
Ship great agents fast with our open source JS frameworks – LangChain, LangGraph, and Deep Agents. Maintained by @LangChain.
Joined January 2026
- Tweets 218
- Following 15
- Followers 2,097
- Likes 158
Photos and videos

Jun 11
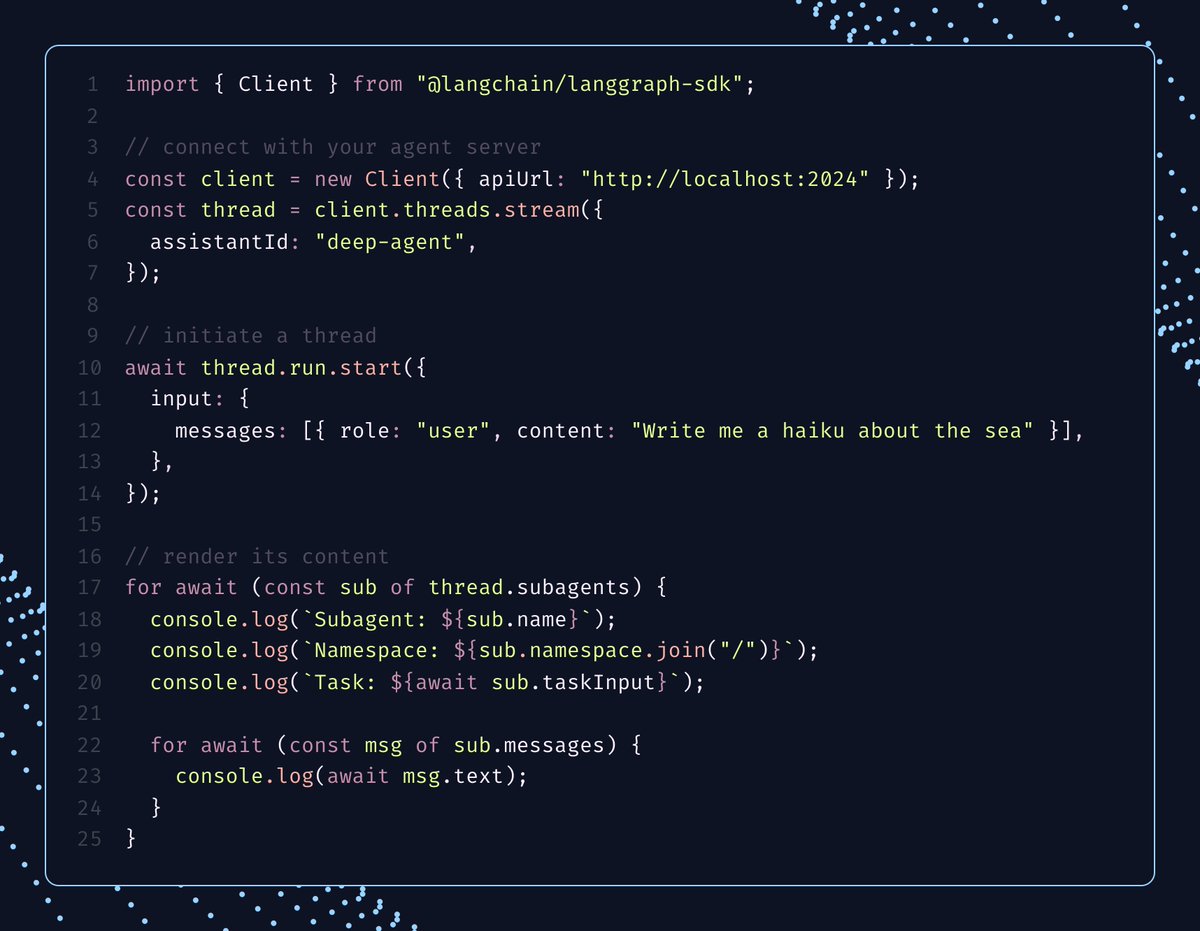
Subagents shouldn’t disappear inside one assistant bubble. With Deep Agents streaming, UIs can subscribe to delegated work as first-class objects: task input, messages, tool calls, and status while the parent run continues.
📚 Docs: docs.langchain.com/oss/javas…
1
4
613
Jun 11
The primitive is the projection: thread.subagents yields each delegated worker as it appears, with its own namespace, task input, messages, and tool calls. Build whatever surface you need on top: logs, cards, timelines, inspectors, or in-process monitors.
119
Jun 10
LangGraphJS 1.4.0 is out 🙌 with tons of new features 👀
👉 Drain/resume graphs safely
👉 recover from node failures
👉 bound runaway work with timeouts
👉 reduce checkpoint bloat with DeltaChannel for durable agents.
... and more!
Release notes: github.com/langchain-ai/lang…
🧵👇
1
249
Jun 10
And finally: DeltaChannel for long-running agents with big state 🚀
Instead of serializing the full accumulated value into every checkpoint, it stores per-step writes and reconstructs state on read, with periodic snapshots to bound replay. Huge for message-heavy threads.
1
41
Jun 10
All features are part of our effort to ship best in class fault tolerance capabilities in LangGraph 🙌
More on this in our latest blog post: langchain.com/blog/fault-tol…
1
38
Jun 10
Agents don't just need access to services.
They need access to where users actually work.
Browsers. Apps. Devices. Local state.
A look at how headless tools bring those capabilities directly into the agent loop.

