
Ass. prof. of Machine Learning. PI of Generative Memory Lab (@DondersInst). Generative diffusion and statistical physics. AI realist.
Joined July 2011
- Tweets 11,001
- Following 2,687
- Followers 6,932
- Likes 47,065
206 Photos and videos



Pinned Tweet

May 11
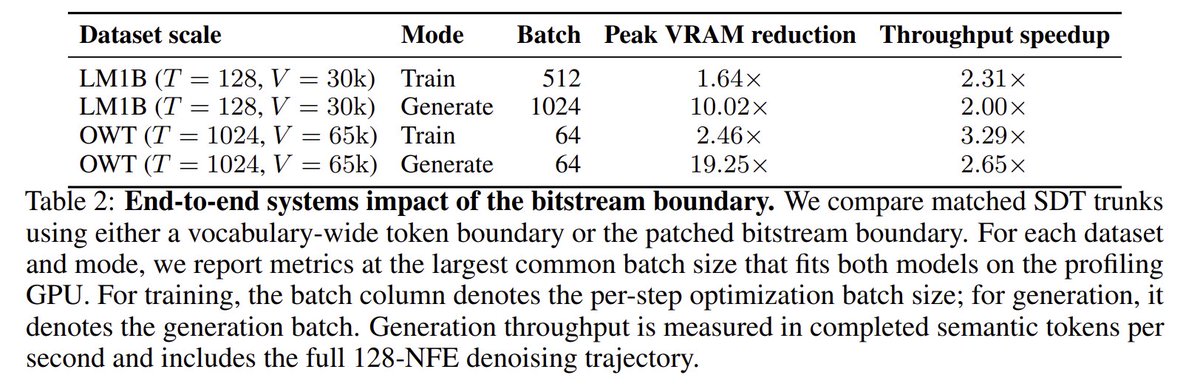
