
Large Model Systems Organization: Join our Slack: slack.sglang.io. We developed SGLang sglang.io, Chatbot Arena (now @arena), and Vicuna!
Joined August 2024
- Tweets 1,132
- Following 199
- Followers 15,420
- Likes 1,397
291 Photos and videos










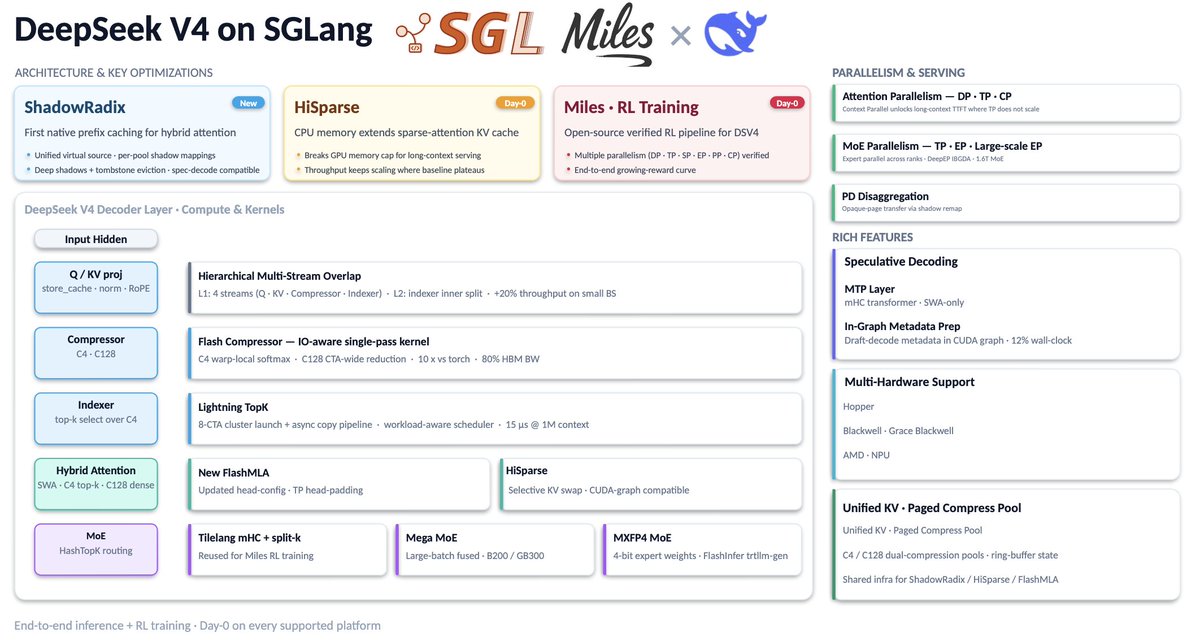
DeepSeek V4 by @deepseek_ai just dropped! SGLang is ready on Day 0 with a full stack of optimizations from architectures to low-level kernels. We also deliver a verified RL training pipeline in Miles (by @radixark) for V4 at launch:
1️⃣ Native "ShadowRadix" Design: DeepSeek V4's hybrid attention is complex. Our new ShadowRadix engine is the first to provide native prefix caching for SWA and compressed KV pools, making 1M context retrieval seamless and memory-efficient.
2️⃣ High-Performance Kernels:
- Flash Compressor: IO-aware fused kernels, 10x faster than naive implementations.
- Lightning TopK: High-speed indexing for 1M context in just 15µs.
- Integrate FlashInfer trtllm-gen MoE, FlashMLA, and MegaMoE kernels
3️⃣ Rich Features: Speculative decoding, HiSparse, Attention DP/TP/CP and MoE TP/EP, and multi-platform support
4️⃣ Verified RL: The open-source RL pipeline: full parallelism (DP/TP/EP/PP/CP), tilelang kernels, tensor-level checked precision, verified with growing reward.
Get started immediately with our out-of-the-box Cookbook 👇
Enjoy! #DeepSeekV4 #SGLang #LLM
23
63
343
183,002
LMSYS Org retweeted

Jun 13
The standout feature in SGLang v0.5.13 is BCG (Breakable CUDA Graph). It delivers prefill efficiency comparable to PCG (Piecewise CUDA Graph), while being significantly more flexible and compatible with advanced optimizations.
BCG is also a powerful debugging tool — it enables eager execution inside CUDA graph replay, so you can easily print debug info or inspect intermediate states.
Prototype by @csy_789. @Oasis_a19 turned it into a production-ready prefill optimization. I was fortunate to pick the name for this awesome technique. 😊
Jun 13

