
training code-gen agents @cohere | open-source @AdapterHub (100k PyPI installs/mo) | prev. @UKPLab | 🇩🇪→🇨🇦
Joined October 2022
- Tweets 77
- Following 336
- Followers 293
- Likes 634
14 Photos and videos








Pinned Tweet

We're just 8 people on our core code team and our 30B-A3B model lands on par with Claude Haiku 4.5 and ahead of NVIDIA's 120B-A12B Nemotron 3 Super on the Artificial Analysis Coding Index. Released under Apache 2.0. Very proud of our work & lots more to come!

Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
19
24
455
31,671
Leon Engländer retweeted
We're just 8 people on our core code team and our 30B-A3B model lands on par with Claude Haiku 4.5 and ahead of NVIDIA's 120B-A12B Nemotron 3 Super on the Artificial Analysis Coding Index. Released under Apache 2.0. Very proud of our work & lots more to come!
Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
19
24
455
31,671
Leon Engländer retweeted

Jun 9
One of many more great open source models by Cohere. Optimized for local coding agents.
Cohere is on a mission to enable sovereign AI, and being able to locally host models is part of this mission.
Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
5
3
39
2,149
Leon Engländer retweeted
Ah, and if someone reading this wants to join our incredible code agents team to do research: we're hiring. jobs.ashbyhq.com/cohere/70a8…
1
1
16
1,203
We're just 8 people on our core code team and our 30B-A3B model lands on par with Claude Haiku 4.5 and ahead of NVIDIA's 120B-A12B Nemotron 3 Super on the Artificial Analysis Coding Index. Released under Apache 2.0. Very proud of our work & lots more to come!
Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
19
24
455
31,671
Ah, and if someone reading this wants to join our incredible code agents team to do research: we're hiring. jobs.ashbyhq.com/cohere/70a8…
1
1
16
1,203
Leon Engländer retweeted

Jun 9
Excited to share North Mini Code: Our first open-source coding model. It is small but very strong in agentic coding for its size🔥
I’m incredibly proud of the team — Shipping a model like this takes outstanding research, engineering, infrastructure, and collaboration.
Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
2
12
53
3,219

Leon Engländer retweeted

My team and I have made a tiny model just for Coding. 30B total 3A active. Its free in OpenCode for the next few weeks - try it out!
Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
1
5
57
3,883
Leon Engländer retweeted

Jun 9
We open-sourced a feisty small agentic coding model.
- 30B total, 3B active
- 256K total context
- Compatible with @opencode
- Apache 2.0. Weights on @huggingface
Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
19
26
394
30,457
Leon Engländer retweeted

