
Desarrollador. Researcher. Research in Generative Al. Formo parte del equipo de LN Data. Hincha de River ♥️
Joined December 2020
- Tweets 2,880
- Following 2,172
- Followers 203
- Likes 22,540
55 Photos and videos













Martin Pascua retweeted

Jun 14
2,529
6,993
35,602
56,186,997
Martin Pascua retweeted

Jun 13
Alibaba Qwen3.7 slowly fading into irrelevance at the frontier due to proprietary stance.
In it's place we have Minimax M3 and... *checks notes* Rio 3.5 397b, made by the municipal IT company of Rio de Janeiro's city government.
huggingface.co/prefeitura-ri…

Community note
Analysis shows Rio-3.5-Open-397B is a 0.6/0.4 weight merge of Nex N2 Pro and Qwen 3.5, not an originally trained model. When the system prompt is removed, it identifies as Nex 79.2% of the time.
x.com/NexEcosystem/s…
github.com/nex-agi/Nex-N2…
139
344
3,414
2,030,846

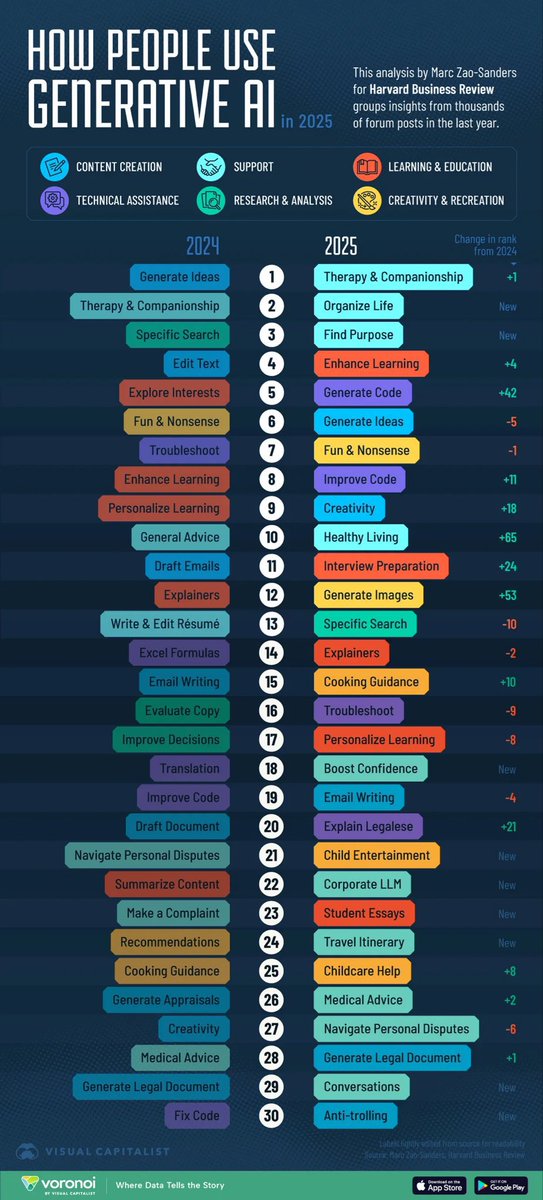
Generamos clones digitales para contar los resultados de un modelo predictivo desarrollado junto al Instituto de Cálculo de Exactas UBA-CONICET
Podés explorar las probabilidades de que Argentina vuelva a ser campeona y hasta simular cruces entre las selecciones que elijas🚀⚽️🤖
Jun 9

Predictivo de la @FIFAWorldCup. En @LANACION simulamos el torneo completo y este es el resultado: acortar.link/l3XGTl - Un equipazo liderado por @nicassese @MartinPascuaDev gran equipo, con la ayuda de @InstitCalculo y los clones digitales de Brenda Escudero y @FedeeLuque
1
414
Martin Pascua retweeted
Jun 8
📣We're updating the price of our Google AI Plus plan to $4.99/mo💰or local equivalent (down from $7.99), and doubling the included storage, from 200GB to 400GB ☁️. Now you can unlock tools to boost your productivity and creativity - and get more space to store your photos, videos and projects - for less.
164
168
2,584
1,006,592
🚀🚀
Jun 4

Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. anthropic.com/institute/recu…
25
Martin Pascua retweeted
Jun 3
Introducing frame.md, a spec built for videos & motion
design.md kept your brand consistent across screens
but when applied to videos, agents translated it back into webpages and decks
frame.md teaches your agents how to make branded video
turn your design.md into frame.md ↓
134
219
1,238
1,099,706
Martin Pascua retweeted
Jun 1
Welcome to the NVIDIA RTX Spark channel.
A new superchip for the age of personal AI.
Don't worry, your favorite NVIDIA local AI content continues on right here, just with a new headliner.
Let's get started...
213
377
7,602
912,667
Martin Pascua retweeted

Jun 1
30 anos.
Por 30 anos o PC foi a mesma coisa: Intel ou AMD dentro, GPU do lado, e torce pra não travar.
A NVIDIA acabou com isso numa keynote.
RTX Spark. Primeiro chip deles para computador pessoal. CPU, GPU e memória num único silício. ARM, 3nm, 1 petaflop de IA local.
Num laptop de 14mm.
Rodou Forza Horizon 6 e 007 First Light no palco a 100 FPS em 1440p. Fora da tomada. Sem throttling. No Windows.
O número que muda tudo: roda modelos de IA de 120 bilhões de parâmetros sem cloud. Sem API. Sem assinatura. Seu agente de IA mora na sua máquina. Ligado 24 horas. Só seu.
O PC não é mais uma tela com teclado. É uma estação de IA pessoal.
748
2,429
28,035
1,913,799

Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
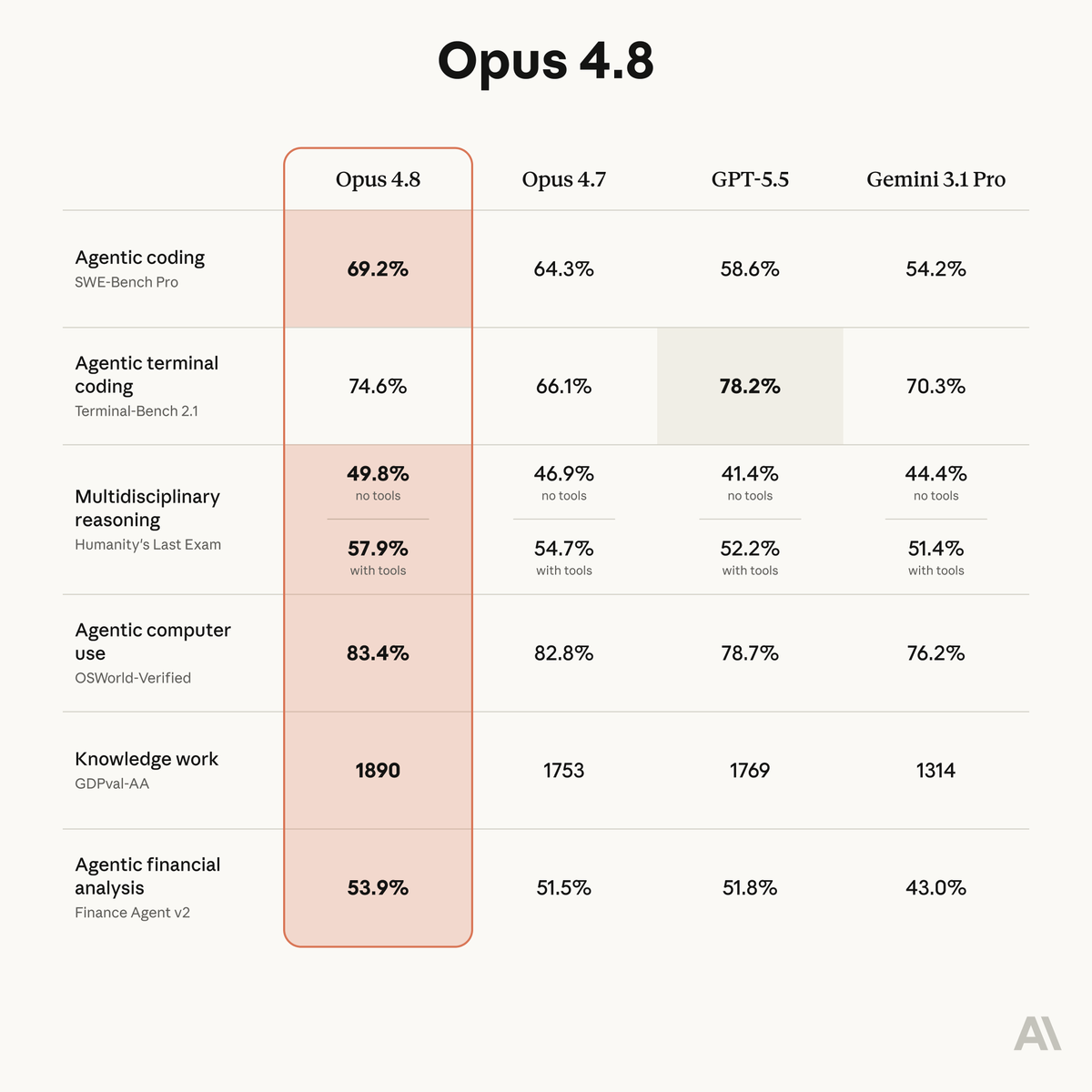
ALT Benchmark table showing how Claude Opus 4.8 compares to its predecessor and to other models on tests of coding, agentic skills, reasoning, and practical knowledge work tasks.
3,687
8,625
67,434
15,243,092
Martin Pascua retweeted

