
Joined April 2023
- Tweets 554
- Following 219
- Followers 1,263
- Likes 4,535
156 Photos and videos












Pinned Tweet

9 Dec 2025
chroma-radiance-x0 result
a true pixel space model combining JiT-x0 loss and pixnerd
give it a go!
github.com/comfyanonymous/Co…
huggingface.co/lodestones/Ch…


11
55
423
181,849


May 24
this is pretty cool
conditional protein diffusion model!
biorxiv.org/content/10.1101/…
4
36
2,931
lodestone-rock retweeted

May 19
🎉 🎉 🎉 We're open-sourcing Chronicles-OCR, a visual perception benchmark evaluating VLLMs on ancient Chinese characters.
The dataset spans 3,000 years of evolution. It covers 7 historical scripts from Oracle Bone to Cursive, featuring 2,800 balanced images across highly diverse physical media.
We assess models on 4 core tasks:
• Character Spotting
• Fine-grained Recognition
• Ancient Text Parsing
• Script Classification
The evaluation reveals how visual distribution shifts affect model perception over time.
Explore the dataset and paper below. 👇
📄 Paper: arxiv.org/abs/2605.11960
🔗 GitHub: github.com/VirtualLUOUCAS/Ch…

2
31
154
17,334
May 12
long boi
May 11

You can just stack more layers.
MV-Split fixes the silent mean-mode collapse in ultra-deep transformers — stable to 1000 layers.
📄 Paper: arxiv.org/abs/2605.06169
🌐 Project: erwold.github.io/mv-split
💻 Code: github.com/erwold/mv-split
🤗 Models: huggingface.co/StableKirito/…

2
30
5,813
May 2
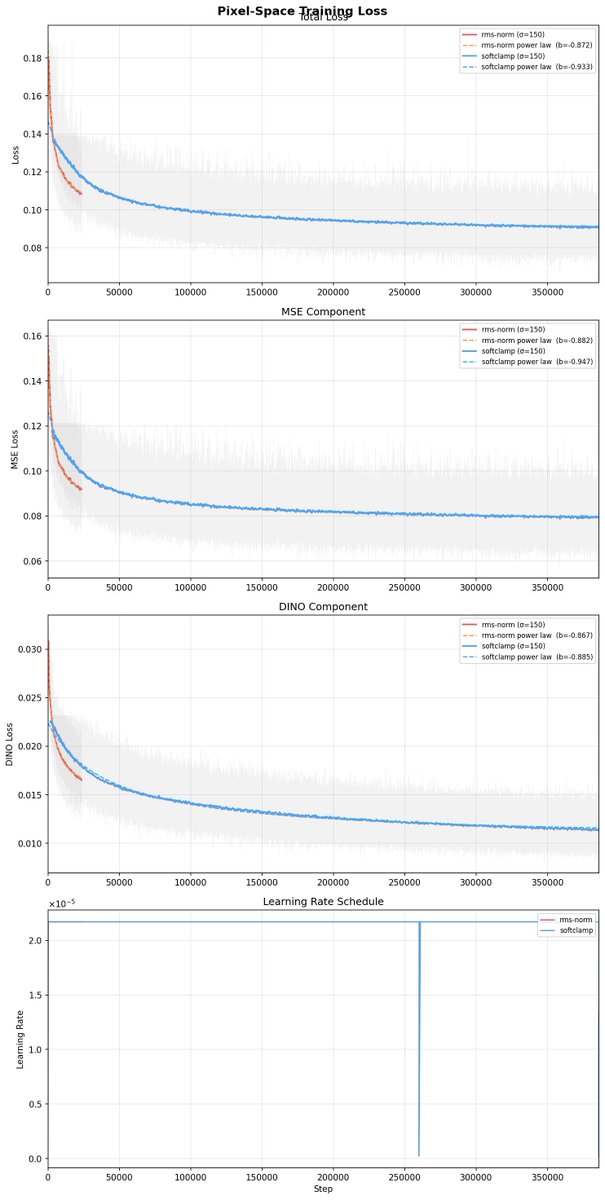
it translates really well FYI
2.5B run 20M data
RMSnorm (arxiv.org/abs/1910.07467) vs softclamp (arxiv.org/abs/2503.10622)
May 1

seems like architectural research can be done ridiculously cheaply by measuring the time to overfit into 1 sample!
RMSnorm (arxiv.org/abs/1910.07467) vs softclamp (arxiv.org/abs/2503.10622) (4000 steps fit)