1
107
Jun 8
Don't loose your customer when they switch between application views. useStream reconnects to your thread mid run and reconciles state and messages outside of runs, making UI thread management easy to manage 😊
Docs: docs.langchain.com/oss/javas…
Jun 8
It's crazy how many agent chat UIs still loose everything if I refreshes the app mid-run 😳🙈
Agents run for minutes: research, code gen, deep analysis. Losing all of that to a tab refresh isn't acceptable 🙅
@LangChain_JS agent streams are durable by default:

2
228
May 27
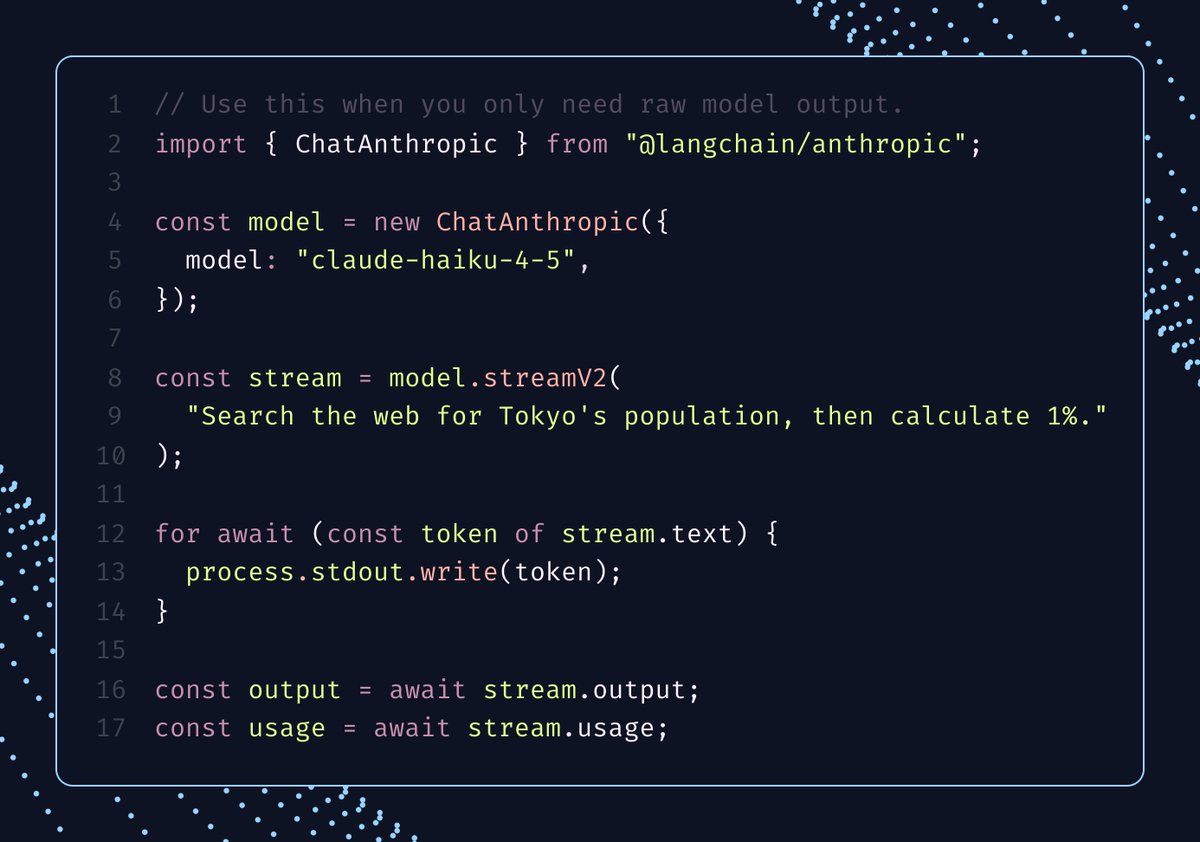
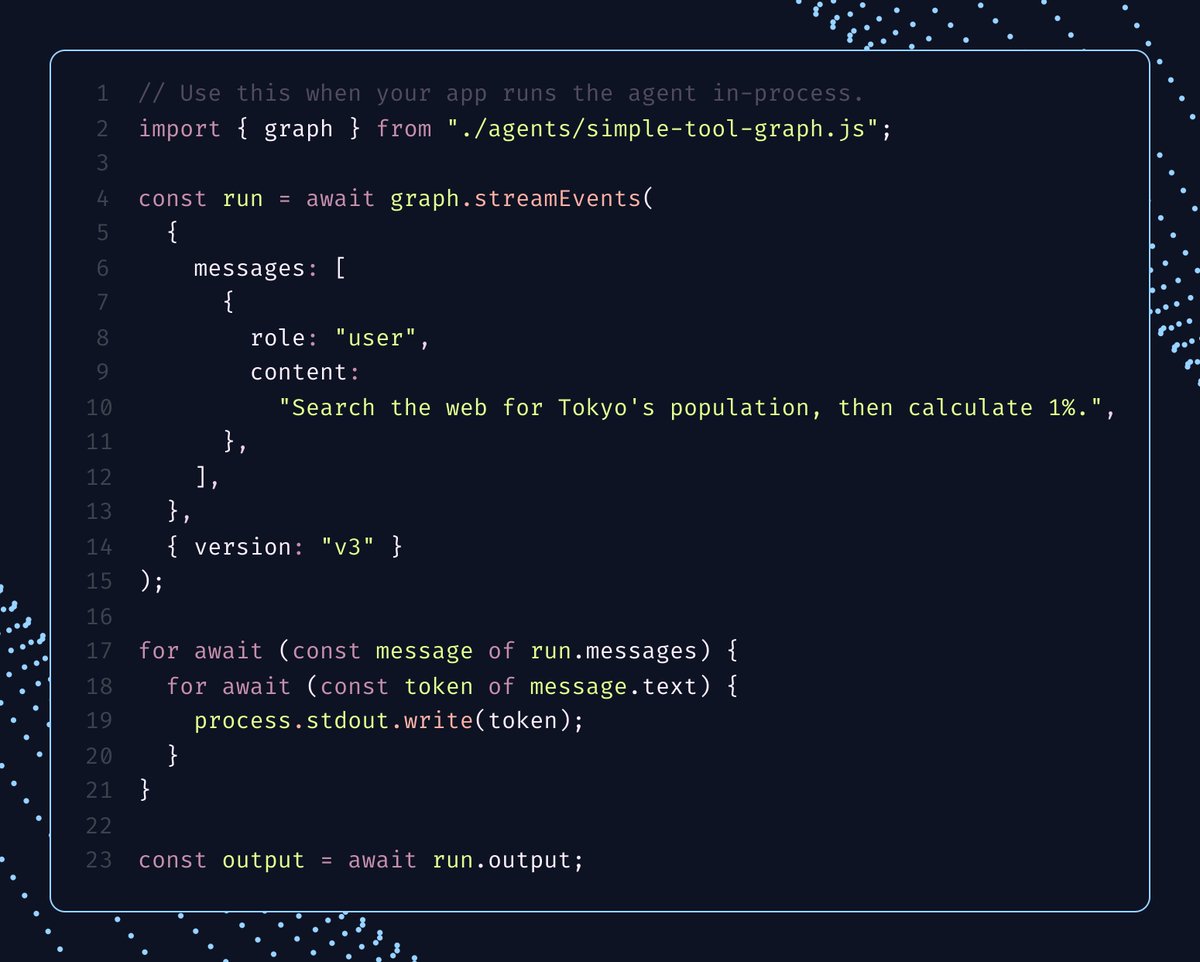
Streaming in LangChain/LangGraph now has one mental model across the stack: start a model, agent, or SDK stream, then read the same projections: .text, .reasoning, .output. Same async iteration, same final value.
One flow, everywhere. That's the win 🥇