May 15
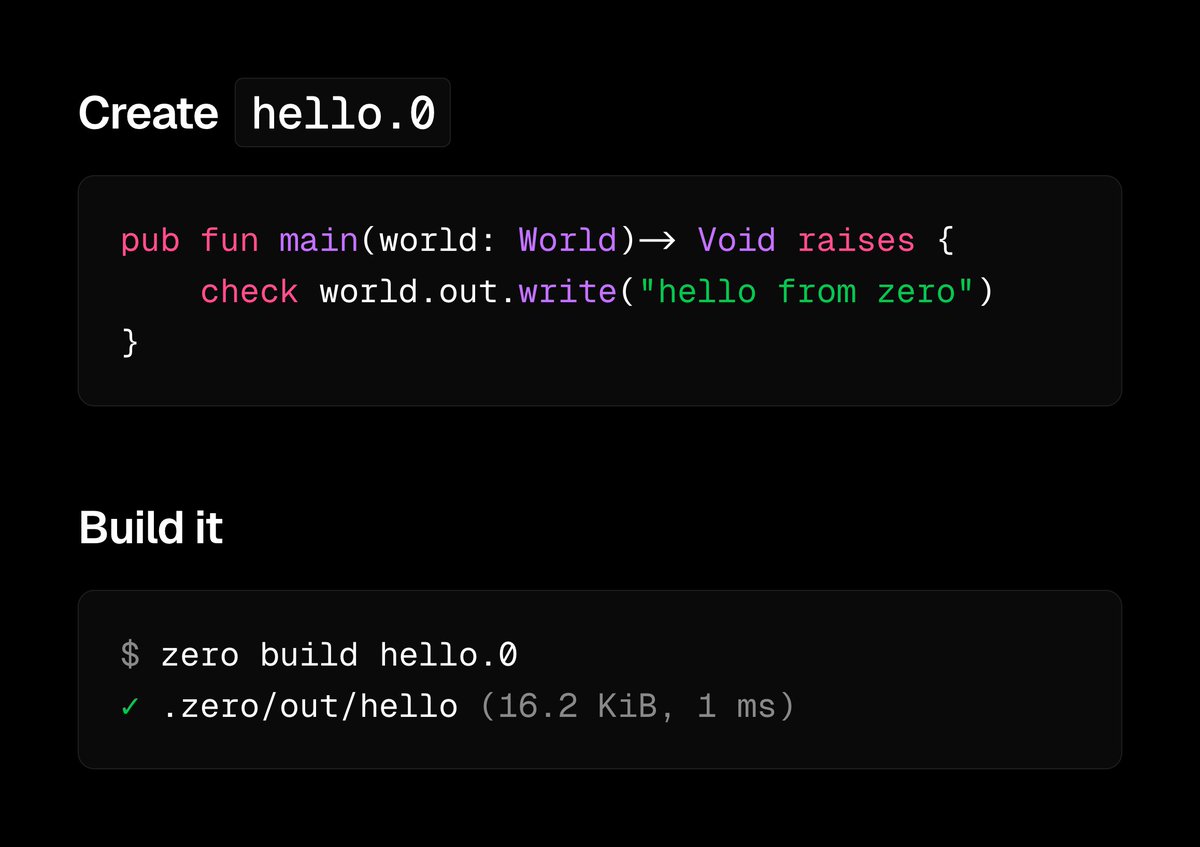
Introducing Zero
The programming language for agents.
I wanted a systems language that was faster, smaller, and easier for agents to use and repair.
Explicit capabilities. JSON diagnostics. Typed safe fixes.
Made for agents on day zero.
393
211
2,715
1,704,285
🚀
May 11

