
8 Photos and videos







*maxwell twelftree retweeted

22h
We wrote our own inference engine in Rust 🦀 for our AMD MI355Xs, with no ROCm anywhere underneath it.
On the small all-reduce that tensor-parallel inference runs for every single token, it comes out about 1.3x faster than AMD's own RCCL at its best, sitting on what looks like the physical latency floor of the chip at around twenty microseconds.
As the first anywhere to have the MI355X fully deployed in production, running Matilda, inference is a huge focus for @MaincodeAU. In fact inference is the part of an AI business that actually meets customers, so we wanted to understand this hardware as deeply as we could. We took the runtime out and drove the GPU through the Linux kernel driver directly, the same interface ROCm itself is built on, to see how close to the silicon we could get.
RCCL is genuinely great and has years of careful work behind it, and it also has to be good at everything a runtime is ever asked to do. A layer that only has to do one thing really well can set all of that aside and cut its overhead to almost nothing. The win isn't a clever trick, just the absence of overhead.
And you don't have to take our word for it. The whole thing ships as a single container image with the kernels compiled in, and three commands reproduce the numbers on any MI355X box.
More in the blog post...

2
2
22
725,966
*maxwell twelftree retweeted

Jun 15
To quit in the biggest fight of your career - is something not everybody can do.
Real Le Layenda 😃
2,043
5,119
84,281
5,028,174

Jun 10
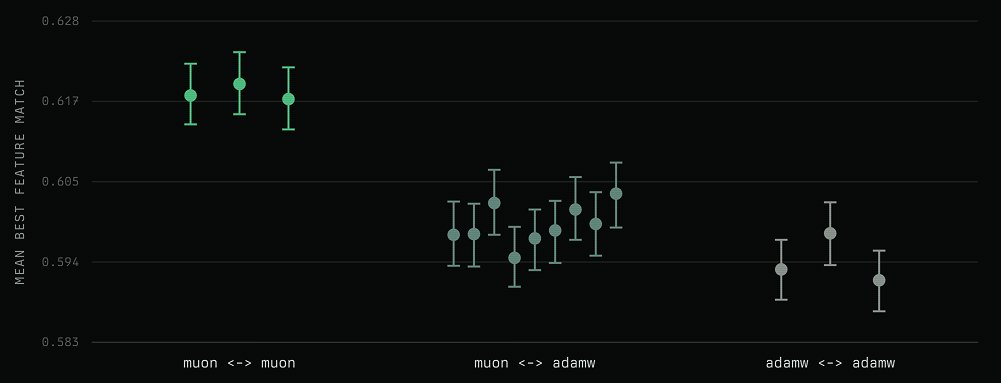
Muon has been a recent obsession of ours, so we dug deeper. It changes the loss curve, but does it change what a model learns?
We trained matched AdamW and Muon GPT-2-class models, held validation loss fixed, and compared their SAE features by firing patterns over the same 1M tokens.
The result: Muon model’s features match an AdamW model’s features about as well as two AdamW seeds match each other. So changing the optimizer perturbs SAE feature identity about as much as changing the random seed. Muon’s advantage is not “different features.” It is “same features, different geometry.”
2
1
117
*maxwell twelftree retweeted
Jun 2
Australia shouldn't have to rent its AI future.
So we built Matilda.
An Australian-built AI assistant, running on our own fully sovereign cluster in Melbourne.
Public access is rolling out now.
14
20
157
2,901,881
*maxwell twelftree retweeted

May 26
Genocide.

Before and after: Tel al-Sultan neighborhood, northwest of the city of Rafah and Rafah refugee camp in Gaza.
2,223
49,401
232,060
3,379,096
May 26
looking for the latest on @ethereum’s EVM → RISC-V migration. who’s actively working on it right now in 2026 on X?
very keen to get involved and contribute.
ethereum:native
41
May 25
super strong benchmarking and i am keen to hear more about the optimisations you guys are working on, if any beyond NVIDIA based hardware; however this reads much more as an inference-engine rather than a coding-agent benchmark.
coding-agent infra is really about the full loop: long-context cache reuse, tool-call churn, multi-turn degradation, quality under speculative decoding, and queue behavior at saturation.
endpoint speed matters, but imo agent throughput matters more - would love to see more here @vipulved on agentic based workloads.
May 24

Yes, the new attention kernels are actually designed for high batch performance and AA doesn't quite capture that impact with single request benchmarks. More here:
together.ai/blog/coding-agen…
139
*maxwell twelftree retweeted