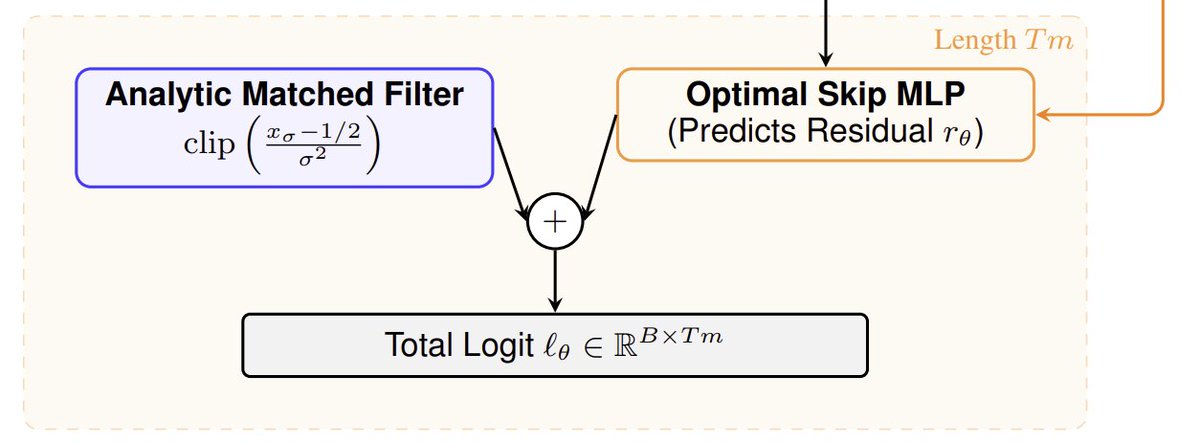
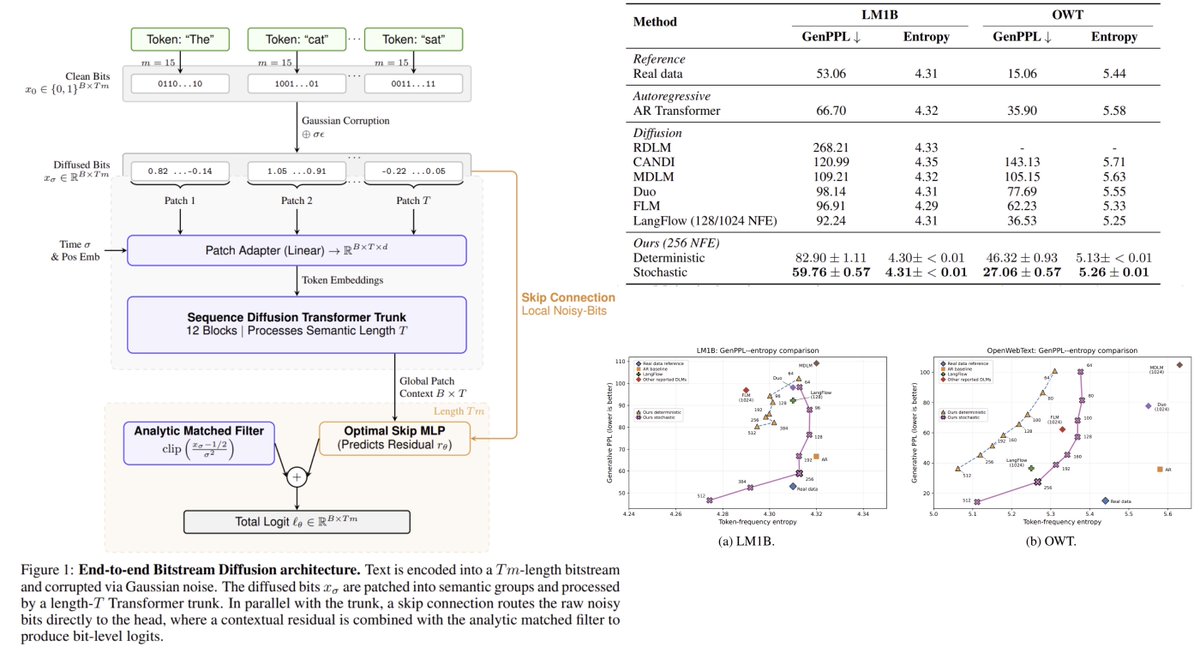
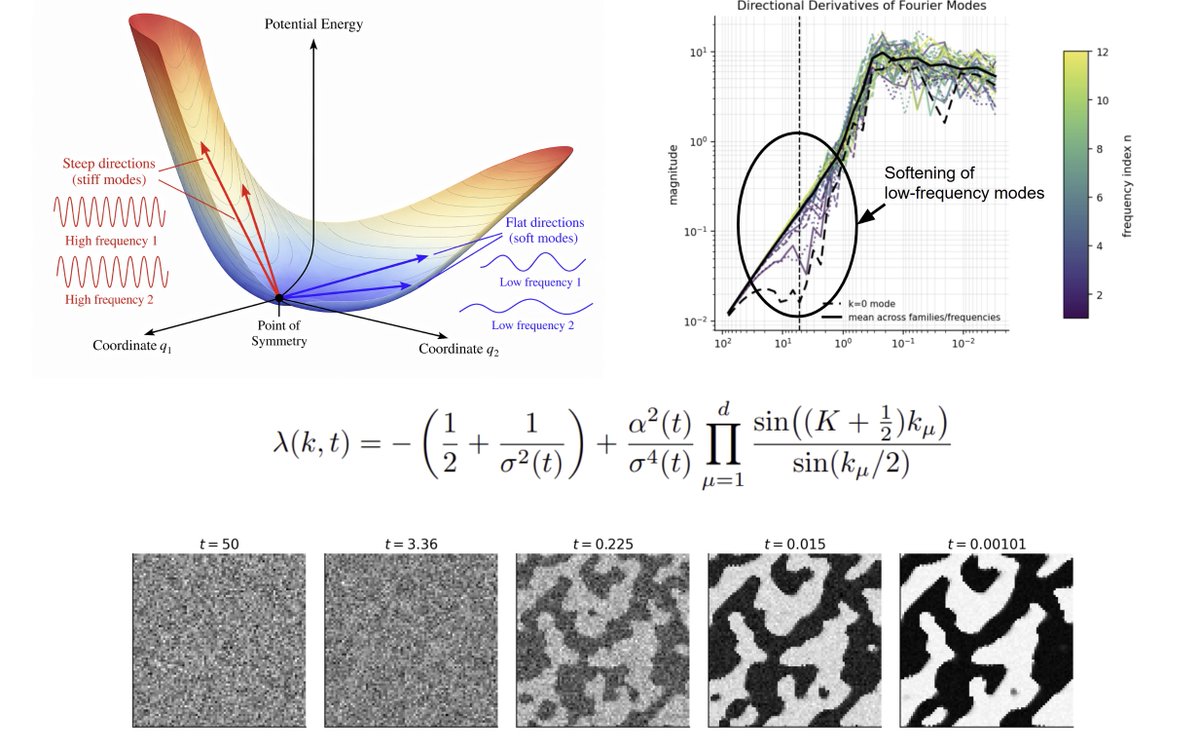
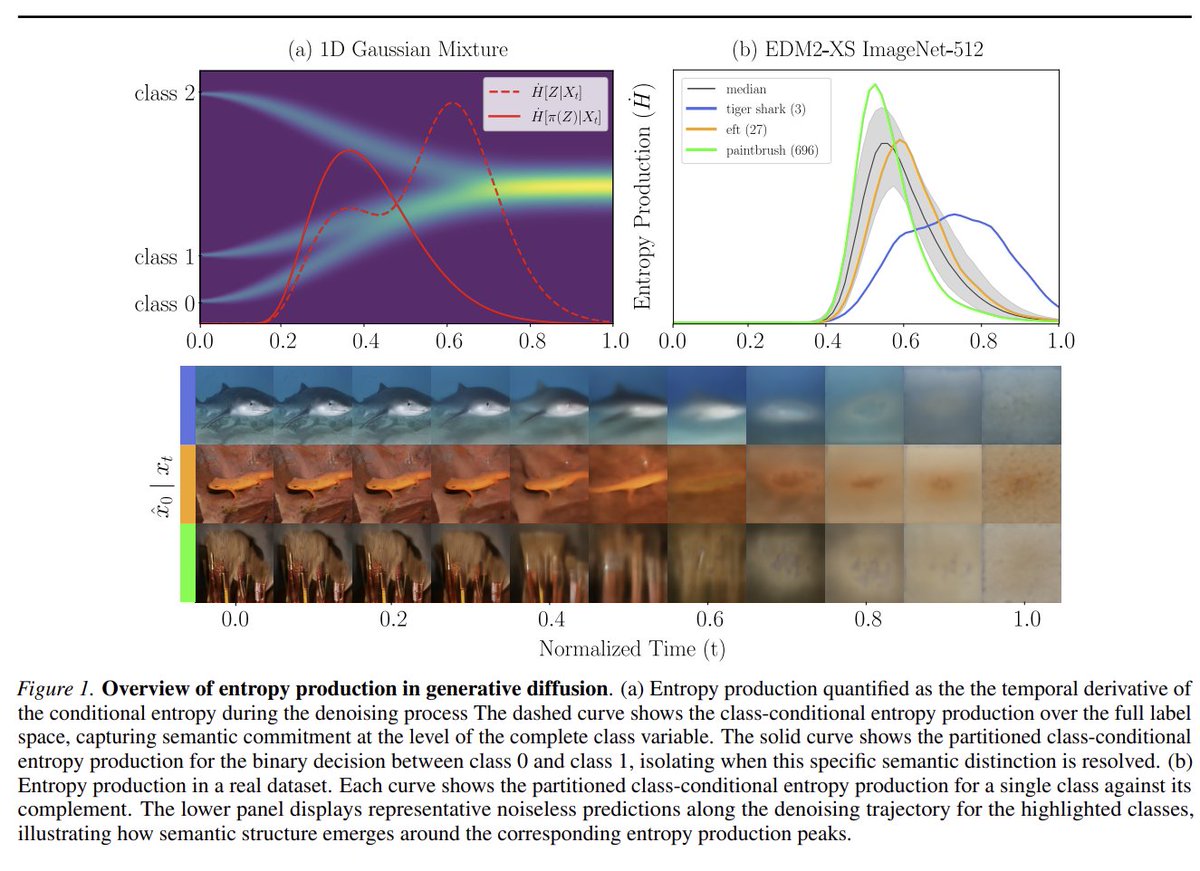
1/?) As promised to Sander Dieleman (@sedielem), we’re finally excited to share:
Towards Closing the Autoregressive Gap in Language Modeling via Entropy-Gated Continuous Bitstream Diffusion
We show that continuous diffusion can achieve very strong language modeling performance when operating directly on bitstreams, outperforming masked and uniform diffusion baselines, and essentially matching autoregressive models under our evaluation settings.
6
37
228
27,807
Luca Ambrogioni retweeted

