
The LLM tuning & inference platform for enterprises. Factual LLMs. Deployed anywhere.
Joined April 2023
- Tweets 308
- Following 9
- Followers 6,323
- Likes 433
40 Photos and videos







🎯 Aiming for 90% accuracy on your Text-to-SQL agent, but can't get past 50%? With our proven methodology, our customers have cracked the code and hit 9s of accuracy!
We're spilling the tea 🍵 in our upcoming webinar. Bring your toughest Text-to-SQL questions—we’ve got answers! 💪
🎯 Build high-accuracy Text-to-SQL BI agents
📅 March 20, 2025
🕘 10:00 - 10:45 AM PT
🔗 Register here today: bit.ly/41qIycU
1
1
6
2,391
Join us for a webinar on building Text-to-SQL BI agents. We’ll show how to finetune any open LLM to reach 90% accuracy. Register now bit.ly/41qIycU
🎯 Build high-accuracy Text-to-SQL BI agents
📅 March 20, 2025
🕘 10:00 - 10:45 AM PT
3
2,188
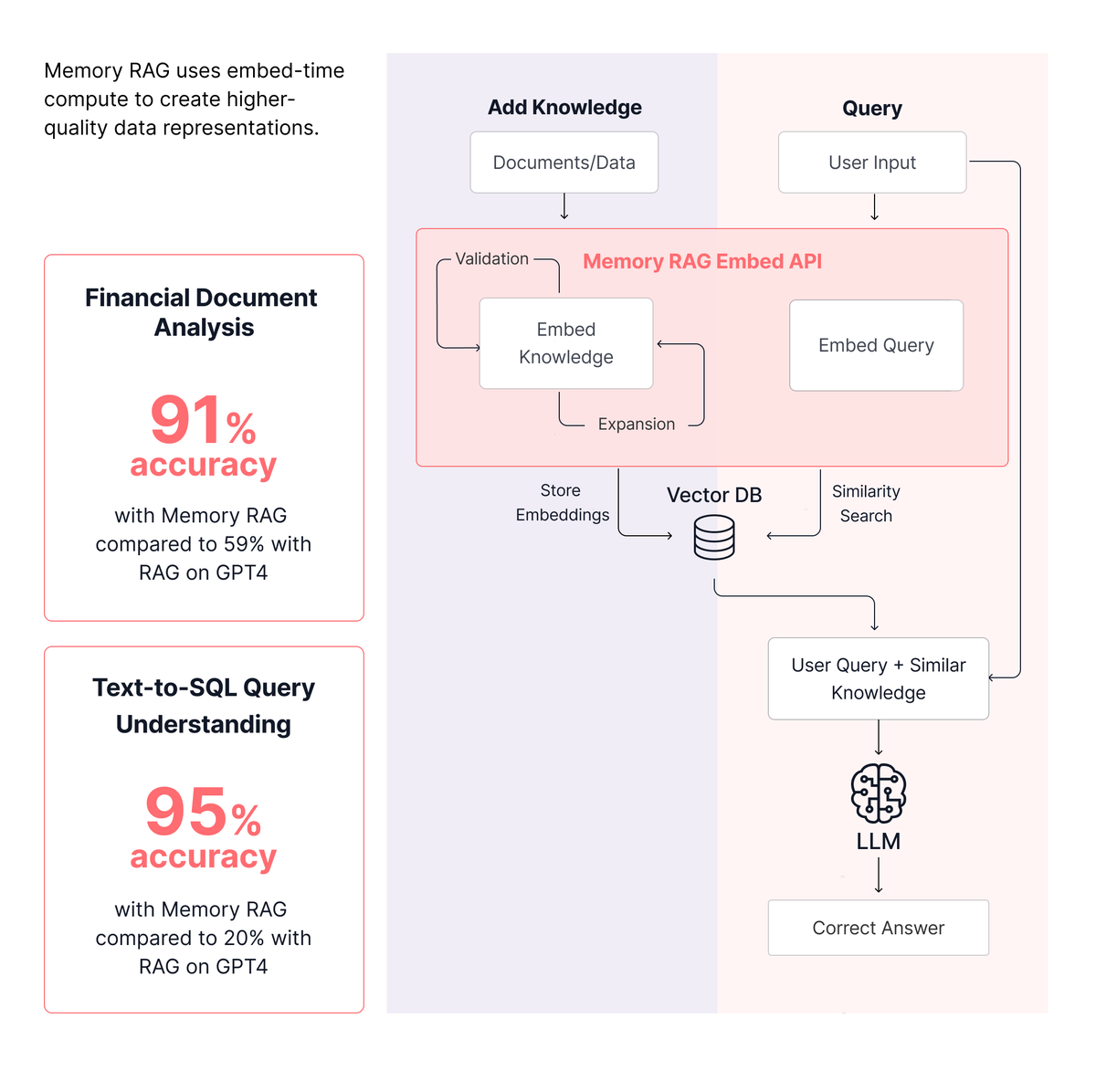
🙌Introducing Memory RAG—a simpler approach to RAG that leverages embed-time compute to create more intelligent, validated data representations. Build mini-agents with a simple prompt.
Get the paper: hubs.la/Q0333d5c0
4
10
1,939
Thanks @DeepLearningAI for featuring us in The Batch!
deeplearning.ai/the-batch/a-…
4
1,179
Have you seen our Classifier Agent Toolkit 😺 demo yet?
Learn how to use our SDK to build a highly accurate Classifier Agent for a customer service chatbot. The agent categorizes customer interactions by intent so it can respond appropriately. You can run multiple evaluations until you reach your desired level of accuracy.
youtube.com/watch?v=-wadT3ds…
1
2
6
3,491
Lamini retweeted