1
1
12
2,706
May 26
A sweet example of what you can build with @LangChain streaming: a tiny multimodal bedtime story app where the story, illustrations, and narration audio arrive as they are generated.
Built with @langchain/react media hooks LangGraph SSE streaming 🚀
May 26
As an upcoming parent, I keep imagining all the tiny routines ahead 😊👼
One I am especially excited for: using AI for making up bedtime stories.
So I built an app that creates one on demand: story, illustrations, and narration all streaming in together with @LangChain_JS ❤️
1
2
9
4,945
May 26
🗣️ New in @LangChain_JS 1.4.3: register streamTransformers on middleware.
Your reusable agent extensions can now ship their own v3 streaming channels alongside hooks and tools, merged at compile time with full TypeScript inference on run.extensions.
Same composability as middleware tools. Better encapsulation for packaged agent features 📦

1
1
6
458
LangChain JS retweeted

May 20
2
23
113
43,838
May 20
ICYMI: You can now give your agents an in-memory TypeScript interpreter to enable some novel agent capabilities. Built using oxc and quickjs.
See this writeup on how to use it!
May 20

we're adding interpreters to our agents, and now so can you!
There's a lot of interesting patterns/ agent behaviors I've seen come across the timeline that depend on some way to run code (think PTC, CodeMode, RLM), but it's been hard to filter that down into an abstraction thats easy to work with. We've spent the last couple of weeks creating an abstraction to solve just that!
Expect me to yap more about this soon - there's a lot to talk about here that was hard to fit into a single post
3
8
1,613
LangChain JS retweeted

