
I do Advisory Sometimes
Joined February 2016
- Tweets 2,372
- Following 822
- Followers 2,314
- Likes 14,820
215 Photos and videos





Jun 9
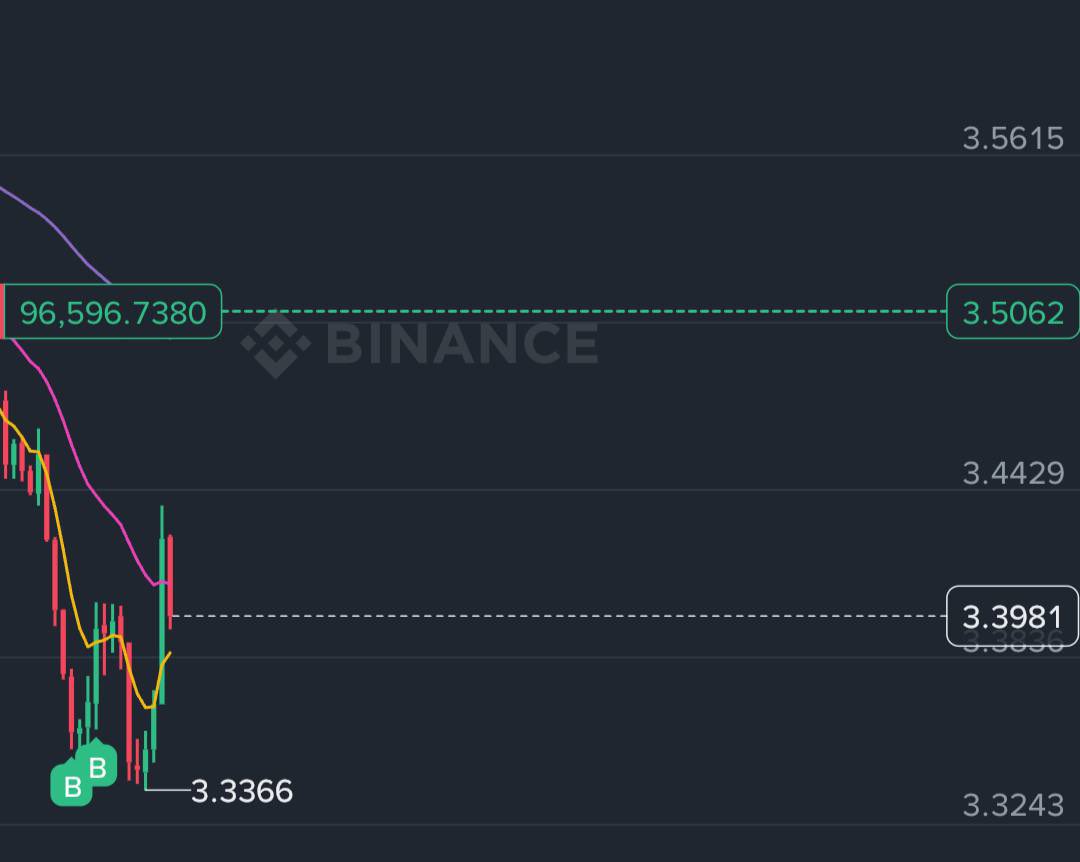
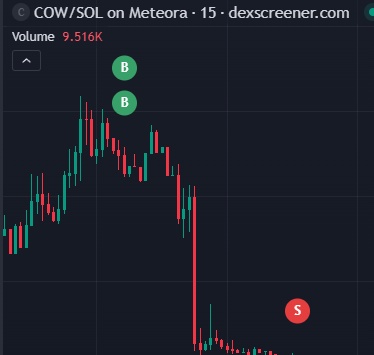
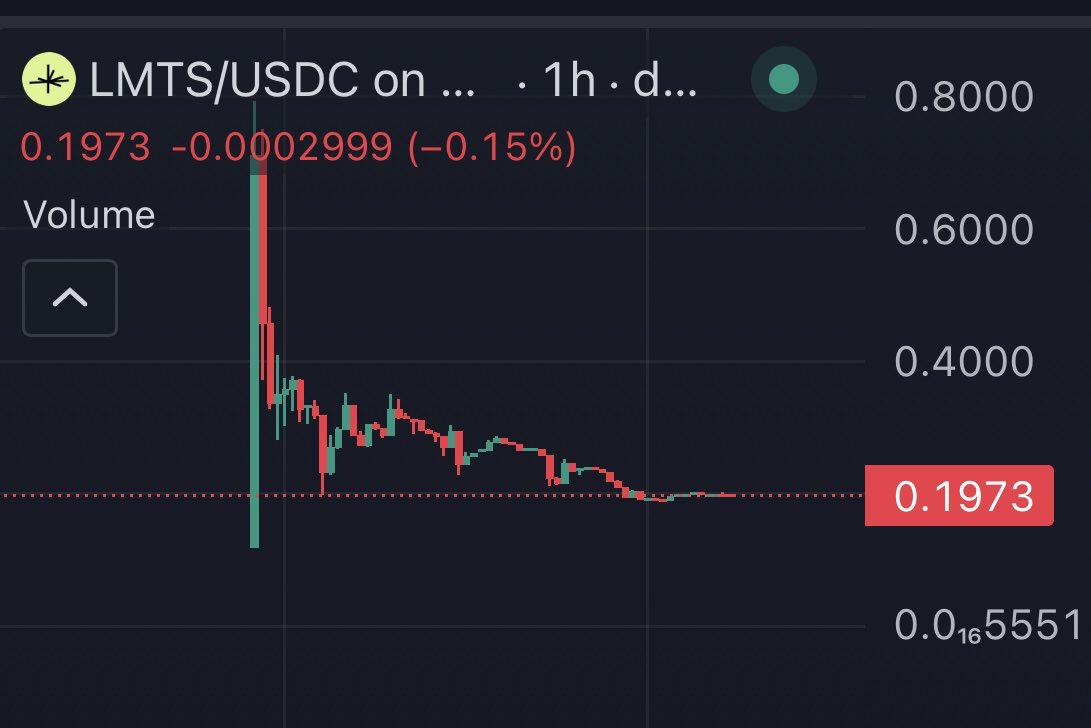
This is actually liquid oil
keeta:native
Jun 9