3
9
84
12,799
May 2
anyone want to write a paper together to strengthen this ? with a proper side by side comparison of a single sample vs a big enough run
1
1
7
935
May 1
seems like architectural research can be done ridiculously cheaply by measuring the time to overfit into 1 sample!
RMSnorm (arxiv.org/abs/1910.07467) vs softclamp (arxiv.org/abs/2503.10622) (4000 steps fit)
10
17
354
32,954
May 2
May 2
it translates really well FYI
2.5B run 20M data
RMSnorm (arxiv.org/abs/1910.07467) vs softclamp (arxiv.org/abs/2503.10622)
1
1,617
May 1
timestep shift 2 vs 6 (5000 steps fit, both using softclamp instead of RMSnorm)

20
2,584

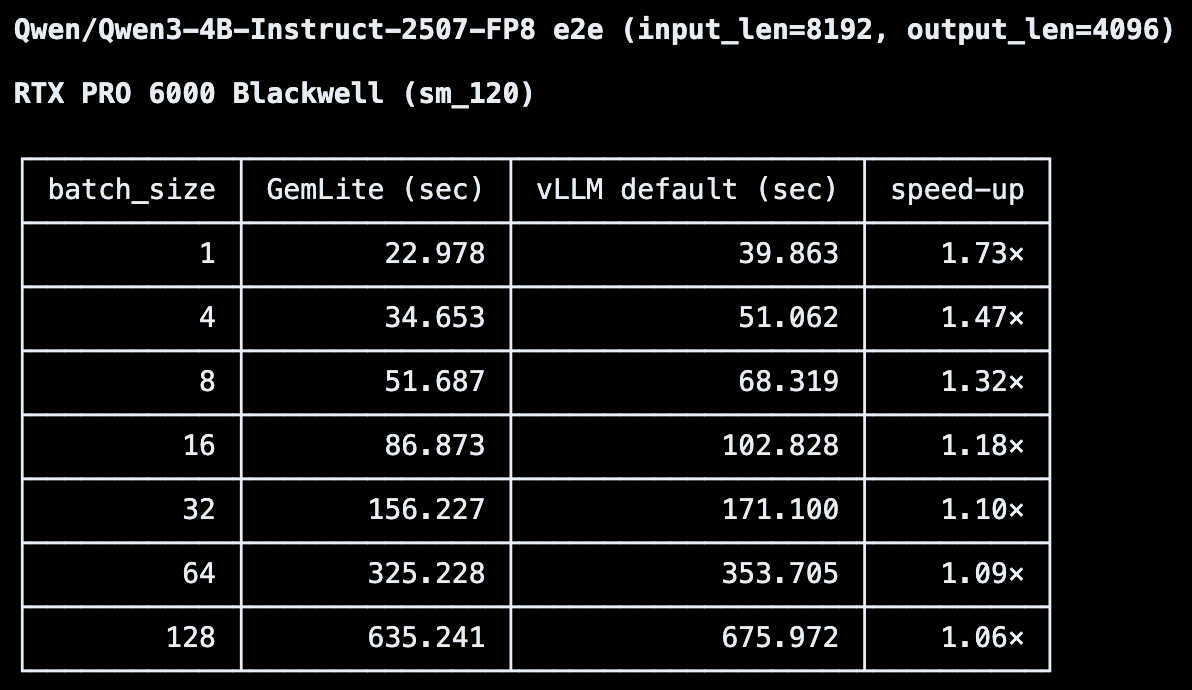
Apr 24
was debugging my x0 trainer using 1 image with lots of high frequency in it and got this interesting pattern.
it seems to converge on high freq first before everything else.
seems like x0 is doing frequency weighting implicitly based on your data distribution.
2
1
70
6,913
Apr 21
recursive model distillation be like

2
7
137
9,691
lodestone-rock retweeted

The US grid, mapped.
Public data for public use.
16,819 power plants and 36,872 generators from EIA.
750,000 transmission circuit-miles from HIFLD.
1,000 data centers from EPA and other open sources.
71
269
2,215
120,002
Apr 10
yes that's the reason why you need to scale it near origin if you're using low precision but this not practical to do.
float is not continuous it's just a really weird integer
this also applies to model training
you can see here the low precision struggle to reach the minima
Apr 9