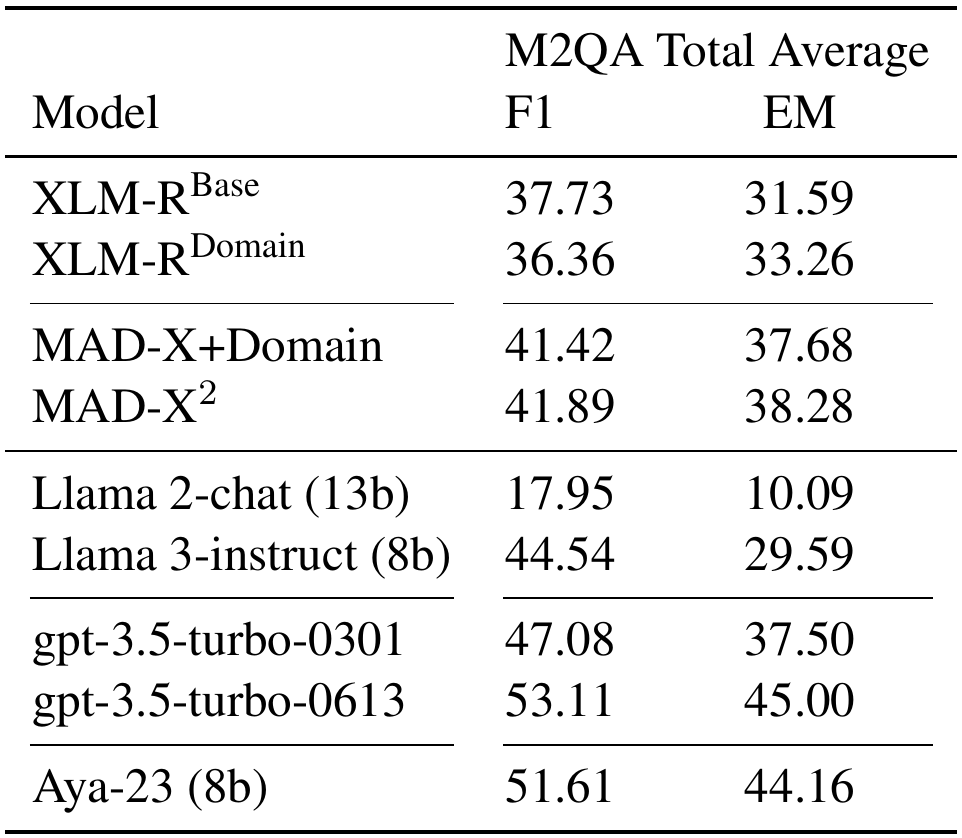
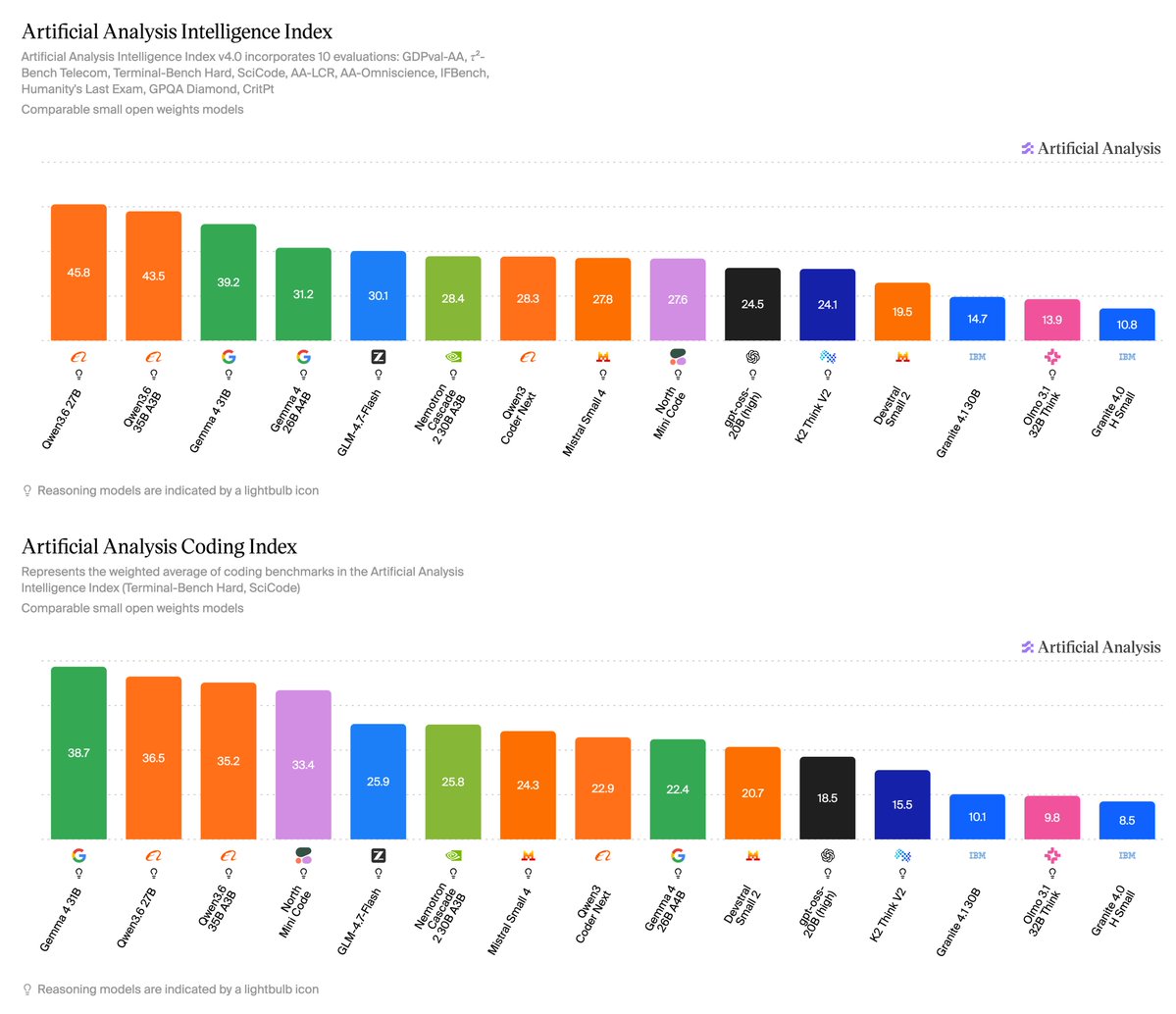
Cohere just released North Mini Code, a small 30B parameter (3B active) open weights coding model that scores 27.6 on the Artificial Analysis Intelligence Index
Less than a month since @cohere's last model release, Command A , has launched another open weights model that is optimized for coding, and much smaller at 30B total parameters and 3B active parameters.
Key Takeaways:
➤ Achieves 27.6 on the Artificial Analysis Intelligence Index, above gpt-oss-20B (high) at 24.5 and just below Mistral Small 4 (119B parameters, 6.5B active) at 27.8
➤ Scores competitively on the Artificial Analysis Coding Index (weighted average of Terminal-Bench Hard and SciCode) against open weights models in its size class, scoring 33.4, significantly above GLM-4.7-Flash at 25.9, and below Qwen3.6 35B A3B at 35.2. However, it underperforms on non-coding agentic tasks, scoring 14% on GDPval-AA and 37% on 𝜏²-Bench Telecom
➤ On Cohere’s API, North Mini Code is faster than several comparable open weights models of its intelligence and size class (~199 output tokens per second)
➤ North Mini Code is a text-only 30B total parameter and 3B active parameter model, and is open-sourced under the Apache 2.0 license
10
29
213
17,931
Leon Engländer retweeted

