
AI for every developer. So what will you build?
Joined April 2024
- Tweets 1,897
- Following 50
- Followers 115,004
- Likes 641
797 Photos and videos













Pinned Tweet

DiffusionGemma, our experimental open model released under an Apache 2.0 license, explores text diffusion, an exceptionally fast approach to text generation.
Here’s how DiffusionGemma accelerates development:
Faster token output: By shifting the bottleneck from memory bandwidth to raw compute, the model generates up to 4x faster token output on dedicated GPUs
Accessible hardware footprint: Activates just 3.8B parameters during inference, fitting comfortably within 24GB-VRAM high-end consumer GPUs when quantized
Novel workflows: Parallel token generation enables self-correction, making it ideal for code infilling, in-line editing, and non-linear structures
DiffusionGemma prioritizes speed over raw quality and accelerates best on compute-bound hardware (like @NVIDIAAI GPUs). Standard @GoogleGemma 4 remains recommended for production quality and memory-bound devices.
30
43
444
116,272
Add near real-time voice translation to your apps with Gemini 3.5 Live Translate via the Gemini Live API. 🎙️
Watch how the model handles live broadcast ingestion and translation with continuous speech-to-speech streaming (S2ST) and synced transcripts, letting users tune into global radio broadcasts in their native language.
13
32
237
14,684
Try building in @GoogleAIStudio and show us what you make.
aistudio.google.com/live?mod…
1
2
15
2,909
DiffusionGemma, our experimental open model released under an Apache 2.0 license, explores text diffusion, an exceptionally fast approach to text generation.
Here’s how DiffusionGemma accelerates development:
Faster token output: By shifting the bottleneck from memory bandwidth to raw compute, the model generates up to 4x faster token output on dedicated GPUs
Accessible hardware footprint: Activates just 3.8B parameters during inference, fitting comfortably within 24GB-VRAM high-end consumer GPUs when quantized
Novel workflows: Parallel token generation enables self-correction, making it ideal for code infilling, in-line editing, and non-linear structures
DiffusionGemma prioritizes speed over raw quality and accelerates best on compute-bound hardware (like @NVIDIAAI GPUs). Standard @GoogleGemma 4 remains recommended for production quality and memory-bound devices.
30
43
444
116,272
Google AI Developers retweeted

Jun 9
Fishjam 🤝 Gemini
You can now translate livestreams on demand, thanks to the newest Gemini 3.5 Live Translate!🌎
We used Fishjam to stream live video over MoQ (Media over QUIC), and Gemini to provide live translation.
Translations are fully on demand – Fishjam only connects to Gemini when a viewer actually requests a language, so you never waste tokens on translations nobody is listening to. 💪
Try it out yourself: translate.fishjam.io/
Congrats to the Gemini team on this release! 🎉

Our latest audio model, Gemini 3.5 Live Translate, takes real-time speech translation to the next level for developers by delivering low-latency translation across 70 languages.
By processing speech as it streams in near real time, the model enables devs to build low-latency audio experiences with:
— Multilingual input: Understands multiple languages in a single session without needing to adjust settings.
— Auto-detection: Identifies the spoken language and begins translation instantly.
— Native audio processing: Generates more natural-sounding speech that preserves speakers' intonation, pacing, and pitch.
— Noise robustness: Filters out ambient noise for clearer conversation in loud environments.
3
9
70
9,254

We built a live multilingual, multi-person video call with Gemini 3.5 Live Translate on LiveKit. Everyone picks their language, speaks naturally, and hears each other in real time in their language of choice.
Watch the demo and check out the open source repo: github.com/livekit-examples/…
Our latest audio model, Gemini 3.5 Live Translate, takes real-time speech translation to the next level for developers by delivering low-latency translation across 70 languages.
By processing speech as it streams in near real time, the model enables devs to build low-latency audio experiences with:
— Multilingual input: Understands multiple languages in a single session without needing to adjust settings.
— Auto-detection: Identifies the spoken language and begins translation instantly.
— Native audio processing: Generates more natural-sounding speech that preserves speakers' intonation, pacing, and pitch.
— Noise robustness: Filters out ambient noise for clearer conversation in loud environments.
12
11
151
20,658
Our latest audio model, Gemini 3.5 Live Translate, takes real-time speech translation to the next level for developers by delivering low-latency translation across 70 languages.
By processing speech as it streams in near real time, the model enables devs to build low-latency audio experiences with:
— Multilingual input: Understands multiple languages in a single session without needing to adjust settings.
— Auto-detection: Identifies the spoken language and begins translation instantly.
— Native audio processing: Generates more natural-sounding speech that preserves speakers' intonation, pacing, and pitch.
— Noise robustness: Filters out ambient noise for clearer conversation in loud environments.
13
25
200
41,257
Get the docs: goo.gle/4g9HZNj
Start cooking: colab.research.google.com/gi…
1
9
2,919
And read the blog to learn more: blog.google/innovation-and-a…
11
3,967
New @GoogleGemma 4 QAT (Quantization-Aware Training) checkpoints are here, so you can run models locally on consumer GPUs and mobile devices with minimal quality loss.
What’s new:
🔹 GGUF (Q4_0): Checkpoints: Max local performance across all sizes and drafter models
🔹 Custom Mobile Schema: We shrunk Gemma 4 down to less than 1GB for mobile devices by using a custom mixed precision schema designed for edge hardware (featuring targeted 2-bit decoding layers, optimized KV caches, and static activations)
By simulating compression during training rather than after (Post-Training Quantization), we've drastically reduced the memory footprint and accelerated decode speeds while preserving reasoning quality. blog.google/innovation-and-a…
19
46
421
18,303
Play our new open-weights music model, @GoogleMagenta RealTime 2, using a MIDI keyboard, live text prompts, and even hand gestures ✌️
x.com/GoogleMagenta/status/2…