11 Dec 2024
I'm so excited to launch @LaminiAI’s Classifier Agent Toolkit, aka. CAT! 🚀🐱 CAT hunts & tags the important signals 🐭 in a vast amount of data — so devs can easily create agentic classifiers.
❌ Manual data labeling
❌ Large, slow general LLM calls that can only handle 20-30 categories with mid accuracy
✅ CAT has helped our customers tag 2,000 pages across 1,000 categories in just 3.6 seconds with 99.9% accuracy. Dev time? A few hours to a few days. Hallucinations? Approaching zero. Meow.
Some common agentic classifiers with CAT:
◽️Customer service agents that extract user intent
◽️Finding high severity tickets, so your teams can prioritize urgent issues
◽️Triage legacy application code based on importance, to prioritize development
◽️Analyze sentiment in earnings calls, reviews, posts, surveys, etc.
More on it 👉 lamini.ai/classifier
Demo from one of our amazing architects Scott youtube.com/watch?v=-wadT3ds…
Happy holidays, hope you like our gift 🎁 Reach out anytime to fill our inbox with cheer at info@lamini.ai (we read, we respond!) This was a huge effort by the entire Lamini team 🎀
1
7
43
5,027
🎁 Our new Classifier Agent Toolkit (CAT 🐱) is here! No more extensive manual data labeling or heavy ML systems.
😻 Build classifier agents that can quickly categorize large volumes of data at 95% accuracy / 400k token throughput in under 2 seconds.
Watch the demo and get the link to the docs and repo here: lamini.ai/classifier-agent-t…
2
1,062
🙌 Our new Enterprise Guide to Fine-Tuning is out! If you can't get above 40-50% accuracy with RAG, fine-tuning might be the answer. Learn the basics of fine-tuning and specific applications and use cases. bit.ly/495Q7c9
1
1
2
786
.@realSharonZhou recently spoke at @Aurecon's #ExemplarForum2024 on high-ROI use cases for LLMs and overcoming key challenges in AI deployment, including poor model quality, hallucinations, costs, and security. Watch the video here: youtube.com/watch?v=gLXT4ljO…
1
1
8
1,229
🎉🎉🎉 Excited to announce our new pay-as-you-go offering, Lamini On-Demand. Get $300 in free credit to run your tuning and inference jobs on our high-performance GPU cluster. Happy tuning! lamini.ai/blog/lamini-on-dem…
1
6
1,108
LLM inference frameworks have hit the “memory wall”, which is a hardware imposed speed limit on memory bound code. Is it possible to tear down the memory wall? @GregoryDiamos explains how it works in his new technical blog post.
lamini.ai/blog/evaluate-perf…
1
3
13
2,653
Go from AI novice to fine-tuning wiz with our Improving Accuracy of LLM Applications course with @DeepLearningAI @asangani7. Here's one student's experience getting to 96% accuracy on factual data in just 3 iterations. lamini.ai/blog/llm-accuracy-…
2
9
1,059
Vertical vs. horizontal AI use cases? GitHub Copilot started vertical and crossed over into horizontal applications. Low latency accuracy were key! Thanks for the great discussion @gajenkandiah and @Hitachi!
youtube.com/watch?v=4Wn-rEzg…
5
694
Like many startups, our tech is possible because of access to open source LLMs.
@realSharonZhou @matthew_d_white @starlordxie and @pentagoniac recently discussed the importance of an open ecosystem and implications of SB 1047.
Thanks to @AIatMeta and @cerebral_valley for hosting and bringing awareness to SB 1047!
2
15
89
34,556
Lamini retweeted

