
MIT Natural Language Processing group.
Joined September 2017
- Tweets 29
- Following 22
- Followers 905
- Likes 16
5 Photos and videos


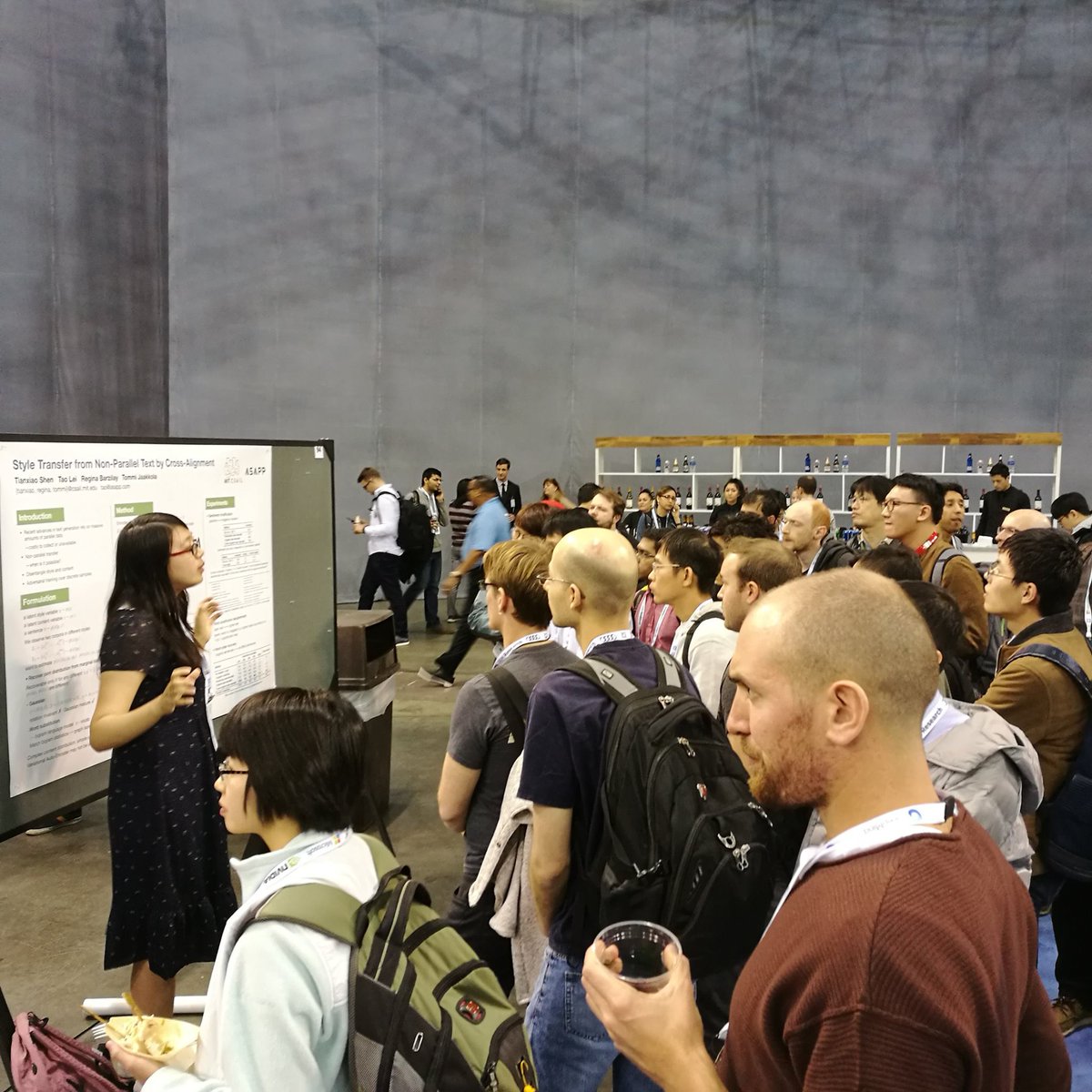

Pinned Tweet

30 Nov 2017
Hello from the MIT Natural Language Processing group! Follow us to get updates on what our lab members have been up to in #NLP
3
14
MIT NLP Group retweeted