Jun 13
If Dario had invented the iPhone he would have spent the whole keynote talking about how it might blow up in your pocket
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
122
574
11,168
420,903


Luca Ambrogioni retweeted

this is sock gnome level. business school lectures will have this as a slide



2
44
2,836
Luca Ambrogioni retweeted

MLSS (mlss.cc/) is back in Tübingen. It is hard to believe how much the field has changed since Alex Smola and I did the first MLSS, and since the first Tübingen edition in 2003. Our last in-person edition here was in 2017, so this feels long overdue (1/3)
3
20
109
13,706
Jun 12
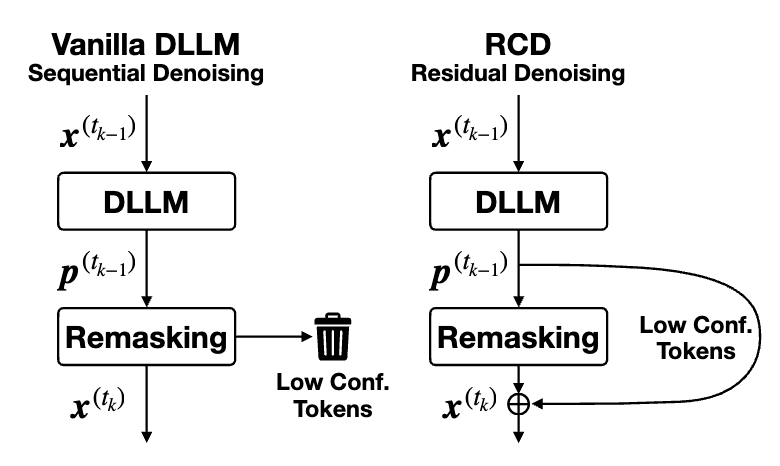
In continuous diffusion, you get this for free since uncertainty is encoded in the decomposition of x_t into the embeddings of the tokens
For example, if you have binary -1 and 1 embeddings, p = 0.5 is encoded by x_t = 0.

DiffusionGemma uses self-conditioning using probability weighted embeddings,
similar to what we explored in detail in our RCD work.
Check our Yuezhou's thread and our ICML paper: arxiv.org/abs/2601.22954
x.com/yuezhouhu/status/20181…

1
3
22
2,772
Luca Ambrogioni retweeted

Jun 11
Excited to see Mercury 2 live on @baseten
Mercury 2 delivers Groq/Cerebras-like speeds (>1000 tokens/sec) with quality comparable to speed-optimized models like Claude Haiku
If you have latency-sensitive workloads we’d love to hear from you.

We are excited to announce that we have partnered with @_inception_ai to make Mercury 2 available on Baseten. This makes us the first inference platform to bring Inception’s diffusion LLM to production.
Inception’s dLLM architecture fixes the bottlenecks of sequential token generation and can deliver 1,000 tokens/sec on standard NVIDIA GPUs. Early users like @augmentcode have seen impressive results, such as an 82% reduction in latency and 90% cost savings, while maintaining high quality.
2
8
59
6,695
Luca Ambrogioni retweeted

Jun 11
Most of Europe has not yet absorbed what AI is about to do to us. The few who have are not saying it loudly enough.
We wrote Europe 2031: a five-year scenario of the continent's slide into irrelevance, how AI is driving it, and what can still be done to change course.

86
163
895
343,087
Luca Ambrogioni retweeted

Jun 11
More than ever before I feel like Fable 5 speaks a different kind of English than we humans do.
It isn't conversational, its not 'light' to read, it barely explains — it's pure load-bearing density, meaning compacted until every token earns its place.
It assumes your context window is as large as its own and you have perfect recall of everything you're working on. Similar to how AI-chess feels alien, this too, feels almost akin to an alien language.
I mean, just read this stuff, nobody talks like this, only advanced AI does:
184
34
759
181,338
Luca Ambrogioni retweeted