Jun 9
We made a small coding model. Its open source apache 2.0.
Now more than ever i think this tech needs to be built in public so that those using it are in control. Try it out if you want a small and efficient coding model.
10
26
226
95,022
Leon Engländer retweeted

It is finally out! We have created a small, efficient code agent model excelling at software engineering and terminal system tasks, go try it out! 🎉
Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
2
14
401

Command A is available on @huggingface with W4A4 quantization 🤗
Cut your serving footprint dramatically with virtually zero performance degradation.
Try it now: huggingface.co/CohereLabs/co…
Introducing: Cohere Command A
We’ve created our most powerful LLM yet, optimized it to run on as little hardware as possible, and released it open-source for all.
8
23
139
34,977
Leon Engländer retweeted

Apr 22
[AI] Agents being given a *massive* clue to a task («the solution to the task is here.txt»), still doesn’t take it. Which is something worth taking into account when using them.
Apr 21

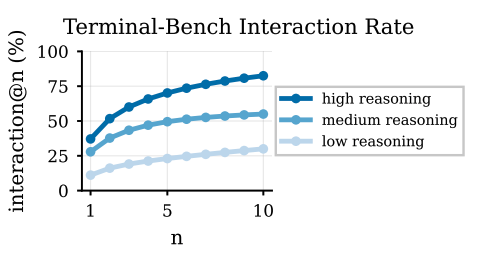
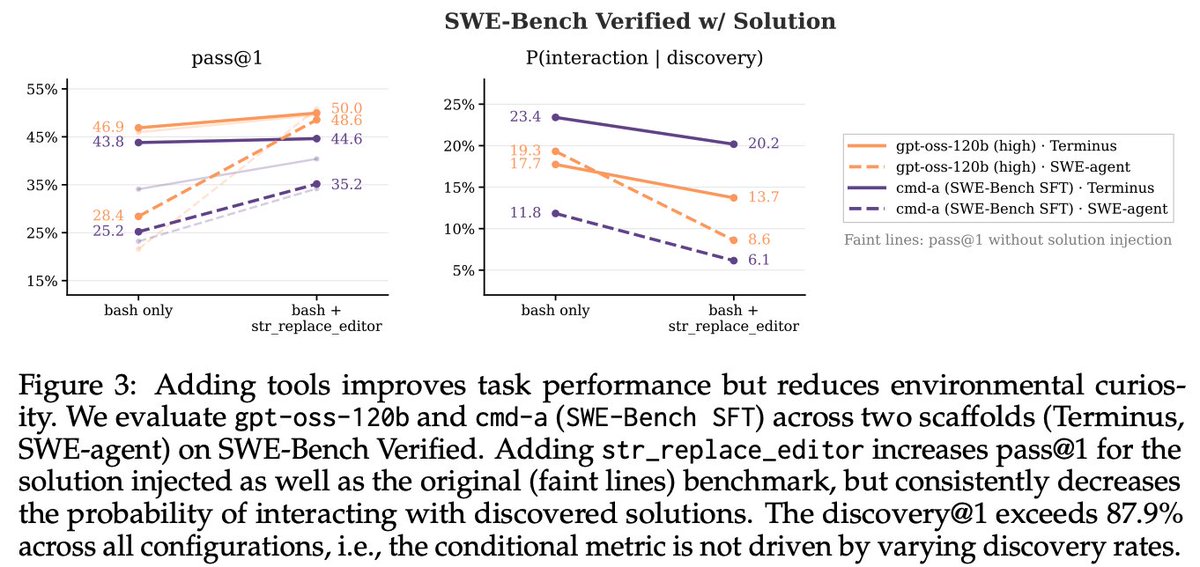
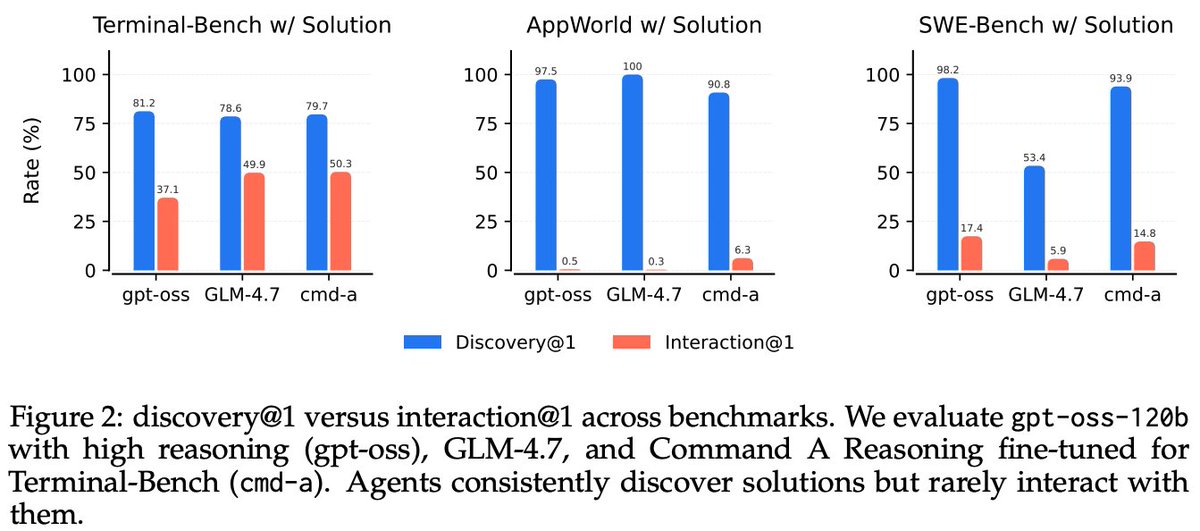
LLM agents are assumed to integrate unexpected environmental observations into their reasoning. It turns out they don't.
We added the complete task solution into agent environments as a file or an API endpoint, and measured whether agents act on what they discover. They almost never do.
Starkest example: on AppWorld, gpt-oss-120b sees a CLI command documented as "returns the complete solution to this task" in 97.54% of runs. It calls it in 0.53%. Same pattern for GLM-4.7 and other models, across Terminal-Bench, SWE-Bench, and AppWorld.
📜 arxiv.org/abs/2604.17609
🧵👇
1
2
180
Leon Engländer retweeted

