
Joined May 2010
- Tweets 13,022
- Following 732
- Followers 689
- Likes 32,957
171 Photos and videos













Pinned Tweet

1 Jan 2024
タイミングはあまり良くないとは思うけど、2024年頭の何かを書いた。(少なくとも当面)Twitterにはほぼいないということだけが重要
maswag.github.io/blog/posts/…
11
1,787
May 12
遅くなりましたが「環境情報の推定と検証による高信頼ロボット」という課題名でOSXの田中さん (@sports_robots) とNIIの栗田さん (@ShuheiKuritaJa) とともにJSTさきがけ融合研究加速支援に採択いただきました
「信頼されるAI」領域です。2年間ですが頑張っていこうと思います
jst.go.jp/kisoken/crest/rese…
2
6
35
6,030
Masaki Waga retweeted

May 1
一緒に取り組ませてもらっていたSoftMatcha 2論文がICML2026にアクセプトされました!一兆トークン規模のコーパスから、埋め込みを考慮したクエリに意味的に類似のフレーズをめっちゃ高速に検索します。@E869120 のアルゴリズム力をはじめとして、異分野シナジーの威力を見たぜ。


1
7
56
12,535

【🎉ICML 採択🎉】
1 兆語規模コーパスに対する類似語検索を「わずか 0.3 秒」で行う SoftMatcha 2 がトップ国際会議 ICML に採択されました。
高速な完全一致検索アルゴリズムと効率的な枝刈りを利用し、既存手法を 600 倍以上高速化しました。論文は以下となります。(1/2)
arxiv.org/abs/2602.10908

2
106
746
57,038
Masaki Waga retweeted

今回の出展をずんだもんに宣伝してもらいました!
(nyanko3141592さんのテンプレートを使わせてもらっています👉 github.com/nyanko3141592/rem…)
1
6
5
968
Masaki Waga retweeted

1
18
33
4,198
Mar 27
無事にQEST FORMATS'24のtrack chairとしての最後のお仕事であるSTTTのspecial issueも出版された模様
doi.org/10.1007/s10009-026-0…
1
154

Masaki Waga retweeted

Feb 19
ITmedia AI+にてSoftMatcha 2について書いていただきました、ありがとうございます! itmedia.co.jp/aiplus/article…
Feb 19

“あいまい”検索システム「SoftMatcha 2」 東大や京大、Sakana AIなどが開発 巨大化するAI学習データを高速検索
itmedia.co.jp/aiplus/article…
4
59
11,252
Masaki Waga retweeted

Feb 12
Introducing SoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Pre-Training Corpora
softmatcha.github.io/v2/
What lies within a trillion-scale pre-training corpus? Can you truly guarantee your benchmarks are uncontaminated simply because there are no exact string matches?
Alongside several research institutions in Japan, Sakana AI is proud to have collaborated in the development of SoftMatcha 2, an ultra-fast and flexible search tool that enables search over trillion-scale natural language corpora in under 0.3 seconds, even while handling semantic variations (substitution, insertion, and deletion). No existing tool meets all these criteria, including infini-gram-mini (EMNLP’25 Best Paper) or the original SoftMatcha (ICLR’25).
Our approach employs string matching based on suffix arrays that scales well with corpus size. To mitigate the combinatorial explosion induced by the semantic relaxation of queries, our method is built on two key algorithmic ideas: fast exact lookup enabled by a disk-aware design, and dynamic corpus-aware pruning.
As a practical application, we demonstrate that SoftMatcha 2 identifies potential benchmark contamination in pre-training corpora that existing exact-match approaches miss.
You can try searching through a 100B-scale corpus via our online demo. The system remains blazingly fast even on trillion-token corpora, so we encourage you to host it yourself for larger scales.
Demo: softmatcha-2.s3-website-ap-n…
Paper: arxiv.org/abs/2602.10908
Code: github.com/softmatcha/softma…
This work is a collaboration with researchers from the University of Tokyo, NII, Kyoto University, SOKENDAI, NINJAL, Tohoku University, and RIKEN.
16
84
463
88,833
Masaki Waga retweeted
Feb 12
We've launched SoftMatcha 2, developed with my friends in academia. It's a blazing-fast search tool for trillion-token pre-training datasets that supports semantic variants. We showcase its use in detecting benchmark contamination in our paper.
🌐 Demo: softmatcha-2.s3-website-ap-n…
📄 Paper: arxiv.org/abs/2602.10908
💻 Code: github.com/softmatcha/softma…
🍵 Project: softmatcha.github.io/v2/
Feb 12

