
Professor at Wroclaw University of Science and Technology
Joined March 2012
- Tweets 116
- Following 137
- Followers 110
- Likes 32
16 Photos and videos












Jun 17
The "most accurate" LLM for systematic-review screening silently discarded 63% of the relevant papers.
Our new open-access paper @ISTJrnal (Information and Software Technology) shows why standard metrics mislead — and what to use instead. 🧵
doi.org/10.1016/j.infsof.202…
1
1
93
Jun 17
LLM4SCREENLIT = recommendations for authors AND a one-page checklist for editors/reviewers, split by study type (benchmarking vs deployment). Validated on 9 LLMs × 24 SE secondary studies (34,528 articles). With Prof. Barbara Kitchenham & @ProfMShepperd .
1
2
21
Jun 17
Everything is open:
📄 Paper (CC-BY): doi.org/10.1016/j.infsof.202…
🧰 Replication package — R/Python metric scripts fillable checklist: doi.org/10.6084/m9.figshare.…
Use it and adapt it.
18
Feb 21
Personalized Share Link to our new @ISTJrnal paper "Test case prioritization: A systematic review using snowballing and TCPFramework with approach combinators":
authors.elsevier.com/a/1me%7…
1
1
100
Feb 21
New paper in Information & Software Technology🚀
We introduce "approach combinators"—ensemble Test Case Prioritization methods improving regression testing.💡
By T. Chojnacki & @LechMadeyski
🔗 doi.org/10.1016/j.infsof.202…
#SoftwareTesting #TestCasePrioritization #SoftwareEngineering
2
1
42
Feb 21
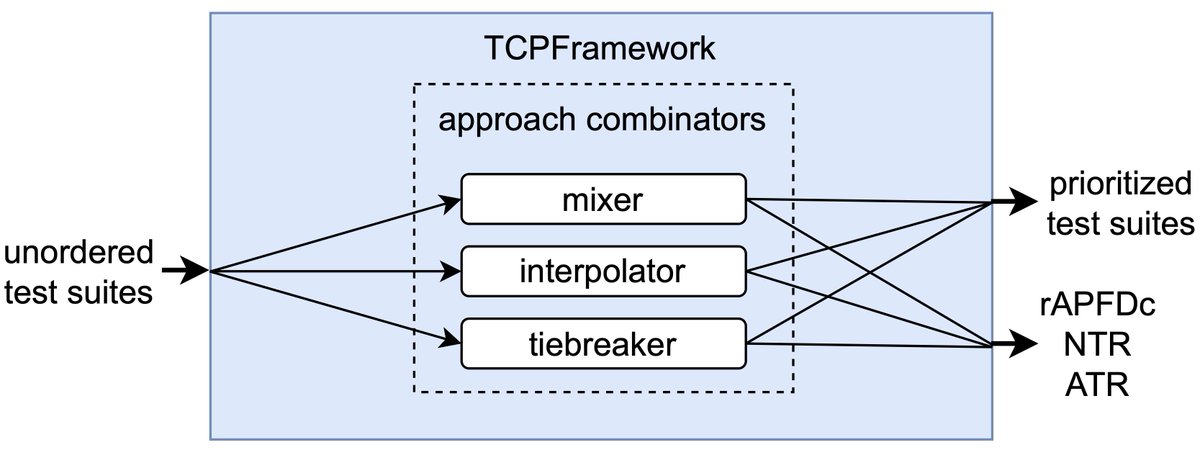
📊 How does it work?
The graphical abstract below presents a simplified view of our framework.
Test suites are passed through different combinations of simple models to produce a highly efficient test ordering—without the need for heavy computation.
👇
1
32
Feb 21
💡 The Results:
By integrating existing strategies, approach combinators consistently improve regression testing.