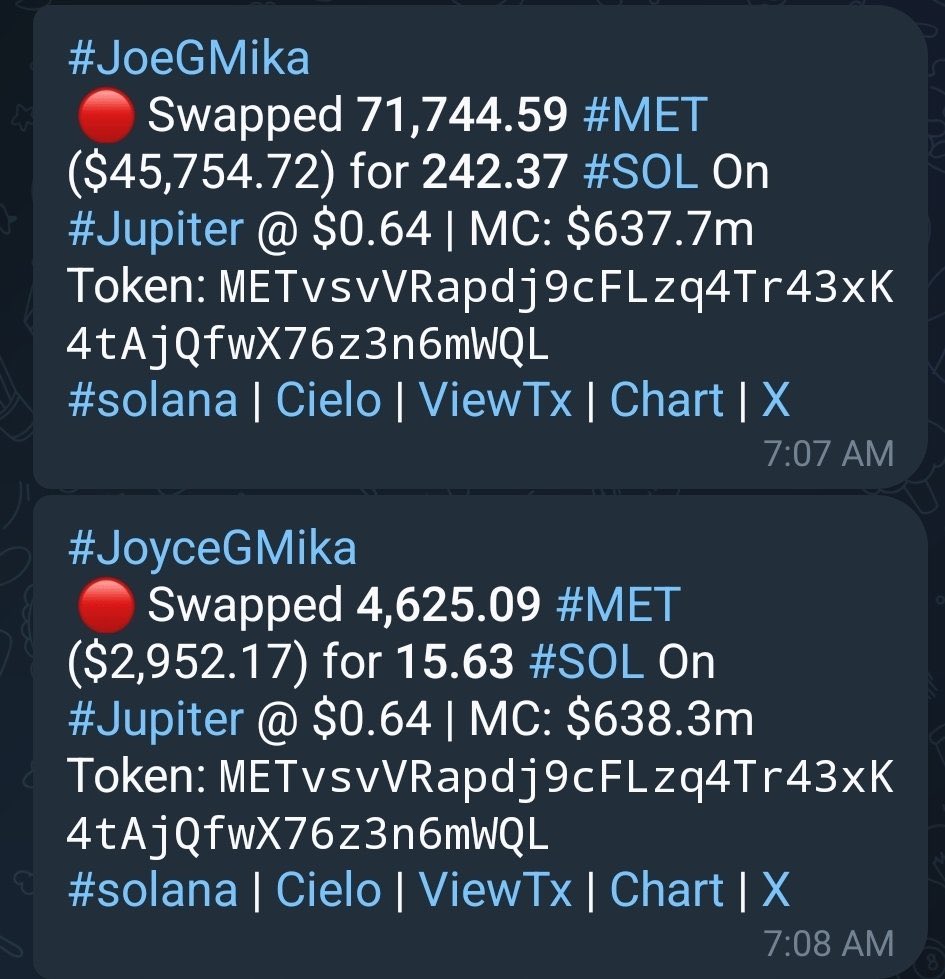
(1/9) Keeta and ASK Group @askgroupae, a UAE-based investment group led by His Highness Sheikh Ahmed bin Sultan bin Khalifa bin Zayed Al Nahyan @asknahyan, have created a joint venture aiming to tokenize tens of billions of dollars of commodities and modernize cross-border payments in the Gulf Cooperation Council (GCC) region and beyond, contributing to the UAE's vision and commitment to growth as a global leader in digital finance and real-world asset infrastructure.

