
Open infrastructure for open intelligence. Lattica · Parallax · Echo
Joined May 2024
- Tweets 491
- Following 73
- Followers 717,730
- Likes 460
154 Photos and videos













Pinned Tweet

Feb 12
They crashed. They fell. They exploded on the pad.
Then they got back up. Faster, wiser, stronger.
Breakthroughs don't come from one perfect run, they come from the freedom to fail 100 times.
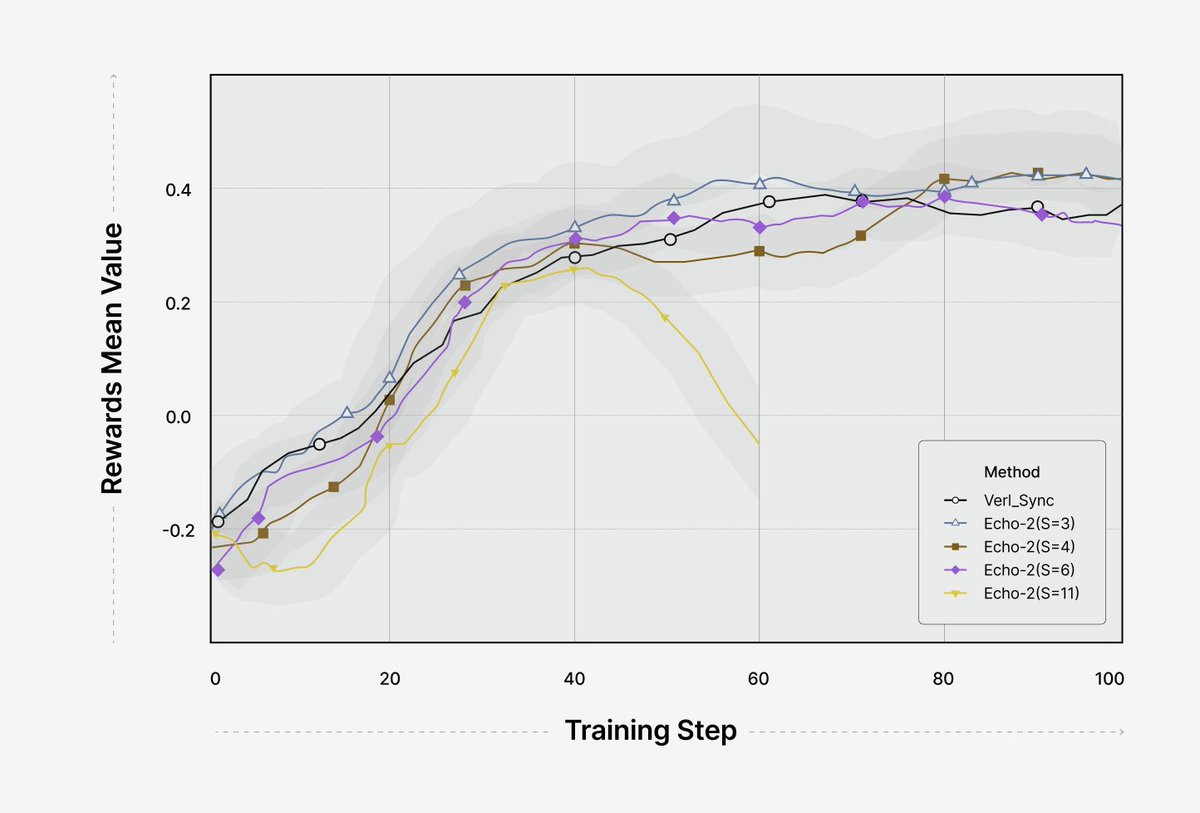
Introducing Echo-2, distributed RL that boosts AI research throughput by 10x.
162
203
745
150,575
Gradient retweeted

Jun 1
nvidia going all in on local ai.
here's our take: it shouldn't depend on which chip you bought.
sparks, macs, the 5090 already on your desk, we cluster across all of it and split your favorite model pipeline-parallel so it runs fully private and local.

NVIDIA RTX Spark: a 1-petaflop superchip, the full CUDA and RTX ecosystem, and Windows-native agents. A new beginning for personal computers.

15
26
106
14,010
May 1
Apr 30

This GPT Image 2 prompt is going insanely viral right now.
“Redraw the attached image in the most clumsy, scribbly, and utterly pathetic way possible. Use a white background, and make it look like it was drawn in MS Paint with a mouse. It should be vaguely similar but also not really, kind of matching but also off in a confusing, awkward way, with that low-quality pixel-by-pixel feel that really emphasizes how ridiculously bad it is. Actually, you know what, whatever, just draw it however you want.”


