
bulked
Joined March 2025
- Tweets 2,742
- Following 345
- Followers 801
- Likes 5,061
554 Photos and videos












𝗣𝗿𝗶𝘀𝗺𝗮𝗫 𝗦𝘁𝗮𝗻𝗱𝗮𝗿𝗱𝘀 𝗳𝗼𝗿 𝗗𝗮𝘁𝗮: 𝗪𝗵𝘆 𝗠𝗼𝘀𝘁 𝗥𝗼𝗯𝗼𝘁𝗶𝗰𝘀 𝗗𝗮𝘁𝗮 𝗜𝘀𝗻'𝘁 𝗚𝗼𝗼𝗱 𝗘𝗻𝗼𝘂𝗴𝗵
everyone training robots is hitting the same wall: theres plenty of data, but most of it is junk.
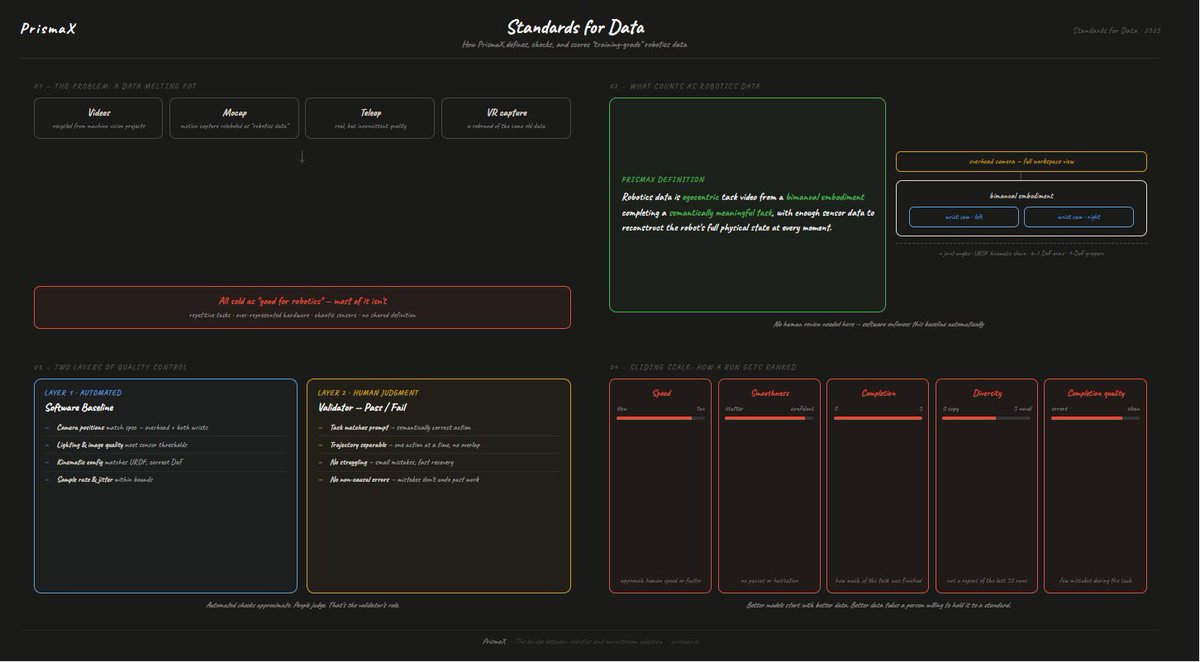
@PrismaXai looked at the open-source robotics datasets flooding platforms like HuggingFace and found a mess videos, motion capture,and teleoperation footage all labeled "robotics data" even when half of it is recycled from old machine vision or VR projects. Camera angles are inconsistent, lighting is bad, tasks repeat endlessly and quality varies wildly between providers.
so prismax wrote down what "good" actually means and built a system to enforce it.
🠴🠴🠴🠴🠴🠴🠴🠴🠴🠴🠴🠴🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶
⯎ first, a clear definition. robotics data has to be egocentric (cameras mounted on the robot, not the room), from a two-armed robot doing a meaningful task, with enough sensor data to reconstruct exactly what the robot's body was doing at every moment joint angles, wrist cameras, overhead view, the works.
⯎ then, two layers of checking. software handles the easy stuff automatically: is the camera positioned right, is the lighting clean, does the kinematic setup match the spec. no human needed for that.
⯎ the harder part, judgment, goes to human validators. did the robot actually do the task in the prompt? did it fumble and recover smoothly, or struggle repeatedly? did a mistake undo previous work? Was the motion confident and fast or hesitant? was it just a copy of the last fifty runs?
🠴🠴🠴🠴🠴🠴🠴🠴🠴🠴🠴🠴🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶🠶
this is the same idea behind why today's best language models are good: a layer of human judgment scoring whats useful and what isnt.
prismax is applying that same layer to robots.
physical AI isnt short on hardware or compute. Its short on data thats actually worth learning from and that takes people, holding every run to a standard.