Making a scatter plot of 400_000 data points, some of the plots had odd gaps in coverage. It took me a little while to realize that it was only when the data was farther from the origin -- it was the raw bfloat16 precision. Everything looks great from -1 to 1, but as you go past 2 and 4, the coverage gaps get larger.
My intuition didn't have it being quite so "discretely countable" at those modest numeric values.
Float32 for comparison.
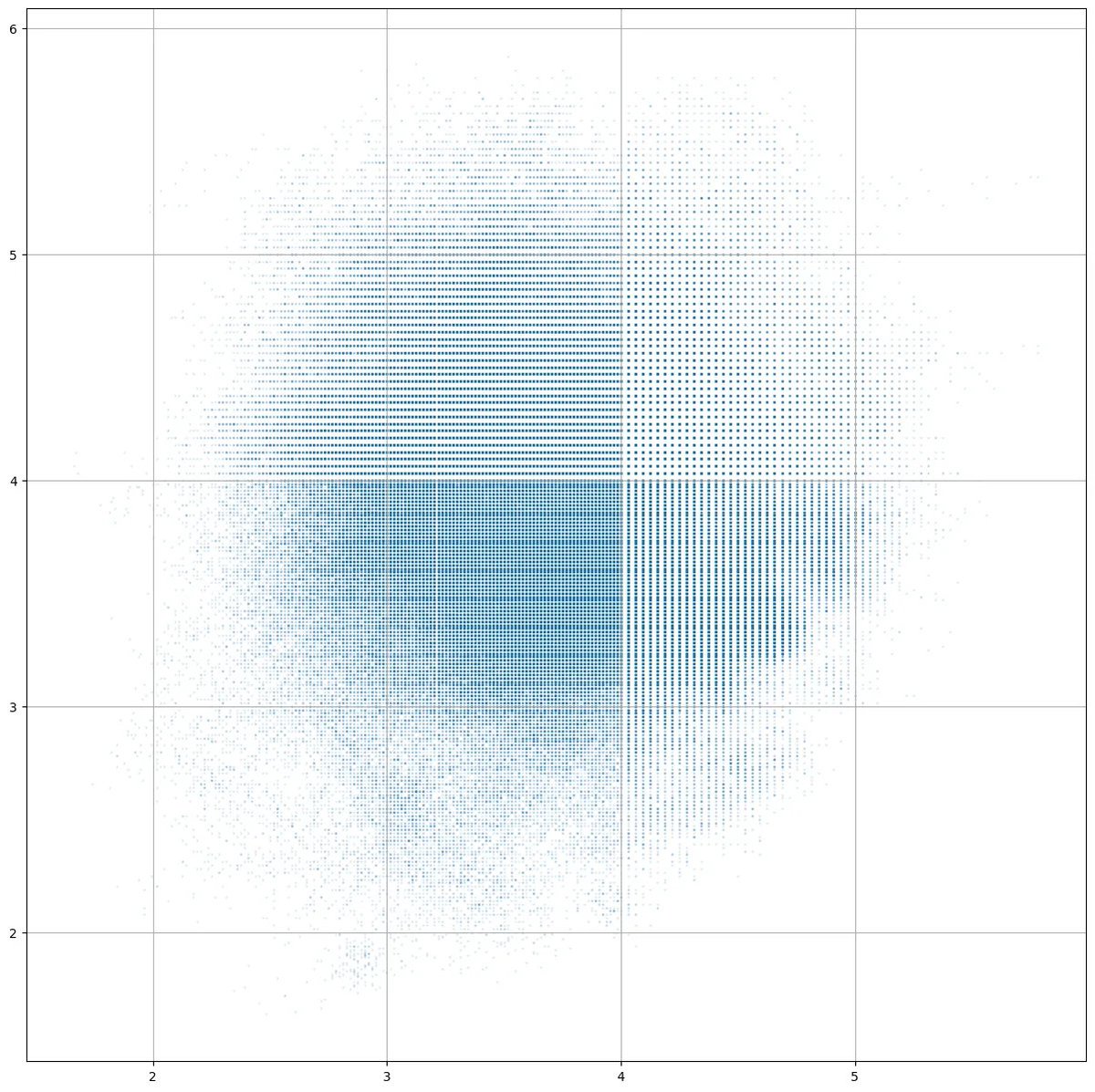
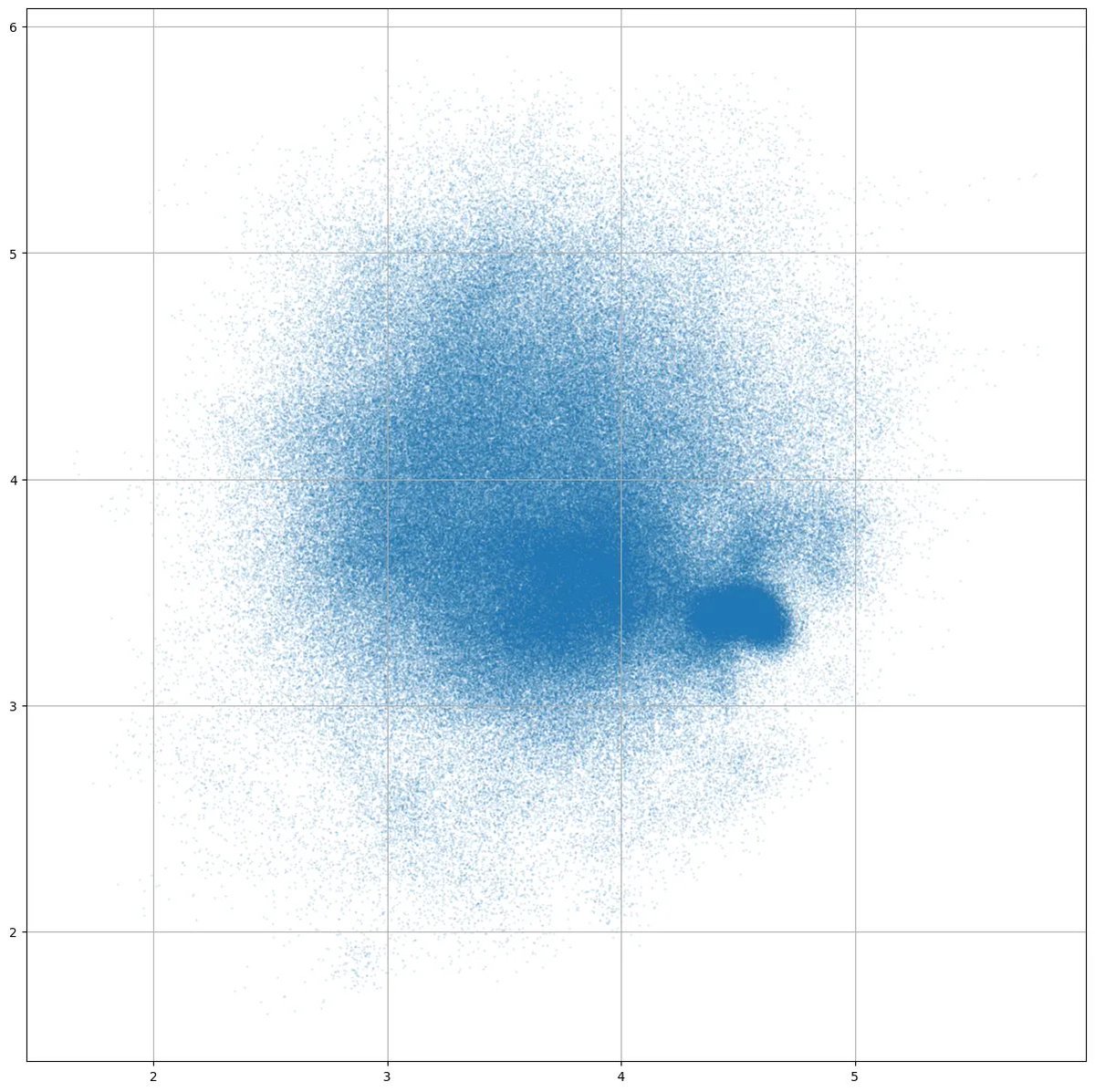
23
1,957
Apr 5