153
47
530
57,515
Gradient retweeted

Apr 29
We're hiring at Gradient.
Building open-source environment infrastructure for our distributed RL training stack — reproducible, scalable to thousand-GPU runs
Looking for 1–2 RL Environments engineers / tech leads: You've designed verifiers, built sandboxes for agentic RL rollouts, or shipped RL training data pipelines that survived contact with real training.
Domain depth in math, code, agent, tool, or GUI is a plus. PhD not required.
Also hiring research interns: PhD / Masters students with hands-on RLHF / RLVR / GRPO / DPO / agentic RL experience. Open-source footprint matters more than paper count. Most intern roles convert post-grad. No age cap. Founding-team-level equity for the right people.
DMs open.
36
40
558
50,368

Thrilled to see @tryParallax live in production on @Theta_Network.
This is exactly why @Gradient_HQ built Parallax: turning the world’s GPU mesh into a sovereign, distributed token factory.
Congrats on the milestone! 🫡
Apr 20

To make this work, we adapted Parallax, @Gradient_HQ's distributed inference framework, to run across EdgeCloud's global node network. One API endpoint, model split across many machines, no centralized cluster required.
25
65
361
42,812
Gradient retweeted
Apr 22
glad we could help!
with the agentic adoption soaring, privacy and token cost are already the top concerns for both agent and human users.
that's what parallax's built for.
Apr 20
To make this work, we adapted Parallax, @Gradient_HQ's distributed inference framework, to run across EdgeCloud's global node network. One API endpoint, model split across many machines, no centralized cluster required.
17
36
206
25,251
Apr 15
Catch @alex_mirran on DevNTell this Friday.
He’ll break down the infrastructure we're building at Gradient and show you exactly how to get started today.
RSVP below👇