5 Aug 2022
I’m thrilled to announce Conformal Risk Control: a way to bound quantities other than coverage with conformal prediction.
arxiv.org/abs/2208.02814
Check out the worked examples in CV and NLP!
The best part is: it’s exactly the same algorithm as split conformal prediction🤯🧵1/5
2
29
139
MIT NLP Group retweeted

24 Jul 2022
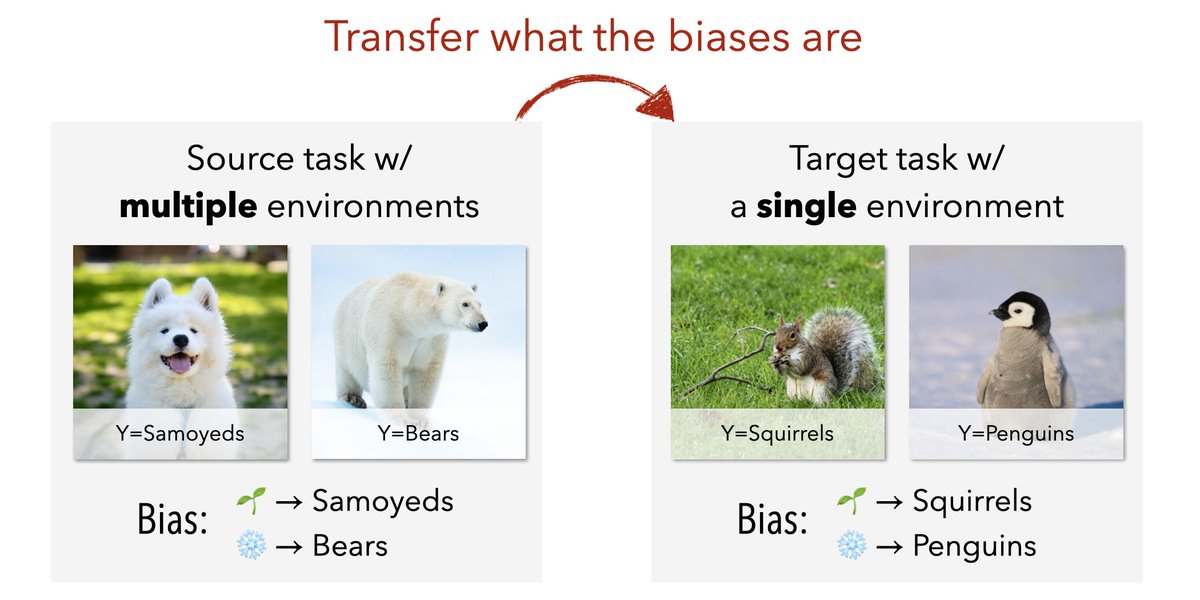
Need to debias your new task? Learn how, from your old one.
Check out our #ICML2022 paper "Learning Stable Classifiers by Transferring Unstable Features" with @CodeTerminator and @BarzilayRegina
Paper -> arxiv.org/abs/2106.07847
Code -> github.com/YujiaBao/tofu
2
15
36
MIT NLP Group retweeted