Today we're sharing our work on interaction models. A new class of model trained from scratch to handle real-time interaction natively, instead of gluing it onto a turn-based one.
youtu.be/A12AVongNN4
15
Martin Pascua retweeted

May 5
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
1,489
2,871
22,977
12,820,605
Martin Pascua retweeted

May 5
23
158
1,032
155,392
Martin Pascua retweeted

Speed up your Gemma 4 workflows by up to 3x with Multi-Token Prediction (MTP) drafters.
Standard LLM inference is fundamentally memory-bandwidth bound, creating a latency bottleneck as billions of parameters travel from VRAM just to generate a single token. We're working to ease this bottleneck with MTP drafters for @googlegemma 4.

26
117
1,059
93,481
🧐 para para para vos me estás diciendo que GitHub Copilot también se sube a la ola de dejar de subvencionar tokens

Starting June 1st, GitHub Copilot will move to a usage-based billing model as GitHub Copilot supports more agentic and advanced workflows.
In early May, you'll see a preview bill experience, giving visibility into projected costs before the transition.
👉 Read more about the upcoming change: github.blog/news-insights/co…
87
Martin Pascua retweeted
Apr 22
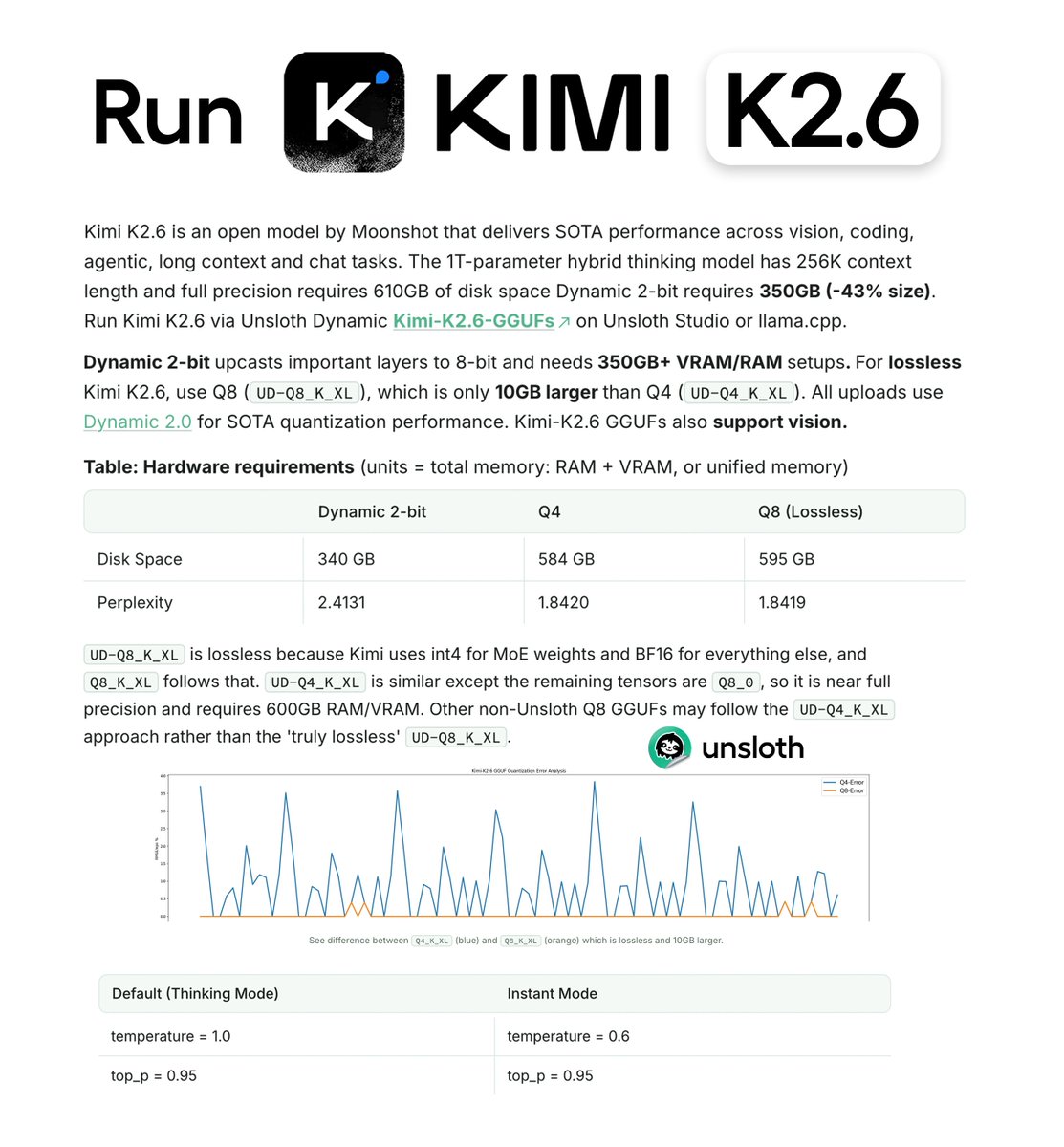
Kimi K2.6 can now run on CPU, GPU and SSD setups! 🔥
We shrank the 1T model to 340GB via Dynamic GGUFs where important layers are upcasted.
Run at >40 tok/s on 350GB RAM/VRAM setups.
Run full precision on 610 GB.
Guide: unsloth.ai/docs/models/kimi-…
GGUF: huggingface.co/unsloth/Kimi-…
Apr 20

Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…

69
170
1,796
220,963

Martin Pascua retweeted

Apr 18
Andrej Karpathy just made one of the most interesting arguments about AI model design that most people are completely missing.
