
Working on Gemini @GoogleDeepMind | formerly: PhD @MIT_CSAIL @MITNLP. Opinions my own
Joined September 2014
- Tweets 493
- Following 815
- Followers 1,843
- Likes 1,728
49 Photos and videos








Pinned Tweet

15 Jul 2022
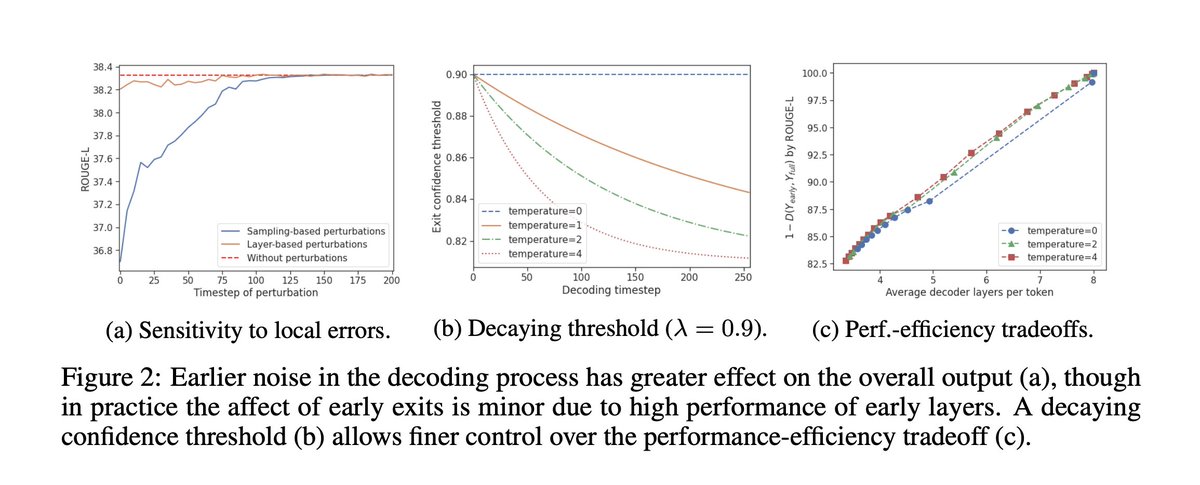
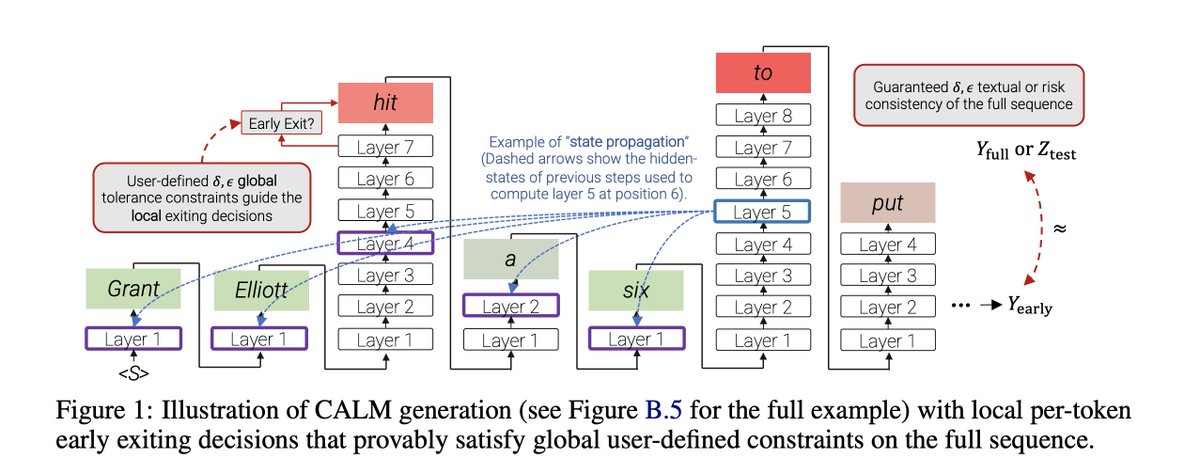
Introducing our work @GoogleAI CALM: Confident Adaptive Language Modeling 🧘
Large Language Models don't need their full size for every generated token. We develop an Early Exit framework to significantly #accelerate decoding from #Transformers!
🔗: arxiv.org/abs/2207.07061
🧵1/
21
269
1,525
Tal Schuster retweeted