🎉 SGLang v0.5.13 is out!
First, new model support!
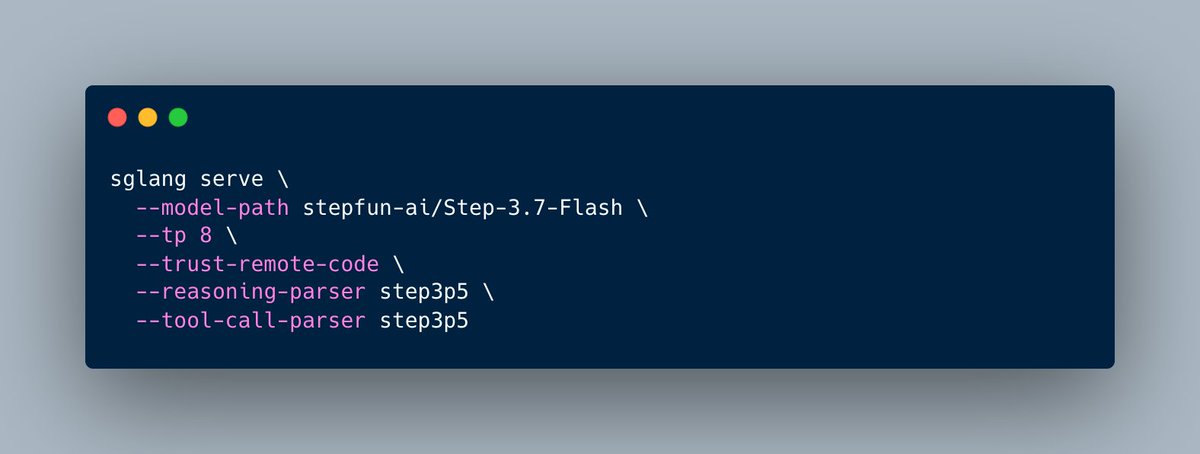
Nemotron 3 Ultra, Step-3.7-Flash, Command A , plus new diffusion models: Cosmos3, FLUX.2-Klein, Ideogram 4, LingBot-World, SANA-WM, and Ernie-Image.
Here are the highlights for this release:
- Speculative Decoding V2 is now the default! Tree drafting (topk>1) for faster generation
- Breakable CUDA Graphs now make prefill faster
- Qwen 3.5 runs faster on NVIDIA Blackwell with new GDN kernels
- HiCache with UnifiedTree on by default for hybrid SWA/Mamba models
- SGLang-Diffusion now supports realtime generation! Plus progressive resolution
- Multiple performance and feature updates for DeepSeek V4
Thanks to our amazing partners and model makers:
@NVIDIAAI @AMD @intel @awscloud @boson_ai @cohere @bfl_ml @ideogram_ai @deepseek_ai @Kimi_Moonshot @Alibaba_Qwen @StepFun_ai @Baidu_Inc @robbyant_brain

4
20
89
17,002
LMSYS Org retweeted

Jun 13
🎉 SGLang v0.5.13 is out!
First, new model support!
Nemotron 3 Ultra, Step-3.7-Flash, Command A , plus new diffusion models: Cosmos3, FLUX.2-Klein, Ideogram 4, LingBot-World, SANA-WM, and Ernie-Image.
Here are the highlights for this release:
- Speculative Decoding V2 is now the default! Tree drafting (topk>1) for faster generation
- Breakable CUDA Graphs now make prefill faster
- Qwen 3.5 runs faster on NVIDIA Blackwell with new GDN kernels
- HiCache with UnifiedTree on by default for hybrid SWA/Mamba models
- SGLang-Diffusion now supports realtime generation! Plus progressive resolution
- Multiple performance and feature updates for DeepSeek V4
Thanks to our amazing partners and model makers:
@NVIDIAAI @AMD @intel @awscloud @boson_ai @cohere @bfl_ml @ideogram_ai @deepseek_ai @Kimi_Moonshot @Alibaba_Qwen @StepFun_ai @Baidu_Inc @robbyant_brain
4
10
72
18,299
LMSYS Org retweeted

🎉 Congratulations to @lmsysorg for setting a new record on NVIDIA GB300 NVL72!

