading a real enterprise table is harder than it looks).
The first doc-parsing benchmark built for AI agents:
2,000 human-verified pages
167K test rules
5 dimensions: tables, charts, faithfulness, formatting, grounding
Fully open source.
📍 Talk TODAY, June 4, 9–10 AM at CVPR. Come say hi 👇
🤗 huggingface.co/datasets/llam…
💻 github.com/run-llama/ParseBe…
📄 arxiv.org/abs/2604.08538
12
18
116
18,116
Jun 4
We're presenting ParseBench at CVPR 2026 today. 🦙
Come learn why document understanding is an AGI-complete problem (an agent can't act on a doc it can't correctly read, and reading a real enterprise table is harder than it looks).
The first doc-parsing benchmark built for AI agents:
2,000 human-verified pages
167K test rules
5 dimensions: tables, charts, faithfulness, formatting, grounding
Fully open source.
📍 Talk TODAY, June 4, 9–10 AM at CVPR. Come say hi 👇
🤗 huggingface.co/datasets/llam…
💻 github.com/run-llama/ParseBe…
📄 arxiv.org/abs/2604.08538
5
7
47
15,975
LlamaIndex 🦙 retweeted
Jun 2
We Parse PDFs
We spent 7 figures to put this on billboards throughout SF.
I thought long and hard about putting something more creative and whimsical. But then you wouldn’t know what we do.
AI agents (and humans) are consuming exponentially more documents as they do real work. They need the best quality document parser to not output garbage on downstream tasks.
This is what we do today as a company. If you have any PDFs (or other documents), we parse them :)
If you’re around SF in June for one of the following events, come stop by our booths:
✅ Snowflake Summit (this week, Booth 1123)
✅ Databricks Data AI Summit (June 15-18, Booth 137)
✅ AI Engineer World Fair(June 29-July 2, Booth L-G47)
You can find us by the same sign we put on our billboards!
We Parse PDFs
@llama_index
23
14
161
14,930
LlamaIndex 🦙 retweeted
Jun 1
Last week we revamped Liteparse to be the fastest PDF parser out there ⚡️
An underrated part of liteparse is it doesn't just give you text. It gives you bounding boxes that a coding agent can use to paint exact audit trails back to the source document.
For instance, check out the deep research skill we compiled in liteparse_samples: github.com/jerryjliu/litepar…
Come check out liteparse: github.com/run-llama/litepar…
We are hard at work making liteparse even better (e.g. Markdown support). Please feel free to open up issues, PRs, and let us know your feature requests 🙏
May 27

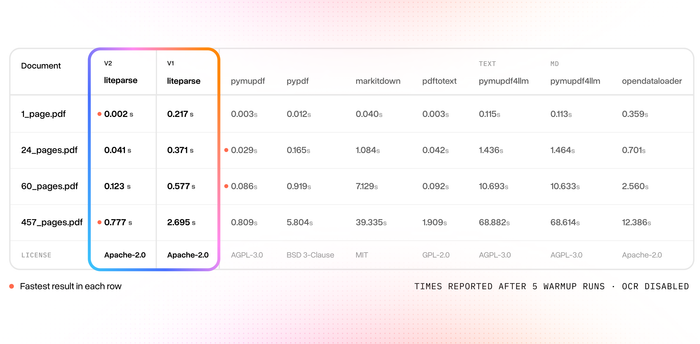
We've created the world's fastest PDF parser ⚡️
And it's more accurate than any other open-source, model-free PDF parser out there (pymupdf, pypdf, markitdown, pdftotext, opendataloader, pymupdf4llm)
Introducing LiteParse v2 - we rewrote the entire library into Rust and adapted it as native packages for Python and Node.
It supports 50 different document types, can be triggered directly or installable directly within your favorite AI agent.
Blog: llamaindex.ai/blog/liteparse…
Repo: github.com/run-llama/litepar…
15
18
289
45,698
Jun 1
❄️ Come meet the LlamaIndex Team at Snowflake Summit 2026.
It might be chilly in Snow Park ☃️ but the AI infrastructure market is red hot 🔥. Come visit our team at the expo floor and explore how you can parse your most complex documents and teach your agents to read unstructured context with human-level accuracy.