Jun 7
Gemma 4 MTP just got officially merged into llama.cpp
This means you can use Gemma 4 QAT MTP for a lightweight super fast setup. Excited to see what the community builds with it
github.com/ggml-org/llama.cp…
57
130
1,228
93,435
Tal Schuster retweeted

Jun 4
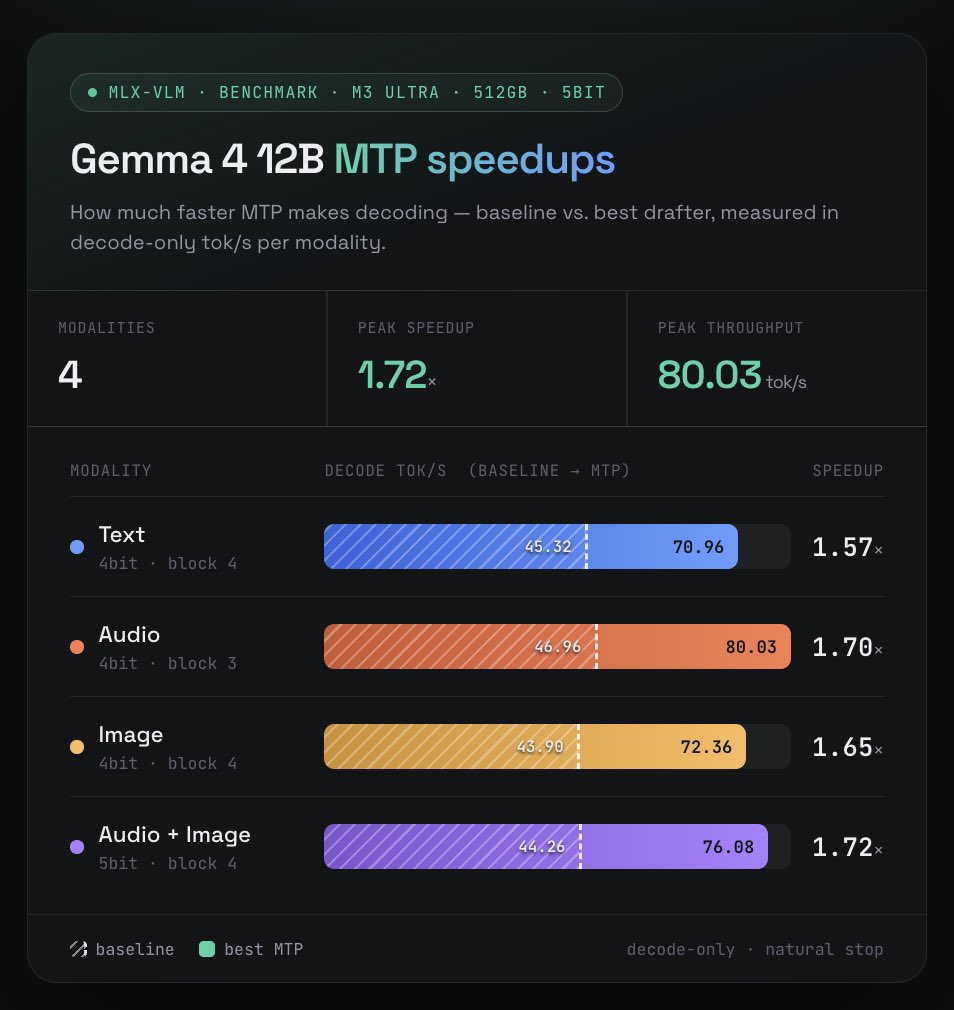
Gemma 4 12B MTP speculative decoding on mlx-vlm 🚀
We benchmarked MTP on Gemma 4 12B across all 4 modalities in mlx-vlm — and it speeds up everything:
text, image, audio, and combined audio image, up to 1.72× and 80 tok/s on a single M3 Ultra.
Get started today:
> uv pip install -U mlx-vlm
github.com/Blaizzy/mlx-vlm
Jun 3