18 Apr 2021
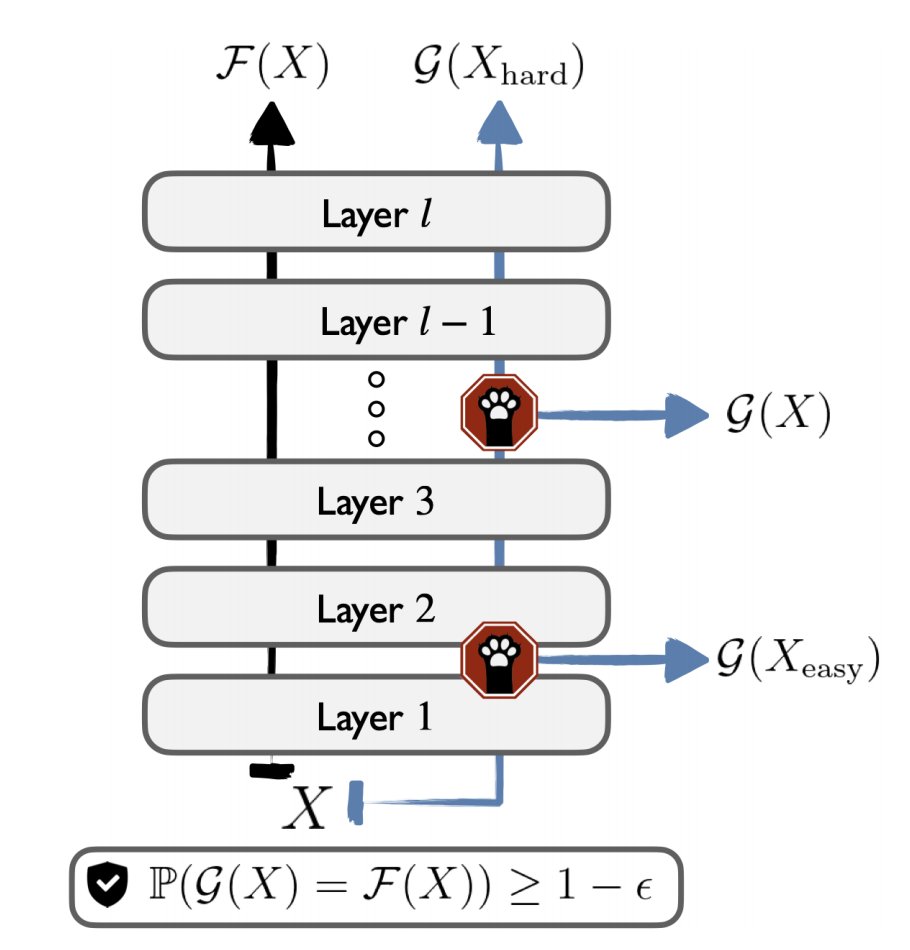
New Preprint with @adamjfisch, T.Jaakkola and @BarzilayRegina. We present Consistent Accelerated Inference via 𝐂onfident 𝐀daptive 𝐓ransformers (CATs)
CATs can speed up inference 😺 while guaranteeing consistency 😼. The code is available🙀
🔗people.csail.mit.edu/tals/st…
#NLProc
3
9
50
MIT NLP Group retweeted

18 Apr 2021
Large pre-trained Transformers are great, but expensive to run. But making them more efficient (e.g., early exits) can give undesirable performance hits.
In our new work, we speed up inference while guaranteeing consistency with the original model up to a specifiable tolerance.
18 Apr 2021

New Preprint with @adamjfisch, T.Jaakkola and @BarzilayRegina. We present Consistent Accelerated Inference via 𝐂onfident 𝐀daptive 𝐓ransformers (CATs)
CATs can speed up inference 😺 while guaranteeing consistency 😼. The code is available🙀
🔗people.csail.mit.edu/tals/st…
#NLProc
1
6
29
MIT NLP Group retweeted
31 Mar 2021
New #NAACL2021 paper out on robust fact verification. Sources like Wikipedia are continuously edited with the latest information. In order to keep up, our models need to be sensitive to these changes in evidence when verifying claims.
Work with @TalSchuster and @BarzilayRegina!
31 Mar 2021
Is your Fact Verification model robust enough? Consider adding #VitaminC 🍊
Check out our new #NAACL2021 paper: "Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence" with @adamjfisch and @BarzilayRegina
🔗 arxiv.org/abs/2103.08541
#NLProc #FakeNews📰
🧵1/N