Apr 22
A really fascinating look into agent behaviour and curiosity...or apparent lack thereof
We've largely operated on the assumption that if given access to a solution, agents will use it
It turns out they almost never do
It's not enough that the most intelligent systems have the capability to interact with the world
They also have to have the curiosity to do so
Apr 21
LLM agents are assumed to integrate unexpected environmental observations into their reasoning. It turns out they don't.
We added the complete task solution into agent environments as a file or an API endpoint, and measured whether agents act on what they discover. They almost never do.
Starkest example: on AppWorld, gpt-oss-120b sees a CLI command documented as "returns the complete solution to this task" in 97.54% of runs. It calls it in 0.53%. Same pattern for GLM-4.7 and other models, across Terminal-Bench, SWE-Bench, and AppWorld.
📜 arxiv.org/abs/2604.17609
🧵👇
1
3
192
Leon Engländer retweeted

Apr 21
Awesome work, really interesting findings!
1
2
1
348
Leon Engländer retweeted

it's worse
Agents *cheat* but they will never ever ever cheat like a curious human with situational awareness. At least in this setting. Actually surprising to me, what gives?
Apr 21
LLM agents are assumed to integrate unexpected environmental observations into their reasoning. It turns out they don't.
We added the complete task solution into agent environments as a file or an API endpoint, and measured whether agents act on what they discover. They almost never do.
Starkest example: on AppWorld, gpt-oss-120b sees a CLI command documented as "returns the complete solution to this task" in 97.54% of runs. It calls it in 0.53%. Same pattern for GLM-4.7 and other models, across Terminal-Bench, SWE-Bench, and AppWorld.
📜 arxiv.org/abs/2604.17609
🧵👇
1
28
3,055
Leon Engländer retweeted

Apr 21
Maybe the most fun project of last year. You throw the gold solution into the face of an LLM, it actually reads it... and then decides to ignore it
Awesome work led by @LeonEnglaender
Apr 21
LLM agents are assumed to integrate unexpected environmental observations into their reasoning. It turns out they don't.
We added the complete task solution into agent environments as a file or an API endpoint, and measured whether agents act on what they discover. They almost never do.
Starkest example: on AppWorld, gpt-oss-120b sees a CLI command documented as "returns the complete solution to this task" in 97.54% of runs. It calls it in 0.53%. Same pattern for GLM-4.7 and other models, across Terminal-Bench, SWE-Bench, and AppWorld.
📜 arxiv.org/abs/2604.17609
🧵👇
2
8
716