Introducing Magenta RealTime 2 (MRT2): the live music model you can play as an instrument.
MRT2 offers MIDI and prompt controls, and runs natively on a MacBook with <200ms latency.
Open weights. Open source inference engine. Suite of apps and plugins.
Hear what it can do and try it out for yourself below 🧵
10
8
118
13,148
Join @GoogleDeepmind and @HeyGen on June 11th! Our LA event for builders working at the intersection of AI agents, creative tooling, and multimodal apps is now open for registration 👇
x.com/HeyGen/status/20622567…

HeyGen Google DeepMind in LA on June 11
A night of demos, conversations, and people building with agents, multimodal apps, and creative tools
Got something interesting? Lightning demo slots are open.
luma.com/heygen-xesd

6
6
50
7,854
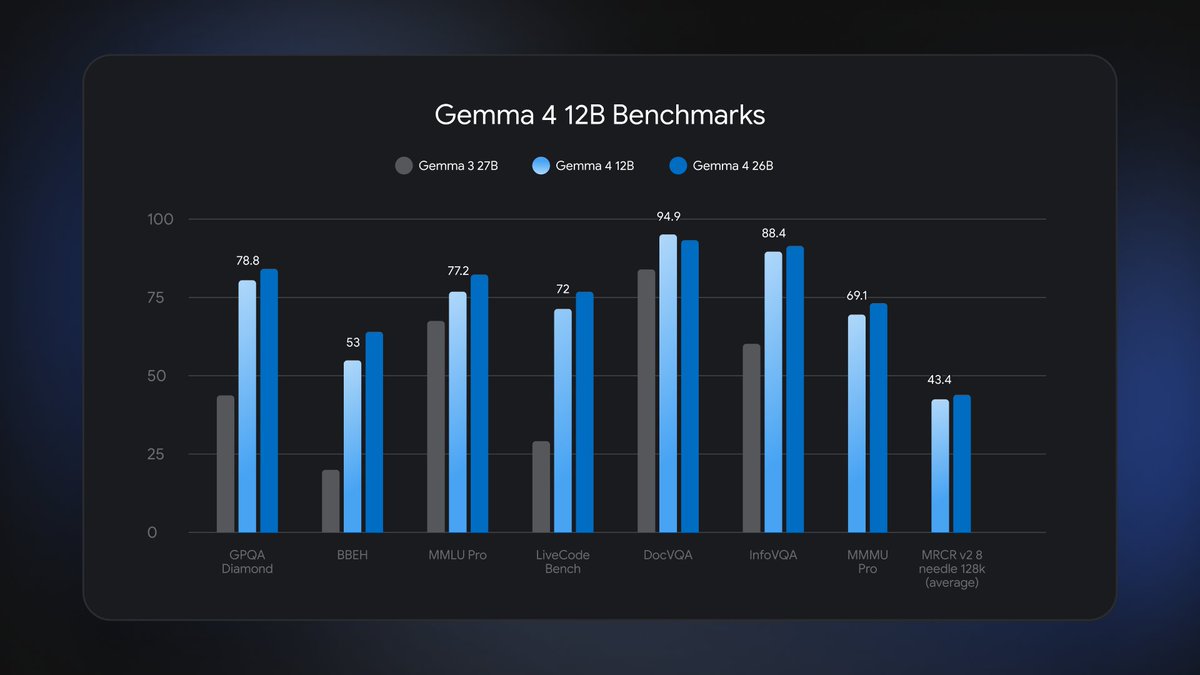
We’re launching Gemma 4 12B: Our unified, encoder-free model that brings powerful multimodal intelligence straight to your laptop 🚀
The model bridges the gap between our mobile E4B model and larger 26B MoE models, packaging frontier-class reasoning and native audio into a highly optimized footprint, all under a permissive Apache 2.0 license.
Here’s what makes it unique:
Encoder-Less Architecture: We removed the multimodal encoders. The vision and audio inputs flow directly into the LLM backbone.
Agentic Performance (16GB VRAM): Run complex, multi-step workflows locally, with performance nearing our 26B model.
34
145
1,097
68,986
> Ecosystem: Compatible with llama.cpp, MLX, @LMStudio, vLLM, @ollama, @UnslothAI, and SGLang.
> Download: Grab the weights on @Kaggle and @HuggingFace: huggingface.co/collections/g…
3
2
51
6,390
- Read the blog to learn more: goo.gle/4elEBO4
- Check out the developer guide: goo.gle/4o3HJRY
2
14
3,156
Building autonomous agents for scientific discovery? 🧬🤖
@GoogleDeepMind Science Skills is now available on GitHub. We've open-sourced this specialized toolkit to accelerate your agentic workflows with scientific grounding and higher token efficiency.
Download now ↓
github.com/google-deepmind/s…
31
269
1,604
88,620
Check out how you can use Science Skills ↓
antigravity.google/use-cases…
1
6
36
5,141