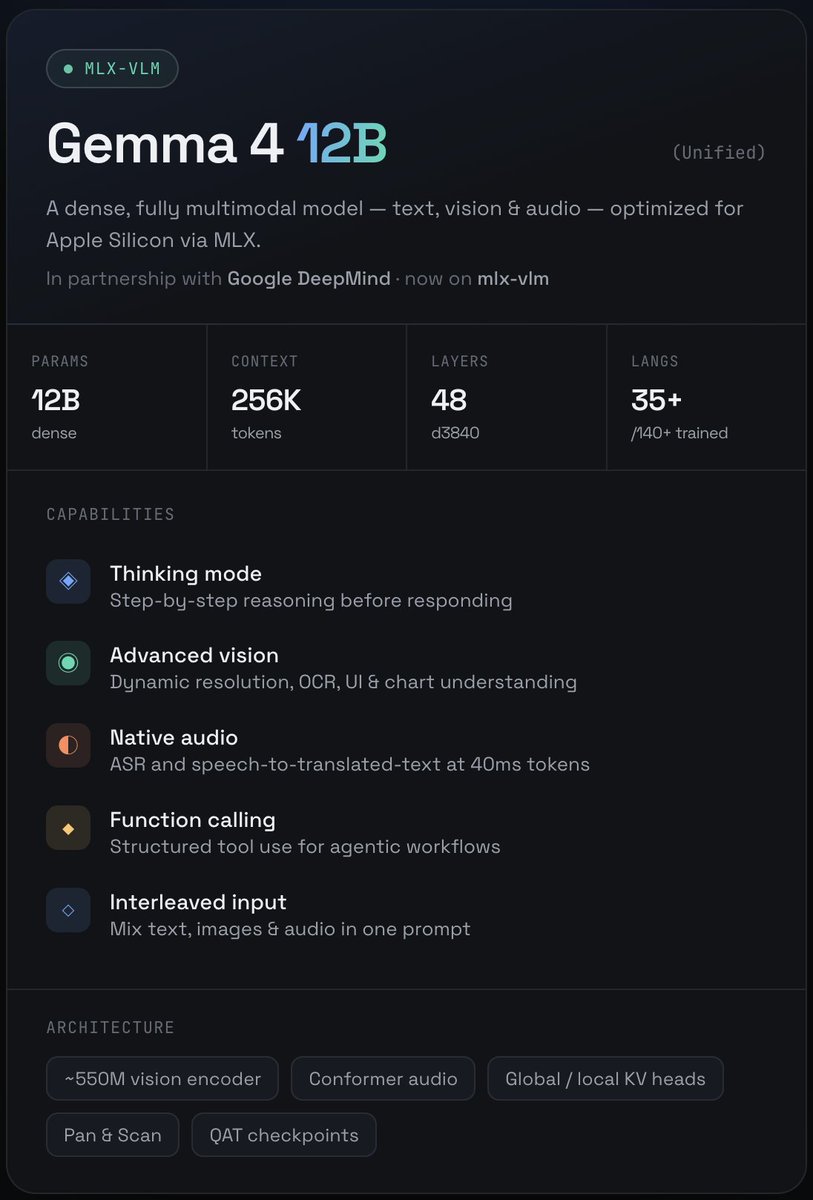
🚀 Gemma 4 12B is here!
We partnered with @GoogleDeepMind to bring and optimize their new dense and unifed multimodal model for Apple Silicon.
◈ 12B dense · 256K context
◈ Thinking mode (built-in reasoning)
◈ Vision: dynamic res, OCR, UI charts
◈ Native audio: ASR speech translation
◈ Function calling for agents
◈ Text image audio, interleaved
Runs local. Get started now ⚡
> uv pip install -U mlx-vlm
github.com/Blaizzy/mlx-vlm
20
21
294
34,471
Tal Schuster retweeted