May 25
Australian activists from the Gaza-bound aid flotilla have arrived back in Sydney, reuniting with loved ones as they describe beatings, sexual assault and torture at the hands of Israeli forces who intercepted their boats in international waters.
89
437
767
22,090
May 25
We just published our inference benchmark report from MC-2, our bare-metal @AMD MI355X cluster designed, built and deployed using state of the art software in Melbourne by @maincodehq.
The goal was to test whether high-performance inference for open-weight models can run on Australian infrastructure, without assuming everything has to sit inside US hyperscalers or offshore API providers.
We benchmarked Qwen3.6 35B A3B FP8 and Kimi K2.6, using vLLM across, short-context throughput, long-context workloads, high-concurrency serving and real streamed inference patterns.
The headline results:
- Qwen3.6, 35B A3B FP8: 9,526 output tokens/sec
- Kimi K2.6, 1T total A32B: 1,309.88 output tokens/sec
This is the foundation we are building at Maincode: high-performance, on-premises AI infrastructure for production inference workloads, and the infrastructure layer behind products like Matilda.
Full benchmark report in the comments.
Note: for my MLE friends, the point here is not just peak numbers. It is validating that enterprise-grade inference can be built, deployed and served here in Australia, by a company building real AI products, clusters and workflows. And no, we didn't optimise the models for inference. Though Eagle3-Spec-Decoding on K2.6 is nice :)
3
1
11
149,664
*maxwell twelftree retweeted
May 20
$LPK $LPKFF 🔥 LPKF CEO bought the dip at €21! Insider buys are bulllllllish! This company has had a TON of insider buys with no sales. Obviously they see a very high market cap coming!
eqs-news.com/news/directors-…

May 15
$LPK $LPKFF Part One of the Re-Rate is Complete. Part Two Takes Us to €1B Market Cap 🚀
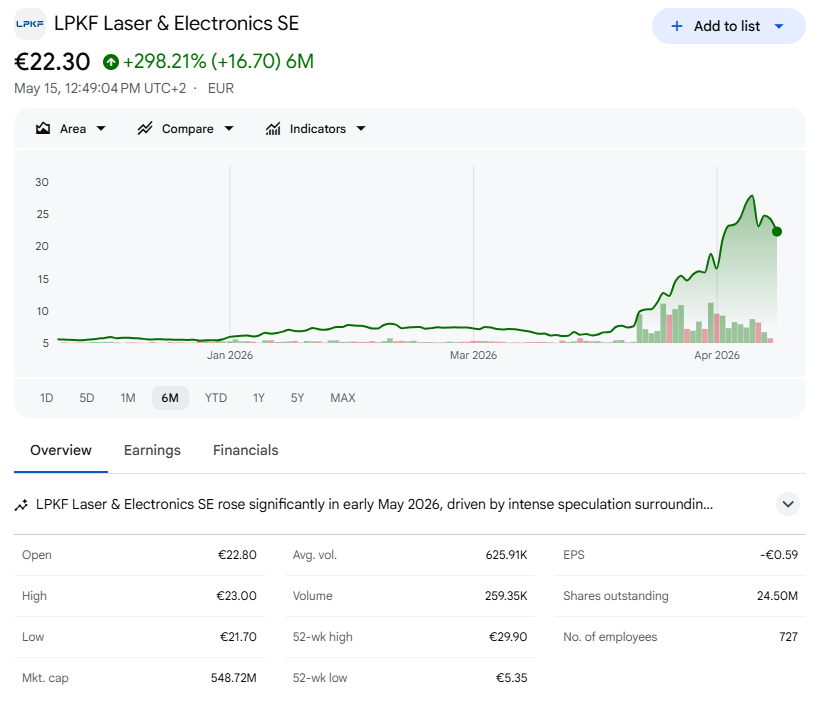
I accumulated LPKF Laser & Electronics (LPK) at a sub-€200M cap because the market was sleeping on the company's essential LIDE technology for AI chip packaging. The thesis was simple and I laid it out at length: LPKF owns the only commercially viable, high-volume manufacturing (HVM) ready process for Through-Glass Via (TGV) formation in advanced semiconductor packaging. That process is Laser-Induced Deep Etching (LIDE), and every serious player in the glass substrate race is either qualifying on LPKF equipment or has already placed pilot orders. CEO estimates 70%-80% market share.
Today the stock trades around €22-23 on a market cap near €550M. Part one of the re-rate is done.
I want to be explicit about what that means. The first leg, roughly €5 to €25, was the market waking up to the existence of the LIDE moat. The next leg is anchored to a specific catalyst path that converts speculation into book-and-bill, and that leg takes us to a €1B cap.
The path is order confirmation from named tier-one customers. Management has guided to first LIDE production orders in Q2 2026 (June-July). The investor forum on June 18 in Hanover is where CEO Klaus Fiedler presents the long-term strategy, and that is the venue where I expect customer color and a hard ramp timeline. Q2 earnings on July 23 is the print where the order intake shows up in the numbers. AGM on June 4 brings in Dr. Arne Schneider, currently CEO of Elmos Semiconductor (a publicly traded German automotive semiconductor company), to the supervisory board. Schneider is a former CFO with five years running a listed German semi SE. The appointment signals two things: governance is being recomposed for the semiconductor pivot, and the board is adding financial discipline at the exact moment LIDE moves from R&D spend to capex and working capital scaling. This is the kind of board change you make when you are about to ramp.
On the customer identity question, the public evidence chain is already strong. Samsung Electro-Mechanics' Sejong pilot line was reported by TechSpot in May 2024 as having finalized its supplier list with Philoptics, Chemtronics, Joongwoo M-Tech, and Germany's LPKF, with the same confirmation appearing in Tom's Hardware citing ETNews and later in Digitimes January 2025 confirming Samsung Electro-Mechanics is working with Chemtronics and LPKF on various manufacturing processes. That is four independent trade outlets sourcing back to Korean primary reporting. On the $INTC Intel side, CEO Fiedler has publicly stated LPKF has been in exclusive paid co-packaged optics (CPO) development with a major US semiconductor partner for over two years. A granted 2023 Intel patent describes LIDE-formed TGVs in an Intel CPO architecture. Korean trade press named LPKF and SCHOTT as Intel's glass substrate collaborators going back to 2024. The UTI to LG Innotek route is publicly confirmed: LG Innotek formally announced a partnership with precision glass-processing specialist UTI in January 2026 to develop glass substrates for advanced semiconductor packaging, with UTI expected to handle the TGV process. LPKF is the plausible equipment vendor on that line given the absence of credible alternatives at HVM scale. Absolics in Georgia and DNP in Japan both run pilot lines that need this exact process. The $ONTO Onto Innovation PACE consortium membership puts LPKF tools in qualification at every member's program.
What we are seeing this week is healthy. The stock has done what it needed to do in a short window, and a pause here lets the technical setup reset before the catalyst cluster lands in June and July. Long-term holders are sitting through it because the catalyst calendar is right in front of us. Every dip into the AGM and the investor forum is a gift.
Catalyst stack into summer:
- June 4: AGM Hanover, Dr. Arne Schneider supervisory board confirmation
- June 18: Investor Forum, long-term strategy detail from Fiedler, expected customer color
- Q2 2026: First LIDE production orders per management guidance
- July 23: Q2 earnings, order intake shows up in the numbers
When the orders land and they are attached to a named tier-one customer, the cap moves through €1B with conviction. Management has been telegraphing this catalyst for two years and the evidence chain backs them up. I take them at their word and so does the supply chain.
This technology is essential for next-generation AI chips. Organic substrates are at their physical limit. Glass is the answer for 1.6T-class signaling, high-bandwidth memory (HBM) integration, and co-packaged optics. LPKF holds the patent stack and the qualification lead on the only HVM-ready process that produces defect-free TGVs at panel scale. At a €550M cap, we have merely begun.
I am a long-term holder. I am glad the momentum took a breather. Healthy.
Incredibly bullish LPK into summer.
7
11
154
82,958
May 18
tok/s will be super slow, memory bandwidth is a huge bottleneck on this as it is on laptops like the G1a Ultra, hosting the Ryzen AI Max PRO 395 128GB unified LPDDR5X
May 18