🚀New record on GB300 NVL72: SGLang exceeds 12K tok/s per GPU on DeepSeek V4 Pro 1.6T (FP4, 8K/1K), orchestrated with NVIDIA Dynamo (SGLang) and MTP.
Per @SemiAnalysis_ InferenceX benchmarks, performance stays strong across the entire interactivity curve.
More to come with @NVIDIAAIInfra 🤝
2
23
197
15,199
🚀New record on GB300 NVL72: SGLang exceeds 12K tok/s per GPU on DeepSeek V4 Pro 1.6T (FP4, 8K/1K), orchestrated with NVIDIA Dynamo (SGLang) and MTP.
Per @SemiAnalysis_ InferenceX benchmarks, performance stays strong across the entire interactivity curve.
More to come with @NVIDIAAIInfra 🤝
8
18
119
30,218
🎉 Meet Kimi-K2.7-Code from @Kimi_Moonshot, their latest open-source coding model, day-0 support is now live in SGLang!
⏳ More reliable on long, multi-step coding tasks
🧠 30% fewer reasoning tokens
⚡️ Same architecture as K2.5/K2.6, deploy with your existing setup
Cookbook: docs.sglang.io/cookbook/auto…
Run it now with SGLang!
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


5
6
64
7,979
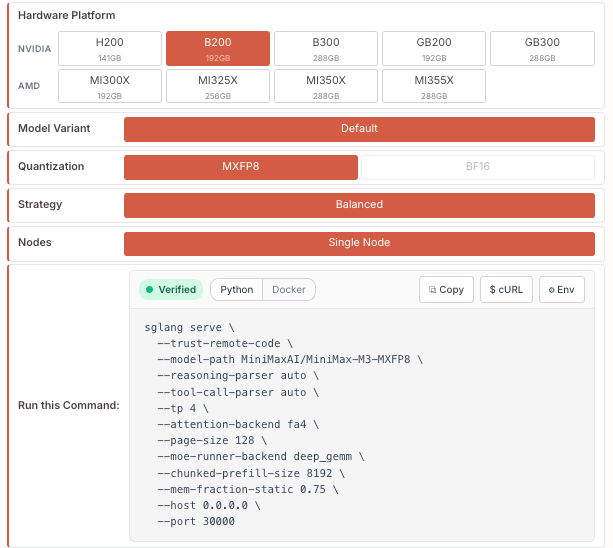
🎉 SGLang has Day-0 support for MiniMax-M3 from @MiniMax_AI, a native-multimodal MoE reasoning model of ~428B total params (~23B active), 60 layers, 1M context across text, image & video.
✅ Native multimodality: text-image-video fusion from step 0
✅ MiniMax Sparse Attention (MSA): 9× prefill / 15× decode speedup over M2 at 1M context, 1/20 per-token compute
✅ Frontier-level agentic performance: coding & cowork
✅ MXFP8 across vendors: native on NVIDIA Blackwell & AMD MI350X/MI355X; bf16 build for H200
Cookbook: docs.sglang.io/cookbook/auto…
Run it now with SGLang!
Jun 12