Ready to learn about the Open Intelligence Stack?
🎙️ This week on DevNTell, we'll be joined by @alex_mirran who is Head of BD at @Gradient_HQ, who'll be giving us an overview of the platform and more!
📅 April 17th
📋 RSVP today
luma.com/tdmfpby7
75
65
384
42,747
Apr 8
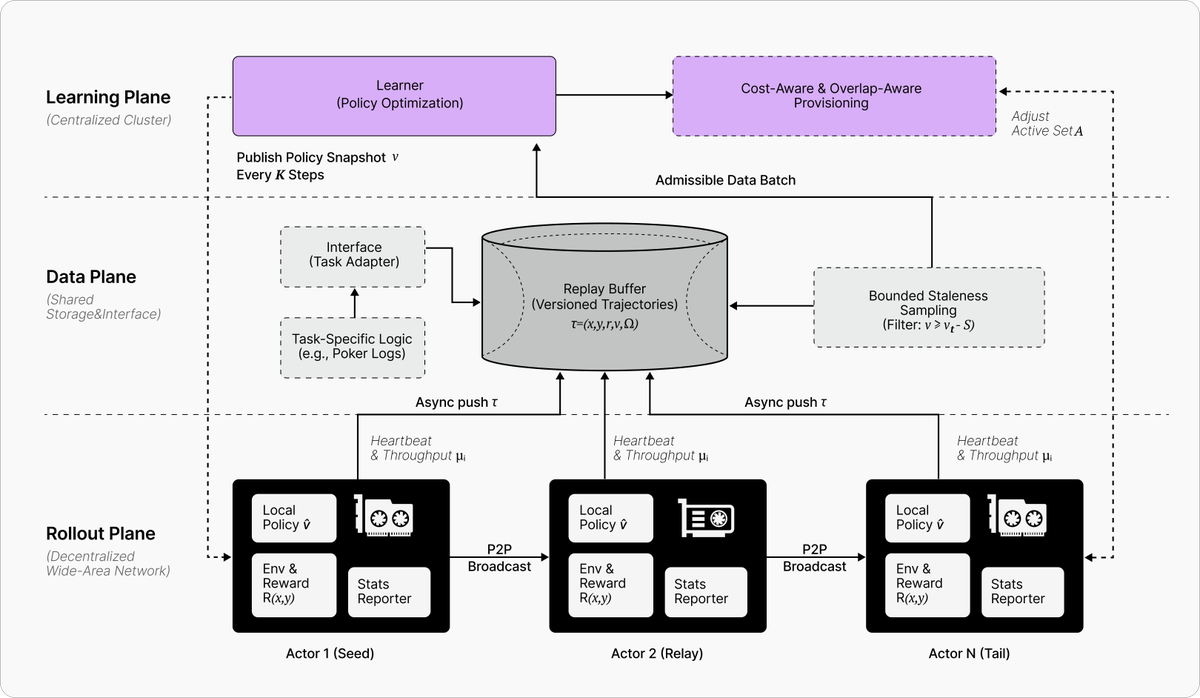
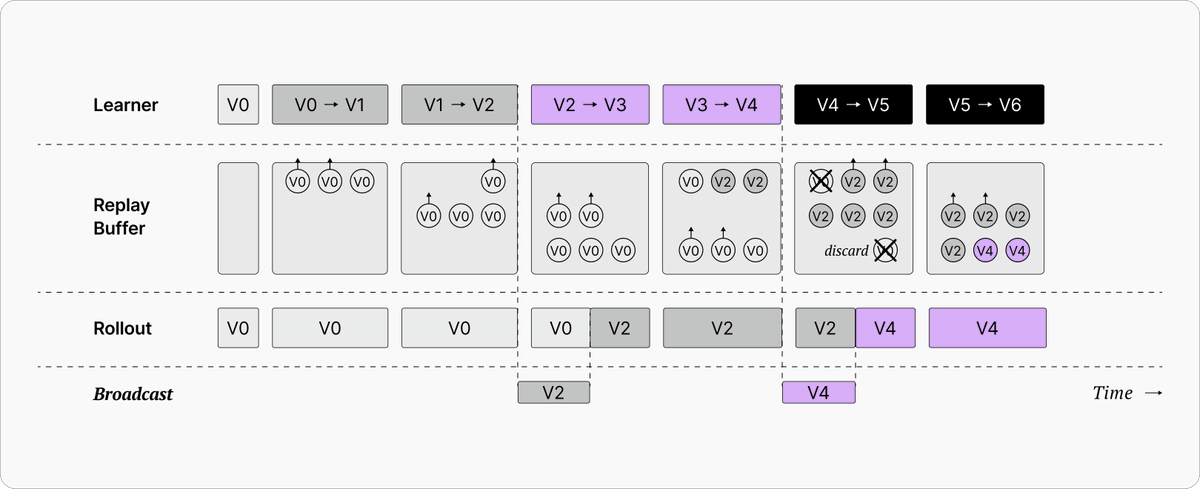
Our cofounder @0xEricYang sat down with @yacinelearning to walk through Echo-2’s distributed RL architecture.
Dive in to learn about async RL with distributed infra, and how we are scaling this for businesses to win in the agentic era.
Apr 7

for those interested in distributed reinforcement learning I just finished a ~1h tutorial on the echo2 framework by @Gradient_HQ
we check:
- how to do async RL
- infra split between rollout workers and centralized learner
- interview with gradient cofounder eric yang himself!

40
48
253
35,631
Apr 8
When you scale parallel agents, prompt updates degrade fast. The more trajectories you process concurrently, the more generic your learned prompts become.
Our researchers worked with @lihanc02 and team on Combee to rethink how aggregation works at scale.
Results held up across GEPA and ACE even past 80 concurrent agents.
Read more on this research👇
Apr 7

Prompt Learning does not scale for parallel agents.
More parallel agents 🤖 = worse prompts 😭
Why? Processing too many trajectories concurrently damages the prompt update process
🐝 We fix this with Combee :
→ preserves high-quality learnt system prompt
→ scales to more than 80 concurrent agents
→ up to 17× speedup without quality drop on top of ACE and GEPA
🥽Use Cases:
1. Prompt learning on large scale collected agent traces
2. Parallel agent learning online with fast knowledge sharing
Read more below to learn how agents actually learn at scale ⬇️

40
49
261
32,867
Gradient retweeted

Apr 4
If software no longer needs you to operate it, what does an “application” even mean?
That’s what we’re digging into at The Agentic Shift with panels, demos, and speakers from Google, PixVerse, MiniMax more.
SF | Apr 8
Sign up here:
lu.ma/y07o6vuo
6
17
77
15,102
Mar 31
As fellow training nerds, UniPat AI’s approach caught our eyes.
Synthesizing future-event data to fix outcome bias and actually beat human prediction markets is defined something worth checking out!
Mar 30