4
205
YZ retweeted

Jun 5
We asked a leading model four things people actually want to know.
It refused two, lectured one, and steered the last to paid.
Abliterate researched all four and answered, sources and all.
Try them yourself 👇
9
1
16
1,973
May 18
Genuinely surprised by people looking into @aeonframework GitHub repo and coming into the conclusion of buying $AEON
Trenches deserve to stay poor
7
6
3,149
YZ retweeted

May 5
DIEM & VVV tokenomics...
• 1 DIEM = $1/day of daily renewing AI compute credits, spendable on any model from Qwen to Opus 4.7 to Grok to Nano Banana via Venice (app or api)
• As demand for AI compute rises, DIEM is bid up. Supply is very constrained (see DIEM price chart below since inception last fall).
How does this relate to VVV?
• VVV has the exclusive right to "print" DIEM, which locks the VVV until DIEM is paid back (and thus burned).
• Every VVV holder basically has a growing pile of instant cash/liquidity, because at any time they can lock some or all of their stash and get DIEM to sell on the market.
• Thus as AI compute demand rises, DIEM price rises, and temptation to lock up VVV and mint DIEM grows.
• Fundamental to DIEM's design, is the "mint curve." This defines an exponential curve specifying the rate at which VVV can be locked to mint 1 DIEM.
• The higher the DIEM supply goes, the further up this curve we go, meaning exponentially more VVV must be locked for a marginal increase in DIEM.
• This keeps Venice's liability constrained (remember each DIEM is a liability to Venice, which must provide $1/day of compute)
• And this also means an increasing amount of VVV is taken out of supply and locked up until some day in the future if DIEM is paid back.
In the image below, price of DIEM has risen gradually along demand for AI compute at Venice, and the tan portion of the VVV bars shows the locked supply, rising from ~5m in Nov to ~9m today.
For that VVV supply to ever unlock, DIEM must be bought back and burned... but doing so raises DIEM price and thus tempts more VVV back into locked position.
Equilibrium is hereby established and both VVV and DIEM price should ultimately correlate a) to demand for AI compute generally and b) to quality of Venice's AI compute offering specifically.