May 7
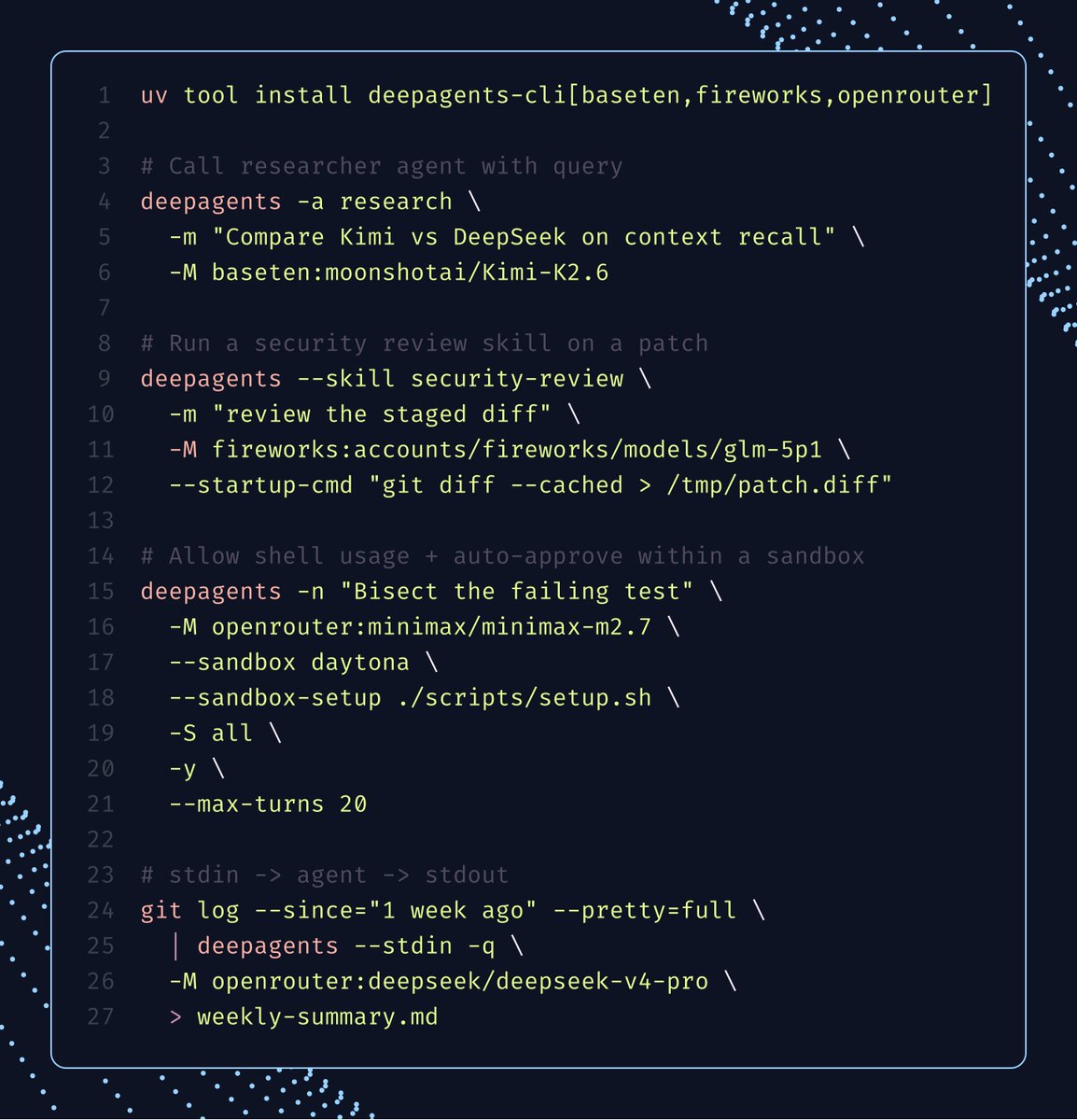
your daily reminder that open models are plenty capable for a lot of coding work. easiest place to feel that out is deepagents! swap the model and go.
i've been enjoying GLM-5.1, Kimi K2.6, MiniMax M2.7, DeepSeek V4 Pro.
here's some examples using our CLI agent in headless mode
4
10
34
12,823
LangChain JS retweeted
May 6
small workflow note that adds up.
/staged-pr is a skill (via slash command) i run when wrapping up a PR. it takes my staged code changes and drafts a concise PR title & description, based on my preferences and our repo conventions. it's routine, formulaic, and well-scoped. i hit it 20 times a day.
in the Deep Agents CLI i use /model to swap mid-session: heavier frontier model for the actual coding, then over to glm 5.1 (via @OpenRouter ) or kimi 2.6 (via @baseten) for the skill.
it yields indistinguishable quality differences, runs faster, and is ~5x cheaper than leading LLMs.
the broader point: matching the model to the task beats picking one model for everything. open models are extremely good at the long tail of routine agent work, even if frontier still wins the hard stuff.
a lot of what we point frontier models at isn't actually that hard!
-- linking skill below for those interested in trying it out
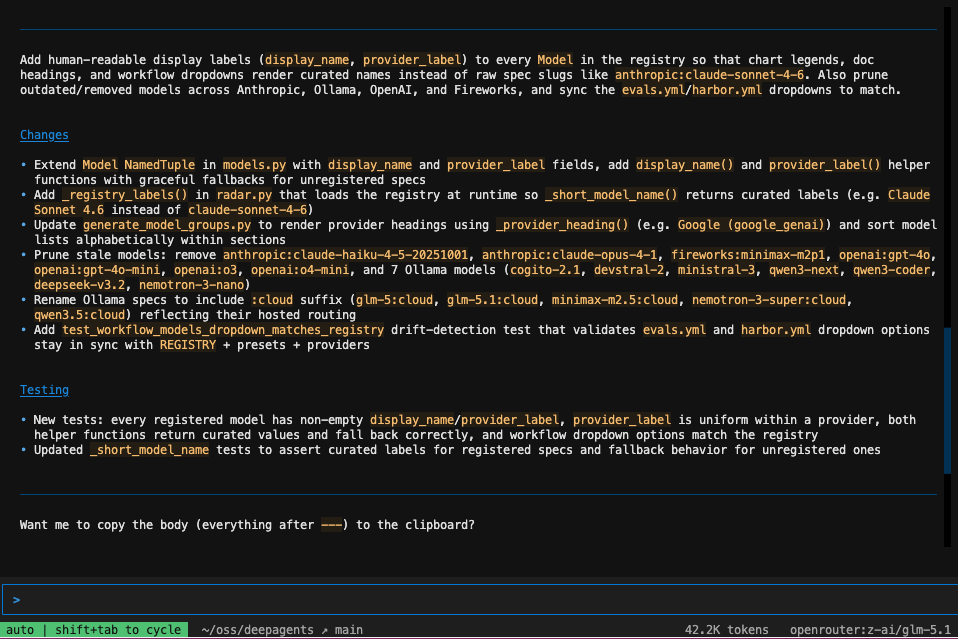
May 4