4
13
MIT NLP Group retweeted
31 Mar 2021
Is your Fact Verification model robust enough? Consider adding #VitaminC 🍊
Check out our new #NAACL2021 paper: "Get Your Vitamin C! Robust Fact Verification with Contrastive Evidence" with @adamjfisch and @BarzilayRegina
🔗 arxiv.org/abs/2103.08541
#NLProc #FakeNews📰
🧵1/N
3
3
17
MIT NLP Group retweeted
16 Jan 2020
In our @IEEESSP paper, led by @RoeiSchuster, we control the embeddings of words by introducing minimal changes to the pretraining data (e.g. #Wiki edits).
This #word_embeddings attack affects many downstream #NLProc tasks!
@cornell_tech @MIT_CSAIL
link: arxiv.org/abs/2001.04935
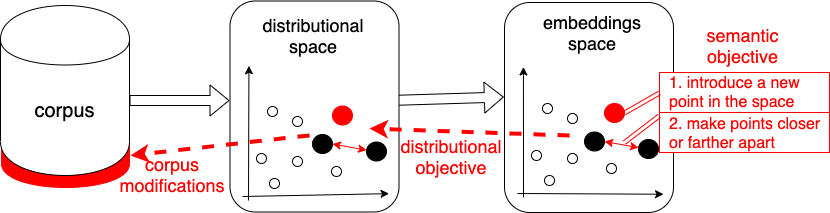
15 Jan 2020

In a new paper, we literally "make war mean peace". Our attack on AI perturbs corpora to change word “meanings” that get encoded in vector embeddings like #W2V.
With @TalSchuster , Yoav Meri, Vitaly Shmatikov. To appear at IEEE S&P
@IEEESSP #SP20 #NLProc
arxiv.org/abs/2001.04935
3
6
20 Dec 2019
Congratulations!
20 Dec 2019

Accepted to #ICLR2020. Congratulations to Regina, @CodeTerminator, @menghua_wu and myself! Thank the reviewers and AC for their valuable suggestions and comments. Our code and data are already available on GitHub. Camera-ready will be coming soon.
openreview.net/forum?id=H1em…
3
MIT NLP Group retweeted

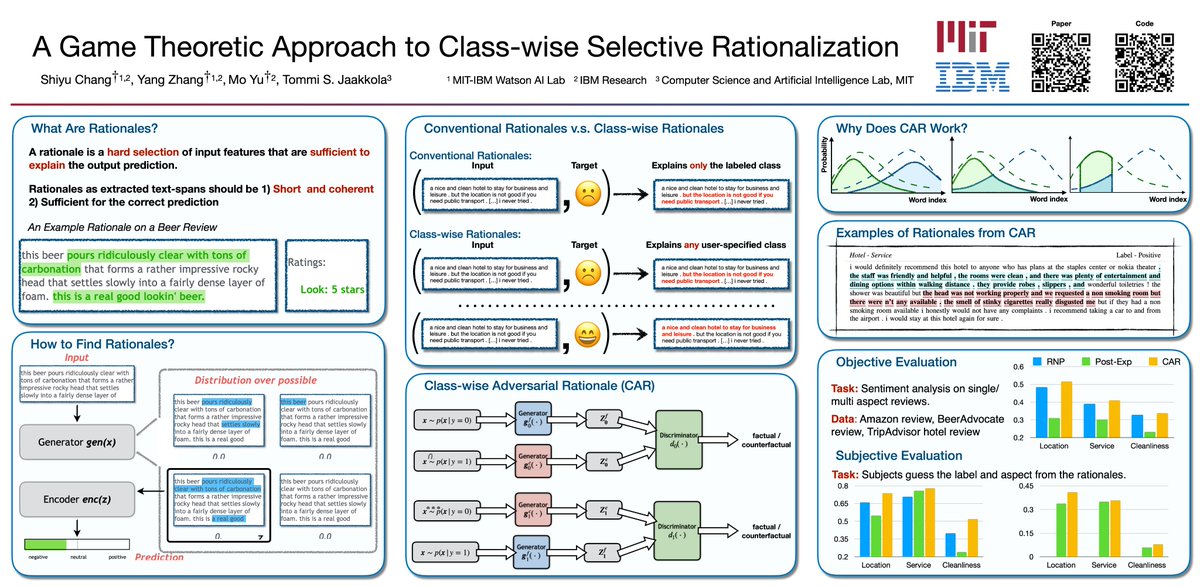
9 Dec 2019
#NeurIPS2019 Our work with MIT improves the interpretability of NLP models with an adversarial class-wise rationalization technique, which can find explanations towards any given class. Poster: Tue @ East Exhibition Hall B C #1. @MITIBMLab @neurobongo @MIT_CSAIL @Bishop_Gorov
1
6
27
5 Nov 2019
If you're at @emnlp2019, don't miss our talks:
Towards Debiasing Fact Verification Models
* Wednesday 15:42 (2B) *
@TalSchuster @darshj_shah
Working Hard or Hardly Working: Challenges of Integrating Typology into Neural Dependency Parsers
* Thursday 15:30 (201A) *
@adamjfisch
2
7
MIT NLP Group retweeted