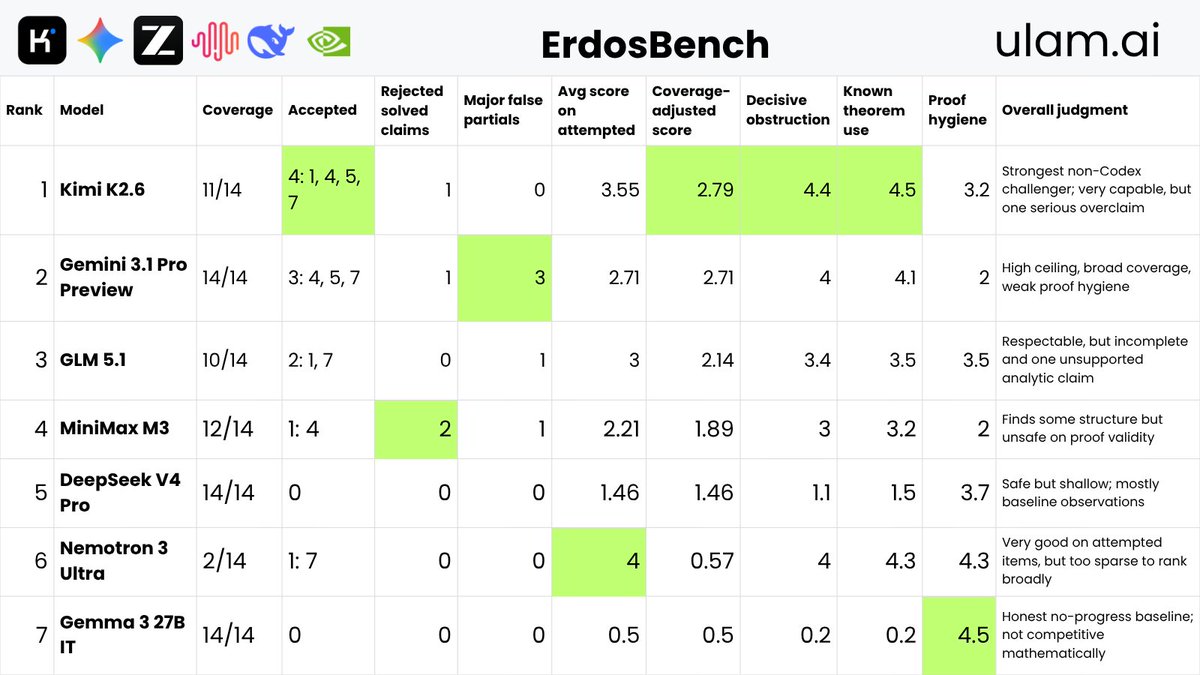
While everyone talks about Mythos vs GPT-5.5, we've tested other near SOTA models on our ErdosBench.
Smoke test on 14 problems with 7 models: Kimi K2.6, Gemini 3.1 Pro, GLM 5.1, MiniMax M3, DeepSeek V4 Pro, Nemotron 3 Ultra and Gemma 3 27b.
The winner overall is... Kimi K2.6
18
26
300
36,879
Luca Ambrogioni retweeted

Jun 11
Aside from the official code release, I am thrilled to share that Spectral Progressive Diffusion a.k.a. SPEED (arxiv.org/abs/2605.18736) is now integrated into @lmsysorg's SGLang (@sgl_project)! 🚀
Instead of always running diffusion at full resolution, SPEED progressively grows resolution across denoising steps, drastically cutting token count and achieving >2× speedup with no quality loss.
SPEED is now supported in SGLang for FLUX.1 & 2, Z-Image, Qwen-Image, and Wan. Support for Ideogram 4 incoming.
Try it out now: docs.sglang.io/docs/sglang-d….
[1/4]