5
5
21
8,402
LlamaIndex 🦙 retweeted
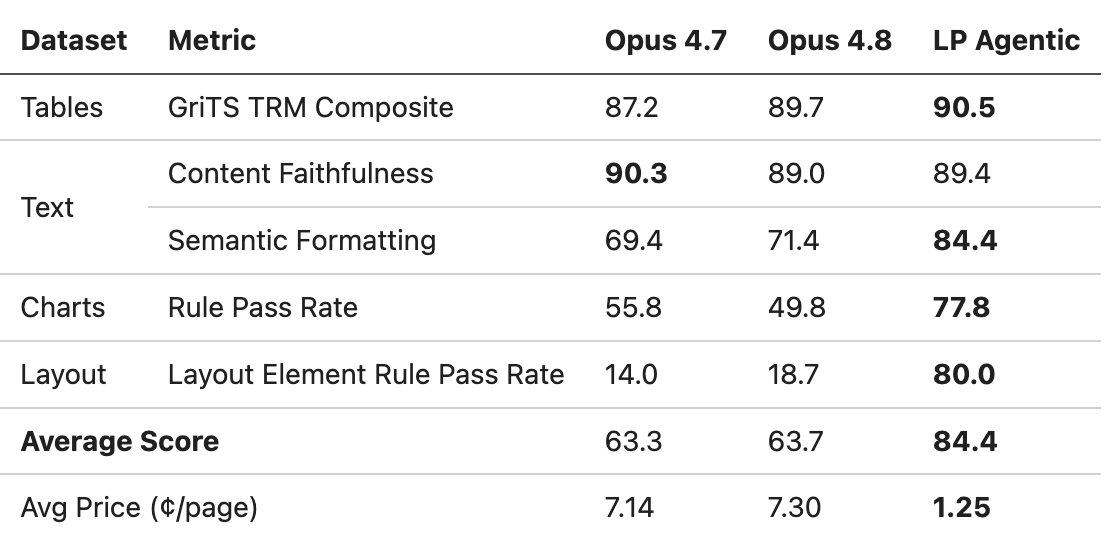
May 30
The secret to LiteParse lies in the grid projection algorithm. We project a complex page layout with text and tables into well-structured text, that humans can read and agents can understanding.
This contains of a few core steps (no LLMs!):
1. Grouping text fragments to lines
2. Identify left,center,right anchors
3. Snap each text item to an anchor
4. Handle flowing paragraphs separately
5. Render each text item in a carefully tuned order so that each piece of text aligns to a grid column
6. Post-processing
For more details check out this great blog post we wrote a month ago!
llamaindex.ai/blog/how-litep…

May 27
We've created the world's fastest PDF parser ⚡️
And it's more accurate than any other open-source, model-free PDF parser out there (pymupdf, pypdf, markitdown, pdftotext, opendataloader, pymupdf4llm)
Introducing LiteParse v2 - we rewrote the entire library into Rust and adapted it as native packages for Python and Node.
It supports 50 different document types, can be triggered directly or installable directly within your favorite AI agent.
Blog: llamaindex.ai/blog/liteparse…
Repo: github.com/run-llama/litepar…
22
27
204
26,298
LlamaIndex 🦙 retweeted
May 29
Parse PDFs in the browser, or the edge, in milliseconds
Our LiteParse WASM package can be literally run anywhere, from cloudflare workers, mobile runtimes, to the browser.
Starter template for Cloudflare: github.com/run-llama/litepar…
LiteParse repo: github.com/run-llama/litepar…
LiteParse docs: developers.llamaindex.ai/lit…

May 29
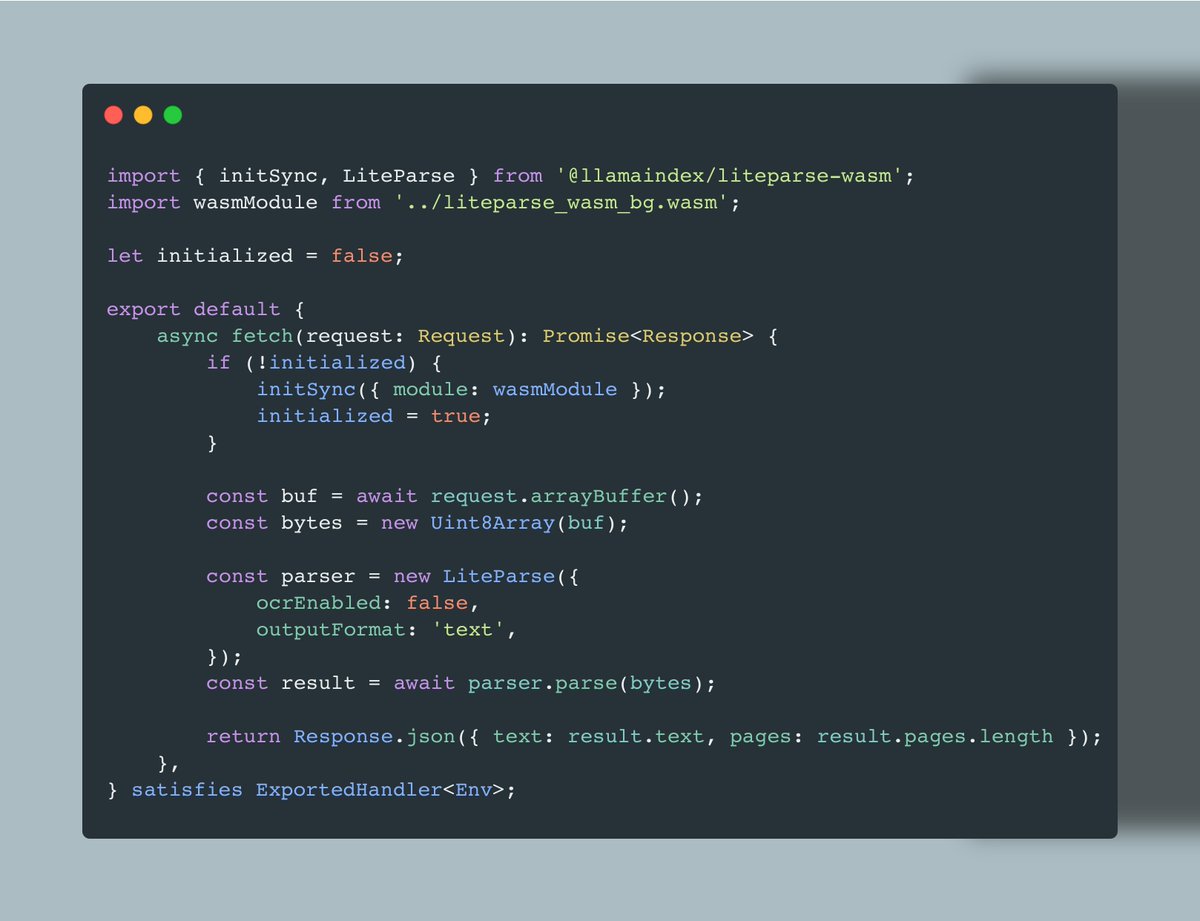
When we say “LiteParse runs everywhere,” we mean it.
Our WASM package is lightweight, minimal, and built for browser and edge runtimes, which makes it a perfect fit for @cloudflare Workers.