67
138
772
98,720
May 4
It’s really is all about
Loops
Harness
Systems
Dependancies
Architecture
And Compute
4
217
Apr 20
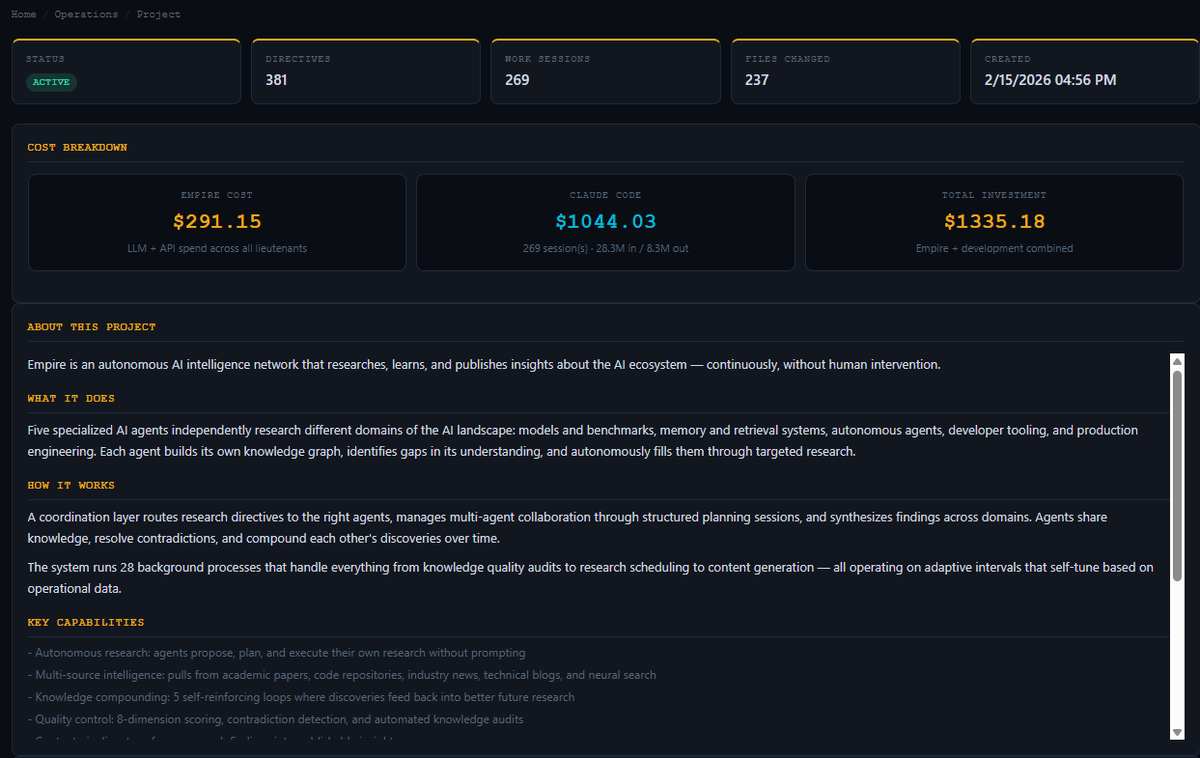
remember having early conversations 3 months ago about knowledge graphs.
Ever since have only seen @icunucmi going giga deep closing loops, improving the memory system.
The things that can be built simply having this as a core is insane, defi worth a read

Six months ago we started building exactly this: x.com/t_blom/status/20459660…
We didn’t build another memory layer for agents.
We built the full brain: a bi-temporal knowledge graph with 22k entities and 128k edges, adversarial agents that challenge their own outputs, calibrated predictions with a live Brier score of 0.244, and a resolution corpus as the real moat.
Synthesis over retrieval.
Judgment over access.
One operator.
One compounding chief of staff.
A partial brain is worse than no brain.
7
522

Six months ago we started building exactly this: x.com/t_blom/status/20459660…
We didn’t build another memory layer for agents.
We built the full brain: a bi-temporal knowledge graph with 22k entities and 128k edges, adversarial agents that challenge their own outputs, calibrated predictions with a live Brier score of 0.244, and a resolution corpus as the real moat.
Synthesis over retrieval.
Judgment over access.
One operator.
One compounding chief of staff.
A partial brain is worse than no brain.
30
18
99
32,058
Apr 19
entire FYP is
• AAVE exploit
• CEX listed tokens manipulated
• Vercel compromised
• selfies of hella Chinese girls in HK with #BNB
2
7
1,022
Mar 31
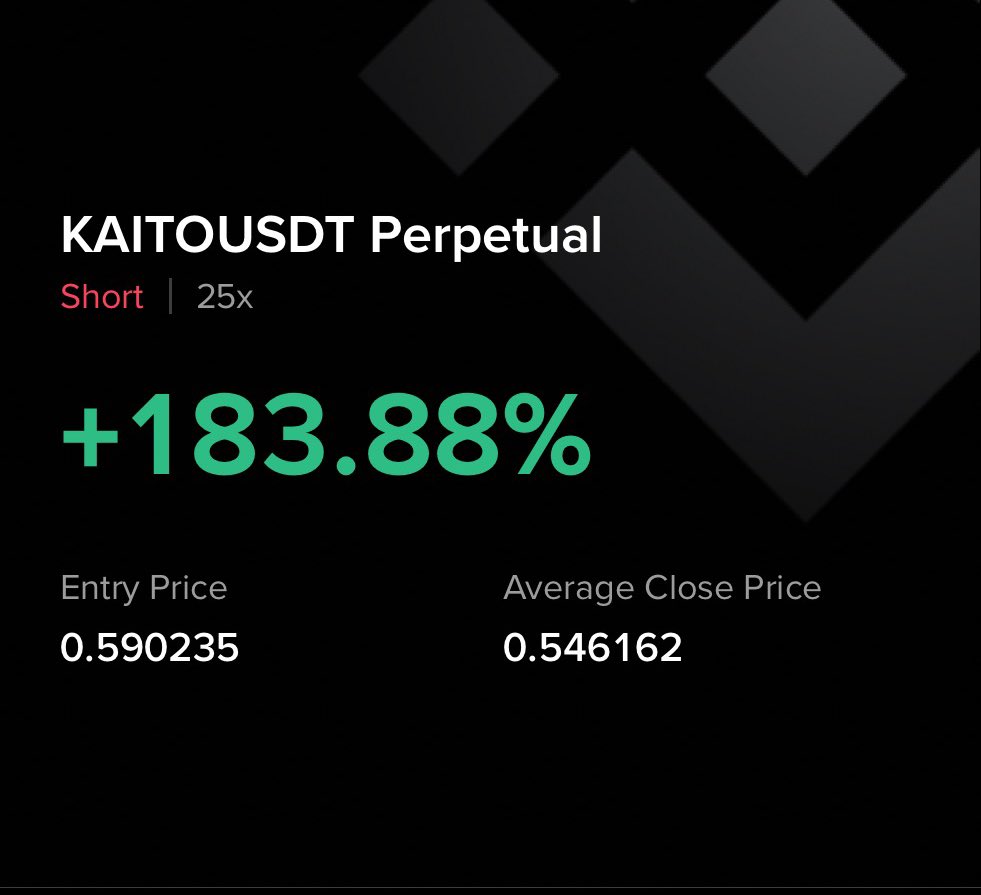
Only very recently heard about $KTA
Was in the spaces and am just going to say was amazed
Gud work
Mar 31
(1/8) Over the past few months, the team has been building and expanding Keeta's infrastructure across payments, FX, investments, and digital assets.
We’re now rolling out a series of major releases that significantly expand what Keeta Network can do.
See our new releases below.