Introducing SoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Pre-Training Corpora
softmatcha.github.io/v2/
What lies within a trillion-scale pre-training corpus? Can you truly guarantee your benchmarks are uncontaminated simply because there are no exact string matches?
Alongside several research institutions in Japan, Sakana AI is proud to have collaborated in the development of SoftMatcha 2, an ultra-fast and flexible search tool that enables search over trillion-scale natural language corpora in under 0.3 seconds, even while handling semantic variations (substitution, insertion, and deletion). No existing tool meets all these criteria, including infini-gram-mini (EMNLP’25 Best Paper) or the original SoftMatcha (ICLR’25).
Our approach employs string matching based on suffix arrays that scales well with corpus size. To mitigate the combinatorial explosion induced by the semantic relaxation of queries, our method is built on two key algorithmic ideas: fast exact lookup enabled by a disk-aware design, and dynamic corpus-aware pruning.
As a practical application, we demonstrate that SoftMatcha 2 identifies potential benchmark contamination in pre-training corpora that existing exact-match approaches miss.
You can try searching through a 100B-scale corpus via our online demo. The system remains blazingly fast even on trillion-token corpora, so we encourage you to host it yourself for larger scales.
Demo: softmatcha-2.s3-website-ap-n…
Paper: arxiv.org/abs/2602.10908
Code: github.com/softmatcha/softma…
This work is a collaboration with researchers from the University of Tokyo, NII, Kyoto University, SOKENDAI, NINJAL, Tohoku University, and RIKEN.
1
10
52
14,906
Feb 12
RT> ICLR'25の仕事がより強くなって帰ってきたの巻です。個人的にはずっとやっているqualitative/Booleanな世界をquantitativeにするという研究の方向性の、高速文字列マッチングでの第二弾という位置づけだったりします
9
390
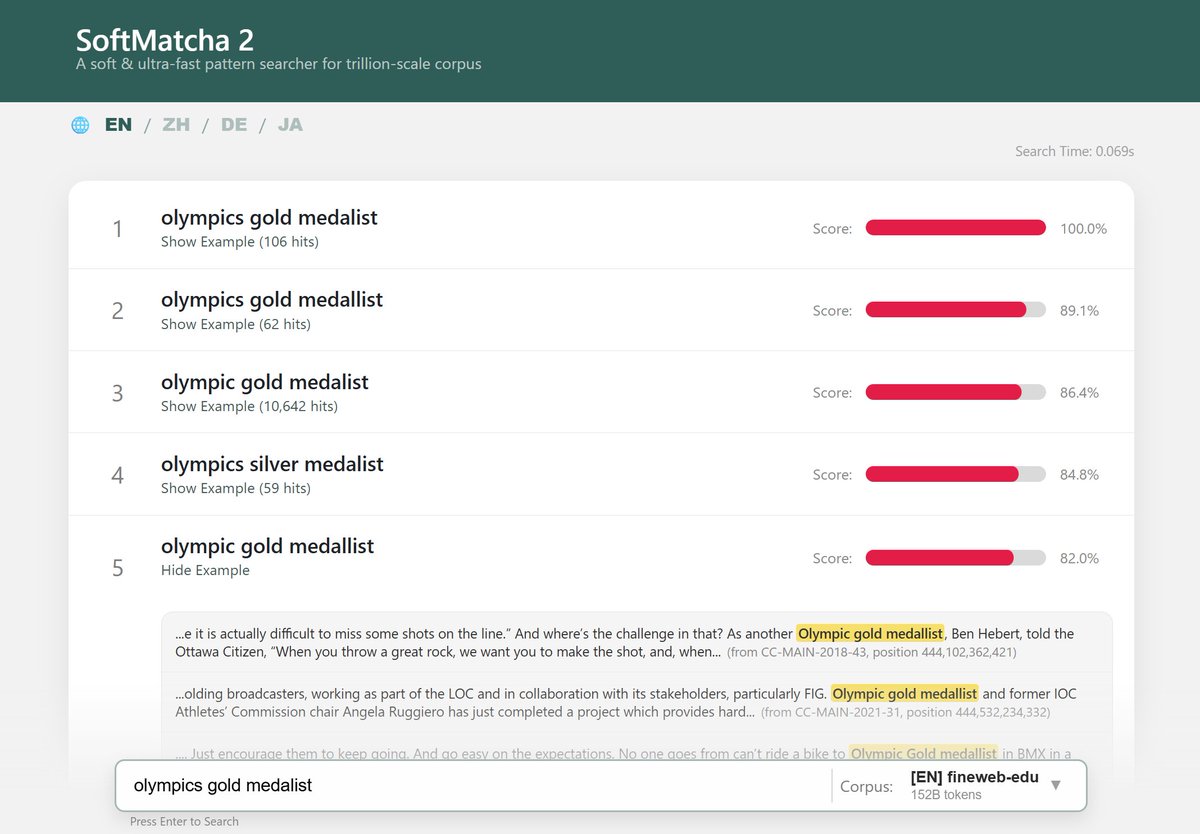
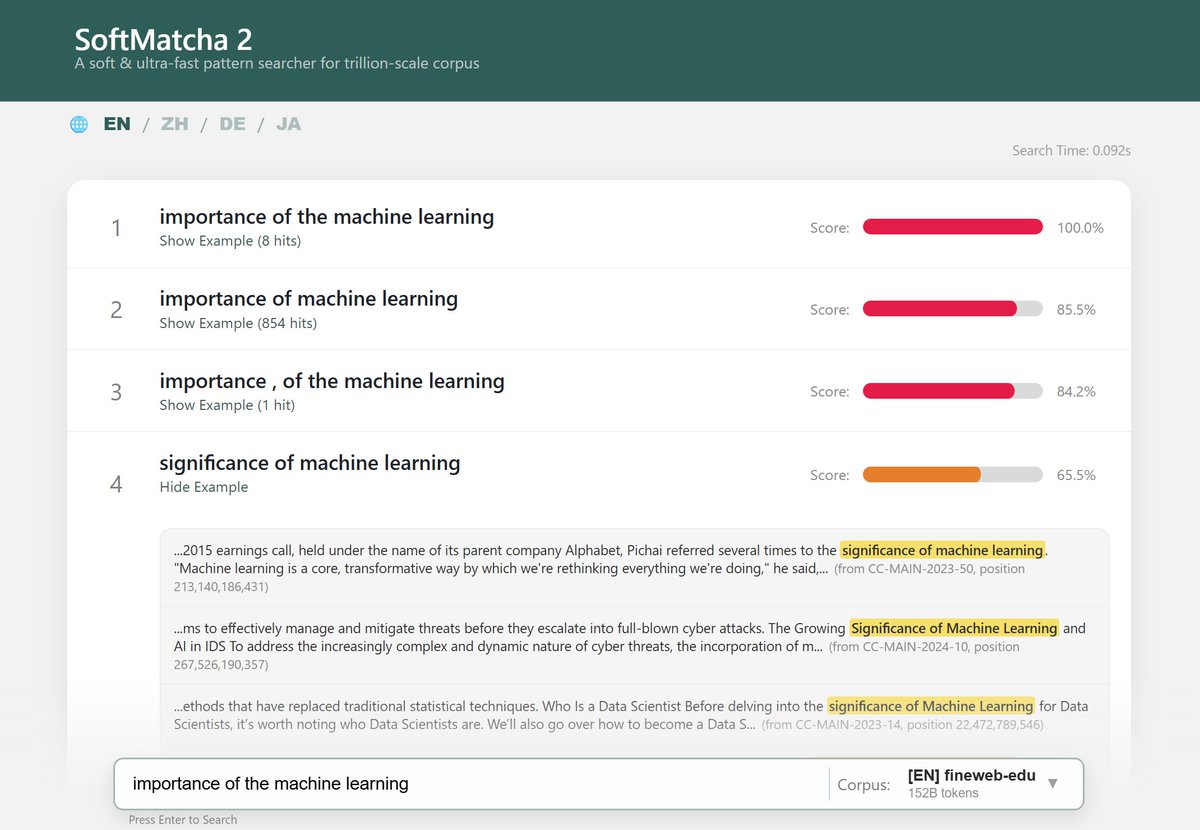
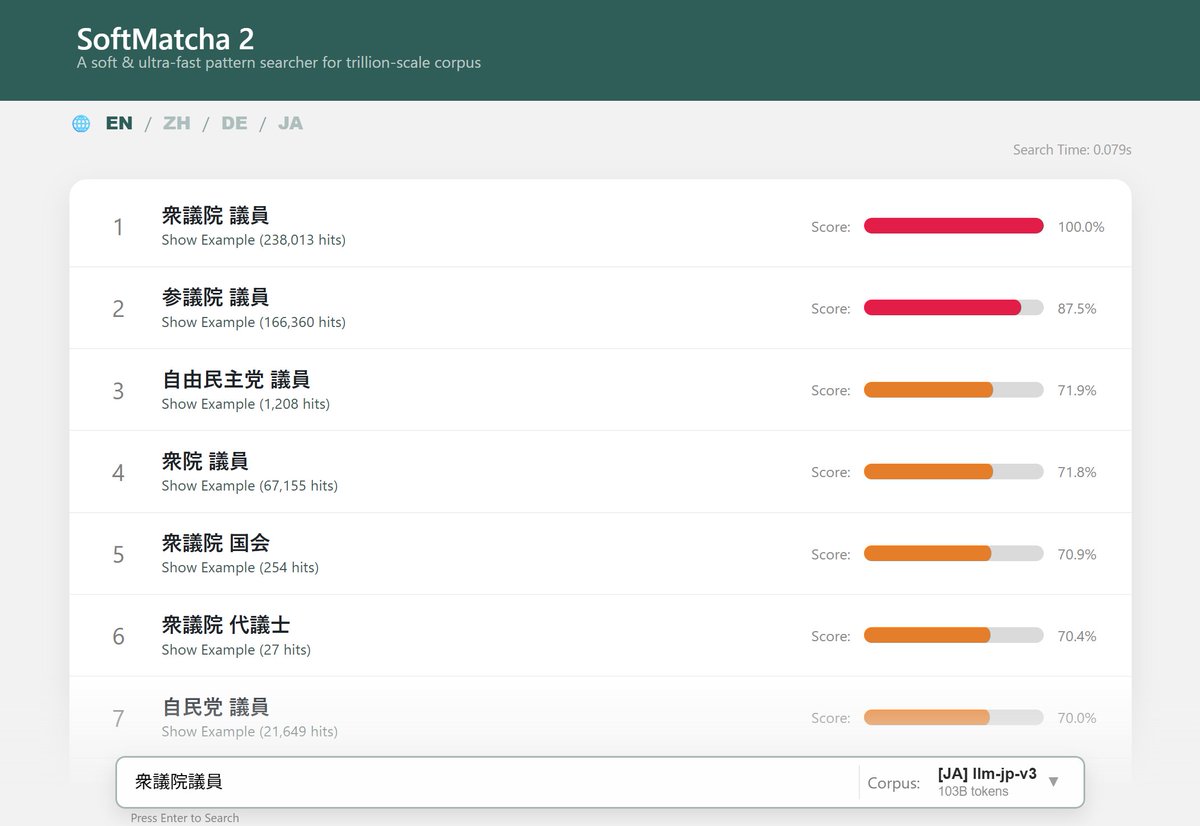
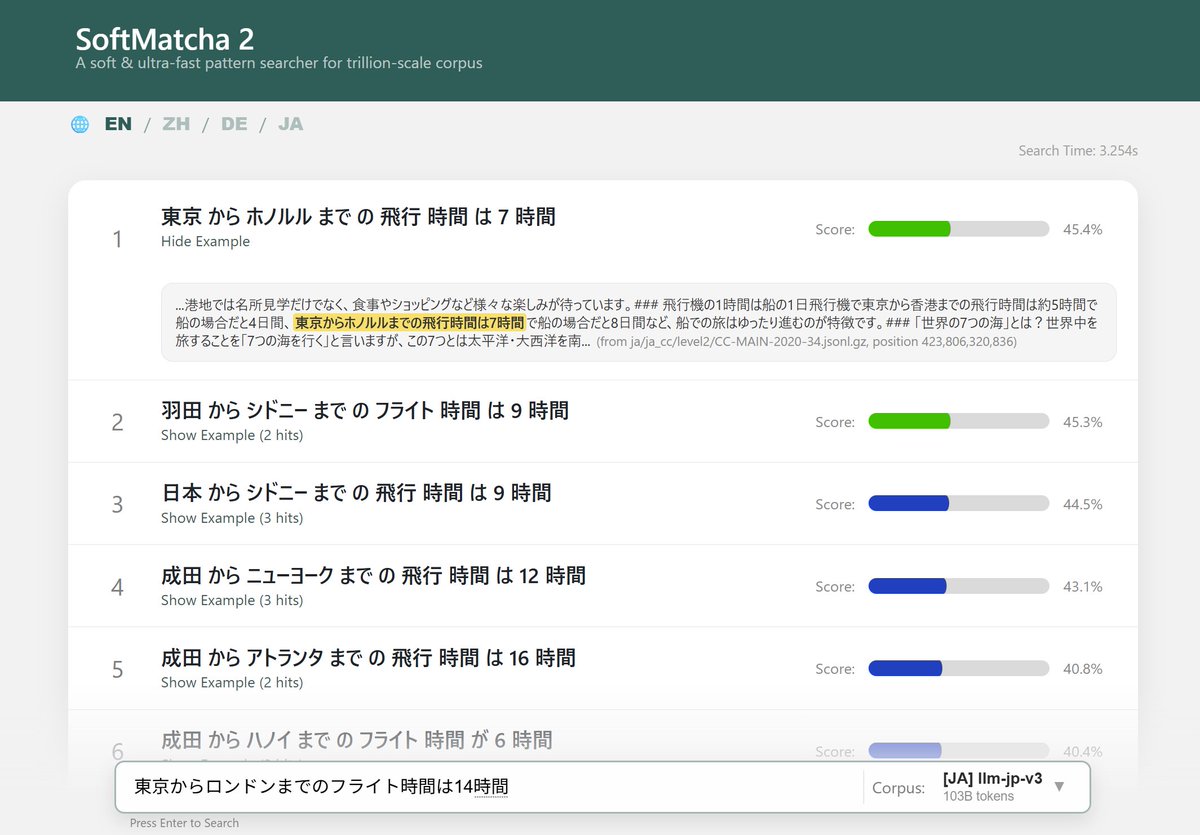
【告知】
超大規模コーパスから類似語を含めた用例検索を行えるツール「SoftMatcha 2」を公開しました!
検索ツールとしては国内最大級の約 2,600 億語に対し、わずか 0.1 秒で検索。英語・日本語含めた 7 つの言語に対応しています。ぜひご活用ください!
softmatcha.github.io/v2/
98
467
62,981
Masaki Waga retweeted