The ultimate takeaway? We achieve state-of-the-art TCP performance across diverse software projects! 🏆
#QA #CICD #AcademicTwitter
31
9 Jan 2025
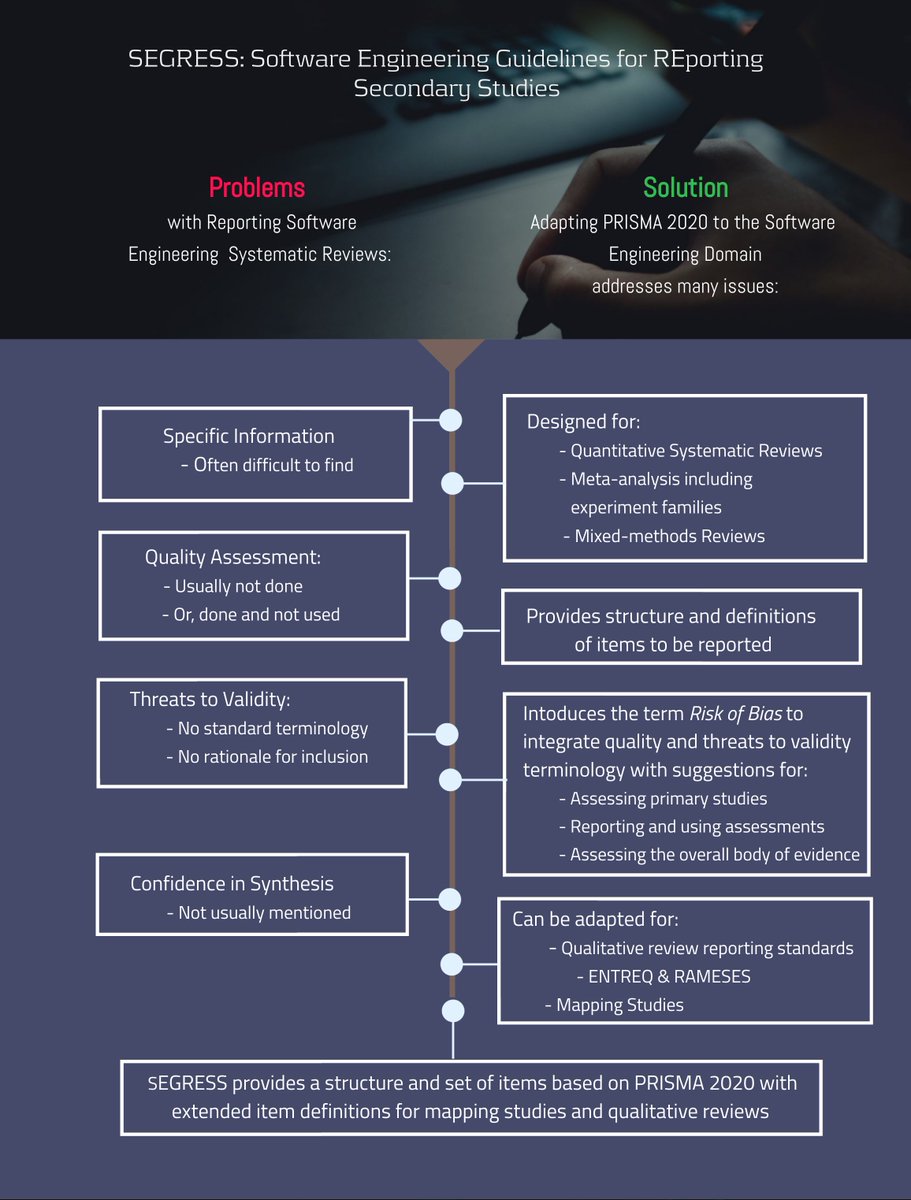
Exciting! e-Informatica Software Engineering Journal (e-informatyka.pl/) just published "Guidelines for Conducting Action Research Studies in Software Engineering" by @MiroslawStaron 👉🏼doi.org/10.37190/e-Inf250105
Let's make 2025 an #ActionResearch year in #SoftwareEngineering
4
93
9 Jan 2025
Happy to share the effect of research visit at BTH and collaboration with @wnukkris et al. We analyzed usage of requirements attributes in industry (2 industrial case studies) & literature👉🏼 doi.org/10.1007/978-3-031-70… or madeyski.e-informatyka.pl/do… #requirementsengineering #requirements
2
77
18 Aug 2024
Interested in “Recommendations for analysing and meta-analysing small sample size software engineering experiments”? 👉🏼My joint paper doi.org/10.1007/s10664-024-1… with Prof. Kitchenham in @emsejournal
#MetaAnalysis #EffectSize #NonParametric #ReproducibleResearch #SoftwareEngineering
1
1
5
400
18 Aug 2024
Tests based on pˆ always had better or equal power than tests based on Cliff’s d, and across all but one simulation condition, pˆ Type 1 error rates were less biased.
1
54
18 Aug 2024
Conclusions: Using pˆ is a low-risk option for analysing and meta-analysing data from small sample-size SE randomized experiments. Parametric methods are only preferable if you have prior knowledge of the data distribution.
49