MiniMax M3, Open-Weight, Now On Hugging Face
Weights:
huggingface.co/MiniMaxAI/Min…
MiniMax Sparse Attention:
huggingface.co/papers/2606.1…
3
12
39
5,123
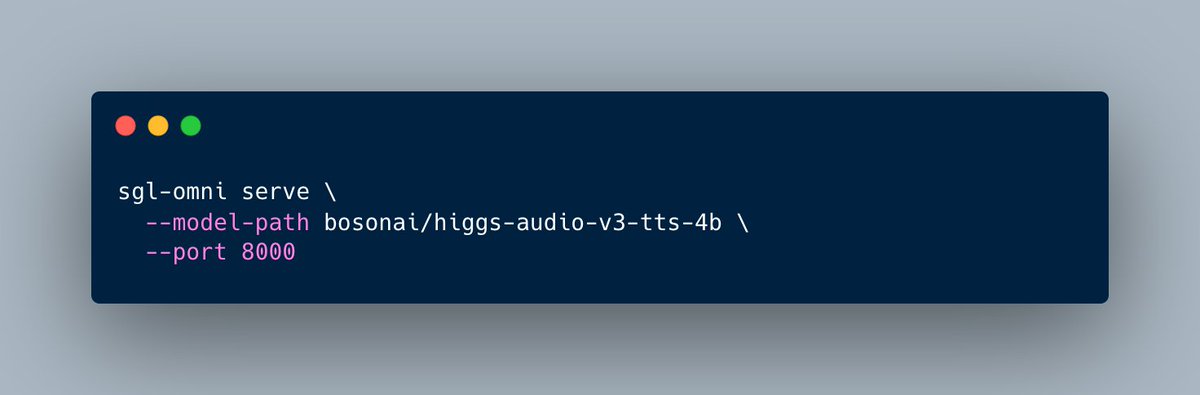
SGLang Office Hour 6/11 Higgs Audio V3 TTS x.com/i/broadcasts/1nKOLLdYN…
1
3
689
LMSYS Org retweeted
Jun 11
Hot take: most of your denoising steps don't need full resolution👌
SPEED proves it with progressive resolution growth during denoising, up to 2× speedup, and quality untouched.
Now shipping in SGLang Diffusion: FLUX.1 & 2, Z-Image, Qwen-Image, Wan. Ideogram 4 next
Congrats @BrianCChao @howard_xhc @YarivLior @GordonWetzstein 👏 and thanks to the support from @hsu_byron and @mick_qian
Don't forget to check out this doc: docs.sglang.io/docs/sglang-d…
Jun 11

Aside from the official code release, I am thrilled to share that Spectral Progressive Diffusion a.k.a. SPEED (arxiv.org/abs/2605.18736) is now integrated into @lmsysorg's SGLang (@sgl_project)! 🚀
Instead of always running diffusion at full resolution, SPEED progressively grows resolution across denoising steps, drastically cutting token count and achieving >2× speedup with no quality loss.
SPEED is now supported in SGLang for FLUX.1 & 2, Z-Image, Qwen-Image, and Wan. Support for Ideogram 4 incoming.
Try it out now: docs.sglang.io/docs/sglang-d….
[1/4]

1
8
30
4,511
LMSYS Org retweeted
Jun 10
📣 SGLang Office Hour: How to Build Fast, Modern Voice Cloning with @boson_ai
Our Office Hour is back!
This week we're joined by Ke and Huapeng from the Boson AI team to talk about Higgs Audio V3 TTS, how to build fast, modern voice cloning that actually sounds human, and their work optimizing SGLang-Omni for TTS production serving.
Bring your questions for Ke and Huapeng, see you tomorrow!

1
3
18
2,432
LMSYS Org retweeted
Jun 10
Heard about Speculative Decoding? Come hear how Speculative Speculative Decoding (SSD) pushes inference speed to a new ceiling. RSVP 👇

We're hosting a research talk lunch event with @TanishqKumar07 in SF!
Come learn about SSD, which is up to 2x faster than the best inference engines in the world, RSVP below!