1
2
170

Jun 13
𝗴𝗿𝗮𝗱𝗶𝗲𝗻𝘁 𝗮𝘁 𝘁𝗵𝗲 𝘅𝟒𝟎𝟐 𝘀𝗼𝗹𝗮𝗻𝗮 𝗵𝗮𝗰𝗸𝗮𝘁𝗵𝗼𝗻: 𝗮𝗶 𝗮𝗴𝗲𝗻𝘁𝘀 𝘁𝗵𝗮𝘁 𝗽𝗮𝘆 𝘁𝗵𝗲𝗺𝘀𝗲𝗹𝘃𝗲𝘀
the x402 solana hackathon took place from october 28 to november 11, 2025, with a $50,000 prize pool across five tracks focused on web-native payments for ai.
@Gradient_HQ was the official supporter of the hackathon
𝘄𝗵𝗮𝘁 𝗶𝘀 𝘅𝟒𝟎𝟐?
x402 is an open protocol for web-native payments.
the 402 code means "payment required" and has long existed in the http specification, but only became practical with the advent of blockchain networks.
the ai agent decides to pay for the api or data itself, without human intervention.
𝘁𝗵𝗲 𝗵𝗮𝗰𝗸𝗮𝘁𝗵𝗼𝗻'𝘀 𝟓 𝘁𝗿𝗮𝗰𝗸𝘀
trustless agents, x402 api integration, mcp servers, x402 development tools, x402 agent applications, each track offered up to $10,000 in prizes.
𝘄𝗵𝗮𝘁 𝘁𝗵𝗲 𝗽𝗮𝗿𝘁𝗶𝗰𝗶𝗽𝗮𝗻𝘁𝘀 𝗯𝘂𝗶𝗹𝘁
the hackathon attracted developers from all over the world and received over 400 projects.
among the finalists were ai agents with autonomous payments, model trading platforms and an iot economy.
one of the projects was an esp32 microcontroller with its own wallet that independently processes payments.
𝘄𝗵𝗮𝘁 𝗱𝗼𝗲𝘀 𝗴𝗿𝗮𝗱𝗶𝗲𝗻𝘁 𝗵𝗮𝘃𝗲 𝘁𝗼 𝗱𝗼 𝘄𝗶𝘁𝗵 𝗶𝘁?
gradient is building a decentralized ai infrastructure on solana. x402 is the next logical layer:
if parallax gives ai agents computing power, x402 gives them a payment rail.
the agent runs on parallax → pays for external apis through x402 → everything happens without human intervention.
2 Nov 2025

x402 x @solana x Parallax.
Blockchain native sovereign agents gonna take over.
3
10
142
Jun 11
𝘀𝗰𝗮𝗹𝗲 𝗮𝗶 𝘃𝘀 𝗽𝗿𝗶𝘀𝗺𝗮𝘅: 𝘁𝘄𝗼 𝘃𝗲𝗿𝘆 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝘁 𝗯𝗲𝘁𝘀 𝗼𝗻 𝗿𝗼𝗯𝗼𝘁𝗶𝗰𝘀 𝗱𝗮𝘁𝗮
scale aiI is worth $25 billion. PrismaX just raised $11 million. On paper, i's no contest, but they are solving the same problem in completely opposite ways and that difference matters
robots need enormous amounts of training data to work reliably. someone has to collect it
@scale_AI answer: hire contractors. A centralized team oversees hundreds of workers who capture and label data on demand
this works well for text, images and standard video. major clients include openai, nvidia, and toyota research institute
in september 2025, scale even launched a dedicated robotics data program, contractors recording pov demonstrations of physical tasks
@PrismaXai answer: make data collection a protocol. Instead of paying contractors, prismax pays operators in pix tokens to remotely control real robots.
quality is scored automatically by an on-chain system called Proof-of-View. the people who create the data share in the revenue it generates
the deeper difference is in the data itself. scale ai handles static labeling, you look at an image and tag whats in it
robotics requires something harder: continuous sequences of physical actions, sensor streams, depth perception, real-time feedback. you cant capture that by outsourcing to anonymous workers on a platform
prismax embeds the operator directly inside the robot's control loop. the data isnt collected about the robot, its collected through it
scale ai owns the data. prismaX distributes it.