22 Aug 2024
🆕 New course on @DeepLearningAI: Improving Accuracy of LLM Applications ➡️ go.fb.me/zfwvd8
Created in collaboration with DL, Meta & @LaminiAI, this free course covers topics like evaluation frameworks, instruction & memory fine-tuning, LoRA training data generation.
11
85
325
34,070
Lamini retweeted

15 Aug 2024
🎉We're excited to share how @LaminiAI, a leading AI cloud service provider, is leveraging our Supermicro GPU Servers to support their large-scale #LLM tuning and generative #AI models. Read our Success Story: hubs.la/Q02LtN5D0 #GenAI #datacenter #GPU #supermicro

11
7
36
18,077
Lamini retweeted

14 Aug 2024
Learn a development pattern to systematically improve the accuracy and reliability of LLM applications in our new short course, Improving Accuracy of LLM Applications, built in partnership with @LaminiAI and @Meta, and taught by Lamini’s CEO @realSharonZhou, and Meta’s Senior Director of Partner Engineering, @asangani7. (Disclosure: I am an investor in Lamini.)
The path to tuning an LLM application can be complex. In this course, you'll learn a systematic sequence of steps for improving accuracy by reducing hallucinations:
- Create an evaluation dataset to measure model accuracy
- Add prompt engineering and self-reflection
- Fine-tune your model including "memory-tuning" which is a new method of embedding facts in an LLM
Using the Llama 3-8B parameter model, you will:
- Build a text-to-SQL agent with a custom schema and simulate situations where it hallucinates
- Understand the difference between instruction fine-tuning, which gives pre-trained LLMs instructions to follow, and memory fine-tuning
- See how Performance-Efficient Fine-tuning (PEFT) techniques like Low-Rank Adaptation (LoRA) reduce training time by 100x and Mixture of Memory Experts (MoME) reduces it even further
I appreciate Meta releasing the Llama's family of open models -- this course gives an example of the unique type of work that developers can do with such models.
Please sign up here: deeplearning.ai/short-course…
22
124
621
66,410
Lamini retweeted
14 Aug 2024
We at @Meta & @LaminiAI & @DeepLearningAI have built a course for you!
🚀 Improving Accuracy of LLM Applications:
deeplearning.ai/short-course…
◽️ Reliable agents & apps are here - it's just a matter of effort.
◽️ The effort is now a ton lower because of... LLMs themselves!
◽️ Evals shouldn't *just* evaluate your LLM, but actually be used to actively improve it (as a north star)
◽️ This course walks through Meta's llama recipe w/ Lamini on building a text-to-SQL agent with a custom schema that removes hallucinations
2
11
92
9,233
What @AndrewYNg said...
14 Aug 2024

Learn a development pattern to systematically improve the accuracy and reliability of LLM applications in our new short course, Improving Accuracy of LLM Applications, built in partnership with @LaminiAI and @Meta, and taught by Lamini’s CEO @realSharonZhou, and Meta’s Senior Director of Partner Engineering, @asangani7. (Disclosure: I am an investor in Lamini.)
The path to tuning an LLM application can be complex. In this course, you'll learn a systematic sequence of steps for improving accuracy by reducing hallucinations:
- Create an evaluation dataset to measure model accuracy
- Add prompt engineering and self-reflection
- Fine-tune your model including "memory-tuning" which is a new method of embedding facts in an LLM
Using the Llama 3-8B parameter model, you will:
- Build a text-to-SQL agent with a custom schema and simulate situations where it hallucinates
- Understand the difference between instruction fine-tuning, which gives pre-trained LLMs instructions to follow, and memory fine-tuning
- See how Performance-Efficient Fine-tuning (PEFT) techniques like Low-Rank Adaptation (LoRA) reduce training time by 100x and Mixture of Memory Experts (MoME) reduces it even further
I appreciate Meta releasing the Llama's family of open models -- this course gives an example of the unique type of work that developers can do with such models.
Please sign up here: deeplearning.ai/short-course…
1
5
1,049
Our new @DeepLearningAI course on Improving Accuracy of LLM Applications is live! If you are short on time but curious about fine-tuning LLMs, this is the course for you!
14 Aug 2024

Learn how to improve the accuracy of your LLM apps in our new course with @LaminiAI & @Meta.
Taught by experts @realSharonZhou & @asangani7, you’ll learn a development pattern to systematically improve the reliability and accuracy of LLM apps.
Join now: hubs.la/Q02Lhdcz0
2
12
5,827