Jun 11

Today we release the code and a demo for our recent Spectral Progressive Diffusion paper🎉
Play around with it anytime! Just as what we have been doing also, we hope that it encourages the integration of our plug-and-play framework into latest and greatest image and video generation models!!
We also included an agent skill wrapper in the repo, to making things easier.
🛜Project website: howardxiao.ca/speed/
📄Paper: arxiv.org/abs/2605.18736
💻Github (with ComfyUI): github.com/howardhx/speed
🤗Demo (HuggingFace): huggingface.co/spaces/howard…
2
12
66
22,779
Jun 12
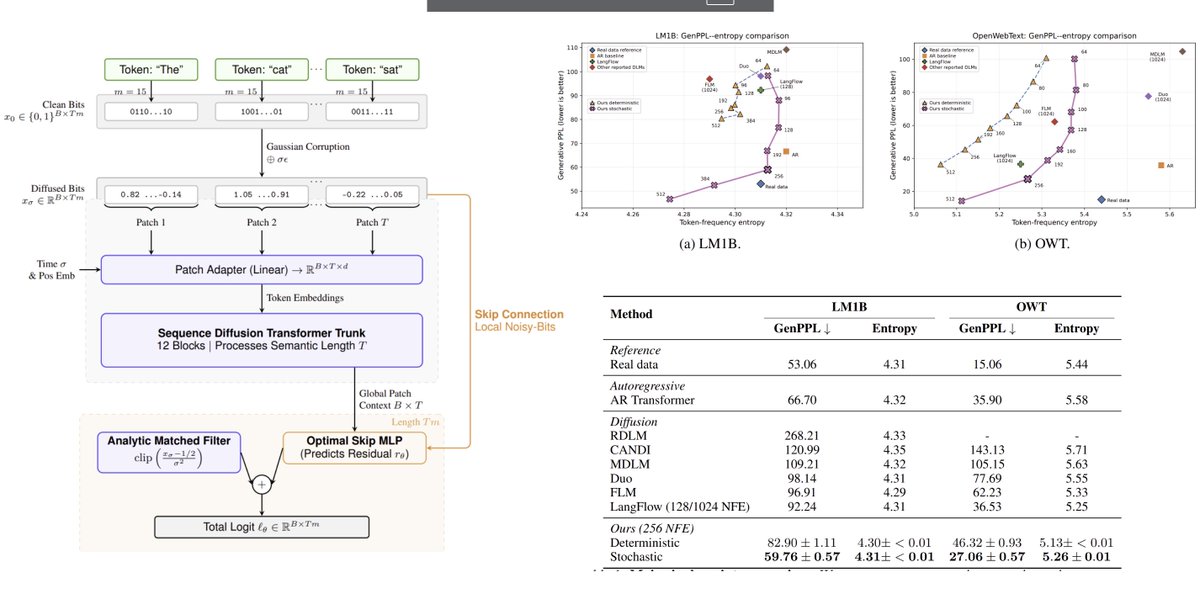
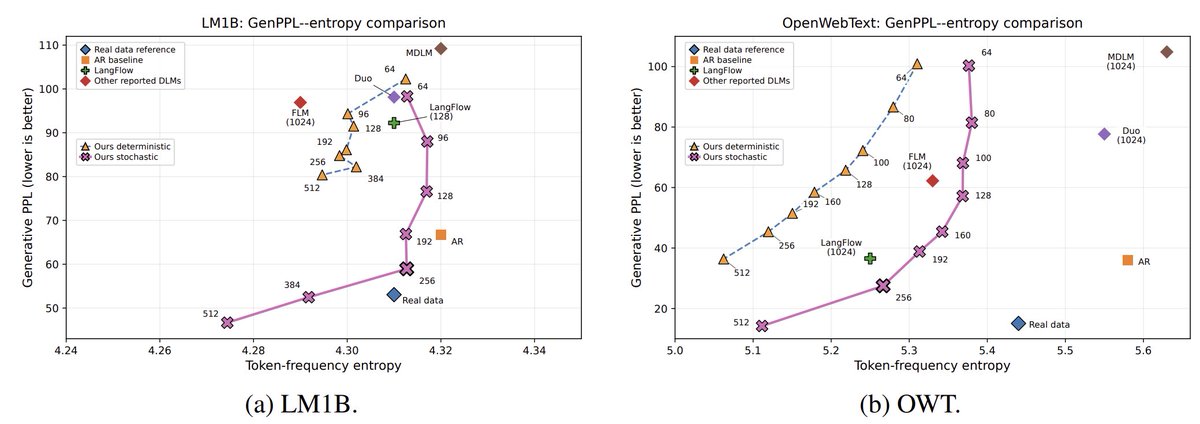
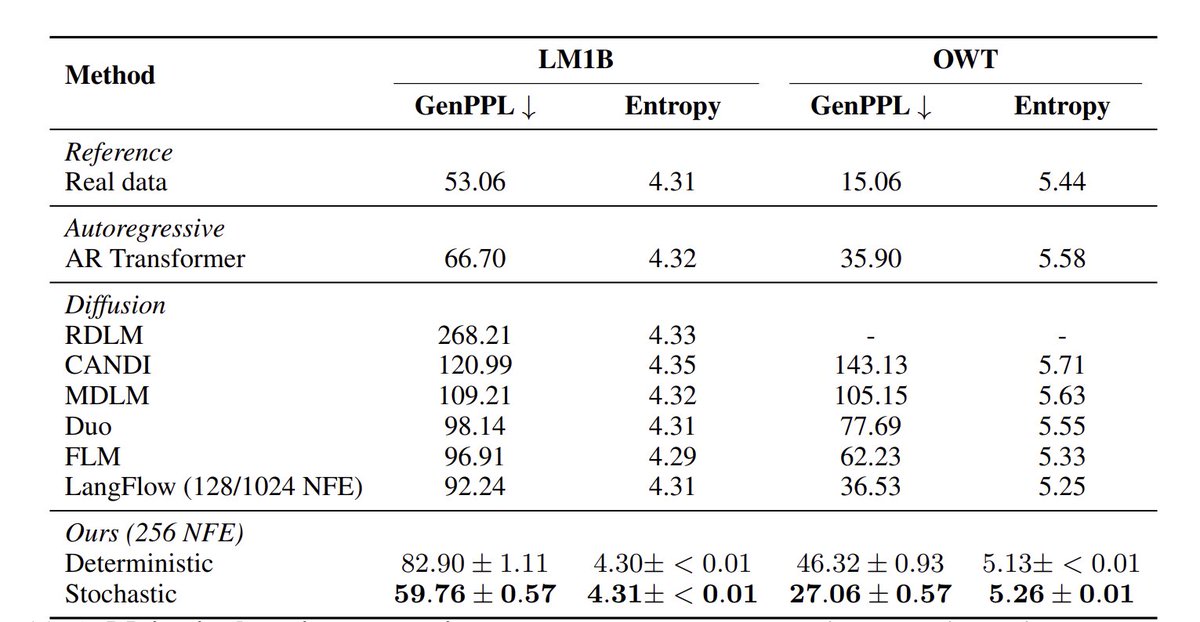
I see the point but nearly all metrics are hackable if this is your goal. Admittedly genPPL is pretty bad and entropy does not fully fix it, so said I think that pareto fronts are decent.