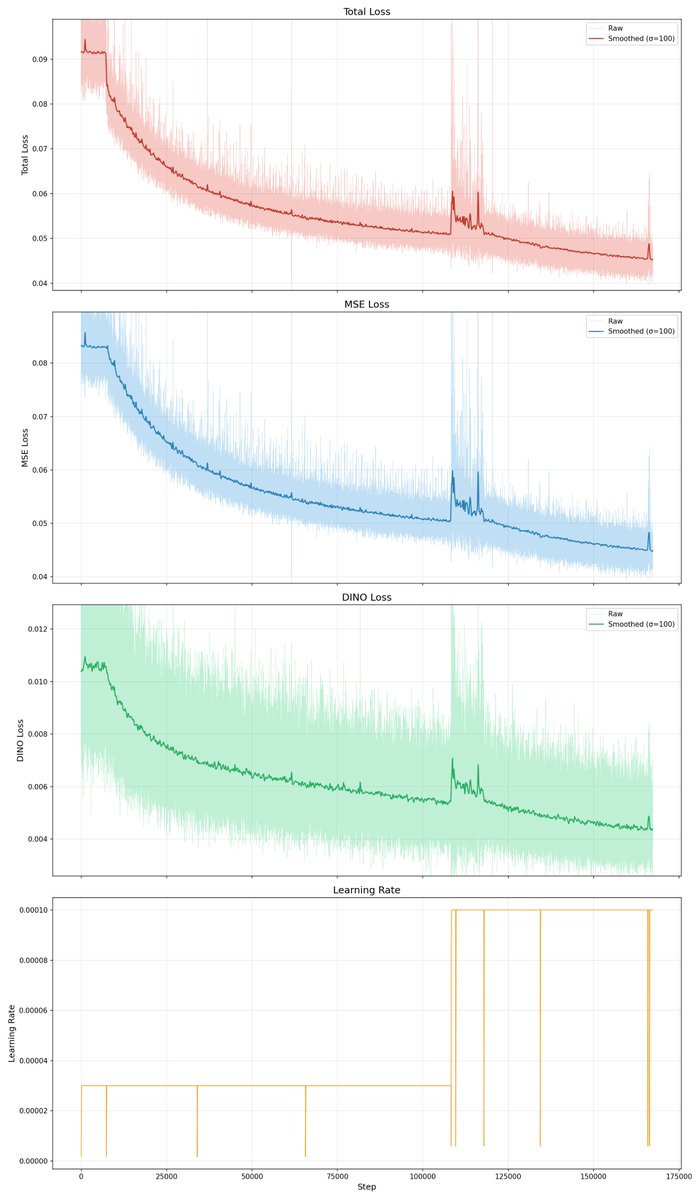
you can just tweak hyperparam mid training and it will just works
every spot where the LR resets is where i changed something mid training.
just make sure you flush your optimizer state and re-spool its accumulator state and everything is golden
3
8
127
11,676
Apr 4
I was a huge fan of @Bose but now not anymore
the product I already paid for, you quietly made it worse. No warning. No consent. No opt-out. Just a forced firmware update that turned a seamless, premium experience into a bureaucratic nightmare that requires me to babysit a smartphone app just to switch between devices.