1
2
18
3,613
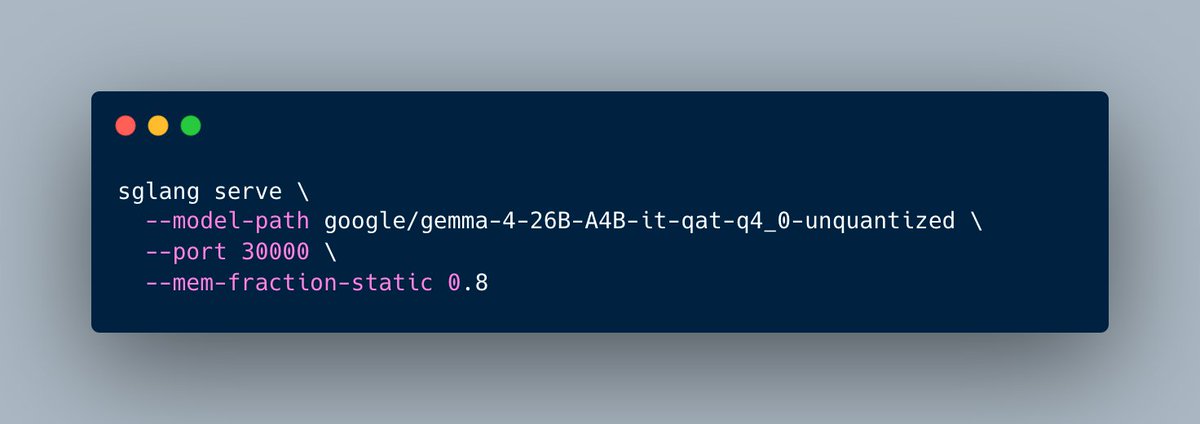
🎉 SGLang has Day-0 support for DiffusionGemma, a text-diffusion variant of @googlegemma 's Gemma 4 (26B A4B MoE), built for blazing low-batch generation speed!
Instead of token-by-token decoding, it denoises blocks of tokens in parallel for much faster generation.
1️⃣ Discrete text diffusion: block-parallel multi-canvas sampling
2️⃣ Multimodal: text, image & video in, text out
3️⃣ Sparse MoE (8 of 128 experts): strong reasoning, low memory
4️⃣ Configurable thinking mode
Run it now with SGLang!
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
2
7
59
5,598
Cookbook is live: docs.sglang.io/cookbook/auto…
4
658
Thank you, New York! We'll see you next time🫡
Jun 9
🏙️ SGLang NY Tech Week Happy Hour Recap
Last Wednesday, SGLang hosted a NY Tech Week Happy Hour in NYC, co-hosted with @HOFCapital, @Cloudflare, @CrusoeAI, and @ArklexAI. 380 registered, 200 in the room, and one unforgettable night. 🧡
The room was packed with engineers, researchers, and enthusiasts from quant funds, banks, and trading firms, all there to talk about one thing: where inference is headed as LLMs move into latency-sensitive production across trading, research, compliance, and risk.
NYC, you showed up and brought the energy. We loved every minute. Until next time! ☀️
#NYTechWeek @Techweek_




8
1,467
🙌The community account @sgl_project is back!
If you're building with SGLang, this is your space. Follow for releases, Office Hours, tutorials & events👇
Jun 9
👋 @sgl_project is back!
Welcome to the home of the SGLang community! While @lmsysorg keeps you posted on technical drops and partner news, this space is for you!
Here's what we've got lined up:
🚀 Version releases: every new SGLang drop, unpacked
🎙️ Office Hours: deep dives, live deployments, and team Q&A
📺 Tutorials: short how-tos and the best Office Hour moments
🌟 Community spotlights: the cool stuff you're building with SGLang
📅 Event updates: meetups, workshops, and where to catch us next
And we'd love to hear from you! What do you want to see? Benchmarks? Model deep dives? A topic for the next Office Hour?
Drop it below 👇 Every idea gets read!

4
25
4,437
📝 New blog: No Token Left Behind: Demystifying Token-In-Token-Out in Miles
In agentic RL, a rollout is a chain of model calls, tool outputs & resumed turns. Token-In-Token-Out (TITO) ensures the trainer evaluates the exact tokens the inference engine produced — break it, and training silently drifts off-policy.
Why it matters:
📦 One sample per task, not per turn: ~10× less compute on 30–50 turn trajectories
🎯 Keeps every token on-policy
How Miles enforces it:
1️⃣ Inference session server: one append-only token buffer per trajectory
2️⃣ Append-only at 3 levels: messages, template rendering, tokens
3️⃣ Pluggable TITO tokenizer: incremental tokenize per-model splice patches
4️⃣ TokenSeqComparator: verifies every rollout stays bit-perfect
Supports Qwen3, GLM, Kimi-K2, Nemotron, Minimax & DeepSeek families.
1
15
137
22,583
Read full blog: lmsys.org/blog/2026-05-13-no…
1
5
1,075
LMSYS Org retweeted
Jun 8
Sleeper hit no more 😄
304M downloads and 744% in 3 months — humbled to see SGLang growing alongside this incredible community. Thank you all for building with us!
Jun 8

PyPI May 2026: 163.8 billion downloads ( 9.2% MoM).
The AI agent race is now measurable in download counts:
⚡ sglang: 304M ( 744% in 3 months), @lsyincs @sgl_project - the sleeper hit
🔀 litellm: 513M ( 425% in 3 months), @krrish_dh @ishaan_jaff @LiteLLM
📐 pydantic-ai-slim: 268M ( 85% MoM), @samuelcolvin @pydantic
🌐 langchain-protocol: 37M ( 524% in one month), @hwchase17 @LangChain
🕷️ browser-use: 24M ( 132% MoM), @mamagnus00 @gregpr07 @browser_use
🤝 crewai: 14.5M ( 108% MoM), @joaomdmoura @crewAIInc
boto3 still #1 at 3.3B. AWS wins the boring prize.
Full data: clickhou.se/43USFbm