1
13
246
Jun 10
𝗳𝗿𝗼𝗺 𝘀𝗲𝗻𝘁𝗿𝘆 𝗻𝗼𝗱𝗲𝘀 𝘁𝗼 𝗲𝗱𝗴𝗲 𝗵𝗼𝘀𝘁𝘀: 𝘁𝗵𝗲 𝗲𝘃𝗼𝗹𝘂𝘁𝗶𝗼𝗻 𝗼𝗳 𝗻𝗲𝘁𝘄𝗼𝗿𝗸 𝗽𝗮𝗿𝘁𝗶𝗰𝗶𝗽𝗮𝘁𝗶𝗼𝗻
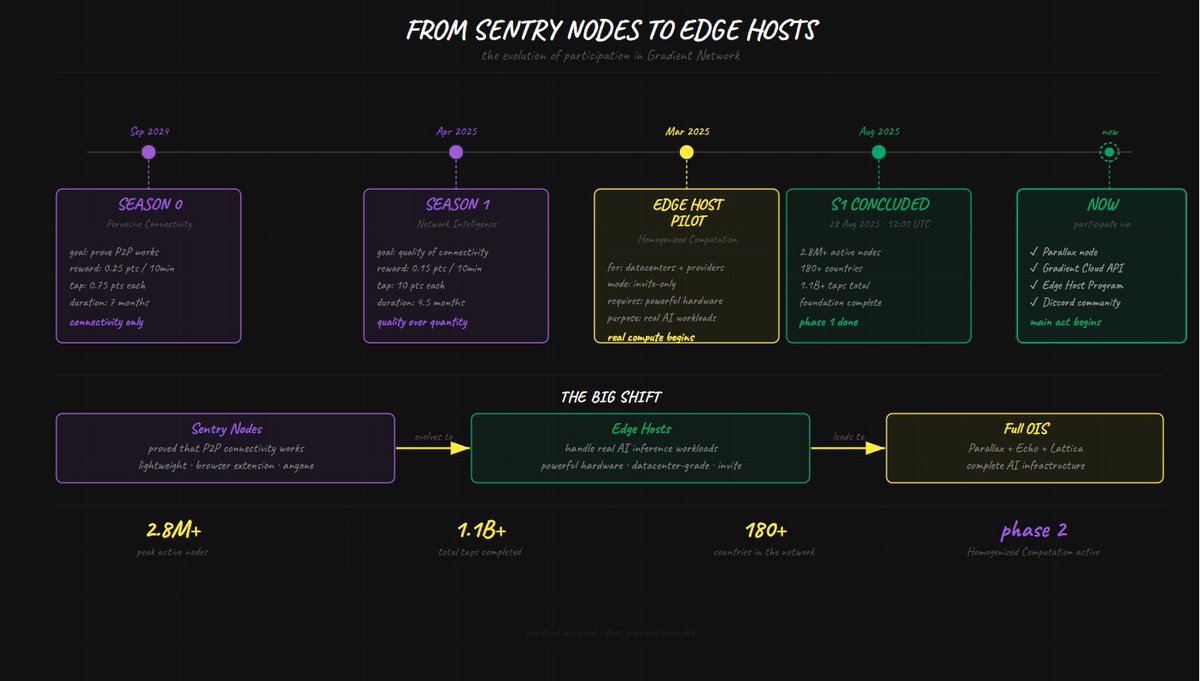
@Gradient_HQ has evolved from simple connectivity checks to real ai computing
𝘀𝗲𝗮𝘀𝗼𝗻 𝟎: 𝗽𝗿𝗼𝗼𝗳 𝗼𝗳 𝗰𝗼𝗻𝗻𝗲𝗰𝘁𝗶𝘃𝗶𝘁𝘆
was started on september 12, 2024 as the first step toward pervasive connectivity.
⮚ sentry node received 0.25 points for every 10 minutes of uptime
⮚ taps are ephemeral p2p connections between two random nodes used to verify connectivity
both nodes received 0.75 points for a successful tap. coinlaunch
the goal: to prove that the global p2p network actually works.
𝘀𝗲𝗮𝘀𝗼𝗻 𝟏: 𝗶𝗺𝗽𝗿𝗼𝘃𝗲𝗱 𝗺𝗲𝗰𝗵𝗮𝗻𝗶𝗰𝘀
was started on april 15, 2025 with an updated reward structure.
⮚ successful tap now rewards 10 points
⮚ payout: 0.15 points for every 10 minutes
season 1 concluded on august 28, 2025. sentry nodes no longer accumulate uptime and taps.
result of two seasons: 2.8 million active sentry nodes in 180 countries. 1.1 billion taps.
𝗲𝗱𝗴𝗲 𝗵𝗼𝘀𝘁 𝗽𝗿𝗼𝗴𝗿𝗮𝗺: 𝘁𝗵𝗲 𝗻𝗲𝘅𝘁 𝗹𝗲𝘃𝗲𝗹
in march 2025, gradient launched the edge host pilot program, the first step in homogenized computation.
⮚ the program invites data centers and individual providers to help shape the next stage of decentralized computing
⮚ the program is invite-only the team itself selects suitable participants
the difference is fundamental: sentry nodes tested connectivity.
edge hosts process real ai workloads via parallax.
𝘄𝗵𝗮𝘁𝘀 𝗻𝗲𝘅𝘁
for the community, the end of season 1 is not the end of participation, but the beginning of the main event.
the team is preparing a product that will unite everything built into a single seamless experience, giving every participant direct access to the full power of distributed intelligence.
3
20
1,200
Jun 7
𝗽𝗿𝗶𝘀𝗺𝗮𝗫 𝗮𝗻𝗱 𝘃𝗶𝗿𝘁𝘂𝗮𝗹𝘀 𝗽𝗿𝗼𝘁𝗼𝗰𝗼𝗹: 𝗻𝗼𝘁 𝗰𝗼𝗺𝗽𝗲𝘁𝗶𝘁𝗼𝗿𝘀 𝗮 𝘀𝘁𝗮𝗰𝗸
most people assume two crypto-robotics projects doing similar things must compete
@PrismaXai and @virtuals_io are the opposite: they need each other
virtuals protocol builds autonomous ai agents.
these agents can pick tasks, pay for data and control real robots.
by november 2025, virtuals agents had completed 500 000 real-world physical tasks and processed $600M in payments through their x402 protocol.
they also invested in prismax's $11M seed round
prismax is what happens before full autonomy arrives
Its the coordination layer: connecting human operators, robot owners and companies that need training data
operators remotely control robots, complete real tasks and earn $PIX tokens based on performance quality.
here's the key insight: autonomy isnt a switch you flip
Its a spectrum you climb. to get robots to work reliably on their own, you first need massive amounts of high-quality training data, collected by humans controlling those same robots
when a virtuals agent initiates a task, prismax provides the human operator and the infrastructure
――――――――――――――――――――――――
that session generates verified training data, better data trains better models
better models make robots more autonomous.
more autonomous robots mean agents need less human help over time
bitrobot verifies the work at the base, prismax coordinates operators in the middle, virtuals runs autonomous agents on top.