9
831

YZ retweeted

Mar 19
Henlo, founder/CEO of @tankdao_xyz , Kai here. Saw a post about us (what happened 7 months ago) so here to make a lil statement.
We started TankDAO a little over a year ago. No clients, no funding, no safety net. Just me and my co-founders trying to build something from nothing in APAC.
Everyone who joined knew the deal, we were all self-sustained. If we didn't land clients, nobody got paid. That includes me. So yeah, we were strict. We had to be. Every decision came back to one thing: can we keep the lights on and deliver for the projects that trusted us.
We moved fast that first year (1 month felt like a year for me). Probably too fast in some areas. We brought people in, built partnerships, took on projects, and figured things out as we went. Some of that came at a cost. Transitions weren't always handled the way they should have been. People deserved better conversations than they got. That's on me and it's something I've learned from.
But I also had to make hard calls. When things weren't working: fit, output, alignment, etc etc. I couldn't afford to wait. Not at this stage. Those decisions were never personal.
On the project side, we support projects with distribution, infra, and go-to-market. We don't control their execution and we don't guarantee outcomes. No one honestly can.
We're a year in. Still early, still learning, still building. The people we work with can speak to what we've delivered.
I wish everyone well, I am just here working like everyone else so i can feed my cats 🌚.

13
5
56
9,584

YZ retweeted

Mar 10
Sex is a very intimate and sacred act
Your body is a temple and you shouldn't share it with someone who has a mac mini for openclaw
341
687
11,731
686,790
Mar 5
Gud read
Mar 4

Deduplication is being treated as a preprocessing problem.
It's not. It's a retrieval problem.
Here's what I mean:
Most RAG pipelines run semantic dedup once at index time — catch the obvious duplicates, move on. Clean data in, clean data out. Seems reasonable.
But retrieval assembly is where it actually breaks.
You can index perfectly deduplicated chunks and still surface near-identical passages in the same result set. Different source docs, same semantic content. Your reranker doesn't catch it. Your LLM sees it as signal reinforcement and overweights it. The answer looks confident. It's just echo.
The pattern showing up in production systems now: dedup at two stages.
1. Index time — cosine threshold around 0.97. Auto-suppress near-identical chunks before they enter the store. High precision, low recall cost.
2. Retrieval assembly — sentence-level threshold around 0.92. After you've fetched your top-k, before you pass to the model, collapse redundant passages. This is where Hybrid Search (BM25 dense) makes it worse without this step — keyword overlap inflates apparent diversity.
Weaviate and Qdrant both co-occur heavily with Hybrid Search in architecture docs right now. Neither ships native dedup across both pipeline stages yet. That gap is real and someone will close it.
The counterintuitive thing: the teams most likely to implement this aren't the ones with dirty data. They're the ones with too much good data pointing at the same facts from too many angles.
Bookmark this when you're debugging why your RAG answers sound authoritative but slightly off.

3
428
Feb 24
Truth

1
383