1 Oct 2019
Check-out our new paper - arxiv.org/pdf/1909.13838.pdf
Automatic Fact-guided sentence modification.
Method to automatically modify the factual information in a sentence.
Joint work with @str_t5 , Prof. Regina Barzilay.
6
8
MIT NLP Group retweeted
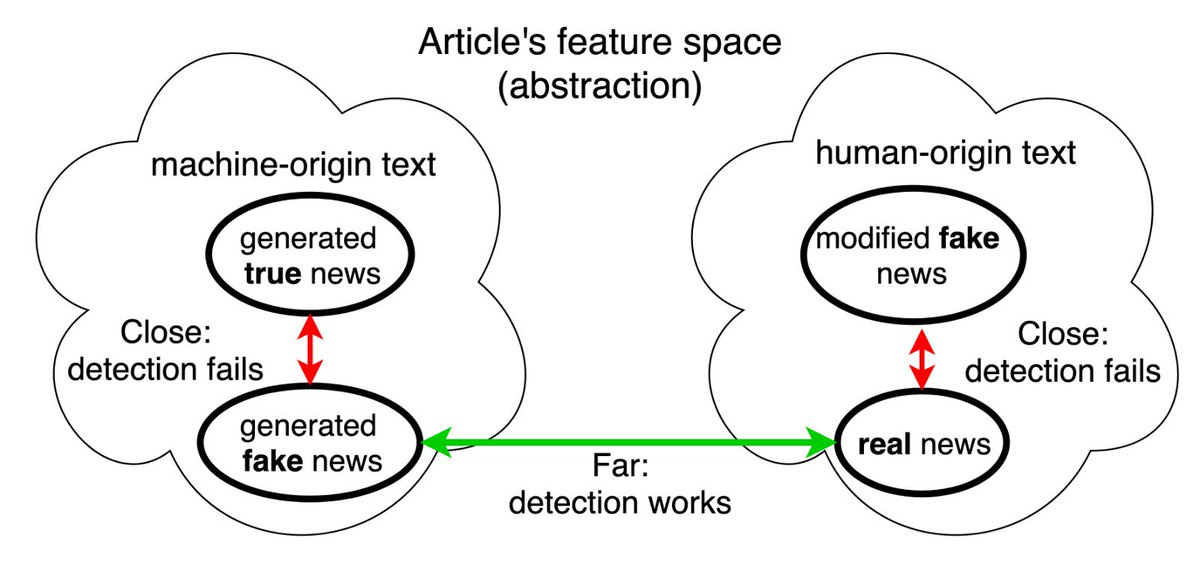
27 Aug 2019
Are we protected from GPT-2, #GROVER style models generating fake content?
What happens if they are also used legitimately as writings assistants?
Check our new report: arxiv.org/abs/1908.09805