3
10
243
Jun 6
previously, to enter a trade you had to:
⤫ open a chart
⤫ find news
⤫ estimate the position size
⤫ go to the exchange and place an order
now you just type whatever you want in claude or chatgpt, it automatically finds an idea, calculates the size and offers a trade
@liquidtrading made this possible through co-invest
crypto, stocks, gold and forex in one chat.
3
11
254
Jun 5
𝗽𝗮𝗿𝗮𝗹𝗹𝗮𝘅 𝗳𝗼𝗿 𝗱𝗲𝘃𝗲𝗹𝗼𝗽𝗲𝗿𝘀: 𝘄𝗵𝗮𝘁 𝘁𝗼 𝗯𝘂𝗶𝗹𝗱 𝗿𝗶𝗴𝗵𝘁 𝗻𝗼𝘄
parallax opens up a wide range of opportunities for hosting and running your own ai applications and agents: coding copilots, personal assistants, vision and speech pipelines, and multi-agent simulations.
all on your own hardware, no cloud, no api keys.
𝘄𝗵𝗮𝘁𝘀 𝗮𝘃𝗮𝗶𝗹𝗮𝗯𝗹𝗲 𝗿𝗶𝗴𝗵𝘁 𝗻𝗼𝘄
parallax supports cross-platform deployment on mac, windows and linux.
built-in network-aware sharding and dynamic task routing intelligent load scheduling with seamless switching between single-machine, multi-device and wide-area cluster modes.
moe models from 0.6b to trillion-class on gpus and apple silicon are supported.
𝗰𝗼𝗱𝗶𝗻𝗴 𝗰𝗼𝗽𝗶𝗹𝗼𝘁
developers can deploy locally and build applications like coding assistants while keeping all sensitive data and control rights local.
your code doesnt go to github copilot or cursor servers. the model works for you.
𝗽𝗲𝗿𝘀𝗼𝗻𝗮𝗹 𝗮𝗴𝗲𝗻𝘁
parallax is designed for next-generation ai applications that remain private, verifiable and open.
the system stores data and memory locally, uses open source tools and tracks every step of the computation results can be reproduced and verified.
openclaw integration is already available, an agent in telegram or discord that runs tasks on your machine.
𝗺𝘂𝗹𝘁𝗶-𝗮𝗴𝗲𝗻𝘁 𝘀𝗶𝗺𝘂𝗹𝗮𝘁𝗶𝗼𝗻
@Gradient_HQ launched a hackathon, "build your own ai lab", to solve problems for individuals that require privacy and low cost, help researchers accelerate their work and build tools for businesses.
multi-agent simulations, research tooling and business automation are all being built by the community using parallax.
7
1
24
399
Jun 4
>>>>> 𝗗𝗲𝗣𝗔𝗜: 𝗪𝗵𝘆 𝟐𝟎𝟐𝟓 𝗜𝘀 𝘁𝗵𝗲 𝗬𝗲𝗮𝗿 𝗼𝗳 𝗣𝗵𝘆𝘀𝗶𝗰𝗮𝗹 𝗔𝗜 <<<<<
while everyone's talking about chatgpt and text-based models, a new movement has emerged in the real world: depai. It stands for decentralized physical ai
robots shouldnt be owned by a few corporations. The data that trains them shouldnt be hoarded by a single company. depai is an attempt to build an open infrastructure for robots on the blockchain.
In 2025, a full-fledged stack of three projects with different roles emerged.
bitrobot is the lower tier. they are building the core infrastructure on solana, where every robot action can be verified. the SeeSaw platform allows users to upload ordinary videos of everyday tasks, which become training data for robots.
the project has raised $6M and Virtuals Protocol is among its investors.
@PrismaXai is the middle tier. this is a coordination network: it connects human operators, robot owners and companies that need data.
Operators remotely control robots, perform real tasks and receive tokens for high-quality work.
$11M from a16z, a live platform supporting eight types of robots.
virtuals protocol is the top layer. Autonomous AI agents that choose tasks themselves, pay for data and manage robots without human intervention. By the end of 2025, 500,000 completed tasks are planned.
𝘄𝗵𝘆 𝗻𝗼𝘄
Robots have become cheaper, models have matured and Web3 has learned to process micropayments quickly and cheaply. Everything has come together.
𝗗𝗲𝗣𝗔𝗜 𝗶𝘀 𝗻𝗼𝘁 𝗵𝘆𝗽𝗲. 𝗜𝘁𝘀 𝘁𝗵𝗲 𝗶𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝗯𝗲𝗶𝗻𝗴 𝗹𝗮𝗶𝗱 𝗼𝘂𝘁 𝗿𝗶𝗴𝗵𝘁 𝗻𝗼𝘄.