Hacking Generative Perplexity: Why Unconditional Text Evaluation Needs Distributional Metrics
Antonio Franca, Alexander Tong
arxiv.org/abs/2606.08417 [𝚌𝚜.𝙲𝙻 𝚌𝚜.𝙰𝙸]
💬Accepted to the Workshop on Structured Probabilistic Inference & Generative Modeling (SPIGM) at ICML 2026
1
514
Jun 12
We created a world in a bottle


2
305
Luca Ambrogioni retweeted

May 1
i think a lot of people are going to be busier (and hopefully more fulfilled) than ever, and jobs doomerism is likely long-term wrong.
though of course there will be disruption/significant transition as we switch to new jobs, the jobs of the future may look v different, etc.
289
160
3,971
715,990
Jun 11
If your compiler turns 100% of your C into machine code, what skill is actually yours?
Jun 11

if AI writes 80% of your code
what skill is actually yours?
1
5
649
Jun 11
Yeah, who doesn't get their creative inspiration from breadth first searches?
They are practically my muses
Jun 10

DeepMind cofounder Shane Legg thinks that search is essential for a model to be genuinely creative.
Pre-trained base models can do incredible things. But Shane thinks this is just a matter of them mixing together existing concepts from their training data.
If he's right, coming up with genuinely novel ideas always involves searching a large space for "hidden gems".
2
984
Luca Ambrogioni retweeted

Transformer training often proceeds through sudden changes: new capabilities appear, attention heads specialize, many heads remain redundant.
We build a solvable model explaining staged head specialization through symmetry breaking and signal structure. arxiv.org/abs/2603.03993
3
19
127
10,174
Luca Ambrogioni retweeted
Why does pre-training help LoRA fine-tuning?
In a solvable model of attention, we find that its entire effect can be summarized by a single quantity: an effective noise level seen by the downstream task.
Better pre-training = lower effective noise.
arxiv.org/abs/2606.05899
12
73
5,553
Luca Ambrogioni retweeted