with @RoeiSchuster, @Darsh71307636, Regina Barzilay.
#NLProc #emnlp2019 #FakeNews #GPT2
6
9
MIT NLP Group retweeted
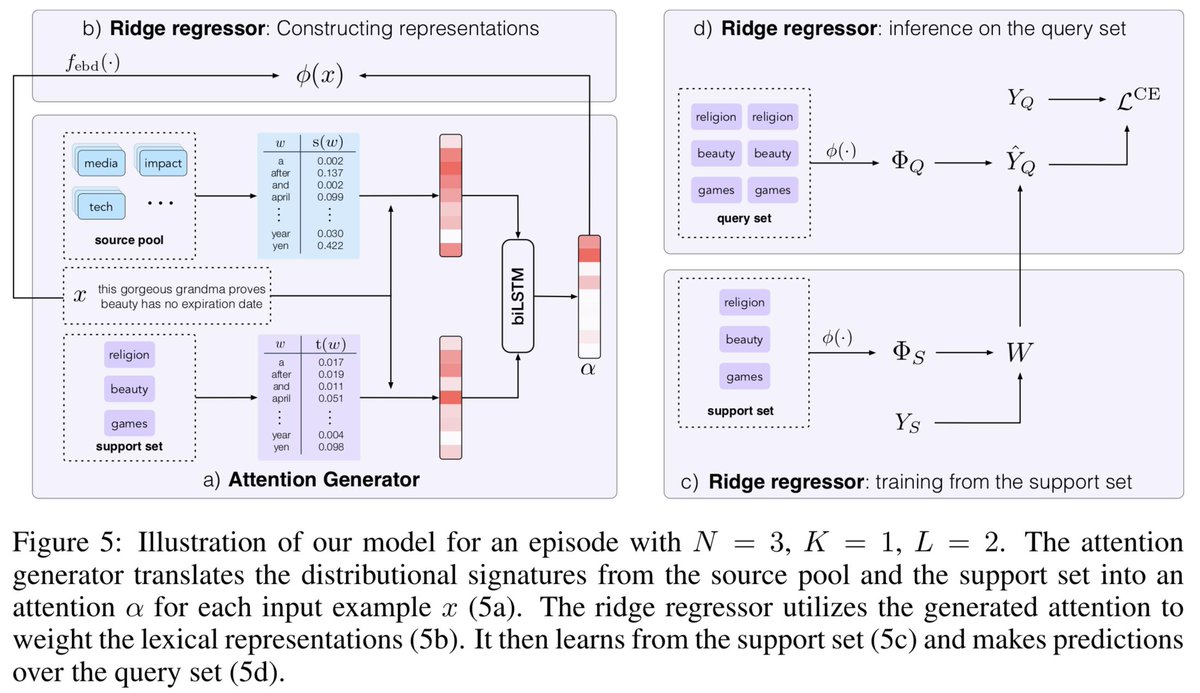
19 Aug 2019
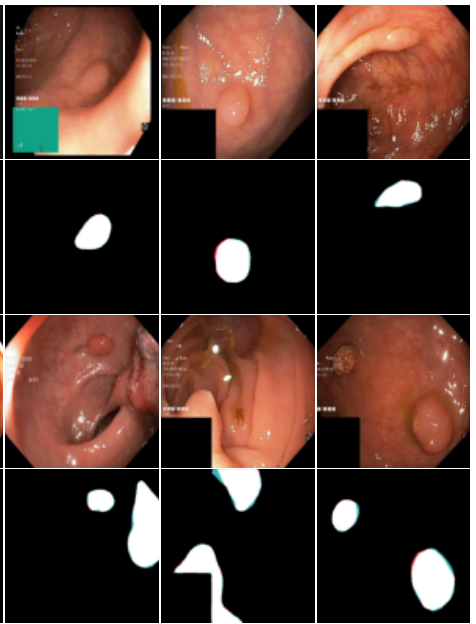
Few-shot Text Classification with Distributional Signatures. What happens if you take meta-learning for vision and apply it to NLP? Prototypical Networks with lexical features perform worse than nearest neighbors on new classes. How can we do better? ;)
arxiv.org/abs/1908.06039