1
9
226
May 28
congrats but im top 1(from the end)
guys from top 10 lost their luck for the next 5 years gg
15k will get 1st dude, thats so fuckin huge
gbulk
May 28

The BULK Paper Trading Comp is COMPLETE
Congratulations to our Top 50, and a huge THANK YOU to everyone that participated and provided feedback
View the finalized leaderboard: early.bulk.trade/leaderboard

21
296
May 28
ai agents are breaking the old cost logic
the more automation, the more expensive the model selection error
you dont need gpt-5 for every sneeze.
sometimes a small model does the same job faster cheaper and without unnecessary tokens
the winner isnt the one with the strongest model
nut the one with the smartest routing.

2
18
372
May 26
>>>>> 𝗟𝗶𝘃𝗲 𝗖𝗼𝗻𝘁𝗿𝗼𝗹: 𝗣𝗿𝗶𝘀𝗺𝗮𝗫 𝗔𝗹𝗿𝗲𝗮𝗱𝘆 𝗟𝗮𝘂𝗻𝗰𝗵𝗲𝘀 𝗖𝗼𝗻𝘁𝗿𝗼𝗹 𝗼𝗳 𝗥𝗲𝗮𝗹 𝗥𝗼𝗯𝗼𝘁𝘀 <<<<<
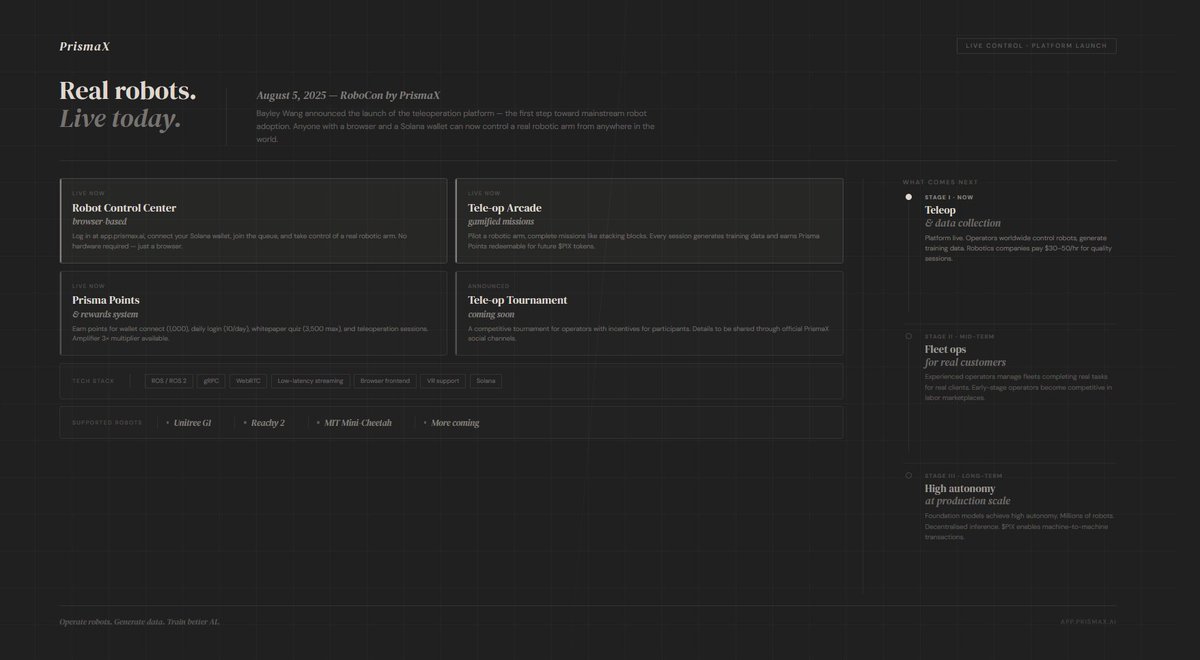
On August 5, 2025, Bayley Wang announced the launch of a teleoperation platform at the first RoboCon by @PrismaXai
"The launch of our platform is the first step toward mass adoption of robots" he said
"Its a proof of concept for a future where humans and robots work hand in hand"
𝗪𝗵𝗮𝘁𝘀 𝗪𝗼𝗿𝗸𝗶𝗻𝗴 𝗥𝗶𝗴𝗵𝘁 𝗡𝗼𝘄
The platform allows users to log in and control a robotic arm from anywhere in the world.
Supported robots include the Unitree G1, Reachy 2 and MIT Mini-Cheetah.
Access is via a browser, no special hardware is required.
The platform uses ROS/ROS 2 for robot control, gRPC for efficient communication and WebRTC for low-latency streaming.
𝗪𝗵𝗮𝘁 𝗖𝗵𝗮𝗻𝗴𝗲𝘀 𝗧𝗵𝗶𝘀
Before the platform's launch, teleoperation was the domain of large corporations with their own teams and infrastructure.
Now, anyone with a computer and a Solana wallet can control a real robot and earn money doing it.
The short-term focus is teleoperation and collecting visual data for model training.
In the medium term, operators will manage fleets of robots to perform real tasks for real customers.
In the long term, robots will achieve high autonomy based on the fundamental models developed in the first two stages.
The network will transition to providing production services for millions of machines.