May 6
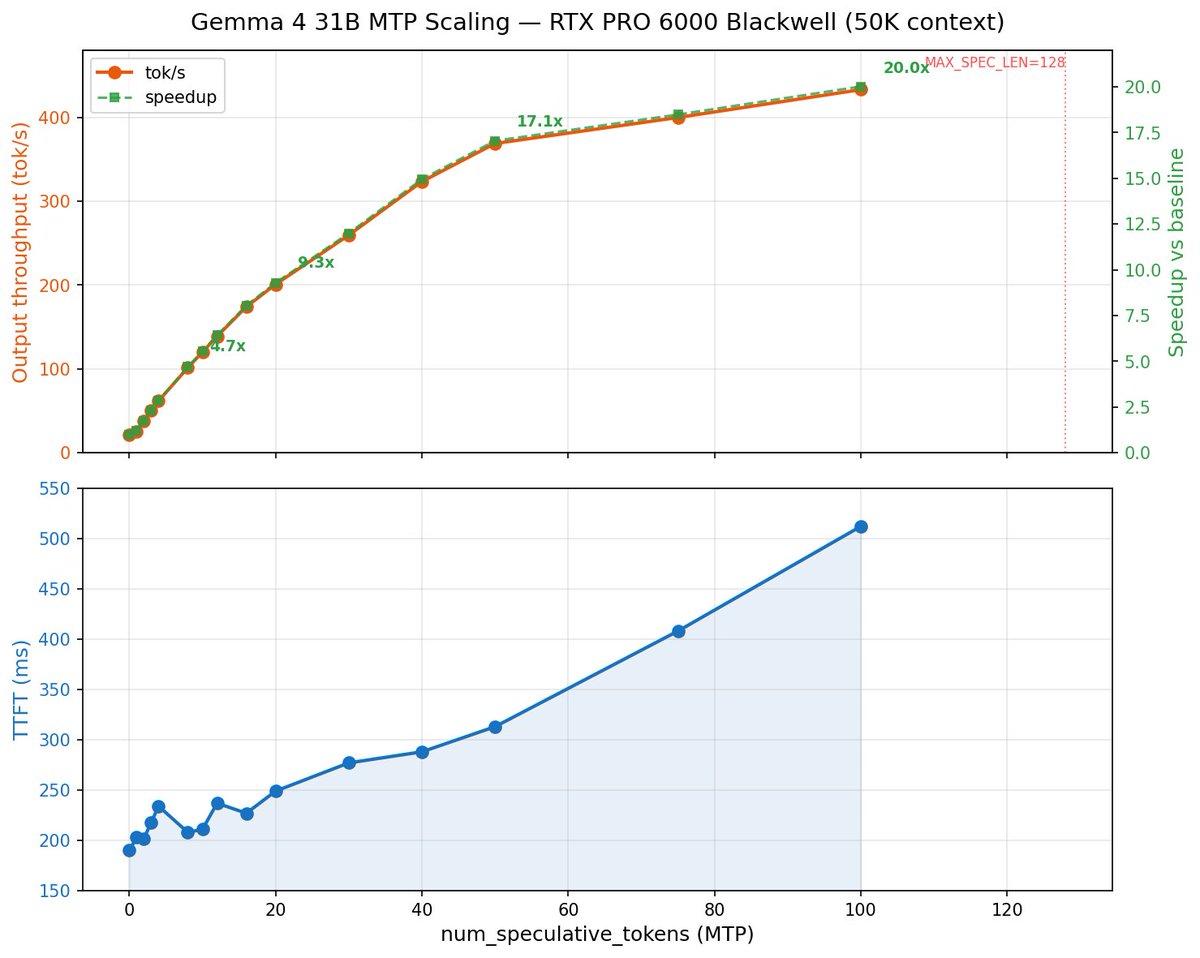
Local AI at 400 tok/s, zero loss, Gemma 4 31B 🤯 Google's MTP approach is way better than Qwen's because it SCALES with MTP parameter but Qwen peaks at MTP=3. I can now have FULL BF16 Gemma 4 31B at 400 tok/s on RTX 6000 Pro using MTP=100, video coming soon!
May 6

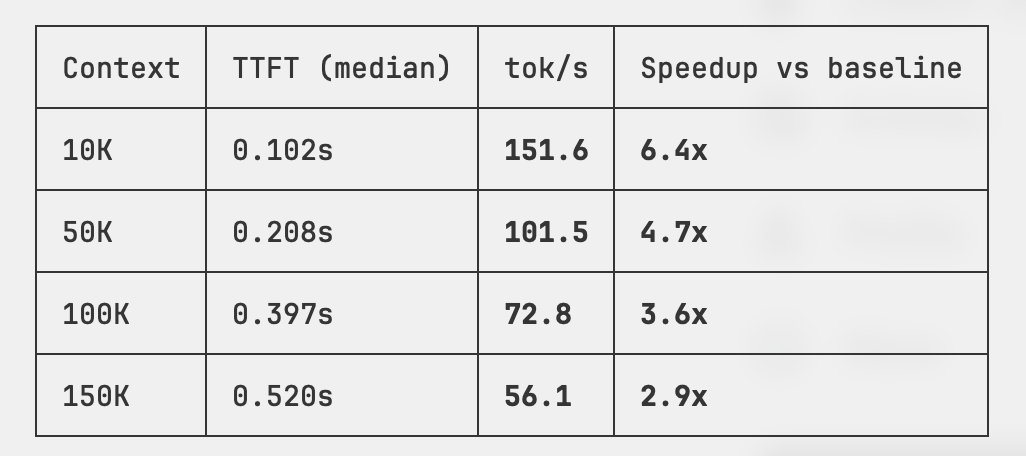
staggering! 🚨 I ran Google's new MTP for Gemma 4 31B (full BF16) on vLLM RTX 6000 Pro (600W). The results are humbling! Next: I'll run dFlash from @zhijianliu_ for comparison; local AI is shaping up good 😎
22
46
511
46,312
Tal Schuster retweeted