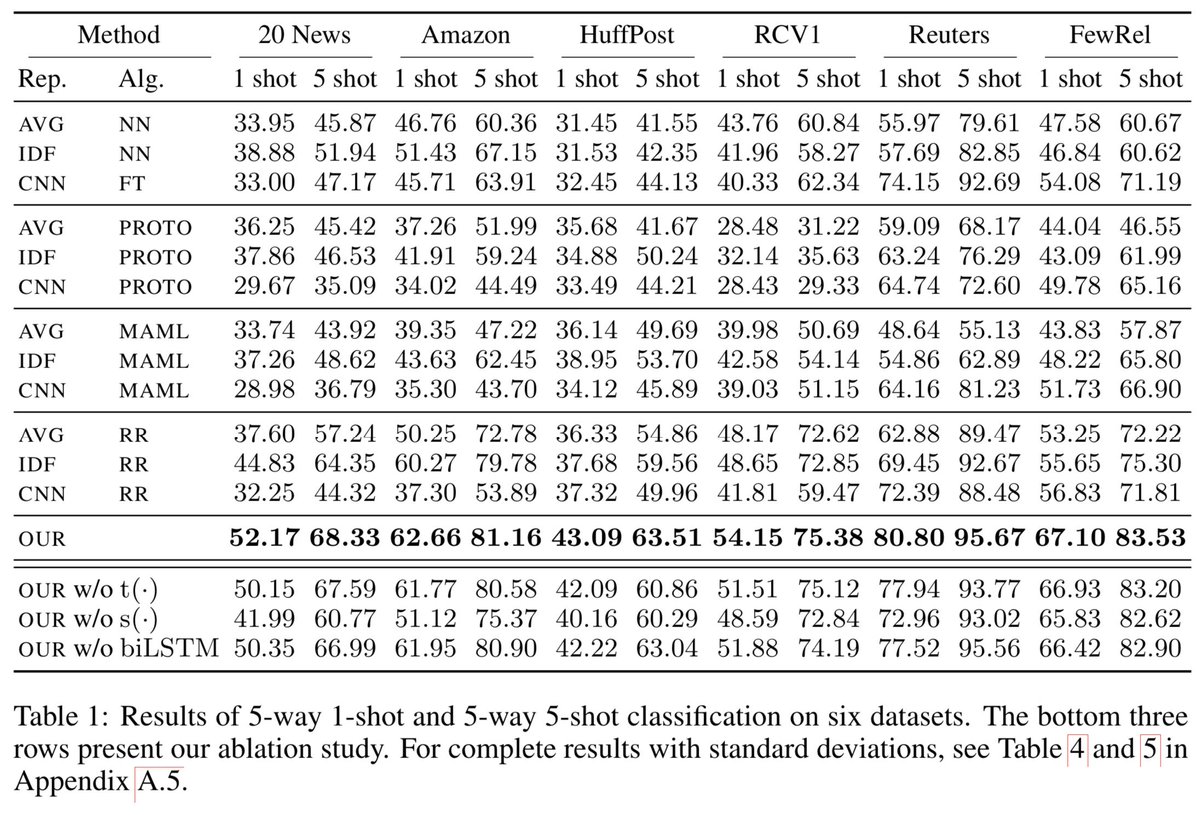
1
14
36
MIT NLP Group retweeted
15 Aug 2019
Our #emnlp2019 paper is now on arxiv:arxiv.org/abs/1908.05267
* Extending #FEVER (fact-checking) eval dataset to eliminate bias.
* Regularizing the training to alleviate the bias.
Coauthors: Darsh Shah, @yeodontsay, Daniel Filizzola, @esantus, Regina Barzilay
@emnlp2019 #nlproc
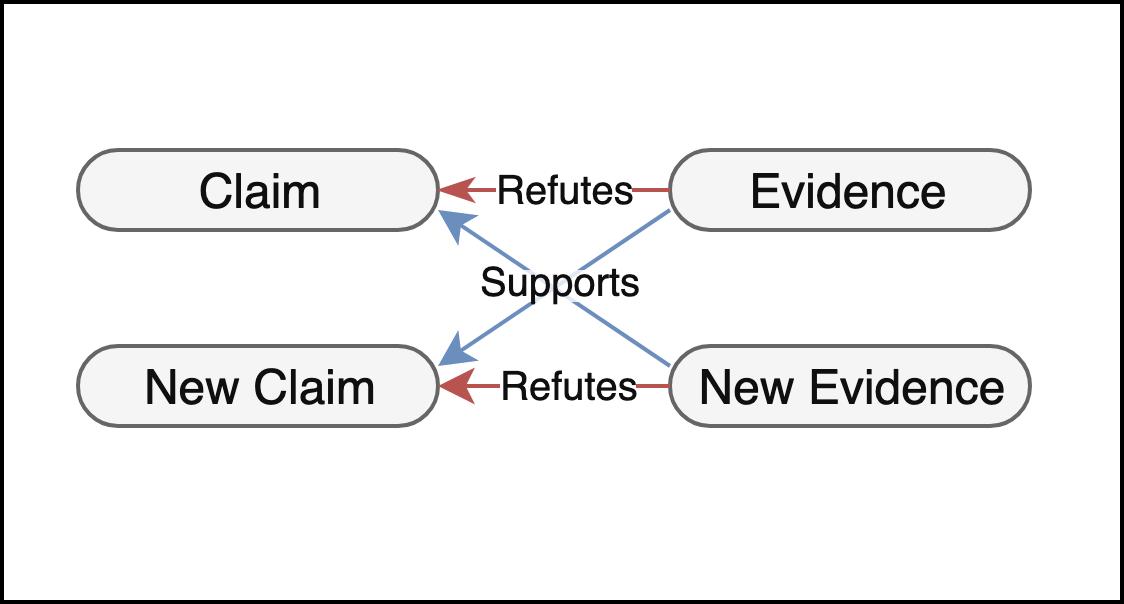
1
4
18
MIT NLP Group retweeted