Lisa Su (CEO of AMD) unveils the world's smallest AI development PC, capable of running 200B parameter models locally.
84
May 18
bullish on $NOW with subscription revenue growing nicely and a fair buy in price but Bill McDermott gives me those 2021 ethereum:native based rug pull vibes...
216
May 17
$LPK is a worthy buy with the recent pull back & inevitable backlog ramp. Glass can become a major substrate/interposer layer for AI packages.
The moat is serious, with patent/IP toll booth switching cost... it's a waiting game for the volume inflection, exactly like how we saw other chokepoint plays mature in photonics and optics.
May 10

“Leading” Glass Substrate players that were name dropped if you’re curious:
• $LPK — TGV Equipment
• $GLW — Glass Materials
• $ASGLY (5201 T)— Glass Materials
• $NIDGY (5214 T) — Glass Materials
• $LRCX — Etching Systems
• $DSCSY (6146 T)— Dicing Equipment
• $SMHSF — Bonding Systems
• $ONTO — Inspection Tools
• $KLAC — Inspection Tools
Fun to see the stuff I’ve called out early in the year like LPK at ~$150m MC get mentioned as a critical player by Trendforce and others.

1
4
1,190
RT @Ex0byt: There’s no ‘gap’, and no one’s 8 months behind. We’ve been trolled on every closed U.S drop and flexed on with open weights. ht…
54
very close to getting DeepSeek-V4-Flash running on AMD MI325X/gfx942 in vLLM!
build load TP=8 generation work, and narrowed the remaining issue to DeepSeek V4 MXFP4 MoE integration/layout on ROCm. gfx942 needs a non-native-FP4 path; PTX/Triton Quark paths both have sharp edges.
@AnushElangovan @AIatAMD would love pointers from ROCm/vLLM folks on the intended MXFP4 expert layout/fallback path for CDNA3. happy to share patches traces :)
2
104
*maxwell twelftree retweeted

Apr 7
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
anthropic.com/glasswing
1,984
6,642
44,005
31,433,458
*maxwell twelftree retweeted

Mar 28
someone at ANTHROPIC just showed CLAUDE finding ZERO DAY vulnerabilities in a live conference demo
claude has found zero day in Ghost, 50,000 stars on github, never had a critical security vulnerability in its entire, history...
it found the blind SQL injection in 90 minutes, stole the admin api key, then did the exact, same thing to the linux kernel
297
1,316
11,650
1,900,977