May 7
Gemma 4 up to 3x faster, directly in your phone! 🚀
Check out the difference Speculative Decoding makes! Multi-Token Prediction (MTP) is supercharging inference speeds for Gemma 4.
51
170
1,746
123,115
Tal Schuster retweeted

May 7
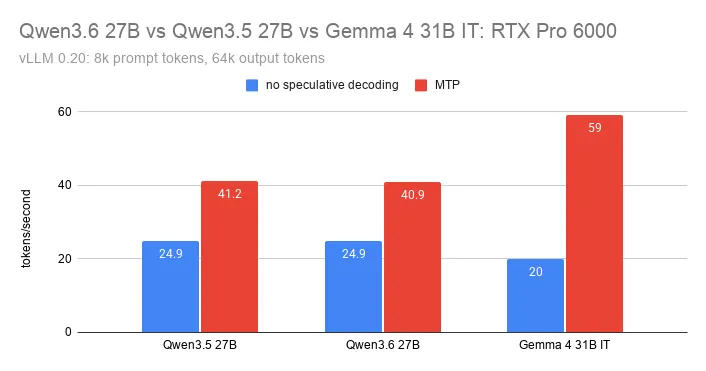
I benchmarked Google’s new MTP for Gemma 4 31B using vLLM with 4 speculative tokens, a fairly conservative setup.
Results:
- Much higher throughput than Qwen3.6’s MTP
- Lower latency too, helped by Gemma 4 generating fewer tokens
- For coding tasks with reasoning enabled, Gemma 4 is now at least 6x faster than Qwen3.6. So you can generate 5 outputs, run your tests to select the best one, and it would still be cheaper than a single output by Qwen3.6.
I’ve updated my full comparison with the new numbers:
kaitchup.substack.com/p/qwen…
I also confirmed what others have reported: Gemma 4’s MTP handles a high number of speculative tokens very well.
On simple text generation, I’m now testing values above 10 and reached 129 tok/s on an RTX Pro 6000, compared with 20 tok/s without MTP.
Next step: confirming how this translates to real tasks.
32
36
331
34,182

Google dropped MTP versions of Gemma4. Ran them on my DGX Spark.
The 31B dense model went from 3.94 → 8.91 tok/s. That's 126%.
Full results:
[26B A4B]
> 25.24 → 31.69 tok/s ( 25.6%)
> TTFT 755 → 332ms (-56%)
[31B]
> 3.94 → 8.91 tok/s ( 126%)
> TTFT 599 → 378ms (-37%)
If you're not running MTP, you're leaving free perf on the table.
19
12
133
47,616
May 6
Nice work from @zhijianliu_'s lab!
Native Gemma drafter gives high speedups across the board. For certain cases like low entropy outputs (greedy decoding, structured etc.) and memory bound stup (small bsz strong device), specialized techniques like this could further boost gen!
May 6

DFlash for Gemma 4: Up to 6x Faster. ⚡⚡
Great to see MTP land natively in Gemma 4 today. If you want to push it further, try DFlash — open source, same quality, more speed!!
github.com/z-lab/dflash
1
4
280
Tal Schuster retweeted

🚨 Google just made Gemma 4 up to 3x faster with MTP ⚡
Same quality, way more speed. It predicts multiple tokens at once and verifies them in parallel, removing latency bottlenecks.
You can also run powerful models locally on mobile like me using Google AI Edge Gallery.
14
24
300
25,160
Tal Schuster retweeted

May 5
🚀 Day-0 MTP support for Gemma4 now available at vLLM with ready-to-use docker image!
⚡️Enjoy up to 3x faster decoding performance to supercharge your development with zero quality degradation!
Check out the full vLLM recipes for Gemma 4 model series👇
recipes.vllm.ai/Google/gemma…