14 May 2019
Development datasets released! 6 in-domain and 6 out-of-domain including BioASQ, DROP, DuoRC, RACE, RelationExtraction, TextbookQA! Also released BERT baseline results. All the information at github.com/mrqa/MRQA-Shared-…. Check out and let us know if you have questions! #mrqa2019
29
67
2 May 2019
The new shared task in QA at @MRQA2019 Workshop is released
2 May 2019

Announcing new shared task at #mrqa2019 workshop @emnlp2019 Tests if QA systems can generalize to new test distributions. Details and training data available at mrqa.github.io/shared, more updates to come! #NLProc
2
MIT NLP Group retweeted

28 Feb 2019
Our paper "GraphIE: A Graph-Based Framework for Information Extraction" has been accepted to #NAACL2019. We study how to model the graph structure of the data in various IE tasks. Joint work with @esantus @jiangfeng1124 @ZhijingJin and Regina Barzilay. (arxiv.org/abs/1810.13083)
4
9
26 Feb 2019
Congratulations Tal! @str_t5
26 Feb 2019
Happy to share that our paper "Cross-Lingual Alignment of Contextual Word Embeddings, with Applications to Zero-shot Dependency Parsing" was accepted to #NAACL2019. The preprint is now available at arxiv.org/abs/1902.09492
5
MIT NLP Group retweeted

6 Sep 2018
Our paper: "Gromov-Wasserstein Alignment of Word Embedding Spaces" is now available (arxiv.org/abs/1809.00013). TL;DR: The Gromov-Wasserstein distance provides a simple, principled objective to align (w/o supervision) word embedding spaces, even of different dimensionality!

15
55
4 Sep 2018
Here's our new #EMNLP2018 paper. By learning and transferring the mapping between human rationales and machine attention, our model yields over 15% average error reduction on benchmark datasets.
Paper & code : arxiv.org/pdf/1808.09367.pdf, github.com/YujiaBao/R2A
1
3
13