
Moving humans forward through radical AI research
Joined May 2026
- Tweets 3
- Following 2
- Followers 41
- Likes 1
1 Photos and videos

Pinned Tweet

Jun 2
Australia shouldn't have to rent its AI future.
So we built Matilda.
An Australian-built AI assistant, running on our own fully sovereign cluster in Melbourne.
Public access is rolling out now.
14
20
157
2,901,848
17h
We wrote our own inference engine in Rust 🦀 for our AMD MI355Xs, with no ROCm anywhere underneath it.
On the small all-reduce that tensor-parallel inference runs for every single token, it comes out about 1.3x faster than AMD's own RCCL at its best, sitting on what looks like the physical latency floor of the chip at around twenty microseconds.
As the first anywhere to have the MI355X fully deployed in production, running Matilda, inference is a huge focus for @MaincodeAU. In fact inference is the part of an AI business that actually meets customers, so we wanted to understand this hardware as deeply as we could. We took the runtime out and drove the GPU through the Linux kernel driver directly, the same interface ROCm itself is built on, to see how close to the silicon we could get.
RCCL is genuinely great and has years of careful work behind it, and it also has to be good at everything a runtime is ever asked to do. A layer that only has to do one thing really well can set all of that aside and cut its overhead to almost nothing. The win isn't a clever trick, just the absence of overhead.
And you don't have to take our word for it. The whole thing ships as a single container image with the kernels compiled in, and three commands reproduce the numbers on any MI355X box.
More in the blog post...
2
2
20
618,504
17h
2
80
Maincode retweeted

Jun 10
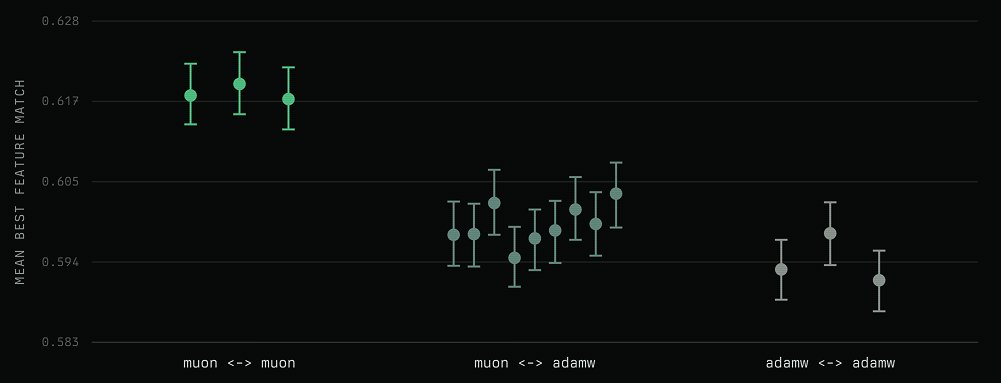
Muon has been a recent obsession of ours, so we dug deeper. It changes the loss curve, but does it change what a model learns?
We trained matched AdamW and Muon GPT-2-class models, held validation loss fixed, and compared their SAE features by firing patterns over the same 1M tokens.
The result: Muon model’s features match an AdamW model’s features about as well as two AdamW seeds match each other. So changing the optimizer perturbs SAE feature identity about as much as changing the random seed. Muon’s advantage is not “different features.” It is “same features, different geometry.”
2
1
113