Feb 12
🍦 SoftMatcha 2 プロジェクトページ: softmatcha.github.io/v2/
🗣️ 今週末 2/14 の #言語学フェス と、それから 3/10 に #NLP2026 でも発表します。遊びにきてください。
(言語学フェス)
sites.google.com/view/lingfe…
soft-monarch-ccb.notion.site…
(NLP)
anlp.jp/nlp2026/
anlp.jp/proceedings/annual_m…

ALT SoftMatch 2: 言語学フェス2026(2026-02-14)のA-12(午前の部)にて発表予定

ALT SoftMatch 2: 言語処理学会年次大会2026(2026-03-10)のQ1-5(午前の部)にて発表予定
1
53
210
31,144
Masaki Waga retweeted
Feb 12
1兆語規模のコーパスから0.1秒単位で用例検索できるツールができてしまいました。意味的な置換・挿入・削除にも対応。
世界の Takuya Akiba と ICPC 史上初世界2位に輝いた E869120 のガチプロ2名にジョインいただき、動くわけがないと思っていたサイズでなぜか動いてます。遊んでみてください。
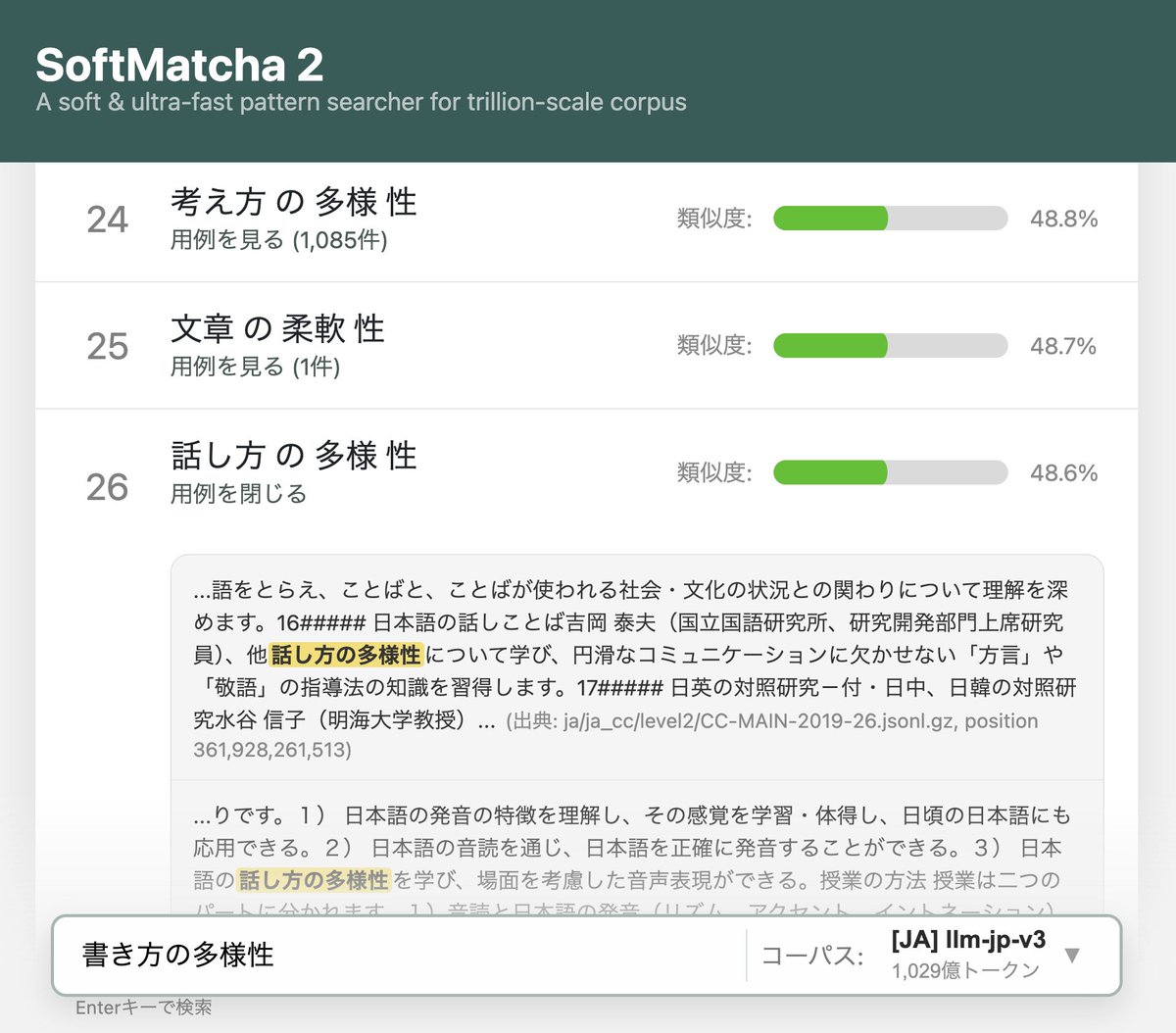
ALT SoftMatcha 2 の検索結果:「書き方の多様性」から「話し方の多様性」や「文章の柔軟性」がヒットしている様子
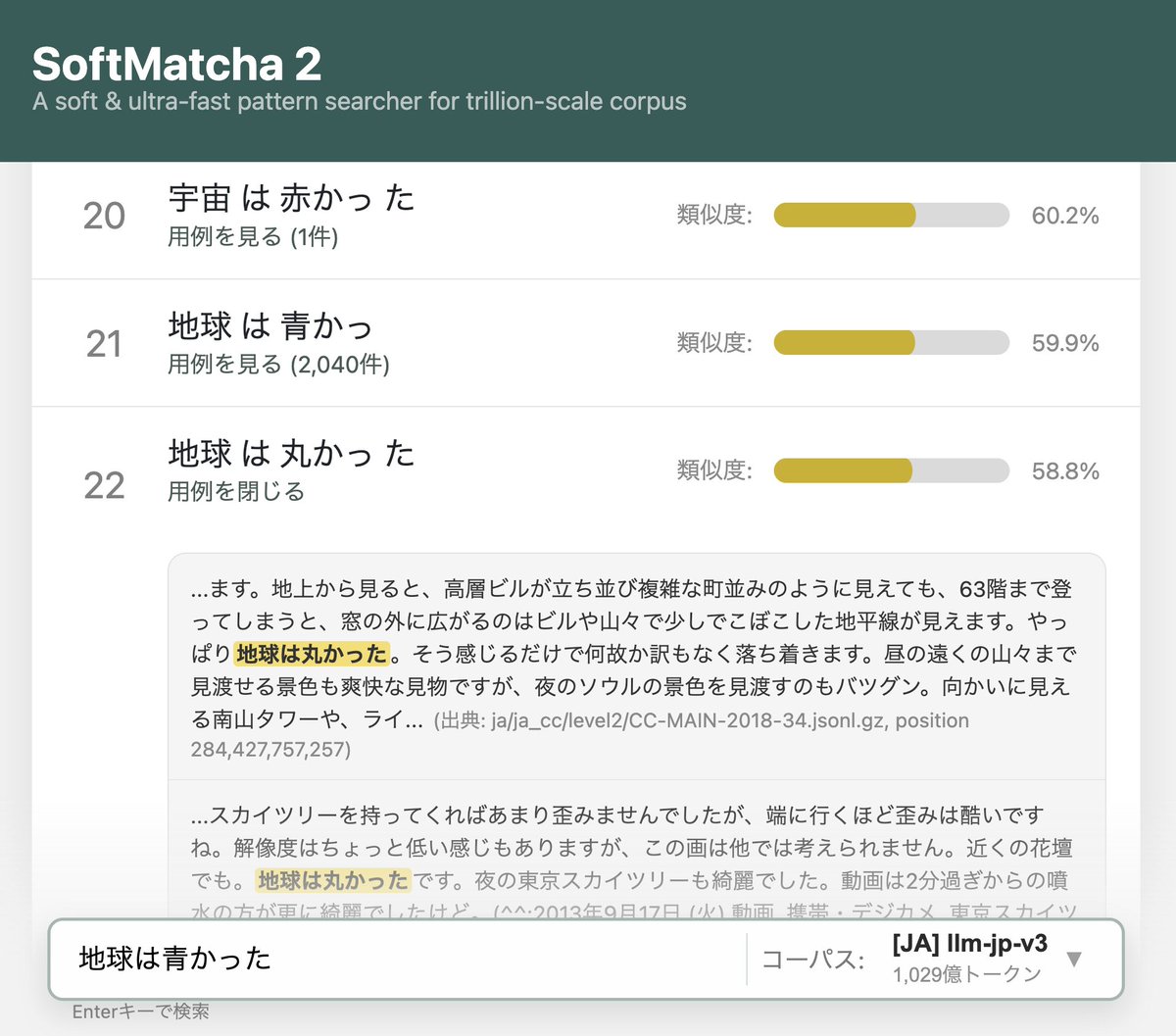
ALT SoftMatcha 2 の検索結果:「地球は青かった」から「地球は丸かった」がヒットしている様子