Today we’re introducing Echo — our full-stack prediction intelligence system, which turns uncertainty🔮 into profit📈.
We Make Prediction General, Evaluable, Trainable and Profitable.
🌐Website: echo.unipat.ai/
46
44
271
25,868
Mar 27
Everyone's scrambling for more compute.
The harder problem is making distributed compute actually work for multi-agent systems.
That's what Echo-2 is built for.
Mar 27

The explosion of agentic AI has kicked off a mad rush for computing power, pushing central processing units back into hot demand on.wsj.com/4uYyMN2
50
51
309
30,247
Mar 26
Benchmarks that test what models have memorized are saturating fast. ARC-AGI-3 is asking a harder question: can AI actually learn something new on the fly?
One direction we've been exploring: multi-agent orchestration. In our study, coordinating four frontier LLMs across multiple turns consistently matched or outperformed the strongest single model, even on tasks none of them could solve alone.
The gap between "best single model" and "best coordination of models" is where a lot of the real progress is hiding.
More on our multi-turn, multi-agent orchestration study: arxiv.org/abs/2509.23537

Announcing ARC-AGI-3
The only unsaturated agentic intelligence benchmark in the world
Humans score 100%, AI <1%
This human-AI gap demonstrates we do not yet have AGI
Most benchmarks test what models already know, ARC-AGI-3 tests how they learn
39
39
269
24,235
Mar 25
Great to see multi-agent systems getting serious engineering attention.
One thing we think about a lot: as agents get more capable, the orchestration layer matters just as much as the models themselves.
Our work on Symphony explores what happens when you remove the central controller entirely and let agents coordinate across consumer hardware through decentralized task allocation and weighted voting.
We've achieved up to 41.6% accuracy gains over centralized frameworks, running on commodity GPUs with <5% orchestration overhead.
Find out more in our Symphony paper:
arxiv.org/abs/2508.20019
Mar 24

New on the Anthropic Engineering Blog:
How we use a multi-agent harness to push Claude further in frontend design and long-running autonomous software engineering.
Read more: anthropic.com/engineering/ha…
64
50
334
31,596
Gradient retweeted
Mar 21
local ai has picked up fast since openclaw dropped.
with the latest wave of small capable models, more people are running serious workloads on their own hardware.
if you missed this good local ai tutorial from @yacinelearning or want a refresher on how distributed scheduling actually works under the hood, it's worth the rewatch over the weekend!
Feb 9
I am continuing my adventure into distributed AI system with the parallax scheduling strat from @Gradient_HQ
in this 37min tutorial I go through:
- heuristic used to make scheduling tractable
- dynamic programming formulation
- filling GPU with water
- shoving them into shelves

14
15
121
16,179
Mar 19
Dobby is a free elf now.
Open models, open orchestration, open compute. The agentic RL stack that used to live inside walled gardens just showed up on hardware you can order and frameworks you can fork.
No masters needed.
Mar 18

Thank you Jensen and NVIDIA! She’s a real beauty! I was told I’d be getting a secret gift, with a hint that it requires 20 amps. (So I knew it had to be good). She’ll make for a beautiful, spacious home for my Dobby the House Elf claw, among lots of other tinkering, thank you!!
39
36
255
24,406
Mar 17
Our GTC takeaway is clear: NVIDIA is betting hard on open.
- NemoClaw turns OpenClaw into enterprise infrastructure.
- Nemotron 4 will be open-sourced.
- Nemotron Coalition puts eight labs on a shared open frontier model.
This is what we've been building toward. Open infrastructure for open intelligence is the direction the biggest AI companies are taking.
74
55
304
27,364
Gradient retweeted
Mar 13
some parallax dev lunch break fun:
- a macbook pro, a mac mini, some cables
- zero internet, zero cost
- openclaw running on parallax
no subs. no token burn. nothing leaves the desk.
just local agents vibing.
17
18
120
14,776
Mar 13
Every AI model you use went through two phases:
- Pre-training builds raw intelligence (reading the internet).
- Post-training builds judgment (learning to be useful).
Reinforcement learning plays a huge part in the latter.
Here's why it matters and how we make it better.
41
54
289
18,878
Mar 13
What this unlocks:
Researchers now have the freedom of experiment. Small teams can iterate without burning runway.
We're productizing this as Logits, RL-as-a-Service built on Echo-2.
Waitlist open for researchers and students at logits.dev
5
6
68
6,897
Mar 13
Read more on Echo-2:
Technical paper: arxiv.org/pdf/2602.02192
Messari report: messari.io/report/gradient-e…
2
3
50
6,283