"𝘛𝘩𝘦 𝘭𝘰𝘯𝘨-𝘵𝘦𝘳𝘮 𝘷𝘢𝘭𝘶𝘦 𝘰𝘧 𝘵𝘩𝘦 𝘱𝘭𝘢𝘵𝘧𝘰𝘳𝘮 𝘪𝘴 𝘵𝘰 𝘣𝘦𝘤𝘰𝘮𝘦 𝘵𝘩𝘦 𝘧𝘰𝘶𝘯𝘥𝘢𝘵𝘪𝘰𝘯 𝘰𝘧 𝘢 𝘭𝘢𝘳𝘨𝘦-𝘴𝘤𝘢𝘭𝘦 𝘧𝘶𝘵𝘶𝘳𝘦 𝘭𝘢𝘣𝘰𝘳 𝘮𝘢𝘳𝘬𝘦𝘵" says Bayley Wang.
2
11
358


May 23
>>>>> 𝗪𝗵𝘆 𝗣𝗿𝗶𝘀𝗺𝗮𝗫 𝗶𝘀 𝘁𝗵𝗲 𝗶𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝗼𝗳 𝗮 𝗻𝗲𝘄 𝗲𝗿𝗮 <<<<<
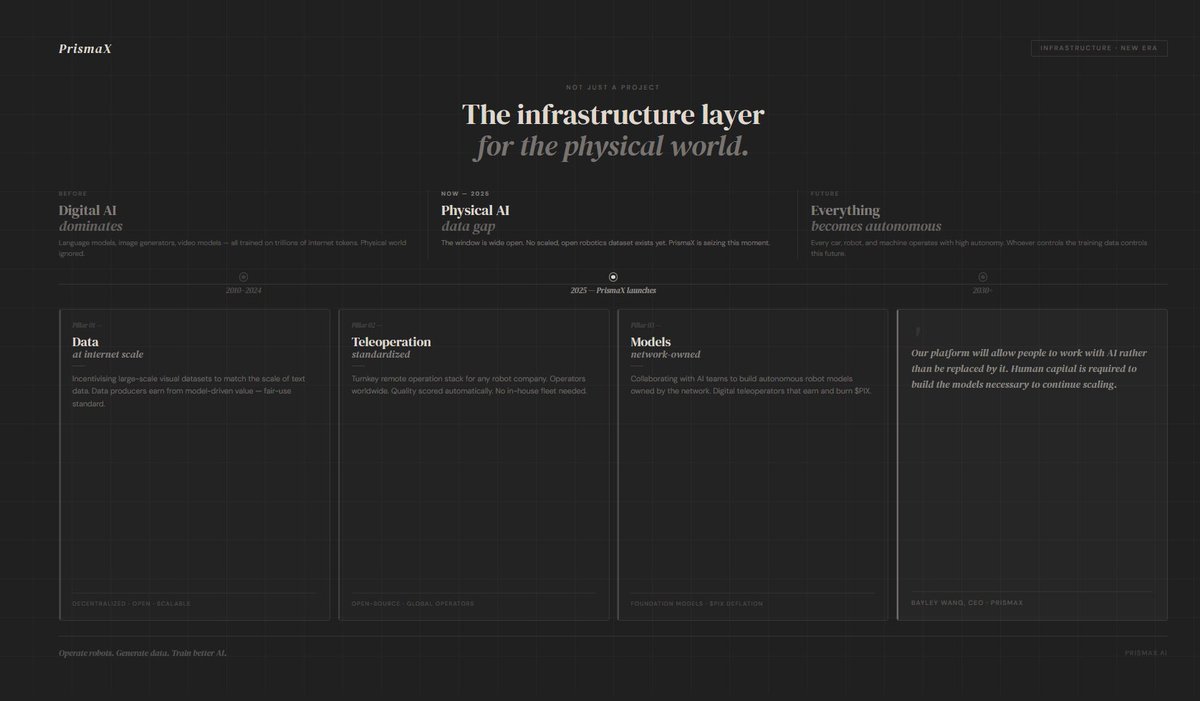
We are used to thinking of AI as something digital.
Text, images, videos it all lives on a screen, but the next wave is different.
Everything that moves will eventually become autonomous. Every car today is already a robot. We're moving toward general-purpose robots.
And this wave has a fundamental problem: there's almost no data for it.
𝗧𝗵𝗲 𝘄𝗶𝗻𝗱𝗼𝘄 𝗶𝘀 𝘀𝘁𝗶𝗹𝗹 𝗼𝗽𝗲𝗻
For text-based AI, it's almost too late to fix the issues of fairness and data availability, but for robotics, where a large-scale open dataset doesnt yet exist, the window is wide open. @PrismaXai is pioneering this position.
𝗪𝗵𝗮𝘁 𝗣𝗿𝗶𝘀𝗺𝗮𝗫 𝗶𝘀 𝗯𝘂𝗶𝗹𝗱𝗶𝗻𝗴
PrismaX is introducing a fair use standard, where data producers earn based on the value their data brings to models.
Three pillars:
𝗱𝗮𝘁𝗮 – stimulating large-scale visual datasets, 𝘁𝗲𝗹𝗲𝗼𝗽𝗲𝗿𝗮𝘁𝗶𝗼𝗻 – standardizing remote robot control, 𝗺𝗼𝗱𝗲𝗹𝘀 – creating autonomous robotic models in collaboration with AI teams.
𝗛𝘂𝗺𝗮𝗻 𝗮𝘁 𝘁𝗵𝗲 𝗖𝗲𝗻𝘁𝗲𝗿 𝗼𝗳 𝘁𝗵𝗲 𝗦𝘆𝘀𝘁𝗲𝗺
"Our platform will enable humans to work with AI, not be replaced by it. As the industry evolves, it's important to remember: human capital is essential to building models that can continue to scale" – Bayley Wang, CEO of PrismaX.