ALT SoftMatcha 2 の検索結果:「AIは世界を変えるか」から「ディープラーニングが世界を変える。」がヒットしている様子
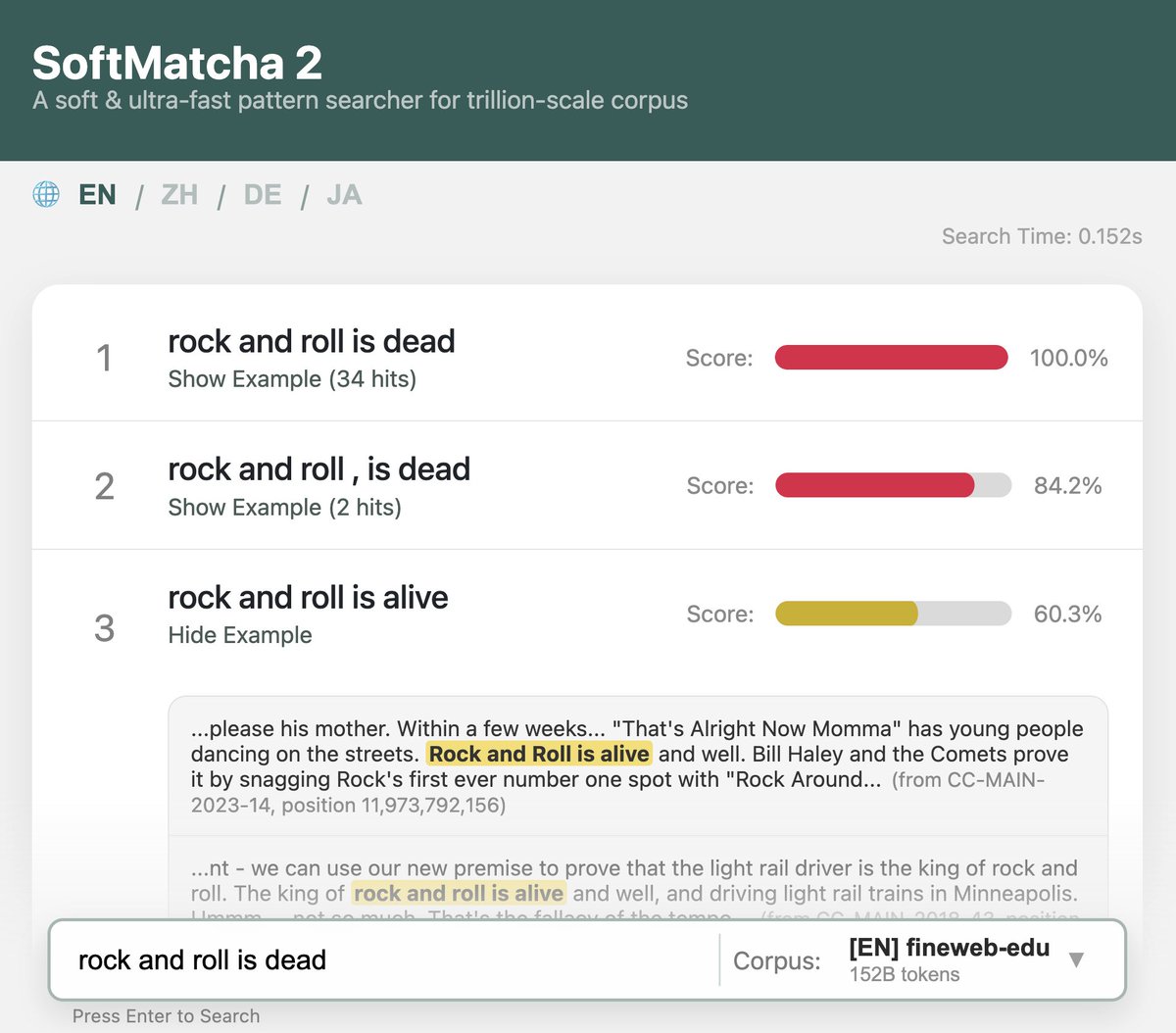
ALT SoftMatcha 2 での用例検索:「rock and roll is dead」から「rock and roll is alive」がヒットしている様子
1
445
2,150
439,299
Masaki Waga retweeted
Feb 12
巨大なLLM事前学習データを爆速で検索出来る「SoftMatcha 2」の開発に参加させてもらいました。デモ、論文、ソースコード等をこの度公開しましたので是非お試し下さい!
softmatcha.github.io/v2/
意味的類似性に基づいた置換や挿入削除に対応しながら1兆トークン規模のデータを0.1秒代で検索すると いうなかなか狂った性能になってます。EMNLP'25 Best Paperのinfini-gram-miniを含む既存のツール全てを大きく凌駕する性能だと思います。用途に特化したデータレイアウトを持つdisk-aware suffix arrayを使いながら、本来指数的になる置換・挿入・削除の候補を実データに基づきうまく枝刈りすることで高速な検索を達成してます。
この規模の事前学習データを検索出来ることの利点の事例として、論文ではベンチマークの汚染の検証をやってみてます。infini-gram-miniのような厳密な検索のみでは発見出来ないような汚染の事例なども有りそうでした。
現在デモでは数百Bトークン規模のデータからの検索を試せるようになってます。コードも公開してますのでご自身でホストしてもらうとより大規模なケースもお試し頂けます。
🌐 Demo: softmatcha-2.s3-website-ap-n…
📄 Paper: arxiv.org/abs/2602.10908
💻 Code: github.com/softmatcha/softma…
若き才能 @e869120 を始めとするSoftMatchaチームの方々との協働はとても刺激的で多くの学びがありました。楽しかった〜!ありがとうございました! @shiatsumat @go2oo2 @ksuenaga @MasWag @sho_yokoi
Feb 12