deepagents-cli is quietly becoming the best place to start coding with open weight models.
we've been investing heavily in making it a harness that's truly model-agnostic, without compromising performance!
different models perform best with different harnesses -- prompts, middleware, settings. our recent profiles API (below) lets you bundle all of that per model, so Kimi, Qwen, GLM, etc. can drive the agent loop just as well as the closed frontier.
more info on profiles x.com/Vtrivedy10/status/2049…
other recent wins worth highlighting:
- /agents - swap agent profiles mid-session (coding agent/content writer/custom)
- /model - fuzzy switcher w/ live status; OpenRouter, LiteLLM, Baseten, hosted Ollama all built-in
- headless mode w/ --json --max-turns for scripting
- --acp to run as an ACP server
- /skill:name skills
- MCP w/ OAuth
full docs and quickstart ⬇️
3
4
11
2,474
LangChain JS retweeted
May 6
we're continuing to see clear examples where a model's harness is a major determinant of overall performance. with the same model, running on same task, it's easy to observe very different scores depending on (system) prompts, tools (& their descriptions), and middleware (steering hooks).
this is exactly why we built a harness profiles abstraction in Deep Agents: per-provider or per-model overrides for base system prompts, tool names implementations, etc., so swapping models doesn't mean losing the work that made the last one good!
10–20pt jumps on tau2-bench in our own testing.
currently cooking up built-in profiles for popular open weight models 🧑🍳
langchain.com/blog/tuning-de…
May 6

you've heard that models are highly trained in their harnesses, but...
it appears that pi is about 7-10% better than codex with gpt-5.4 on a ProgramBench task.
Same exact prompt, same environment. It's a good harness.

ALT see ProgramBench.com
6
7
33
15,232
LangChain JS retweeted
May 6
the deeper point: model choice and harness choice aren't independent variables.
benchmarking a model without specifying the harness is like benchmarking a chip without specifying the compiler. the number means something, but not what people think it means.
profiles make the harness a first-class, named object — you can diff it, version it, and swap it when you swap models.
May 6
we're continuing to see clear examples where a model's harness is a major determinant of overall performance. with the same model, running on same task, it's easy to observe very different scores depending on (system) prompts, tools (& their descriptions), and middleware (steering hooks).
this is exactly why we built a harness profiles abstraction in Deep Agents: per-provider or per-model overrides for base system prompts, tool names implementations, etc., so swapping models doesn't mean losing the work that made the last one good!
10–20pt jumps on tau2-bench in our own testing.
currently cooking up built-in profiles for popular open weight models 🧑🍳
langchain.com/blog/tuning-de…
1
6
12
2,422