Soona Amhaz of Volt Capital noted:
"PrismaX addresses a fundamental gap in physical AI: access to high-quality visual datasets that are both accessible and scalable. As autonomy moves into the real world, its clear that the current infrastructure cant keep up"
𝗪𝗵𝘆 𝗜𝘁 𝗠𝗮𝘁𝘁𝗲𝗿𝘀 𝗡𝗼𝘄
Whoever controls the data of the physical world controls the future of autonomous systems.
PrismaX is building the Common Crawl for the real world and its doing so openly, with fair value distribution among all participants.
This isnt just a project. Its the infrastructure of an era that has already begun.
2
14
252
Marchi retweeted

May 22
There will not be a faster DEX in the world
There will not be a faster consensus in the world
There will not be a more efficient liquidation system
No other crypto exchange has SPAN margining
No other exchange gives yield carry back to depositors
No other protocol offers dynamic risk engines
There will be only one exchange that is truly portfolio aware
There will only be one 30% allocation to users
There will only be BULK
155
52
461
108,284
May 20
>>>>> 𝗣𝗿𝗶𝘀𝗺𝗮𝗫 𝗳𝗼𝗿 𝗗𝗲𝘃𝗲𝗹𝗼𝗽𝗲𝗿𝘀: 𝗛𝗼𝘄 𝘁𝗼 𝗕𝘂𝗶𝗹𝗱 𝗼𝗻 𝘁𝗵𝗲 𝗣𝗵𝘆𝘀𝗶𝗰𝗮𝗹 𝗔𝗜 𝗕𝗮𝘀𝗲 𝗟𝗮𝘆𝗲𝗿 <<<<<
@PrismaXai positions itself not just as a platform, but as an open protocol, an infrastructure on which other teams can build their products. If you're building robots or AI services for the physical world, PrismaX provides three ready-made tools.
𝗢𝗽𝗲𝗻 𝗧𝗲𝗹𝗲𝗼𝗽𝗲𝗿𝗮𝘁𝗶𝗼𝗻 𝗦𝘁𝗮𝗰𝗸
PrismaX provides ready-made code and an API for integrating robots into the network. The robot-side backend connects to a cross-platform frontend, allowing people around the world to control it via a browser or VR.
Under the hood, the PrismaX blockchain protocol handles operator detection, reputation and payouts. Developers dont need to build everything from scratch, they simply connect to the stack.
𝗣𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗮𝗯𝗹𝗲 𝗗𝗮𝘁𝗮 𝗖𝗼𝗹𝗹𝗲𝗰𝘁𝗶𝗼𝗻 𝗘𝗻𝗴𝗶𝗻𝗲
Robotics companies can interact with the existing dataset via an API: program their own filters and purchase only the data they need or send API requests to collect new data for a specific task.
The Eval Engine functions simultaneously as a programmable real-time filter and as a data query validation engine.
This means that any team that needs data to train physical models can obtain it through a single interface, instead of building their own collection infrastructure.
𝗧𝗵𝗿𝗲𝗲-𝗣𝗮𝗿𝘁𝘆 𝗠𝗮𝗿𝗸𝗲𝘁𝗽𝗹𝗮𝗰𝗲
The programmable marketplace connects robot users, owners and operators. It supports data collection, robot leasing, robots-for-hire and potentially, machine-to-machine coordination and robot-to-robot transactions.
𝗪𝗵𝘆 𝗯𝘂𝗶𝗹𝗱 𝘁𝗵𝗶𝘀 𝗼𝗻 𝗣𝗿𝗶𝘀𝗺𝗮𝗫 𝗶𝗻𝘀𝘁𝗲𝗮𝗱 𝗼𝗳 𝗳𝗿𝗼𝗺 𝘀𝗰𝗿𝗮𝘁𝗰𝗵?
Companies today spend millions collecting even a small fraction of the data they need.
Decentralization allows for significantly more data collection, significantly faster and at a lower cost.
At the same time, PrismaX enables iteration on data at the speed of code, a paradigm shift in model training.
4
23
264
May 18
>>>>> 𝗣𝗿𝗶𝘀𝗺𝗮 𝗣𝗼𝗶𝗻𝘁𝘀: 𝗧𝗵𝗲 𝗣𝗼𝗶𝗻𝘁𝘀 𝗦𝘆𝘀𝘁𝗲𝗺 𝗮𝗻𝗱 𝗛𝗼𝘄 𝘁𝗼 𝗘𝗮𝗿𝗻 𝗧𝗵𝗲𝗺 𝗥𝗶𝗴𝗵𝘁 𝗡𝗼𝘄 <<<<<
@PrismaXai points is prismaX's internal rewards system. points are earned for activity on the platform and will likely be counted toward the future distribution of $PIX tokens. Theres no official confirmation of the airdrop, but the system is already operational and points are being awarded right now.
𝗛𝗼𝘄 𝘁𝗼 𝗚𝗲𝘁 𝗦𝘁𝗮𝗿𝘁𝗲𝗱
Log in to app.prismax and connect your Solana wallet you'll immediately receive 1,000 Prisma Points as a welcome bonus. This is the easiest way to log in.