Jun 10
You may have recently heard claims that video generation models are "dumb" about physics, and only "world models" (V-JEPA, specifically) have a valid internal model of physics.
This turns out to be false. In a recent paper, researchers show that a LINEAR probe of diffusion videogen models predict various "physics" very well, significantly better than V-JEPA or VideoMAE (and plain VAE just sucks).
This is noteworthy, because a *linear* probe being this accurate shows that the model has a pretty explicit internal representation of the physics!
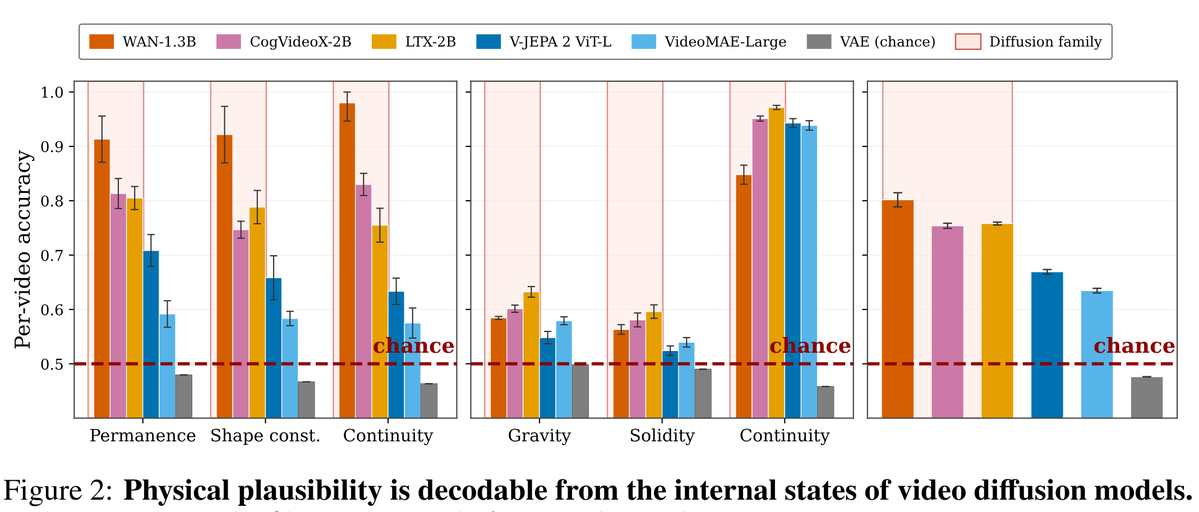
42
107
1,068
100,259

How do you study events that almost never happen? 🧵
Protein folding, phase transitions, chemical reactions—rare but decisive ⚡, and a nightmare for classical simulation.
Our new paper tackles this with stochastic optimal control: a unifying way to learn reaction statistics, sample transition paths, and go beyond reversible dynamics.
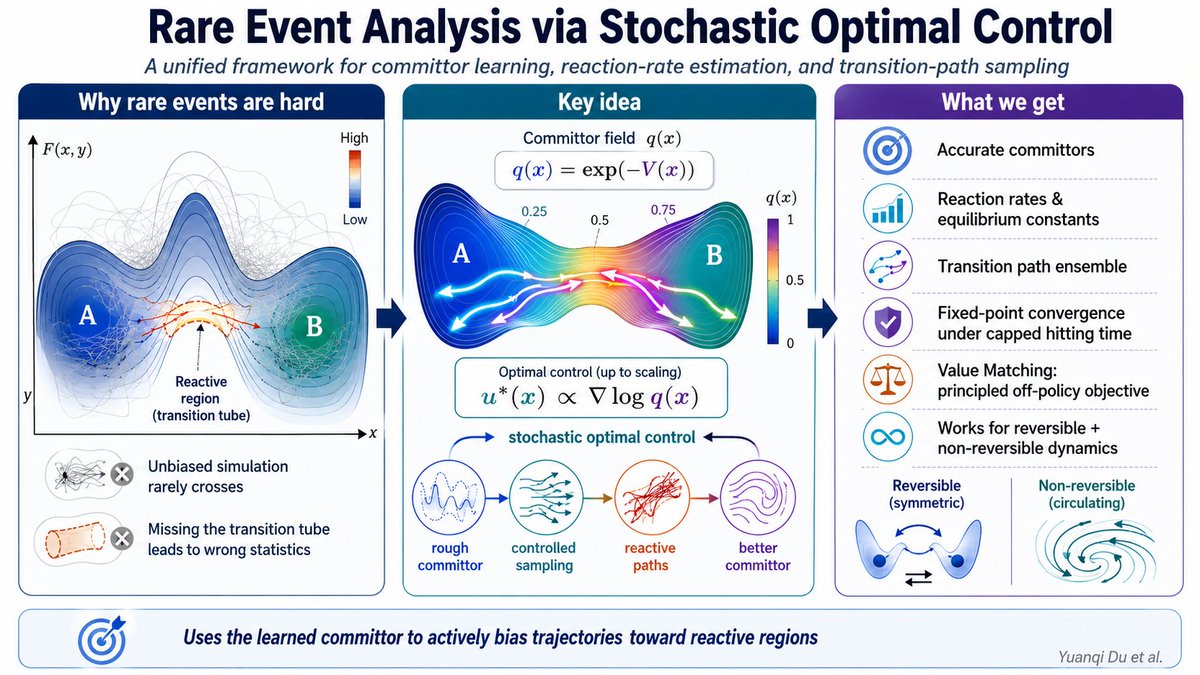
5
41
282
21,231