I paid premium money for the privilege of pressing one button. That was the promise. That was the product. And you had the audacity to silently delete that experience from hardware sitting in my hands, hardware I OWN.
Here's the thing about ownership that apparently needs to be spelled out: when I buy your product, the transaction is complete. You don't get to keep editing what I purchased. An over-the-air update that removes functionality isn't a feature, it's a violation. At best it's a suggestion. You do not get to treat my hardware like a subscription you can renegotiate at will.
Roll it back. Make it optional.
youtube.com/watch?v=CWPrjGVN…
2
15
1,810
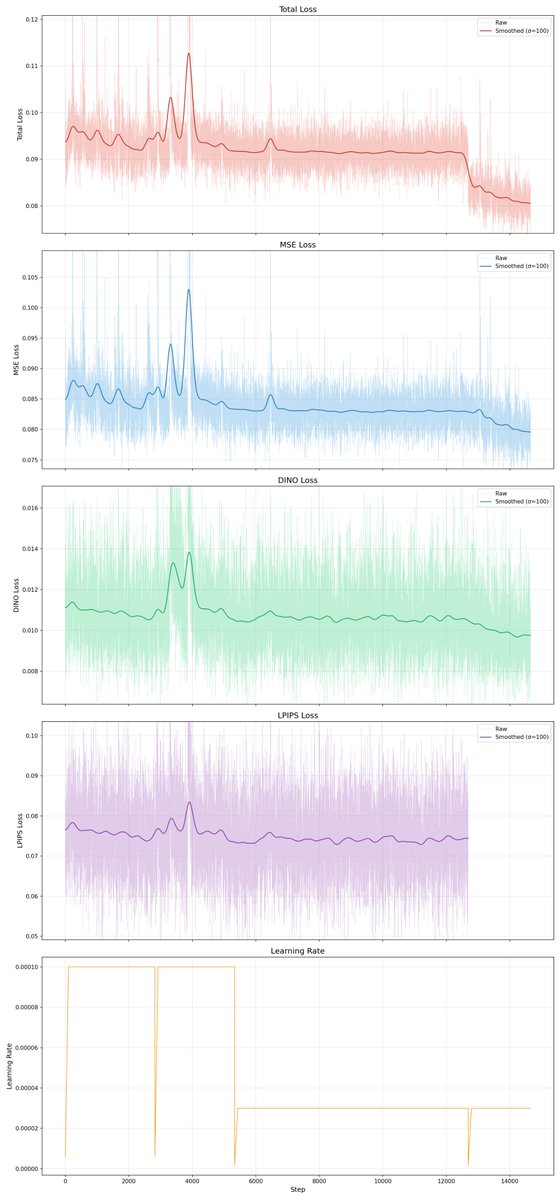
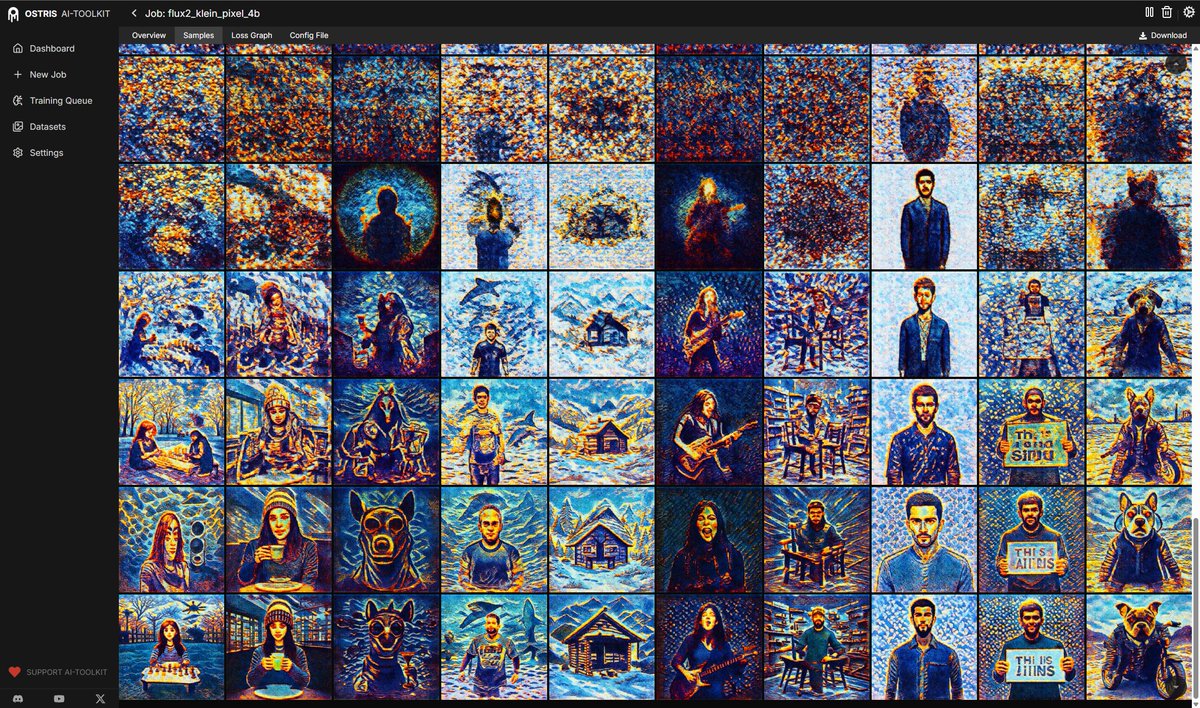
Experimenting training a FLUX.2 klein 4B pixel space version. I am just doing patch 16 directly from the pixel space into the model. I trained just the in/out layers for 24 hrs. I just unfroze the img stream of the first block and the linear layers of the last. Converging fast.
7
12
116
10,660