2
4
11
2,675
We're excited to see Vortex built on SGLang!
By integrating directly into the serving stack, Vortex turns theoretical sparse-attention speedups into real end-to-end gains. It's a great example of why a programmable, production-grade serving layer matters.
Excited to build this with the community! 👏
Jun 5

🌀 Introducing Vortex — sparse attention designed by AI agents, efficient at scale.
📈 Same accuracy, way more throughput — across every model we tried 👇
🔹 GLM-4.7-Flash (MLA) → 4.7× faster
🔹 MiniMax-M2.7 (229B) → 1.37× faster
🔹 Qwen3-1.7B (agent-discovered!) → 3.46× faster
🤖 How? An agent writes a flow in a few lines of Python; Vortex compiles it into fused kernels in a real serving stack (SGLang) and benchmarks it end-to-end.
🏗️ The design: a Python frontend (vFlow) over a page-centric tensor abstraction (vTensor) a serving-integrated backend.
📄 arxiv.org/abs/2606.06453
💻 github.com/Infini-AI-Lab/vor…
🌐 infini-ai-lab.github.io/vort…
📚 infini-ai-lab.github.io/vort…

3
3
24
4,594
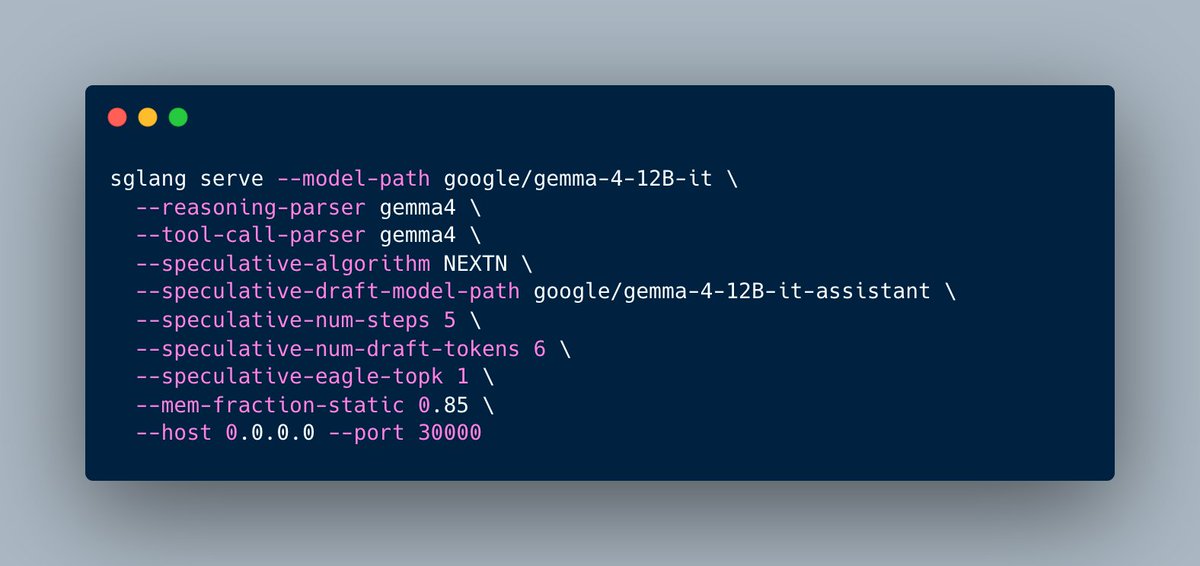
🎉 New Gemma 4 QAT checkpoints from @googlegemma, Quantization-Aware Training that shrinks memory while keeping quality. Day-0 support is now live in SGLang!
✅ Gemma 4 E2B down to 1GB with a mobile-specialized format
✅ QAT beats standard PTQ on quality at the same compression
✅ Q4_0 MTP checkpoints keep the MTP speedup while quantized
Run it now with SGLang!
Jun 5
We just dropped Gemma 4 Quantization-Aware Training (QAT) checkpoints on Hugging Face!
All Gemma 4 model sizes and their drafters are now optimized with QAT to cut memory requirements and maximize on-device performance!
4
6
105
11,394
Check out our cookbook: docs.sglang.io/cookbook/auto…
5
846