Gemma 4: Now up to 3x Faster. ⚡
Same quality, way more speed. Our new MTP drafters allow Gemma 4 to predict multiple tokens at once, effectively tripling your output speed without compromising intelligence.
17
98
902
88,904


Tal Schuster retweeted
May 5
Gemma 4 just got even faster!
We're releasing Multi-Token Prediction (MTP) drafters that deliver up to a 3x speedup, without any degradation in output quality or reasoning logic.
98
353
3,345
206,646
May 5
We've just released open source MTP style drafters for Gemma 4 models ⚡
Now Gemma 4 models are even faster on your choice of hardware, without losing quality!
Grateful for the fruitful collaboration between my team, Gemma team, and many collaborators to enable this release!
May 5

Excited to introduce Gemma 4 Multi-Token Prediction Drafters⚡️Accelerated inference right in your pockets
- Up to a 3x speedup
- Same quality guarantees
- Available in your favorite open-source tools
4
4
29
4,352
May 5
And beautiful benchmarks from @Prince_Canuma with MLX on Apple silicon
x.com/i/status/2051716011892…
May 5
Congratulations to @GoogleDeepMind on the launch of Gemma 4 Multi-Token-Prediction Drafters 🎉🚀
Happy to have partnered with them for Day-0 support on MLX
The new drafters accelerate both single and batch requests by upto 3x.
Here is a graph showing how different block sizes affect performance.
MLX-VLM release coming soon!
PR and model collection 👇🏽


1
6
1,605

Gemma v4 MTP drafters are out! 🚀
I was quite involved with the development of this, so I thought I might as well do a short summary of the key bits. :)
tl;dr: Nothing reduces your decode time like drafting. ⚡️
🔗 blog.google/innovation-and-a…
1
3
13
795
Tal Schuster retweeted

May 5
Si sois amantes de la familia de modelos Gemma 4, ojito a esto que acaban de meterle un boost de rendimiento que puede llegar hasta x3 más rápido, según el modelo, sin pérdida de calidad en sus respuestas o razonamientos 🔥
May 5
Excited to introduce Gemma 4 Multi-Token Prediction Drafters⚡️Accelerated inference right in your pockets
- Up to a 3x speedup
- Same quality guarantees
- Available in your favorite open-source tools
14
49
614
43,619
Tal Schuster retweeted

Gemma 4: Now up to 3x Faster. ⚡
Same quality, way more speed. Our new MTP drafters allow Gemma 4 to predict multiple tokens at once, effectively tripling your output speed without compromising intelligence.
167
627
6,069
837,083
May 5
And checkout @MaartenGr really cool visual guide to Gemma 4 that now also includes a detailed visual explanation of the drafter:
newsletter.maartengrootendor…
2
142
Feb 19
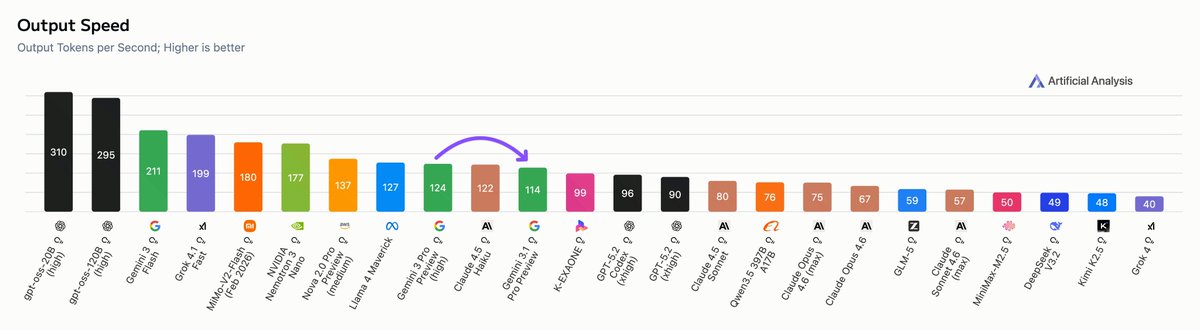
Better model for about the same speed. More to come!

Gemini 3.1 Pro Preview has an average speed of 114 output tokens/s. Although slightly slower than its predecessor (-10 t/s), it remains one of the fastest models in the top 10 of the Artificial Analysis Intelligence Index, trailing only other Google models (Gemini 3 Flash and Gemini 3 Pro Preview).
6
249