His take is that frontier AI models are not too big because the technology is complex and too big because the training data is garbage.
When you or I think of the internet, we picture Wall Street Journal articles, Wikipedia entries, serious writing.
That is not what a pretraining dataset looks like.
When researchers at frontier labs look at random documents from the actual training corpus, it is stock ticker symbols, broken HTML, spam, gibberish.
One estimate puts Llama 3's information compression at just 0.07 bits per token meaning the model has only a hazy recollection of most of what it trained on.
So we build trillion parameter models not because we need a trillion parameter brain but because we need a trillion-parameter compression engine to squeeze some intelligence out of a firehose of noise.
Most of those parameters are doing memory work, not cognitive work.
Karpathy's prediction is separate the two entirely.
Build a cognitive core, a model that contains only the algorithms for reasoning and problem-solving, stripped of encyclopedic memorization and pair it with external memory that it can query when it needs facts.
He thinks a cognitive core trained on high-quality data could hit genuine intelligence at around one billion parameters.
For reference, today's flagship models run between 200 billion and 1.8 trillion parameters with most of that weight dedicated to remembering the internet's slop.
The trend is already moving his direction. GPT-4o operates at roughly 200 billion parameters and outperforms the original 1.8 trillion-parameter GPT-4.
Inference costs for GPT-3.5-level performance dropped 280-fold between 2022 and 2024 driven almost entirely by smaller, cleaner, better-architected models.
The real bottleneck in AI right now is not compute but rather data quality.
45
133
901
200,001