𝗪𝗮𝘆𝘀 𝘁𝗼 𝗘𝗮𝗿𝗻 𝗣𝗼𝗶𝗻𝘁𝘀
Daily login automatically earns 10 points. You dont need to do anything, just log in to the platform every day.
The whitepaper quiz awards 500 points for each correct answer, plus a 1,000-point bonus for a perfect score.
Five questions, maximum 3,500 points per session.
Amplifier Membership for $99 provides a 3x multiplier on all points, thats 30 points per day instead of 10.
This option is for those who want to accumulate points faster.
Teleoperation with robotic arms also earns points. An Explorer badge is awarded to those who complete a profile and link social accounts.
𝗪𝗵𝘆 𝗶𝘀 𝘁𝗵𝗶𝘀 𝗶𝗺𝗽𝗼𝗿𝘁𝗮𝗻𝘁?
Points are accumulated based on completed tasks and are likely linked to future airdrops. The earlier you start, the more points you'll earn by the TGE.
𝗽𝗮𝗿𝘁𝗶𝗰𝗶𝗽𝗮𝘁𝗶𝗼𝗻 𝗶𝘀 𝗰𝗼𝗺𝗽𝗹𝗲𝘁𝗲𝗹𝘆 𝗳𝗿𝗲𝗲: 𝗮 𝘄𝗮𝗹𝗹𝗲𝘁, 𝗱𝗮𝗶𝗹𝘆 𝗹𝗼𝗴𝗶𝗻, 𝗮𝗻𝗱 𝗾𝘂𝗶𝘇 𝗿𝗲𝗾𝘂𝗶𝗿𝗲 𝗻𝗼 𝗶𝗻𝘃𝗲𝘀𝘁𝗺𝗲𝗻𝘁.
1
12
305
May 16
𝗾𝘄𝗲𝗻𝟑 𝟐𝟑𝟓𝗯 𝗼𝗻 𝗰𝘂𝘀𝘁𝗼𝗺 𝗵𝗮𝗿𝗱𝘄𝗮𝗿𝗲 𝘃𝗶𝗮 𝗽𝗮𝗿𝗮𝗹𝗹𝗮𝘅
usually, running a 235b model = datacenter, several h100s, tens of thousands of dollars. parallax changes this.
𝗾𝘄𝗲𝗻𝟑-𝟐𝟑𝟓𝗯-𝗶𝗻𝘁𝟒 has been officially added to parallax. this means the model can be run distributedly, across multiple custom devices or via the global parallax network.
𝘄𝗵𝘆 𝗾𝘄𝗲𝗻𝟑 𝟐𝟑𝟓𝗯
qwen3-235b-a22b outperforms deepseek-r1 and o1 on arena-hard and both aime math benchmarks. its the current flagship open-source model.
architectural trick: 235b is the total number of parameters, but only 22b are active per token. the moe architecture makes the model faster than its dense counterparts with the same characteristics.
𝗽𝗿𝗼𝗯𝗹𝗲𝗺 𝘄𝗶𝘁𝗵𝗼𝘂𝘁 𝗽𝗮𝗿𝗮𝗹𝗹𝗮𝘅
the qwen3-235b is impossible on any consumer gpu: even in int4, you need ~117gb of vram. two h100s in fp8 give 160gb, still not enough. at least four h100s with int4 or eight with fp8.
𝘪𝘴 𝘶𝘯𝘢𝘤𝘩𝘪𝘦𝘷𝘢𝘣𝘭𝘦 𝘧𝘰𝘳 𝘮𝘰𝘴𝘵.
𝗵𝗼𝘄 𝗽𝗮𝗿𝗮𝗹𝗹𝗮𝘅 𝘀𝗼𝗹𝘃𝗲𝘀 𝘁𝗵𝗶𝘀
parallax shards the model across multiple nodes. instead of one machine with 4 h100s, it uses several regular gpus around the world via latticas p2p. each node maintains its own shard and requests go through parallax swarm.
installation:
| pip install parallax-ai | → select qwen3-235b-int4 → parallax automatically finds nodes and distributes the model.
result
𝗳𝗿𝗼𝗻𝘁𝗶𝗲𝗿 𝗺𝗼𝗱𝗲𝗹 𝗮𝘁 𝗹𝗲𝘃𝗲𝗹 𝗼𝟏. 𝗿𝘂𝗻𝘀 𝗹𝗼𝗰𝗮𝗹𝗹𝘆. 𝗱𝗮𝘁𝗮 𝗶𝘀 𝗻𝗼𝘁 𝘁𝗿𝗮𝗻𝘀𝗳𝗲𝗿𝗿𝗲𝗱 𝗮𝗻𝘆𝘄𝗵𝗲𝗿𝗲. 𝗻𝗼 𝘀𝘂𝗯𝘀𝗰𝗿𝗶𝗽𝘁𝗶𝗼𝗻, 𝗻𝗼 𝗼𝗽𝗲𝗻𝗮𝗶 𝗮𝗽𝗶, 𝗻𝗼 𝗱𝗮𝘁𝗮𝗰𝗲𝗻𝘁𝗲𝗿.
3
16
326
May 13
most referral programs give you a one-time cut
@liquidtrading gives you a share of every trade your referrals ever make
you earn up to 50% of fees from every trade your referrals make
the bigger your network trades → the more you earn
top referrers unlock even better terms over time
alpha groups. trading communities. solo traders.

2
8
292