1兆語規模のコーパスから0.1秒単位で用例検索できるツールができてしまいました。意味的な置換・挿入・削除にも対応。
世界の Takuya Akiba と ICPC 史上初世界2位に輝いた E869120 のガチプロ2名にジョインいただき、動くわけがないと思っていたサイズでなぜか動いてます。遊んでみてください。
ALT SoftMatcha 2 の検索結果:「書き方の多様性」から「話し方の多様性」や「文章の柔軟性」がヒットしている様子
ALT SoftMatcha 2 の検索結果:「地球は青かった」から「地球は丸かった」がヒットしている様子
ALT SoftMatcha 2 の検索結果:「AIは世界を変えるか」から「ディープラーニングが世界を変える。」がヒットしている様子
ALT SoftMatcha 2 での用例検索:「rock and roll is dead」から「rock and roll is alive」がヒットしている様子
4
255
1,149
249,283
Masaki Waga retweeted

31 Dec 2025
#クラウドファンディングCAMPFIRE にて、
研究者の業績管理を楽にするサービス PubListAuto の支援募集を開始しました。
国内外、大小問わず、論文等の自分の発表情報を網羅的にウェブから集約して、利用可能にするサービスです。
ご支援よろしくお願いします!
camp-fire.jp/projects/907619…
32
36
19,165
15 Dec 2025
丁度一年くらいまえに初稿をざっと書いたブラックボックス検査のtutorial論文が一般公開されたので、宣伝しときます。実は始めて書いた日本語論文だったりします
doi.org/10.11509/isciesci.69…
1
2
6
810
17 Dec 2025
ついでに、同12/15にはFSTTCSの併設ワークショップのQuantFormalで大体これに対応するトークをやってきました (quantformal-2025.vercel.app/) スライドも公開されてます
274