Using WebAssembly, you can spin up a parser that runs directly on the Worker, takes PDF bytes as input, and returns extracted text plus page count (all in under 25 lines of code!)🚀
👩💻 Try it out now: github.com/run-llama/litepar…
📚️ Get started with LiteParse: developers.llamaindex.ai/lit…
8
20
289
25,158
LlamaIndex 🦙 retweeted
May 29
Document Parsing Gemini 🔥
Excited to collaborate with the Google team on this, here's to many more!

The team at @llama_index built an awesome template using LlamaParse and the new Managed Agents in the Gemini API. See how they built an agent that can tackle unstructured documents. 📄↓
8
8
105
18,404
LlamaIndex 🦙 retweeted
May 29
Parse PDFs at lightspeed (this video is at 1x)
Absolute cinema
May 27
We've created the world's fastest PDF parser ⚡️
And it's more accurate than any other open-source, model-free PDF parser out there (pymupdf, pypdf, markitdown, pdftotext, opendataloader, pymupdf4llm)
Introducing LiteParse v2 - we rewrote the entire library into Rust and adapted it as native packages for Python and Node.
It supports 50 different document types, can be triggered directly or installable directly within your favorite AI agent.
Blog: llamaindex.ai/blog/liteparse…
Repo: github.com/run-llama/litepar…
29
63
902
143,590
May 29
When we say “LiteParse runs everywhere,” we mean it.
Our WASM package is lightweight, minimal, and built for browser and edge runtimes, which makes it a perfect fit for @cloudflare Workers.
Using WebAssembly, you can spin up a parser that runs directly on the Worker, takes PDF bytes as input, and returns extracted text plus page count (all in under 25 lines of code!)🚀
👩💻 Try it out now: github.com/run-llama/litepar…
📚️ Get started with LiteParse: developers.llamaindex.ai/lit…
9
20
142
45,428